我有一個excel檔案。它有沒有名稱的列。此列是最后一個命名列的下一個實體。我會在最后一個命名的列之后命名沒有名稱的列,一個計數器自最后一個命名的列以來有多少個空列。
我有這樣的事情:
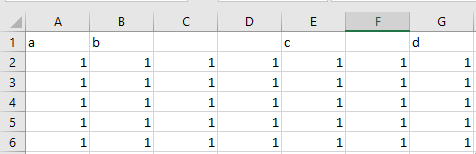
如果我只是正常閱讀 .csv,我會得到:
a b Unnamed: 2 Unnamed: 3 c Unnamed: 5 d
0 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1
2 1 1 1 1 1 1 1
3 1 1 1 1 1 1 1
4 1 1 1 1 1 1 1
因此,我使用 header=None 閱讀,而不是獲得第一行中的列,在那里我可以使用 ffill 來填充它們,就像我希望的那樣。我唯一還想添加的是一個計數器。
我希望我的輸出是這樣的:
a b0 b1 b2 c0 c1 d
0 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1
2 1 1 1 1 1 1 1
3 1 1 1 1 1 1 1
4 1 1 1 1 1 1 1
uj5u.com熱心網友回復:
首先前向填充由Series.maskffill 創建的缺失值,然后添加計數器:
s = df.columns.to_series()
df.columns = s.mask(s.str.startswith('Unnamed')).ffill()
#https://stackoverflow.com/a/61853830/2901002
from collections import defaultdict
renamer = defaultdict()
for column_name in df.columns[df.columns.duplicated(keep=False)].tolist():
if column_name not in renamer:
renamer[column_name] = [column_name '0']
else:
renamer[column_name].append(column_name str(len(renamer[column_name])))
df = df.rename(
columns=lambda column_name: renamer[column_name].pop(0)
if column_name in renamer
else column_name
)
print (df)
a b0 b1 b2 c0 c1 d
0 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1
2 1 1 1 1 1 1 1
3 1 1 1 1 1 1 1
4 1 1 1 1 1 1 1
另一個想法是使用默認的 pandas 函式來洗掉重復的列名稱:
s = df.columns.to_series()
df.columns = s.mask(s.str.startswith('Unnamed')).ffill()
#https://stackoverflow.com/a/43792894/2901002
df.columns = pd.io.parsers.ParserBase({'names':df.columns})._maybe_dedup_names(df.columns)
print (df)
a b b.1 b.2 c c.1 d
0 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1
2 1 1 1 1 1 1 1
3 1 1 1 1 1 1 1
4 1 1 1 1 1 1 1
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/456658.html
上一篇:如何從熊貓行中增加某些列?
下一篇:合并兩個不同的資料框