我正在嘗試使用 selenium 對“https://uidb-pbs.tubitak.gov.tr/#tabs-3”網站進行網頁抓取,但我無法從網站獲取表格或表格專案的文本。我正在嘗試這樣做:
PATH = "C:\Program Files (x86)\chromedriver.exe"
tubitak_ua_driver = webdriver.Chrome(PATH)
tubitak_ua_driver.get("https://uidb-pbs.tubitak.gov.tr/#tabs-3")
project_table = tubitak_ua_driver.find_element_by_xpath('//*[@id="programCagriListTable"]/tbody')
print(project_table.text)
這段代碼沒有給出任何錯誤,但也沒有給出文本,當我嘗試獲取驅動程式的內部 html 時,我從網站獲得了第一個選項卡的 innerHTML。問題是什么?
uj5u.com熱心網友回復:
問:為什么您的代碼不起作用?
該網站設計不佳,網頁中有多個具有相同 ID 的表格,您的代碼獲取第一個內部沒有任何內容的表格。因此,您得到的是空字串。
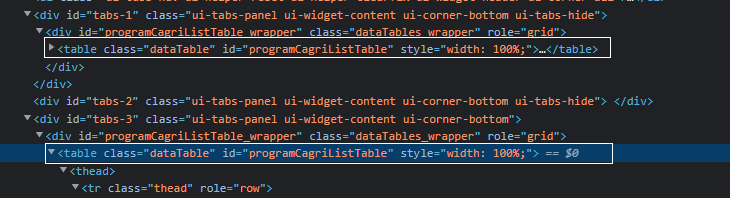
問:我們如何獲得所需的表。
所需的表存在于網頁中查詢 ID 的第二個實體中。獲取回傳元素的第二個實體,然后您可以獲取文本或將整個表加載到 pandas 資料框中。
table = driver.find_elements_by_xpath('//*[@id="programCagriListTable"]/tbody')
print(table[1].text)
uj5u.com熱心網友回復:
問題是; 此 xpath '//*[@id="programCagriListTable"]/tbody' 有兩個元素,因此您需要指定所需的元素。例如:'(//*[@id="programCagriListTable"]/tbody)[1]'
但是如果你想要一個元素的文本,你必須去元素的文本是
(//table[@id="programCagriListTable"])[2]//descendant::td,并用 for 來查看
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/490635.html
上一篇:Neo4J-有沒有辦法在一個查詢中加載多個子查詢,如LOAD...CREATE..LOAD..CREATE..LOAD...(用于測驗)
下一篇:如何用同一類刮掉另一個跨度