訊息佇列使用場景
訊息佇列中間件是分布式系統中重要的組件,主要解決應用耦合,異步訊息,削峰填谷等問題,實作高性能、高可用、可伸縮和最終一致性架構,
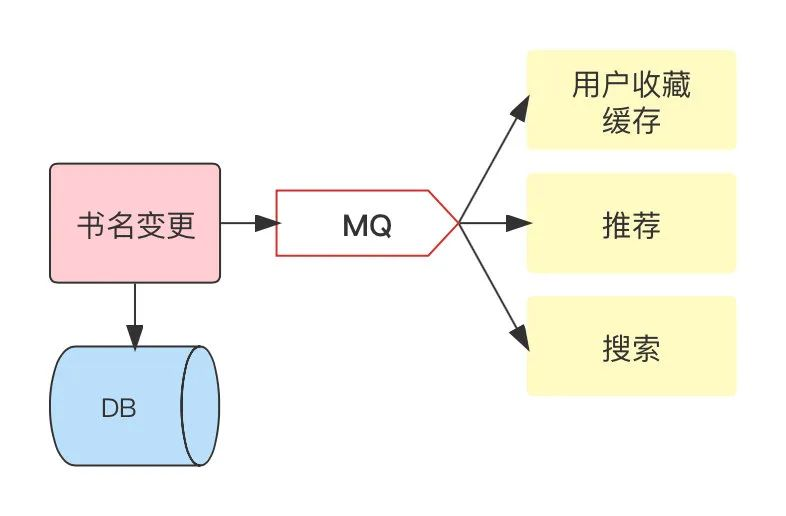
解耦:多個服務監聽、處理同一條訊息,避免多次 rpc 呼叫,
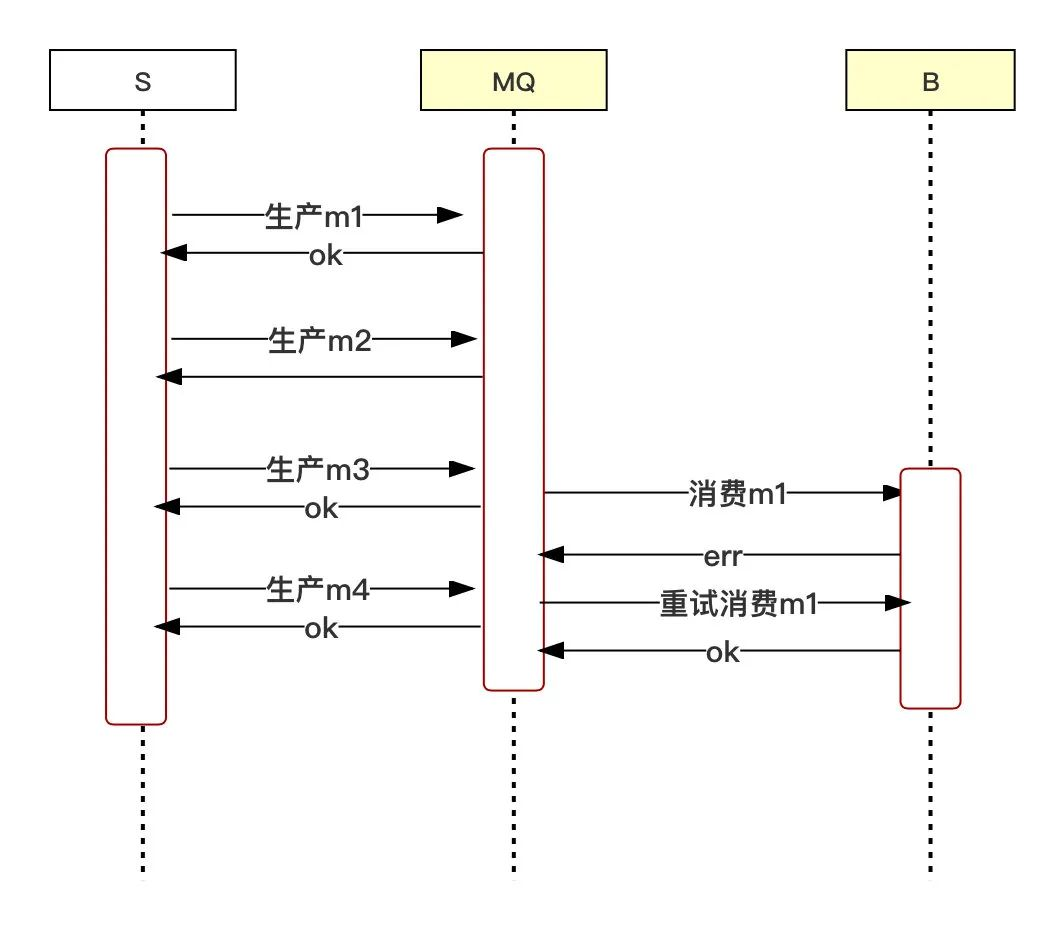
異步訊息:訊息發布者不用等待訊息處理的的結果,
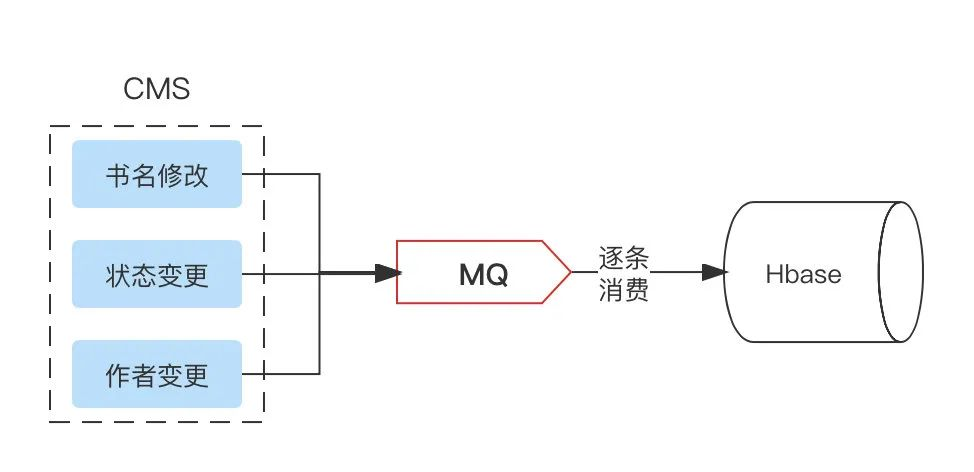
削峰填谷:較大流量、寫入場景,為下游 I/O 服務抗流量,當然大流量下就需要使用其他方案了,
-
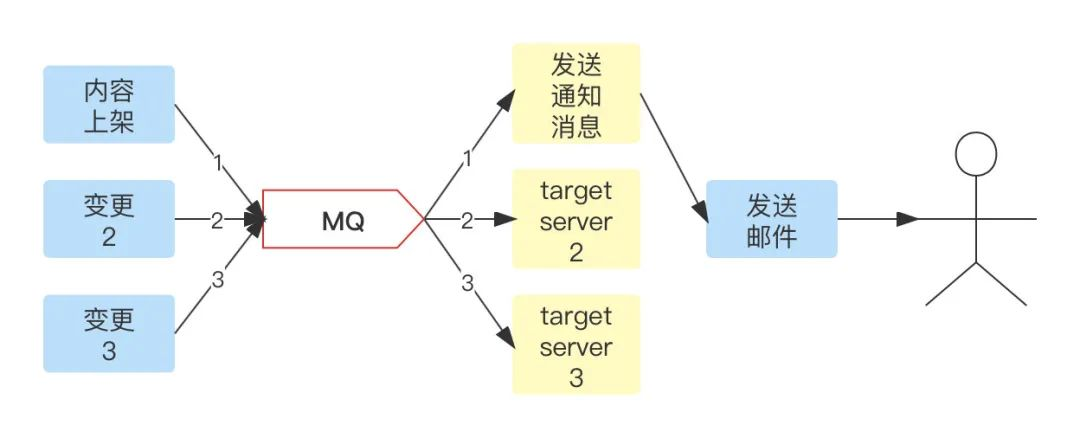
訊息驅動框架:在事件總線中,服務通過監聽事件訊息驅動服務完成相應動作,
訊息佇列模式
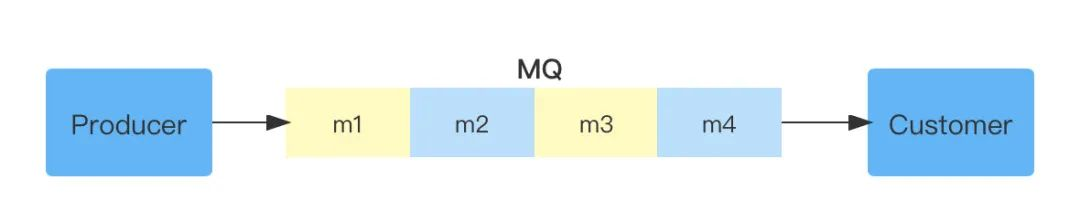
點對點模式,不可重復消費
多個生產者可以向同一個訊息佇列發送訊息,一個訊息在被一個訊息者消費成功后,這條訊息會被移除,其他消費者無法處理該訊息,如果消費者處理一個訊息失敗了,那么這條訊息會重新被消費,
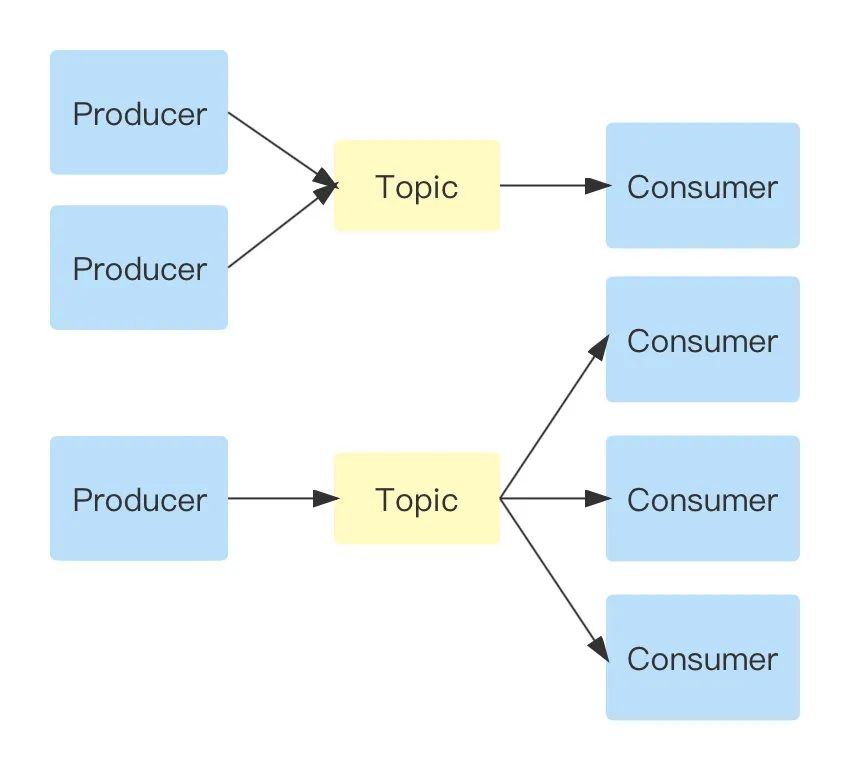
發布/訂閱模式
發布訂閱模式需要進行注冊、訂閱,根據注冊消費對應的訊息,多個生產者可以將訊息寫到同一個 Topic 中,多種訊息可以被同一個消費者消費,一個生產者生產的訊息,同樣也可以被多個消費者消費,只要他們進行過訊息訂閱,
選型參考
-
訊息順序:發送到佇列的訊息,消費時是否可以保證消費的順序;
-
伸縮:當訊息佇列性能有問題,比如消費太慢,是否可以快速支持擴容;當消費佇列過多,浪費系統資源,是否可以支持縮容,
-
訊息留存:訊息消費成功后,是否還會繼續保留在訊息佇列;
-
容錯性:當一條訊息消費失敗后,是否有一些機制,保證這條訊息一定能成功,比如異步第三方退款訊息,需要保證這條訊息消費掉,才能確定給用戶退款成功,所以必須保證這條訊息消費成功的準確性;
-
訊息可靠性:是否會存在丟訊息的情況,比如有 A/B 兩個訊息,最后只有 B 訊息能消費,A 訊息丟失;
-
訊息時序:主要包括“訊息存活時間”和“延遲訊息”;
-
吞吐量:支持的最高并發數;
-
訊息路由:根據路由規則,只訂閱匹配路由規則的訊息,比如有 A/B 兩者規則的訊息,消費者可以只訂閱 A 訊息,B 訊息不會消費,
