說一道常見面試題:
使用Redis分布式鎖的詳細方案是什么?
一個很簡單的答案就是去使用 Redission 客戶端,Redission 中的鎖方案就是 Redis 分布式鎖的比較完美的詳細方案,
那么,Redission 中的鎖方案為什么會比較完美呢?
正好,我用 Redis 做分布式鎖經驗十分豐富,在實際作業中,也探索過許多種使用 Redis 做分布式鎖的方案,經過了無數血淚教訓,
所以,在談及 Redission 鎖為什么比較完美之前,先給大家看看我曾經使用 Redis 做分布式鎖遇到過的問題,
我曾經用 Redis 做分布式鎖想去解決一個用戶搶優惠券的問題,這個業務需求是這樣的:當用戶領完一張優惠券后,優惠券的數量必須相應減一,如果優惠券搶光了,就不允許用戶再搶了,
在實作時,先從資料庫中先讀出優惠券的數量進行判斷,當優惠券大于 0,就進行允許領取優惠券,然后,再將優惠券數量減一后,寫回資料庫,
當時由于請求數量比較多,所以,我們使用了三臺服務器去做分流,
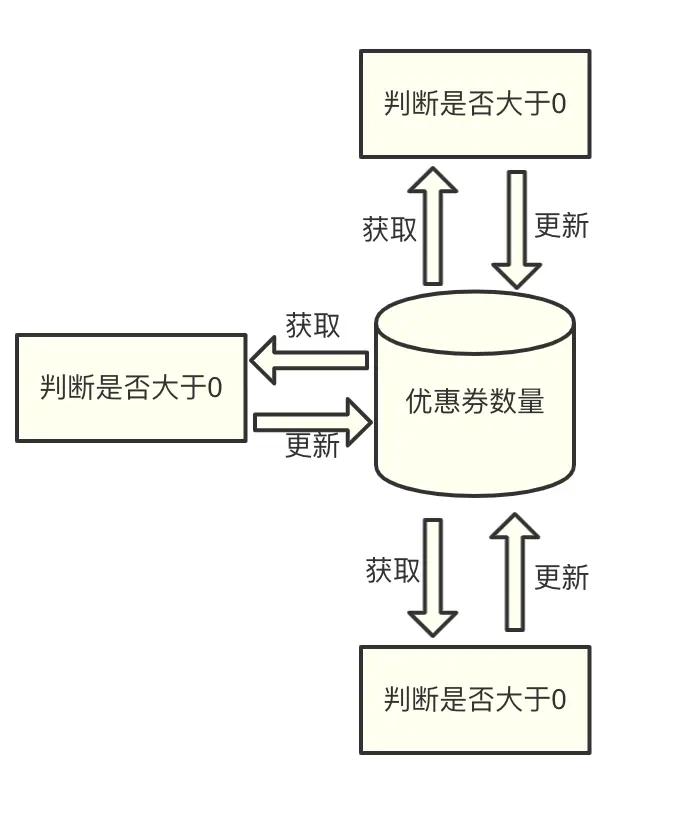
這時候會出現一個問題:
如果其中一臺服務器上的 A 應用獲取到了優惠券的數量之后,由于處理相關業務邏輯,未及時更新資料庫的優惠券數量;在 A 應用處理業務邏輯的時候,另一臺服務器上的 B 應用更新了優惠券數量,那么,等 A 應用去更新資料庫中優惠券數量時,就會把 B 應用更新的優惠券數量覆寫掉,
看到這里,可能有人比較奇怪,為什么這里不直接使用 SQL:
update 優惠券表 set 優惠券數量 = 優惠券數量 - 1 where 優惠券id = xxx
原因是這樣做,在沒有分布式鎖協調下,優惠券數量可能直接會出現負數,因為當優惠券數量為 1 的時候,如果兩個用戶通過兩臺服務器同時發起搶優惠券的請求,都滿足優惠券大于 0 的條件,然后都執行這條 SQL 陳述句,結果優惠券數量直接變成 -1 了,
還有人說可以用樂觀鎖,比如使用如下 SQL:
update 優惠券表 set 優惠券數量 = 優惠券數量 - 1 where 優惠券id = xxx and version = xx
這種方式就在一定幾率下,很可能出現資料一直更新不上,導致長時間重試的情況,
所以,經過綜合考慮,我們就采用了 Redis 分布式鎖,通過互斥的方式,以防止多個客戶端去同時更新優惠券數量的方案,
當時,我們首先想到的就是使用 Redis 的 setnx 命令,setnx 命令其實就是 set if not exists 的簡寫,
