我正在嘗試從本質上是一個開放資料源的 XML 檔案中獲取條目串列。
編輯:
如果我使用
=IMPORTXML(B1;”/*”)
所有內容都被塞進一個單元格。B1 是存盤網站 URL 的欄位。我在單獨的列中需要的是標題、型別、城市和媒體物件。網址:
http://meta.et4.de/rest.ashx/search/?experience=open-data-niedersachsen-tourismus&licensekey=VdEVEni8FhWA58234fIbjwk0bAysCkHhvXXTnC5b&type=POI&latitude=52.3744779&longitude=9.7385532&distance=30000&template=ET2014A_LIGHT_MULTI.xml
期待任何想法,提示和答案。問候
uj5u.com熱心網友回復:
使用 importxml 和 xpath:
該站點使用命名空間,因此請使用 local-name()
//*[local-name() ='title']
//*[local-name() ='type']
//*[local-name() ='city']
//*[local-name() ='media_objects']
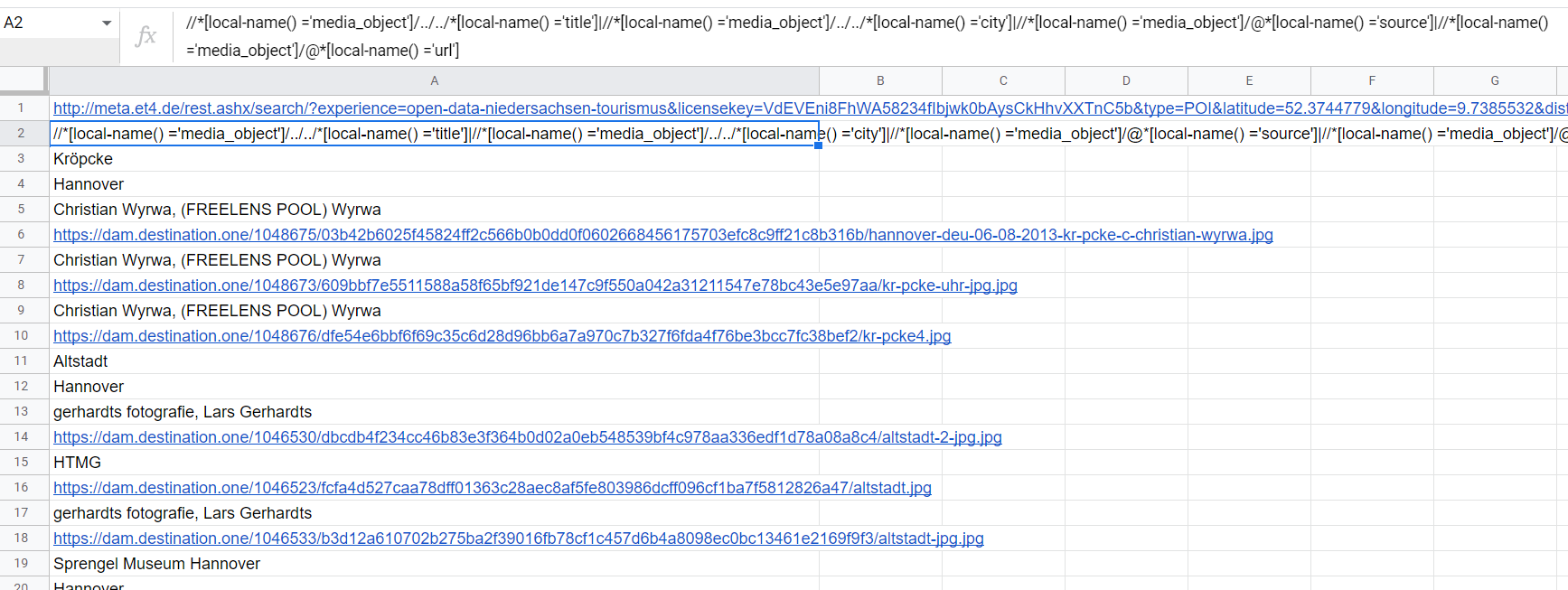
一個復雜的組合 title/cities/media_object (/.. 允許獲得父母)