Kafka
Kafka 是由 Apache 軟體基金會開發的一個開源流處理平臺,由 Scala 和 Java 撰寫,該專案的目標是為處理實時資料提供一個統一、高吞吐、低延遲的平臺,其持久化層本質上是一個“按照分布式事務日志架構的大規模發布/訂閱訊息佇列”,這使它作為企業級基礎設施來處理流式資料非常有價值,(維基百科)
基本術語
Producer:訊息生產者,一般情況下,一條訊息會被發送到特定的主題上,通常情況下,寫入的訊息會通過輪詢將訊息寫入各磁區,生產者也可以通過設定訊息 key 值將訊息寫入指定磁區,寫入磁區的資料越均勻 Kafka 的性能才能更好發揮,
Topic:Topic 是個抽象的虛擬概念,一個集群可以有多個 Topic,作為一類訊息的標識,一個生產者將訊息發送到 topic,消費者通過訂閱 Topic 獲取磁區訊息,
Partition:Partition 是個物理概念,一個 Topic 對應一個或多個 Partition,新訊息會以追加的方式寫入磁區里,在同一個 Partition 里訊息是有序的,Kafka 通過磁區,實作訊息的冗余和伸縮性,以及支持物理上的并發讀、寫,大大提高了吞吐量,
Replicas:一個 Partition 有多個 Replicas 副本,這些副本保存在 broker,每個 broker 存盤著成百上千個不同主題和磁區的副本,存盤的內容分為兩種:master 副本,每個 Partition 都有一個 master 副本,所有內容的寫入和消費都會經過 master 副本;follower 副本不處理任何客戶端的請求,只同步 master 的內容進行復制,如果 master 發生了例外,很快會有一個 follower 成為新的 master,
Consumer:訊息讀取者,消費者訂閱主題,并按照一定順序讀取訊息,Kafka 保證每個磁區只能被一個消費者使用,
Offset:偏移量是一種元資料,是不斷遞增的整數,在訊息寫入時 Kafka 會把它添加到訊息里,在磁區內偏移量是唯一的,消費程序中,會將最后讀取的偏移量存盤在 Kafka 中,消費者關閉偏移量不會丟失,重啟會繼續從上次位置開始消費,