當 key 設定值成功后,則回傳 1,否則就回傳 0,所以,這里 setnx 設定成功可以表示成獲取到鎖,如果失敗,則說明已經有鎖,可以被視作獲取鎖失敗,
setnx lock true
如果想要釋放鎖,執行 del 指令,把 key 洗掉即可,
del lock
利用這個特性,我們就可以讓系統在執行優惠券邏輯之前,先去 Redis 中執行 setnx 指令,再根據指令執行結果,去判斷是否獲取到鎖,如果獲取到了,就繼續執行業務,執行完再使用 del 指令去釋放鎖,如果沒有獲取到,就等待一定時間,重新再去獲取鎖,
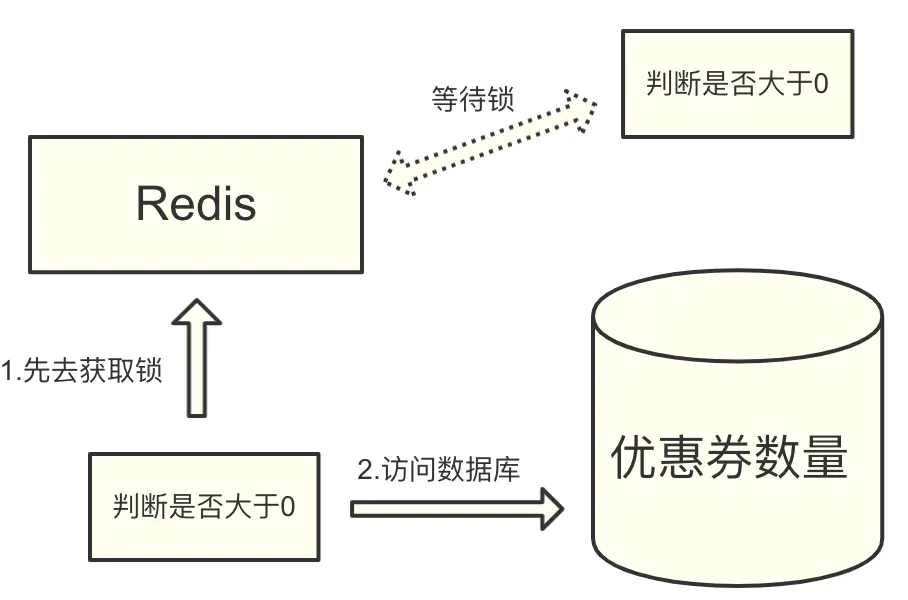
乍一看,這一切沒什么問題,使用 setnx 指令確實起到了想要的互斥效果,
但是,這是建立在所有運行環境都是正常的情況下的,一旦運行環境出現了例外,問題就出現了,
想一下,持有鎖的應用突然崩潰了,或者所在的服務器宕機了,會出現什么情況?
這會造成死鎖——持有鎖的應用無法釋放鎖,其他應用根本也沒有機會再去獲取鎖了,這會造成巨大的線上事故,我們要改進方案,解決這個問題,
怎么解決呢?咱們可以看到,造成死鎖的根源是,一旦持有鎖的應用出現問題,就不會去釋放鎖,從這個方向思考,可以在 Redis 上給 key 一個過期時間,
這樣的話,即使出現問題,key 也會在一段時間后釋放,是不是就解決了這個問題呢?實際上,大家也確實是這么做的,
不過,由于 setnx 這個指令本身無法設定超時時間,所以一般會采用兩種辦法來做這件事:
1、采用 lua 腳本,在使用 setnx 指令之后,再使用 expire 命令去給 key 設定過期時間,
if redis.call("SETNX", "lock", "true") == 1 then
local expireResult = redis.call("expire", "lock", "10")
if expireResult == 1 then
return "success"
else
return "expire failed"
end
else
return "setnx not null"
end
2、直接使用 set(key,value,NX,EX,timeout) 指令,同時設定鎖和超時時間,
redis.call("SET", "lock", "true", "NX", "PX", "10000")
以上兩種方法,使用哪種方式都可以,
釋放鎖的腳本兩種方式都一樣,直接呼叫 Redis 的 del 指令即可,
到目前為止,我們的鎖既起到了互斥效果,又不會因為某些持有鎖的系統出現問題,導致死鎖了,這樣就完美了嗎?