//*[local-name() ='media_object']/../../*[local-name() ='title']|//*[local-name() ='media_object']/../../*[local-name() ='city']|//*[local-name() ='media_object']/@*[local-name() ='source']|//*[local-name() ='media_object']/@*[local-name() ='url']
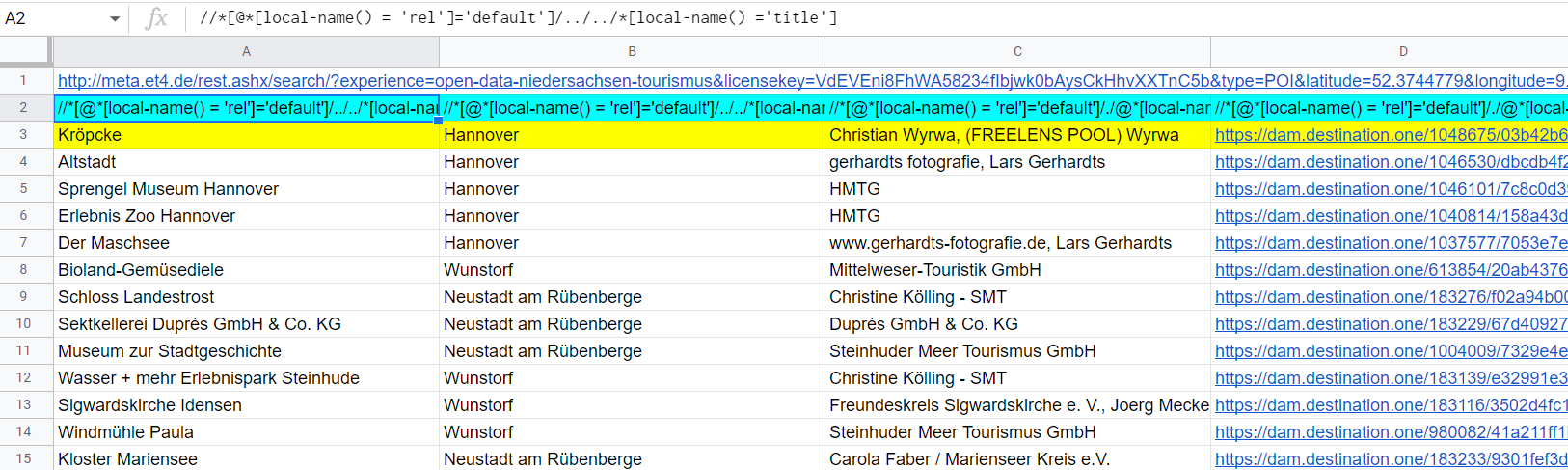
對于默認媒體,請使用這些 xpath
//*[@*[local-name() = 'rel']='default']/../../*[local-name() ='title']
//*[@*[local-name() = 'rel']='default']/../../*[local-name() ='city']
//*[@*[local-name() = 'rel']='default']/./@*[local-name() ='source']
//*[@*[local-name() = 'rel']='default']/./@*[local-name() ='url']
uj5u.com熱心網友回復:
如果要獲取該頁面的標題,請使用:
=IMPORTXML(B1,"//title", "en_US")
其中顯示 - 對于您的頁面:
興趣點
請參閱此處的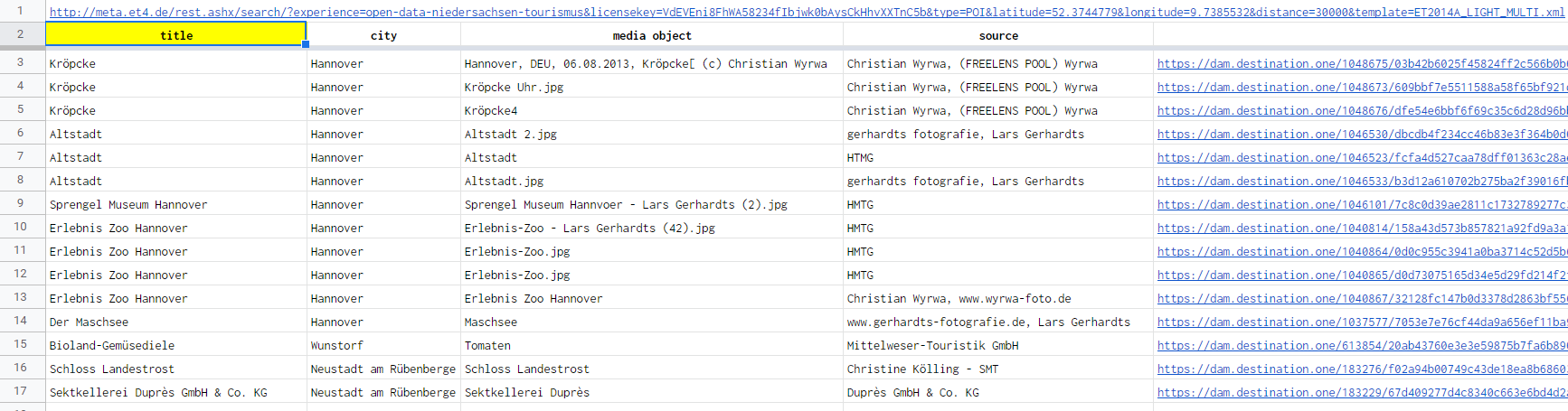
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/496026.html