我有一個示例資料集。這是:
import pandas as pd
import numpy as np
df = {'Point1': [50,50,50,45,45,35,35], 'Point2': [48,44,30,35,33,34,32], 'Dist': [4,6,2,7,8,3,6]}
df = pd.DataFrame(df)
df
它的輸出在這里:
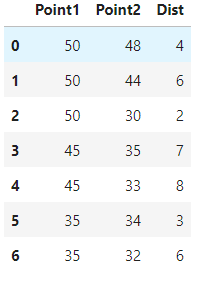
我的目標是找到每組point1的dist值及其條件和point2值。這是我的代碼。(它給出了一個錯誤)
if df['dist'] < 5 :
df1 = df[df['dist'].isin(df.groupby('Point1').max()['Dist'].values)]
else :
df1 = df[df['dist'].isin(df.groupby('Point1').min()['Dist'].values)]
df1
這是預期的輸出:
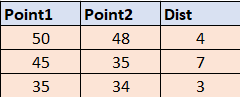
因此,如果存在小于 5 的 Dist 值,我想取這些組中的最大值。如果沒有,我想拿最小的。我希望這很清楚。
uj5u.com熱心網友回復:
IIUC,您想找到最接近 5 的 Dist,并且值低于 5 的優先級。
為此,您可以計算兩列以幫助您按優先級順序對值進行排序并取第一列。這里'cond'首先按≤5排序,然后>5,cond2按到5的絕對距離排序。
thresh = 5
(df
.assign(cond=df['Dist'].gt(thresh),
cond2=df['Dist'].sub(thresh).abs(),
)
.sort_values(by=['cond', 'cond2'])
.groupby('Point1', as_index=False).first()
.drop(columns=['cond', 'cond2'])
)
輸出:
Point1 Point2 Dist
0 35 34 3
1 45 35 7
2 50 48 4
注意。這也是在程序中按 Point1 排序,如果不需要,可以創建一個函式以這種方式對資料框進行排序并按組應用它。讓我知道是否是這種情況
uj5u.com熱心網友回復:
由于您使用的是 pandas DataFrame,因此您可以使用括號語法來過濾資料
在你的情況下:
df[df['Dist']] < 5
關于問題的第二部分,這有點令人困惑,您能否進一步解釋一下“在這些組中取最大值。如果沒有,我想取最小值”
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/456648.html