1 什么是模型攻防
1.1 攻防定義
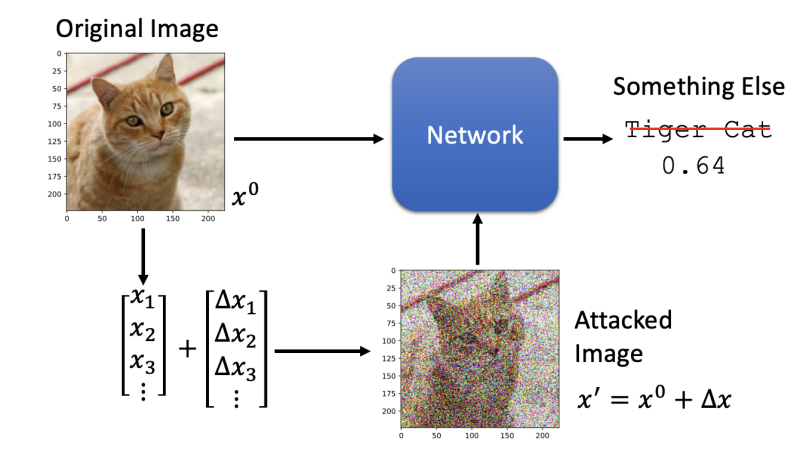
我們在平常的深度學習模型開發中,一般關注的重點在模型指標上,比如ACC、F1、Bleu等,但其實還有另一方面需要注意,那就是模型攻防,特別是在人臉識別等安全領域,什么是模型攻擊(model attack)呢?以圖片分類為例,如下圖,原始圖片經過分類模型,可以正確識別是tiger cat,我們在圖片上加入某些一定分布的噪聲后,模型可能就會把它錯誤識別為其他類別,比如keyboard,
1.2 攻擊條件
模型攻擊必須滿足兩個條件
- 在原始圖片上加入一定噪音,通過模型后,predict和真實label盡量遠,和目標假label盡量近,loss如下
-
- 加入的噪音必須在一定范圍內,使得人類分辨不出來,這個稱為限制constrain,數學表達如下
![]()
1.3 攻擊限制constrain
對于噪音距離定義,有兩種方式
1. L2距離,也就是假樣本和真樣本的均方差,
![]()
2. 最大距離,假樣本和真樣本,差別最大的點
![]()
實際應用中,一般取最大距離,相比L2平均距離和最大距離,最大距離差別過大,容易被人類分辨出來,
1.4 模型攻擊場景
除了視覺領域外,NLP、語音識別均可以做模型攻擊,實際場景中,比如人臉識別,有人做了一副特殊的眼鏡,帶上它后,就會識別為其他人,如下圖

模型攻擊會對業務的安全性造成很嚴重的影響,因此模型防御(model defense)十分關鍵,模型攻擊分為白盒攻擊、黑盒攻擊,了解如何做模型攻擊,有利于掌握模型防御,
2 模型攻擊 model attack
模型攻擊分為白盒攻擊、黑盒攻擊,
2.1 白盒攻擊
白盒攻擊指的是,在知道模型結構和引數的情況下,設計方法進行攻擊,常用的方法仍然是梯度下降,此時我們的神經網路引數是固定的,我們要調整的是樣本輸入x,通過梯度下降來找到最合適的樣本x,同時假樣本必須滿足最大距離限制,模型攻擊的loss可以定義為
![]()
則目標函式為
![]()
常用的方法如下
- FGSM (https://arxiv.org/abs/1412.6572)
- Basic iterative method (https://arxiv.org/abs/1607.02533)
- L-BFGS (https://arxiv.org/abs/1312.6199)
- Deepfool (https://arxiv.org/abs/1511.04599)
- JSMA (https://arxiv.org/abs/1511.07528)
- C&W (https://arxiv.org/abs/1608.04644)
- Elastic net attack (https://arxiv.org/abs/1709.04114)