Broker:獨立的 Kafka 服務器,一個 Topic 有 N 個 Partition,一個集群有 N 個 Broker,那么每個 Broker 都會存盤一個這個 Topic 的 Partition,如果某 topic 有 N 個 partition,集群有(N+M)個 broker,那么其中有 N 個 broker 存盤該 topic 的一個 partition,剩下的 M 個 broker 不存盤該 topic 的 partition 資料,如果某 topic 有 N 個 partition,集群中 broker 數目少于 N 個,那么一個 broker 存盤該 topic 的一個或多個 partition,在實際生產環境中,盡量避免這種情況的發生,這種情況容易導致 Kafka 集群資料不均衡,
系統框架
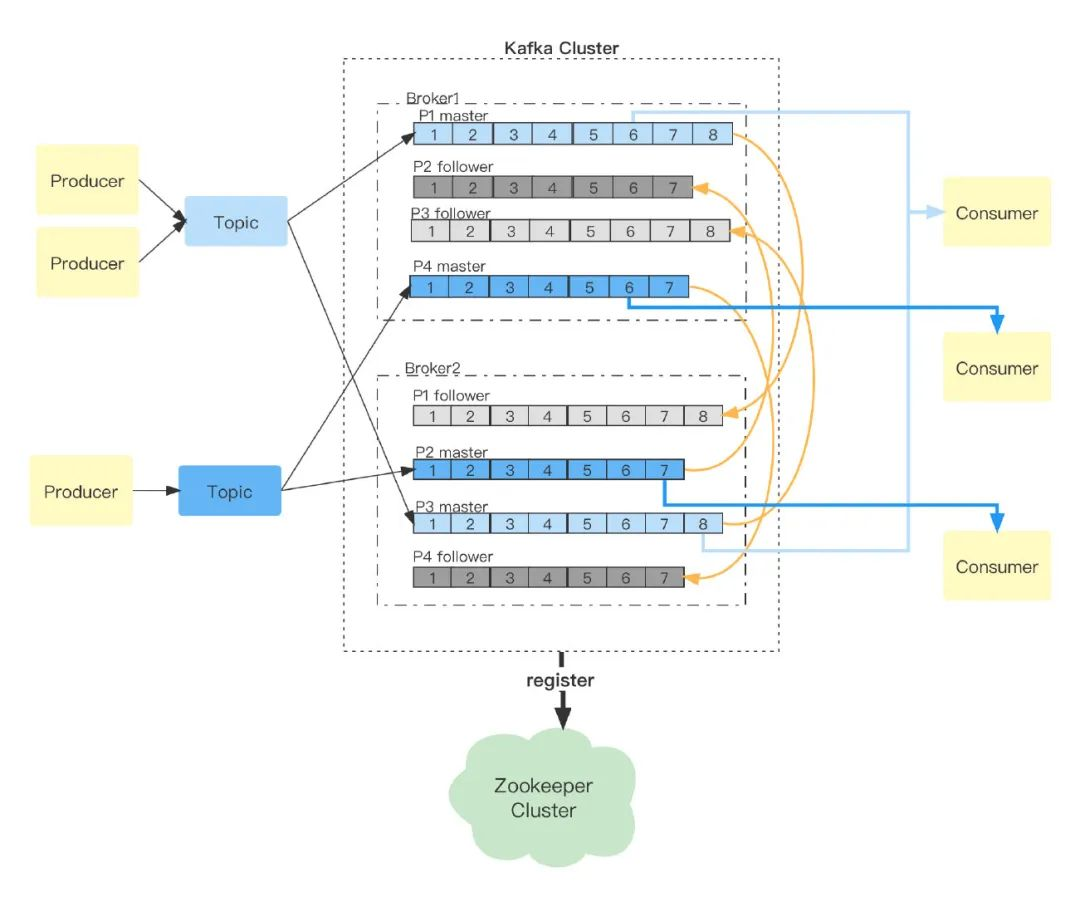
第一個 topic 有兩個生產,新訊息被寫入到 partition 1 或者 partition 2,兩個磁區在 broker1、broker2 都有備份,有新訊息寫入后,兩個 follower 磁區會從兩個 master 磁區同步變更,對應的 consumer 會從兩個 master 磁區根據現在 offset 獲取訊息,并更新 offset,第二個 topic 只有一個生產者,同樣對應兩個 partition,分散在 Kafka 集群的兩個 broker 上,有新訊息寫入,兩個 follower 磁區會同步 master 變更,兩個 Consumer 分別從不同的 master 磁區獲取訊息,
優點
高吞吐量、低延遲:kafka 每秒可以處理幾十萬條訊息,它的延遲最低只有幾毫秒;
可擴展性:kafka 集群支持熱擴展;
持久性、可靠性:訊息被持久化到本地磁盤,并且支持資料備份防止資料丟失;
容錯性:允許集群中節點故障,一個資料多個副本,少數機器宕機,不會丟失資料;
高并發:支持數千個客戶端同時讀寫,
缺點
磁區有序:僅在同一磁區內保證有序,無法實作全域有序;
無延時訊息:消費順序是按照寫入時的順序,不支持延時訊息
重復消費:消費系統宕機、重啟導致 offset 未提交;
Rebalance:Rebalance 的程序中 consumer group 下的所有消費者實體都會停止作業,等待 Rebalance 程序完成,
使用場景
日志收集:大量的日志訊息先寫入 kafka,資料服務通過消費 kafka 訊息將資料落地;
訊息系統:解耦生產者和消費者、快取訊息等;
