這是我從給定串列制作字典的程式:
import csv
list1=[]
header=[]
with open('D:\C \Programs\Advanced Programming\grades.csv', 'r') as csv_file:
csv_reader = csv.reader(csv_file)
for line in csv_reader:
list1.append(line)
header = list1[0]
res = [dict(zip(header, values)) for values in list1[1:]]
for i in res:
print(i)
輸出是:
{'Last name': 'Alfalfa', ' First name': ' Aloysius', ' Final': '49', ' Grade': ' D-'}
{'Last name': 'Alfred', ' First name': ' University', ' Final': '48', ' Grade': ' D '}
{'Last name': 'Gerty', ' First name': ' Gramma', ' Final': '44', ' Grade': ' C'}
{'Last name': 'Android', ' First name': ' Electric', ' Final': '47', ' Grade': ' B-'}
{'Last name': 'Bumpkin', ' First name': ' Fred', ' Final': '45', ' Grade': ' A-'}
{'Last name': 'Rubble', ' First name': ' Betty', ' Final': '46', ' Grade': ' C-'}
現在在這本詞典中,我必須添加另一列總分,該列應包含串列中的學生總分,即串列 [2]
如何同時將所有標記添加到字典中,使其看起來像:
{'Last name': 'Alfalfa', ' First name': ' Aloysius', ' Final': '49', ' Grade': ' D-', 'Total marks': '49'}
{'Last name': 'Alfred', ' First name': ' University', ' Final': '48', ' Grade': ' D ','Total marks': '48'}
我不明白怎么做。請告訴我如何解決這個問題。
uj5u.com熱心網友回復:
據我了解,您想添加一個值等于“最終”的新列,您可以執行以下操作:
for raw in res:
raw['Total marks'] = raw[' Final']
print(res)uj5u.com熱心網友回復:
解決方案是將您的資料視為 pandas dataFrame 而不是串列。
舉個例子:
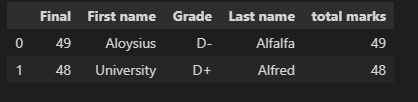
import pandas as pd
data = [{'Last name': 'Alfalfa', ' First name': ' Aloysius', ' Final': '49',
' Grade': ' D-'},{'Last name': 'Alfred', ' First name': ' University', '
Final': '48', ' Grade': ' D '}]
df=pd.DataFrame.from_dict(data,orient='columns')
list2=['49','48']
df['total marks']=list2
df
uj5u.com熱心網友回復:
我不知道您如何存盤標記,因此我無法為您提供完整的作業答案,但簡而言之:
res是一個字典串列。你可以通過設定一個額外的鍵和值到字典中my_dict['my_key'] = 'my_value':您應該for像這樣在回圈中使用它:
for i in res:
i['Total marks'] = total_marks # where total_marks is the total number.
這對你有幫助嗎?
如果list2以與學生相同的順序包含所有總分list1,您可以:
for i in range(len(res):
res[i]['Total marks'] = list2[i]
uj5u.com熱心網友回復:
for dict in res:
dict['Total marks'] = dict[' Final']
此外,您可能希望將數值設為整數/浮點數,而不是字串。
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/448679.html