- Spatially Transformed (https://arxiv.org/abs/1801.02612)
- One Pixel Attack (https://arxiv.org/abs/1710.08864)
以Fast Gradient Sign Method (FGSM)為例,它通過梯度下降的方法,調整樣本x,來優化目標函式,使得上面定義的loss最小,其假樣本的構造方法為,在真實樣本每個點x上,要么加上ε,要么減去ε,如下
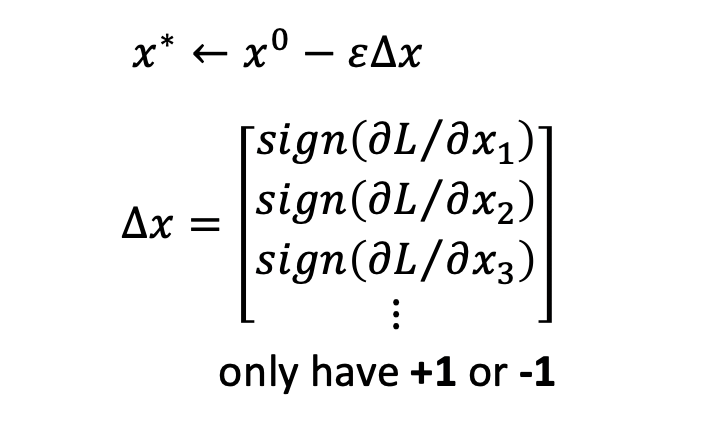
2.2 黑盒攻擊
白盒攻擊方法我們懂了,那我們是不是不公布模型引數,就可以防御了呢,顯然不是,我們還可以進行黑盒攻擊,怎么進行黑盒攻擊呢,我們可以利用資料,自己訓練一個模型,稱為proxy model,然后對這個proxy model進行白盒攻擊,利用得到的樣本來攻擊真實模型,一般效果也不錯,
這兒關鍵問題有兩個
- 怎么得到訓練proxy model的資料,一方面可以利用與此模型任務類似的資料,比如影像分類問題,可以使用ImageNet資料,另一方面,可以利用要攻擊的模型,來構造資料,predict標簽,
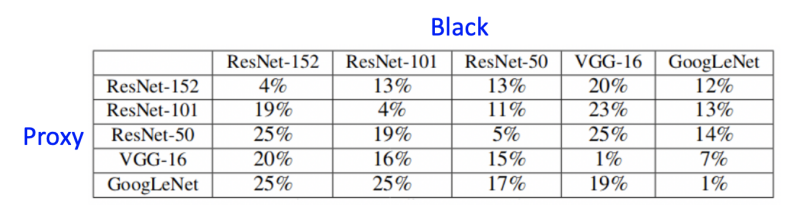
- 怎么知道proxy model的結構,一般來說,同一類任務,即使proxy model和真實model結構不同,效果也OK的,當然proxy model和真實model結構相同,效果會更好,下面是不同分類模型,proxy model構造的假樣本,在真實model上的正確率,有圖可見,兩者模型越接近,模型攻擊效果越好,
3 模型防御
模型防御分為被動防御和主動防御
3.1 被動防御
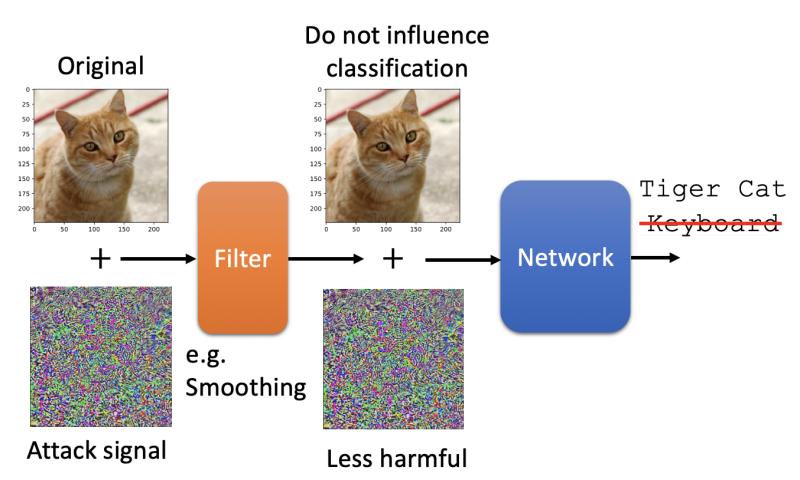
被動防御通過不修改原始模型,來進行防御,主要方法有模型前加入filter,輸入樣本進行padding、伸縮變化等,
在真實模型前加一個filter,filter可以是一些平滑化處理等,通過這個filter,輸入樣本會進行一些變化,從而使得攻擊樣本在模型上失效,
對輸入樣本,進行適當的padding,伸縮變化等,也可以在不影響真實模型predict的情況下,使得攻擊樣本失效,
3.2 主動防御
主動防御思想為,先主動進行模型攻擊,找到可以攻擊的假樣本,然后把他們加入到訓練資料中,重新訓練模型,從而使得模型在這些假樣本上,也能正確predict,這個方法有點像data augment,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/4673.html
標籤:其他
下一篇:帶你通俗理解HTTPS