用戶活動跟蹤:kafka 經常被用來記錄 web 用戶或者 app 用戶的各種活動,如瀏覽網頁、搜索、點擊等活動,這些活動資訊被各個服務器發布到 kafka 的 topic 中,然后消費者通過訂閱這些 topic 來做實時的監控分析,亦可保存到資料庫;
運營指標:記錄運營、監控資料,包括收集各種分布式應用的資料,生產各種操作的集中反饋,比如報警和報告;
流式處理:比如 spark streaming,
RabbitMQ
RabbitMQ 是實作了高級訊息佇列協議(AMQP)的開源訊息代理軟體(亦稱面向訊息的中間件(英語:Message-oriented middleware),RabbitMQ 服務器是用 Erlang 語言撰寫的,而群集和故障轉移是構建在開放電信平臺框架上的,所有主要的編程語言均有與代理介面通訊的客戶端函式庫,(維基百科)
基本術語
Broker:接收客戶端鏈接物體,實作 AMQP 訊息佇列和路由功能;
Virtual Host:是一個虛擬概念,權限控制的最小單位,一個 Virtual Host 里包含多個 Exchange 和 Queue;
Exchange:接收訊息生產者的訊息并將訊息轉發到佇列,發送訊息時根據不同 ExchangeType 的決定路由規則,ExchangeType 常用的有:direct、fanout 和 topic 三種;
Message Queue:訊息佇列,存盤為被消費的訊息;
Message:由 Header 和 Body 組成,Header 是生產者添加的各種屬性,包含 Message 是否持久化、哪個 MessageQueue 接收、優先級,Body 是具體的訊息內容;
Binding:Binding 連接起了 Exchange 和 Message Queue,在服務器運行時,會生成一張路由表,這張路由表上記錄著 MessageQueue 的條件和 BindingKey 值,當 Exchange 收到訊息后,會決議訊息中的 Header 得到 BindingKey,并根據路由表和 ExchangeType 將訊息發送到對應的 MessageQueue,最終的匹配模式是由 ExchangeType 決定;
Connection:在 Broker 和客戶端之間的 TCP 連接;
