我有一些帶有字幕/文本的影像,我想從圖片中洗掉所有內容,但要讓文本清晰,(最重要的是文本需要清晰且良好,以便任何 ocr 程式都可以讀取它)。
- 在原始影像(1.png)中,文本應該是白色的,但這并不意味著它是 RGB:255,255,255,因此它因像素而異。所以這是我無法找到獲取文本的方法的問題。
也許我需要將 rgb 轉換為不同的東西,也許是任何帶有百分比或 idk 的值
我嘗試使用以下代碼將影像 1.png 轉換為 2.png,這是結果,但它們還不夠好
1.png:

2.png
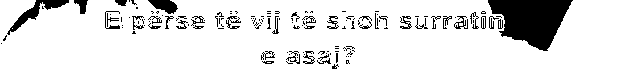
RGB_min=[180,180,180]
RGB_max=[245,245,245]
def level(img):
copy = img.copy()
for x in range(img.size[0]):
for y in range(img.size[1]):
pxl = list(copy.getpixel((x, y)))
# if pxl[0] < 220 and pxl[1] < 220:
if (pxl[0] < RGB_min[0] and pxl[1] < RGB_min[1] ) or (pxl[0] > RGB_max[0] or pxl[1] >RGB_max[1]) :
pxl[0] = 255
pxl[1] = 255
pxl[2] = 255
else:
pxl[0] = 0
pxl[1] = 0
pxl[2] = 0
copy.putpixel((x, y), tuple(pxl))
return copy
image = Image.open('1.png')
leveled = level(image)
leveled.save('2.png')
如果放大,您可以在這里看到像素在文本中的情況。
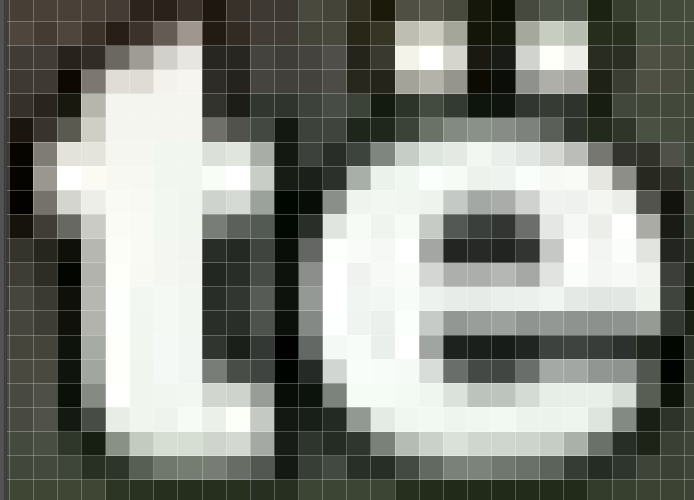
uj5u.com熱心網友回復:

這是撰寫point()處理復合邏輯的函式的一種可能更直觀的方法:
#!/usr/bin/env python3
from PIL import Image
# Build a linear gradient 0..255
im = Image.linear_gradient('L')
# Save how it looks initially just for debug
im.save('DEBUG-start.png')
# Make all pixels between 180..220 black, leaving others as they were
res = im.point(lambda p: 0 if p>180 and p<220 else p)
# Save result
res.save('result.png')
這是開始影像:

處理后的影像:

轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/493563.html