假設有這樣一種情況,如果一個持有鎖的應用,其持有的時間超過了我們設定的超時時間會怎樣呢?會出現兩種情況:
- 發現系統在 Redis 中設定的 key 還存在
- 發現系統在 Redis 中設定的 key 不存在
出現第一種情況比較正常,因為你畢竟執行任務超時了,key 被正常清除也是符合邏輯的,
但是最可怕的是第二種情況,發現設定的 key 還存在,這說明什么?說明當前存在的 key,是另外的應用設定的,
這時候如果持有鎖超時的應用呼叫 del 指令去洗掉鎖時,就會把別人設定的鎖誤洗掉,這會直接導致系統業務出現問題,
所以,為了解決這個問題,我們需要繼續對 Redis 腳本進行改動……毀滅吧,累了……

首先,我們要讓應用在獲取鎖的時候,去設定一個只有應用自己知道的獨一無二的值,
通過這個唯一值,系統在釋放鎖的時候,就能識別出這鎖是不是自己設定的,如果是自己設定的,就釋放鎖,也就是洗掉 key;如果不是,則什么都不做,
腳本如下:
if redis.call("SETNX", "lock", ARGV[1]) == 1 then
local expireResult = redis.call("expire", "lock", "10")
if expireResult == 1 then
return "success"
else
return "expire failed"
end
else
return "setnx not null"
end
或者
redis.call("SET", "lock", ARGV[1], "NX", "PX", "10000")
這里,ARGV[1] 是一個可傳入的引數變數,可以傳入唯一值,比如一個只有自己知道的 UUID 的值,或者通過雪球演算法,生成只有自己持有的唯一 ID,
釋放鎖的腳本改成這樣:
if redis.call("get", "lock") == ARGV[1]
then
return redis.call("del", "lock")
else
return 0
end
可以看到,從業務角度,無論如何,我們的分布式鎖已經可以滿足真正的業務需求了,能互斥,不死鎖,不會誤洗掉別人的鎖,只有自己上的鎖,自己可以釋放,
一切都是那么美好!!!
可惜,還有個隱患,我們并未排除,這個隱患就是 Redis 自身,
要知道,lua 腳本都是用在 Redis 的單例上的,一旦 Redis 本身出現了問題,我們的分布式鎖就沒法用了,分布式鎖沒法用,對業務的正常運行會造成重大影響,這是我們無法接受的,
所以,我們需要把 Redis 搞成高可用的,一般來講,解決 Redis 高可用的問題,都是使用主從集群,
但是搞主從集群,又會引入新的問題,主要問題在于,Redis 的主從資料同步有延遲,這種延遲會產生一個邊界條件:當主機上的 Redis 已經被人建好了鎖,但是鎖資料還未同步到從機時,主機宕了,隨后,從機提升為主機,此時從機上是沒有以前主機設定好的鎖資料的——鎖丟了……丟了……了……

到這里,終于可以介紹 Redission(開源 Redis 客戶端)了,我們來看看它怎么是實作 Redis 分布式鎖的,
Redission 實作分布式鎖的思想很簡單,無論是主從集群還是 Redis Cluster 集群,它會對集群中的每個 Redis,挨個去執行設定 Redis 鎖的腳本,也就是集群中的每個 Redis 都會包含設定好的鎖資料,
我們通過一個例子來介紹一下,
假設 Redis 集群有 5 臺機器,同時根據評估,鎖的超時時間設定成 10 秒比較合適,
第 1 步,咱們先算出集群總的等待時間,集群總的等待時間是 5 秒(鎖的超時時間 10 秒 / 2),
第 2 步,用 5 秒除以 5 臺機器數量,結果是 1 秒,這個 1 秒是連接每臺 Redis 可接受的等待時間,
第 3 步,依次連接 5 臺 Redis,并執行 lua 腳本設定鎖,然后再做判斷:
- 如果在 5 秒之內,5 臺機器都有執行結果,并且半數以上(也就是 3 臺)機器設定鎖成功,則認為設定鎖成功;少于半數機器設定鎖成功,則認為失敗,
- 如果超過 5 秒,不管幾臺機器設定鎖成功,都認為設定鎖失敗,比如,前 4 臺設定成功一共花了 3 秒,但是最后 1 臺機器用了 2 秒也沒結果,總的等待時間已經超過了 5 秒,即使半數以上成功,這也算作失敗,
再額外多說一句,在很多業務邏輯里,其實對鎖的超時時間是沒有需求的,
比如,凌晨批量執行處理的任務,可能需要分布式鎖保證任務不會被重復執行,此時,任務要執行多長時間是不明確的,如果設定分布式鎖的超時時間在這里,并沒有太大意義,但是,不設定超時時間,又會引發死鎖問題,