Channel:信道,Broker 和客戶端只有 tcp 連接是不能發送訊息的,必須創建信道,AMQP 協議規定只有通過 Channel 才能執行 AMQP 命令,一個 Connection 可以包含多個 Channel,之所以需要建立 Channel,是因為每個 TCP 連接都是很寶貴的,如果每個客戶端、每個執行緒都需要和 Broker 互動,都需要維護一個 TCP 連接的話是機器耗費資源的,一般建議共享 Connection,RabbitMQ 不建議客戶端執行緒之前共享 Channel,至少保證同一 Channel 發小訊息是穿行的;
Command:AMQP 命令,客戶端通過 Command 來完成和 AMQP 服務器的互動,
系統框架
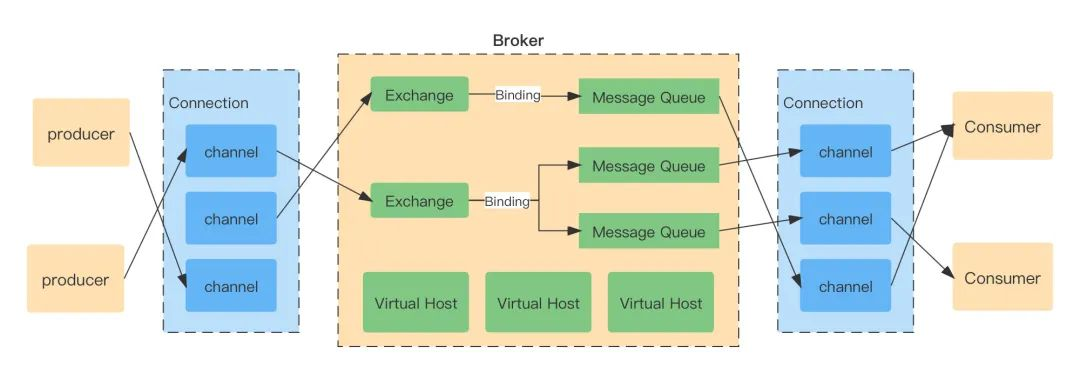
一條 Message 經過信道到達對應的 Exchange,Exchange 收到訊息后決議出訊息 Header 內容,獲取訊息 BindingKey 并根據 Binding 和 ExchangeType 將訊息轉發到對應的 MessageQueue,最后通過 Connection 將訊息傳送的客戶端,
ExchangeType
Direct:精確匹配
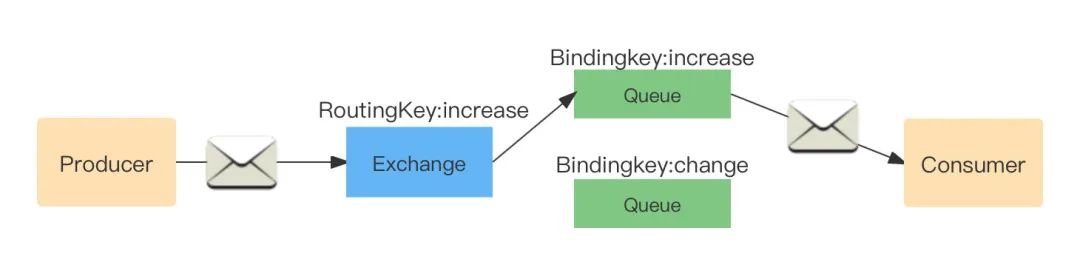
- 只有 RoutingKey 和 BindingKey 完全匹配的時候,訊息佇列才可以獲取訊息;
- Broker 默認提供一個 Exchange,型別是 Direct 名字是空字串,系結到所有的 Queue(這里通過 Queue 名字來區分),
Fanout:訂閱、廣播
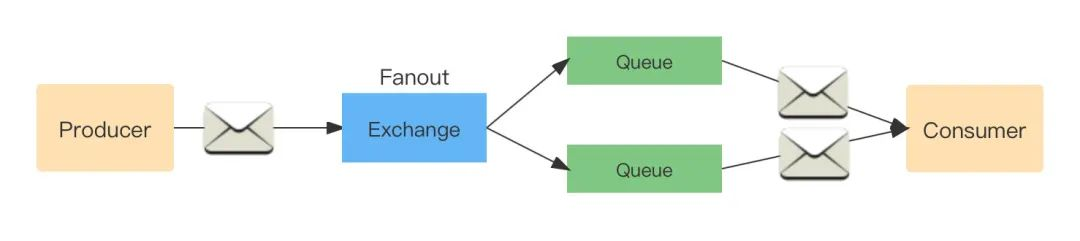
- 這個模式會將訊息轉發到所有的路由的 Queue 中
Topic:通配符模式
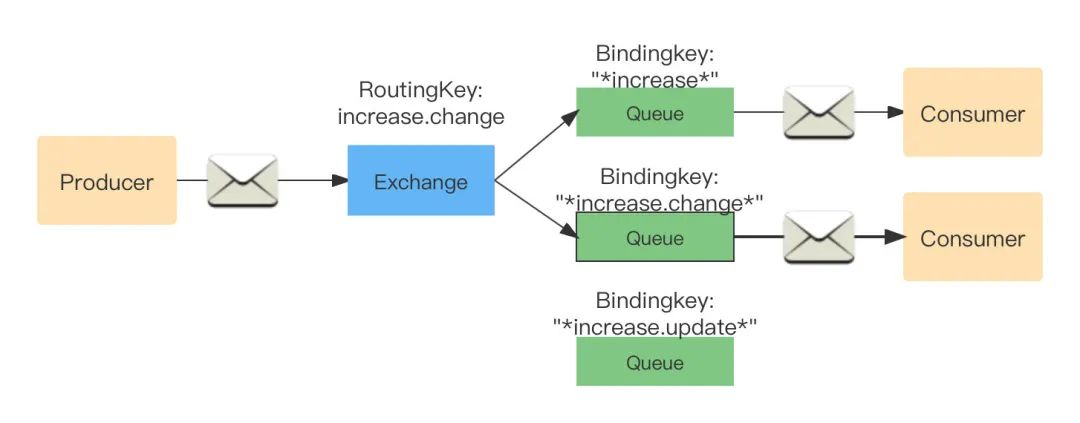
- RoutingKey 為一個句點號“. ”分隔的字串(將被句點號“. ”分隔開的每一段獨立的字串稱為一個單詞),如“quick.orange.rabbit”,BindingKey 與 RoutingKey 一樣;
- Bindingkey 中的兩個特殊字符"#"和“_”用于模糊匹配,“#”用于匹配多個單次,“_”用來匹配單個單詞(包含零個),
優點
- 基于 AMQP 協議:除了 Qpid,RabbitMQ 是唯一一個實作了 AMQP 標準的訊息服務器;
- 健壯、穩定、易用;
- 社區活躍,檔案完善;
- 支持定時訊息;
- 可插入的身份驗證,授權,支持 TLS 和 LDAP;
- 支持根據訊息標識查詢訊息,也支持根據訊息內容查詢訊息,
缺點
