1. 動態SQL(核心)
1.1 簡介
Mybatis框架的動態SQL技術是一種根據特定條件動態拼裝SQL陳述句的功能,它存在的意義是為了解決拼接SQL陳述句字串時的難點問題,
比如: 我們在多條件查詢的時候會寫這樣的陳述句:
select * from sys_user where 1=1 and
再比如:做更新的時候,我們沒有修改的資料列也執行了更新操作,
1.2 if和where標簽
|
<!-- List<Emp> select ByCondition(Emp emp); -->
<select id="selectByCondition" resultType="com.hy.bean.Emp">
select emp_id,emp_name,emp_salary from sys_emp <!-- where標簽會自動去掉“標簽體內前面、后面多余的and/or” --> <where> <!-- 使用if標簽,讓我們可以有選擇的加入SQL陳述句的片段,這個SQL陳述句片段是否要加入整個SQL陳述句,就看if標簽判斷的結果是否為true --> <!-- 在if標簽的test屬性中,可以訪問物體類的屬性,不可以訪問資料庫表的欄位 --> <if test="empName != null"> <!-- 在if標簽內部,需要訪問介面的引數時還是正常寫#{} -->
or emp_name=#{empName} </if> <if test="empSalary > 2000"> or emp_salary>#{empSalary} </if>
<!-- 第一種情況:所有條件都滿足 WHERE emp_name=? or emp_salary>? 第二種情況:部分條件滿足 WHERE emp_salary>? 第三種情況:所有條件都不滿足 沒有where子句 --> </where> </select>
|
1.3 set標簽
需求:實際開發時,對一個物體類物件進行更新,往往不是更新所有欄位,而是更新一部分欄位,此時頁面上的表單往往不會給不修改的欄位提供表單項 ,

例如:上面的表單,如果服務器端接收表單時,使用的是User這個物體類,那么userName、userBalance、userGrade接收到的資料就是null ,
如果不加判斷,直接用User物件去更新資料庫,在Mapper組態檔中又是每一個欄位都更新,那就會把userName、userBalance、userGrade設定為null值,從而造成資料庫表中對應資料被破壞,
此時需要我們在Mapper組態檔中,對update陳述句的set子句進行定制,此時就可以使用動態SQL的set標簽,
|
<update id="updateEmployeeDynamic">
update sys_emp
<!-- set emp_name=#{empName},emp_salary=#{empSalary} -->
<!-- 使用set標簽動態管理set子句,并且動態去掉兩端多余的逗號 -->
<set>
<if test="empName != null">
emp_name=#{empName},
</if>
<if test="empSalary < 3000">
emp_salary=#{empSalary},
</if>
</set>
where emp_id=#{empId}
</update> |
第一種情況:所有條件都滿足 SET emp_name=?, emp_salary=?
第二種情況:部分條件滿足 SET emp_salary=?
第三種情況:所有條件都不滿足 update t_emp where emp_id=?
沒有set子句的update陳述句會導致SQL語法錯誤
1.4 trim標簽
使用trim標簽控制條件部分兩端是否包含某些字符
prefix屬性:指定要動態添加的前綴內容
suffix屬性:指定要動態添加的后綴
prefixOverrides屬性:指定要動態去掉的前綴,使用“|”分隔有可能的多個值
suffixOverrides屬性:指定要動態去掉的后綴,使用“|”分隔有可能的多個值
下面例子中,trim標簽內部如果有條件,則where會出現,否則where不出現,
suffixOverrides=“and|or”:整個條件部分,如果在后面有多出來的“and或or”會被自動去掉,
|
<!-- List<Emp> selectByConditionByTrim(Emp emp) --> <select id="selectByConditionByTrim" resultType="com.hy.bean.Emp"> select emp_id,emp_name,emp_age,emp_salary,emp_gender from sys_emp <!-- prefix屬性指定要動態添加的前綴 --> <!-- suffix屬性指定要動態添加的后綴 --> <!-- prefixOverrides屬性指定要動態去掉的前綴,使用“|”分隔有可能的多個值 --> <!-- suffixOverrides屬性指定要動態去掉的后綴,使用“|”分隔有可能的多個值 --> <!-- 當前例子用where標簽實作更簡潔,但是trim標簽更靈活,可以用在任何有需要的地方 --> <trim prefix="where" suffixOverrides="and|or"> <if test="empName != null"> emp_name=#{empName} and </if> <if test="empSalary > 3000"> emp_salary > #{empSalary} and </if> <if test="empAge < 20"> emp_age=#{empAge} or </if> <if test="empGender==’ m’ "> emp_gender=#{empGender} </if> </trim> </select> |
1.5 choose/when/otherwise標簽
在多個分支條件中,僅執行一個,

