我有一個如下所示的資料集:
timepoint Nc2g12345_mean Nc2g12345_sd Nc3g15832_mean Nc3g15832_sd Nc3g44800_mean
1 0HR 0.000000000 0.0000000000 0.0008530604 0.000369386 0.0000000000
2 3.5HR 0.015091864 0.0066996647 0.0255918106 0.012939058 0.0096750639
3 8HR 0.225065617 0.0848419107 0.1337172105 0.028238102 0.1190215407
4 264HR 0.004265092 0.0048551997 0.0044785669 0.002306815 0.0034684191
5 720HR 0.001968504 0.0019685039 0.0000000000 0.000000000 0.0003650968
6 216HR 0.000328084 0.0005682581 0.0027724462 0.002884997 0.0023731289
我想創建一個“平均值”值的 ggplot(這些值將由我的 y 軸值表示,由以“_mean”結尾的串列示),誤差條對應于標準偏差(在以“_sd”結尾的列中表示) . 我想(沿 x 軸)按列標題的前 9 個字符(這些是基因名稱)進行分組。我想根據時間點為我的圖著色。
現在的資料結構對于繪圖來說不是最佳的。有哪些聰明的方法可以將資料整理成更可行的 ggplot 格式?一個 tidyverse 解決方案將是理想的。
uj5u.com熱心網友回復:
這個怎么樣:
library(tidyverse)
dat <- tibble::tribble(~timepoint, ~Nc2g12345_mean, ~Nc2g12345_sd, ~Nc3g15832_mean, ~Nc3g15832_sd, ~Nc3g44800_mean,
"0HR", 0.000000000, 0.0000000000, 0.0008530604, 0.000369386, 0.0000000000,
"3.5HR", 0.015091864, 0.0066996647, 0.0255918106, 0.012939058, 0.0096750639,
"8HR", 0.225065617, 0.0848419107, 0.1337172105, 0.028238102, 0.1190215407,
"264HR", 0.004265092, 0.0048551997, 0.0044785669, 0.002306815, 0.0034684191,
"720HR", 0.001968504, 0.0019685039, 0.0000000000, 0.000000000, 0.0003650968,
"216HR", 0.000328084, 0.0005682581, 0.0027724462, 0.002884997, 0.0023731289)
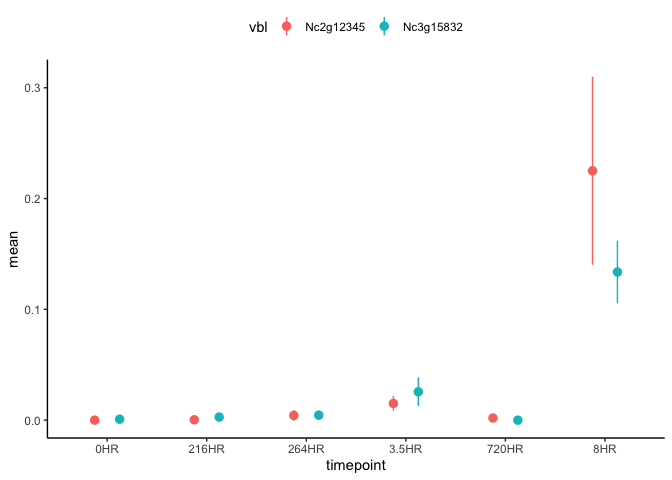
dat %>% pivot_longer(-timepoint, names_pattern="(.*)_(.*)",
names_to = c("vbl", ".value")) %>%
filter(!is.na(sd)) %>%
ggplot(aes(x=timepoint, y=mean, ymin = mean -sd, ymax = mean sd, colour=vbl))
geom_pointrange(position=position_dodge(width=.5))
theme_classic()
theme(legend.position="top")
由reprex 包(v2.0.1)創建于 2022-06-05
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/485858.html