- erlang 開發原始碼難懂,不利于做二次開發和維護;
- 介面和協議復雜,學習和維護成本較高,
總結
- erlang 有并發優勢,性能較好,雖然原始碼復雜,但是社區活躍度高,可以解決開發中遇到的問題;
- 業務流量不大的話可以選擇功能比較完備的 RabbitMQ,
Pulsar
Apache Pulsar 是 Apache 軟體基金會頂級專案,是下一代云原生分布式訊息流平臺,集訊息、存盤、輕量化函式式計算為一體,采用計算與存盤分離架構設計,支持多租戶、持久化存盤、多機房跨區域資料復制,具有強一致性、高吞吐、低延時及高可擴展性等流資料存盤特性,被看作是云原生時代實時訊息流傳輸、存盤和計算最佳解決方案,Pulsar 是一個 pub-sub (發布-訂閱)模型的訊息佇列系統,(百科)
基本術語
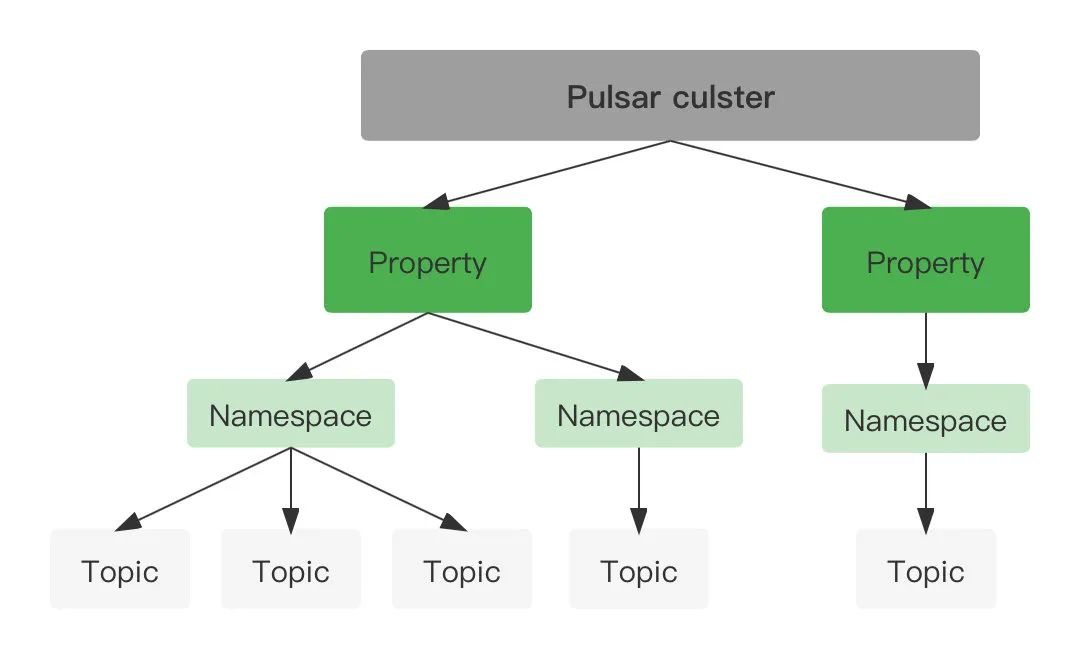
Property:代表租戶,每個 property 都可以代表一個團隊、一個功能、一個產品線,一個 property 可包含多個 namesapce,多租戶是一種資源隔離手段,可以提高資源利用率;
Namespace:Pulsar 的基本管理單元,在 namaspace 級別可設定權限、訊息 TTL、Retention 策略等,一個 namaspace 里的所有 topic 都繼承相同的設定,命名空間分為兩種:本地命名空間,只在集群內可見、全域命名空間對多個集群可見集群命名空間;
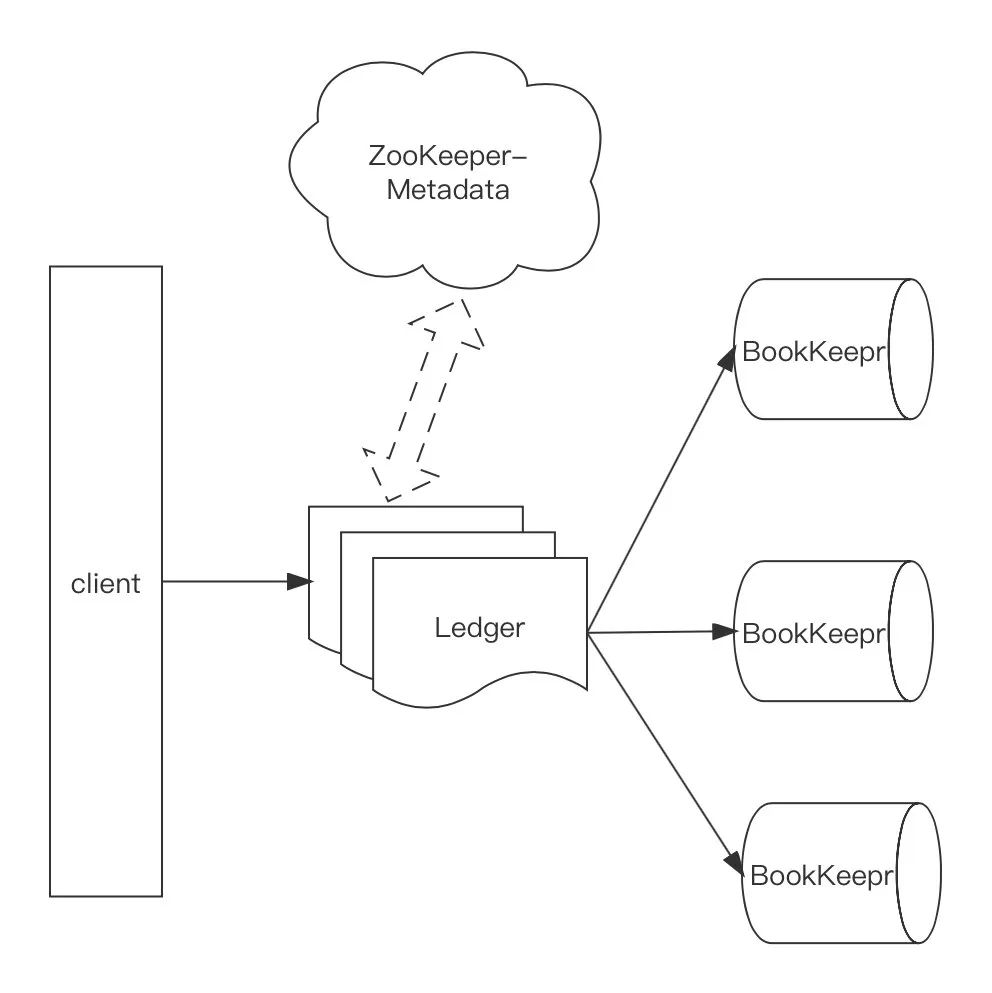
Producer:資料生產方,負責創建訊息并將訊息投遞到 Pulsar 中;
Consumer:資料消費方,連接到 Pulsar 接收訊息并進行相應的處理;
Broker:無狀態 Proxy 服務,負責接收訊息、傳遞訊息、集群負載均衡等操作,它對 client 屏蔽了服務端讀寫流程的復雜性,是保證資料一致性與資料負載均衡的重要角色,Broker 不會持久化保存元資料,可以擴容但不能縮容;
BookKeeper:有狀態,負責持久化存盤訊息,當集群擴容時,Pulsar 會在新增 BookKeeper 和 Segment(即 Bookeeper 的 Ledger),不需要像 kafka 一樣在擴容時進行 Rebalance,擴容結果是 Fragments 跨多個 Bookies 以帶狀分布,同一個 Ledger 的 Fragments 分布在多個 Bookie 上,導致讀取和寫入會在多個 Bookies 之間跳躍;
