我想對 OCR 的影像進行二值化。我附上了將影像資料作為輸入并回傳二進制影像的代碼,此方法適用于大多數影像。
例如,
- 原來的:

- 結果:
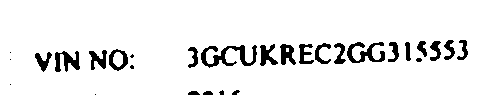
def preprocessing(image):
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blured1 = cv2.medianBlur(image, 3)
blured2 = cv2.medianBlur(image, 51)
divided = np.ma.divide(blured1, blured2).data
normed = np.uint8(255 * divided / divided.max())
th, image = cv2.threshold(normed, 100, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)
image = cv2.erode(image, np.ones((3, 3), np.uint8))
image = cv2.dilate(image, np.ones((3, 3), np.uint8))
return image
但是當我在下面附加的影像上應用相同的方法時,它不會按預期作業。它應該提供具有用于 tesseract 輸入的可讀文本的影像。
- 原圖1:

- 預處理影像:

- 原始影像 2:

- 預處理影像:

uj5u.com熱心網友回復:
您可能應該嘗試自己拆卸影像。我認為 Bradley-Roth 演算法(Bradley-Roth Adaptive Thresholding Algorithm - How do I get better performance?)可以幫助您稍作修改 - 如果鄰域比 128 亮,則突出顯示較暗的鄰域,如果鄰域是比 128 暗,那么亮的部分會突出顯示。
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/489339.html