你知道如何閱讀 PDF 檔案嗎,哪種 mimetype 是 text/html?
我嘗試了下面的代碼段,但 OCR 不起作用,導致此問題“API 呼叫 drive.files.insert 失敗并出現錯誤:文本/html 型別的檔案不支持 OCR”
function extractTextFromPDF(pdfID) {
// PDF File URL
// You can also pull PDFs from Google Drive
var url = "https://drive.google.com/file/d/" pdfID
var blob = UrlFetchApp.fetch(url).getBlob();
var resource = {
title: blob.getName(),
mimeType: blob.getContentType(),
};
// Enable the Advanced Drive API Service
var file = Drive.Files.insert(resource, blob, { ocr: true, ocrLanguage: 'en' });
// Extract Text from PDF file
var doc = DocumentApp.openById(file.id);
var text = doc.getBody().getText();
return text;
}
此外,我曾嘗試將檔案轉換為任何其他格式,如 .csv .css 或文本,但什么時候文本是可怕的、很長的 HTML,我認為內容是加密的。我考慮從提取的 HTML 中拆分資料,但不幸的是,內容不存在或以某種方式加密。
我想要做的是從這個有線 pdf 列印文本,以便稍后將其寫入 Google 表格。你知道我如何閱讀這個檔案嗎?檔案我在這里附上一個 pdf,所以你可以看到我在與什么作斗爭。
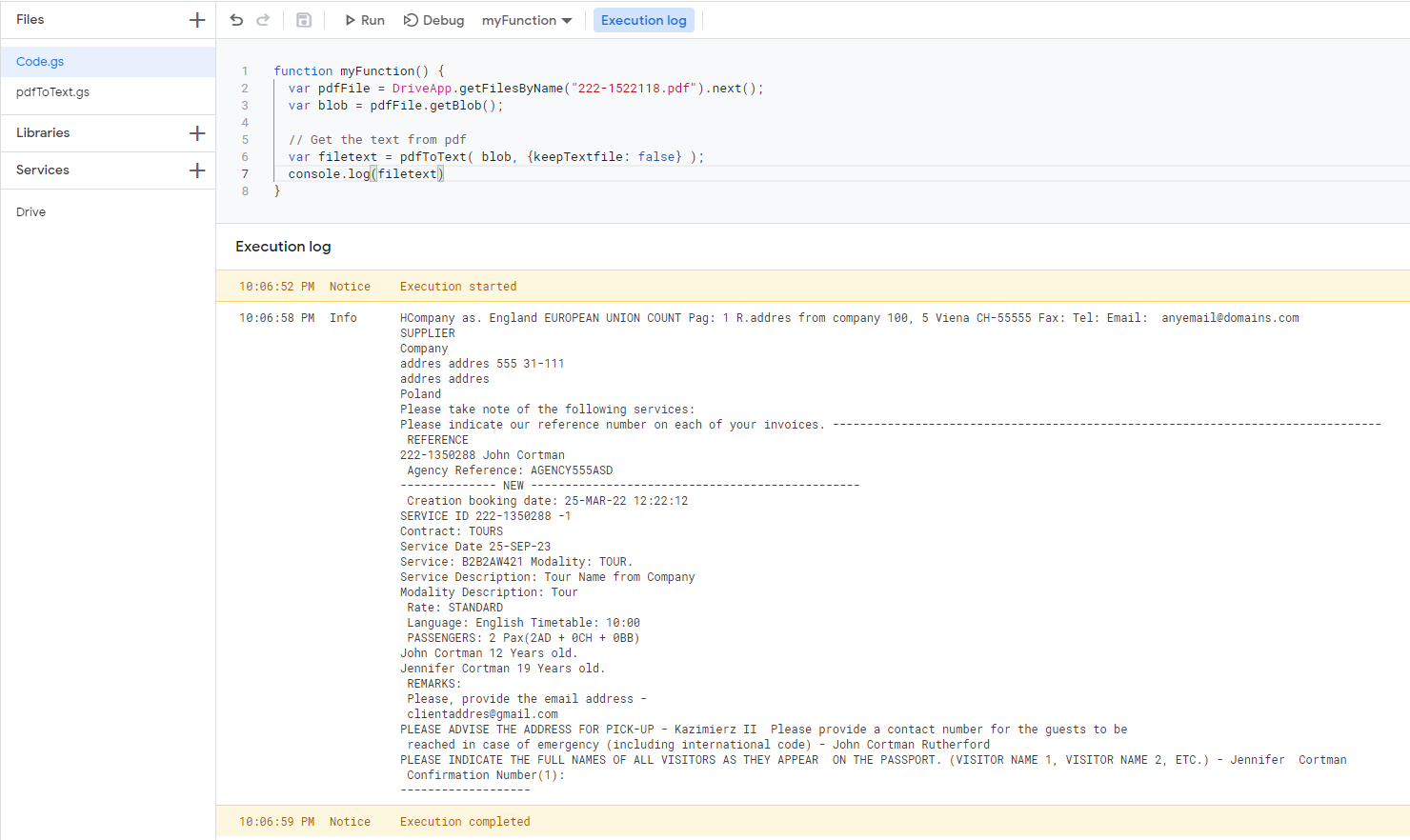
我使用了 Mogsdad 的圖書館pdfToText
參考:在 Google 中從 PDF 中獲取文本
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/448954.html
上一篇:將單頁PDF轉換為影像