ZooKeeper:存盤 Pulsar 、 BookKeeper 的元資料,集群配置等資訊,負責集群間的協調、服務發現等;
Topic:用作從 producer 到 consumer 傳輸訊息,Pulsar 在 Topic 級別擁有一個 leader Broker,稱之為擁有 Topic 的所有權,針對該 Topic 所有的 R/W 都經過該 Broker 完成,Topic 的 Ledger 和 Fragment 之間映射關系等元資料存盤在 Zookeeper 中,Pulsar Broker 需要實時跟蹤這些關系進行讀寫流程;
Ledger:即 Segment,Pulsar 底層資料以 Ledger 的形式存盤在 BookKeeper 上,是 Pulsar 洗掉的最小單位;
Fragment :每個 Ledger 由若干 Fragment 組成,
系統框架
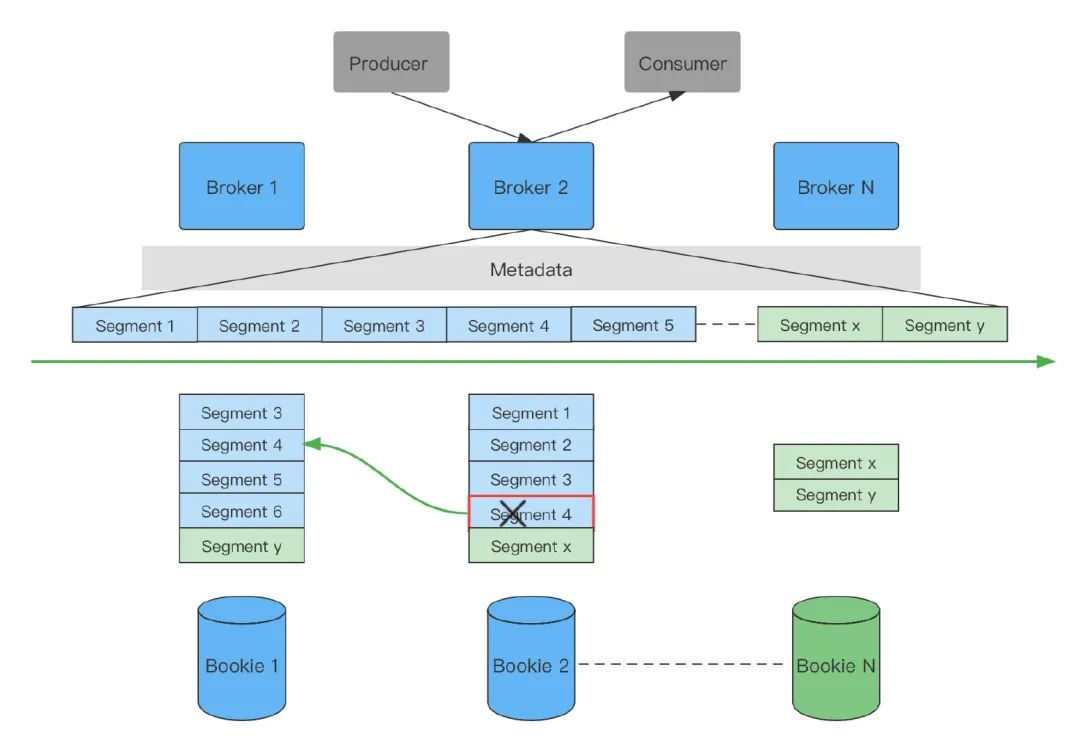
上面框架圖分別演示了擴容、故障轉移兩種情況,擴容:因業務量增大擴容新增 Bookie N,后續寫入的資料 segment x、segment y 寫入新增 Bookie 中,為保持均衡擴容結果如上圖綠色模塊所示,故障轉移:Bookie 2 的 segment 4 發生故障,Pulasr 的 Topic 會立馬從新選擇 Bookie 1 作為處理讀寫的服務,
Broker 是無狀態的服務,只服務資料計算不存盤,所以 Pulsar 可以認為是一種基于 Proxy 的分布式系統,
優點
- 靈活擴容
- 無縫故障恢復
- 支持延時訊息
- 內置的復制功能,用于跨地域復制如災備
- 支持兩種消費模型:流(獨享模式)、佇列(共享模式)
RocketMQ
RocketMQ 是一個分布式訊息和流資料平臺,具有低延遲、高性能、高可靠性、萬億級容量和靈活的可擴展性,RocketMQ 是 2012 年阿里巴巴開源的第三代分布式訊息中間件,(維基百科)
基本術語
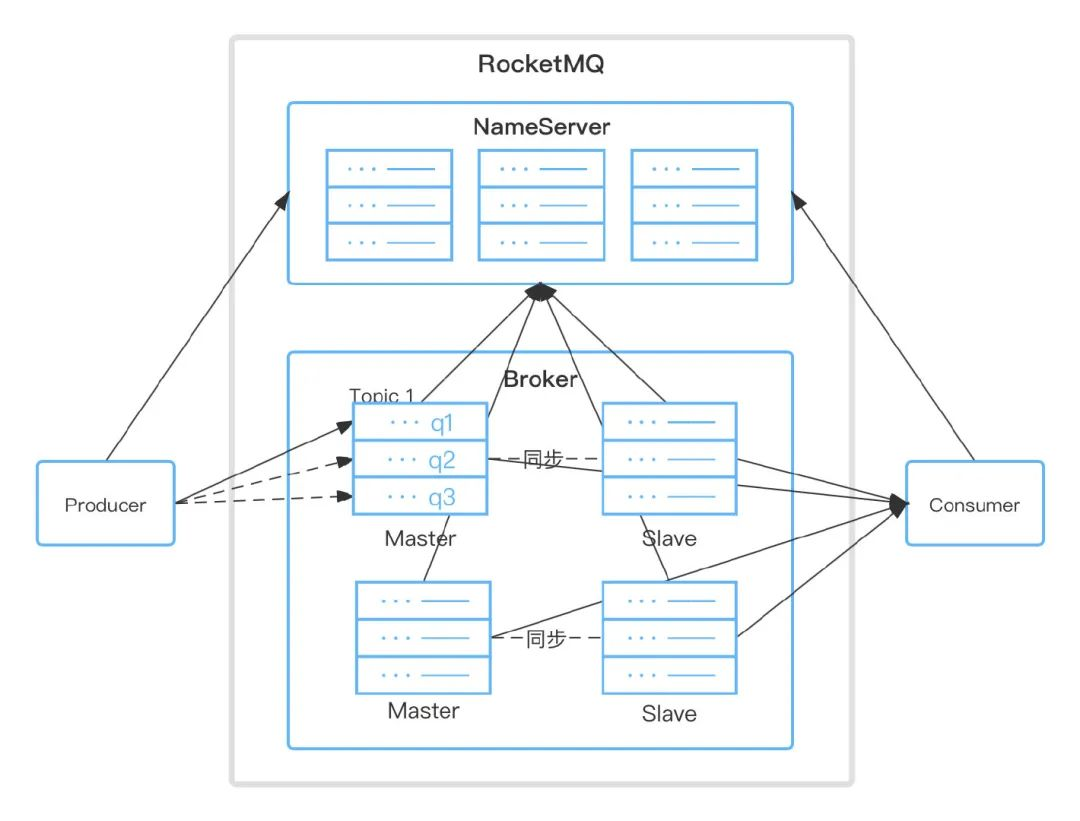
Topic:一個 Topic 可以有 0 個、1 個、多個生產者向其發送訊息,一個生產者也可以同時向不同的 Topic 發送訊息,一個 Topic 也可以被 0 個、1 個、多個消費者訂閱;
Tag:訊息二級型別,可以為用戶提供額外的靈活度,一條訊息可以沒有 tag;