所以,解決這種問題的通用辦法是,每個持有鎖的客戶端都啟動一個后臺執行緒,通過執行特定的 lua 腳本,去不斷地重繪 Redis 中的 key 超時時間,使得在任務執行完成前,key 不會被清除掉,
腳本如下:
if redis.call("get", "lock") == ARGV[1]
then
return redis.call("expire", "lock", "10")
else
return 0
end
其中,ARGV[1] 是可傳入的引數變數,表示持有鎖的系統的唯一值,也就是只有持有鎖的客戶端才能重繪 key 的超時時間,
到此為止,一個完整的分布式鎖才算實作完畢,總結實作方案如下:
- 使用 set 命令設定鎖標記,必須有超時時間,以便客戶端崩潰,也可以釋放鎖;
- 對于不需要超時時間的,需要自己實作一個能不斷重繪鎖超時時間的執行緒;
- 每個獲取鎖的客戶端,在 Redis 中設定的 value 必須是獨一無二的,以便識別出是由哪個客戶端設定的鎖;
- 分布式集群中,直接每臺機器設定一樣的超時時間和鎖標記;
- 為了保證集群設定的鎖不會因為網路問題導致某些已經設定的鎖出現超時的情況,必須合理設定網路等待時間和鎖超時時間,
這個分布式鎖滿足如下四個條件:
- 任意時刻只能有一個客戶端持有鎖;
- 不能發生死鎖,有一個客戶端持有鎖期間出現了問題沒有解鎖,也能保證后面別的客戶端繼續去持有鎖;
- 加鎖和解鎖必須是同一個客戶端,客戶端自己加的鎖只能自己去解;
- 只要大多數 Redis 節點正常,客戶端就能正常使用鎖,
當然,在 Redission 中的腳本,為了保證鎖的可重入,又對 lua 腳本做了一定的修改,現在把完整的 lua 腳本貼在下面,
獲取鎖的 lua 腳本:
if (redis.call('exists', KEYS[1]) == 0) then
redis.call('hincrby', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then
redis.call('hincrby', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
return redis.call('pttl', KEYS[1]);
對應的重繪鎖超時時間的腳本:
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then
redis.call('pexpire', KEYS[1], ARGV[1]);
return 1;
end;
return 0;
對應的釋放鎖的腳本:
if (redis.call('hexists', KEYS[1], ARGV[3]) == 0) then
return nil;
end;
local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1);
if (counter > 0) then
redis.call('pexpire', KEYS[1], ARGV[2]);
return 0;
else
redis.call('del', KEYS[1]);
redis.call('publish', KEYS[2], ARGV[1]);
return 1;
end;
return nil;
到現在為止,使用 Redis 作為分布式鎖的詳細方案就寫完了,
我既寫了一步一坑的坎坷經歷,也寫明了各個問題和解決問題的細節,希望大家看完能有所識訓,
最后再給大家提個醒,使用 Redis 集群做分布式鎖,有一定的爭議性,還需要大家在實際用的時候,根據現實情況,做出更好的選擇和取舍,
你好,我是四猿外,
一家上市公司的技術總監,管理的技術團隊一百余人,
我原創了不少文章,把其中的一些精華文章做了個匯總整理,搞了一份PDF——《爬坡》,其中包括了15篇技術文章(學習編程技巧、架構師、MQ、分布式)和 13 篇非技術文章(主要是程式員職場),
這份檔案的質量咋樣?我就不多自吹了,很多人看完說”受益匪淺“,
想獲取《爬坡》,可以掃下圖的碼,關注我的公眾號「四猿外」,在后臺回復:爬坡

轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/445374.html
標籤:架構設計
上一篇:計算自定義資料的長度
下一篇:異地多活的資料一致性簡單設計