Producer:訊息生產者;
Broker:存盤訊息,以 Topic 為緯度輕量級的佇列;轉發訊息,單個 Broker 節點與所有的 NameServer 節點保持長連接及心跳,會定時將 Topic 資訊注冊到 NameServer;
Consumer:訊息消費者,負責接收并消費訊息;
MessageQueue:訊息的物理管理單位,一個 Topic 可以有多個 Queue,Queue 的引入實作了水平擴展的能力;
NameServer:負責對原資料的管理,包括 Topic 和路由資訊,每個 NameServer 之間是沒有通信的;
Group:一個組可以訂閱多個 Topic,ProducerGroup、ConsumerGroup 分別是一類生產者和一類消費者;
Offset:通過 Offset 訪問存盤單元,RocketMQ 中所有訊息都是持久化的,且存盤單元定長,Offset 為 Java Long 型別,理論上 100 年內不會溢位,所以認為 Message Queue 是無限長的資料,Offset 是下標;
Consumer:支持 PUSH 和 PULL 兩種消費模式,支持集群消費和廣播消費,
系統框架
優點
支持發布/訂閱(Pub/Sub)和點對點(P2P)訊息模型:
- 順序佇列:在一個佇列中可靠的先進先出(FIFO)和嚴格的順序傳遞;支持拉(pull)和推(push)兩種訊息模式;
- 單一佇列百萬訊息的堆積能力;
- 支持多種訊息協議,如 JMS、MQTT 等;
- 分布式橫向擴展架構;
- 滿足至少一次訊息傳遞語意;
- 提供豐富的 Dashboard,包含配置、指標和監控等;
- 支持的客戶端,目前是 java、c++及 golang
缺點
- 社區活躍度一般;
- 延時訊息:開源版不支持任意時間精度,僅支持特定的 level,
使用場景
- 為金融互聯網領域而生,對于可靠性要求很高的場景,
作者:anncdchen
本文來自博客園,作者:古道輕風,轉載請注明原文鏈接:https://www.cnblogs.com/88223100/p/The-basic-principle-and-selection-comparison-of-message-queue.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/502161.html
標籤:架構設計
下一篇:設計模式——行為型設計模式