|
<!-- List<Emp> selectByConditionByChoose(Emp emp) --> <select id="selectEmployeeByConditionByChoose" resultType="com.hy.bean.Emp"> select emp_id,emp_name,emp_salary from sys_emp where <choose> <when test="empName != null">emp_name=#{empName}</when> <when test="empSalary > 3000">emp_salary > 3000</when> <otherwise>1=1</otherwise> </choose>
<!-- 第一種情況:第一個when滿足條件 where emp_name=? 第二種情況:第二個when滿足條件 where emp_salary < 3000 第三種情況:兩個when都不滿足 where 1=1 執行了otherwise --> </select>
|
1.6 foreach標簽
1.6.1 基本用法
比如:批量插入
abstract public void insertBatch(@Param(“empList”) List<Emp> empList));
|
<!-- INSERT INTO `sys_emp` VALUES (null, '李冰冰', 'lbb', 'f', 300,default,2), (null, '張彬彬', 'zbb', 'm', 599,default,3), (null, '萬茜', 'wq', 'm', 4000,default,1), (null, '李若彤', 'lrt', 'm', 5000.8,default,1) --> <insert id="insertBatch"> INSERT INTO `sys_emp`(emp_id,emp_name,emp_gender) <foreach collection="empList" item="emp" separator="," open="VALUES" > (null,#{emp.empName},#{emp.empGender}) </foreach> </insert> |
|
|
我們這里寫的批量插入的例子本質上是一條SQL陳述句,
collection屬性:要遍歷的集合,如果介面中方法中使用了@Param ,collection屬性中要用這個名字,
item屬性:遍歷集合的程序中能得到每一個具體物件,在item屬性中設定一個名字,將來通過這個名字參考遍歷出來的物件
separator屬性:指定當foreach標簽的標簽體重復拼接字串時,各個標簽體字串之間的分隔符
open屬性:指定整個foreach回圈把字串拼好后,這個字串整體的前面要添加的字串
close屬性:指定整個foreach回圈把字串拼好后,這個字串整體的后面要添加的字串
index屬性:這里起一個名字,便于后面參考
遍歷List集合,這里能夠得到List集合的索引值
遍歷Map集合,這里能夠得到Map集合的key
如果介面形參位置沒有使用@Param注解,而且foreach標簽也沒有使用默認的名稱,則會拋出例外

Caused by:org.apache.ibatis.binding.BindingException: Parameter ‘empList’ not found. Available parameters are[arg0,collection, list]
1.6.2 批量更新
而實作批量更新則需要多條update SQL陳述句拼起來,并且用分號分開,也就是一次性發送多條SQL陳述句讓資料庫執行,
此時需要在資料庫連接資訊的URL地址中設定
?allowMultiQueries=true
對應的foreach標簽如下:
<!-- int updateBatch(@Param("empList") List<Emp> empList) -->
<update id="updateBatch">
<foreach collection="empList" item="emp" separator=";">
update sys_emp set emp_name=#{emp.empName} where emp_id=#{emp.empId}
</foreach>
</update>
1.6.3 關于foreach標簽的collection屬性
如果沒有給介面中List型別的引數使用@Param注解指定一個具體的名字,那么在collection屬性中默認可以使用collection或list來參考這個list集合,這一點可以通過例外資訊看出來:
Parameter 'empList' not found. Available parameters are [collection, list]
在實際開發中,為了避免隱晦的表達造成一定的誤會,建議使用@Param注解明確宣告變數的名稱,然后在foreach標簽的collection屬性中按照@Param注解指定的名稱來參考傳入的引數,
1.7 sql標簽
1.7.1 抽取重復的SQL片段
|
<!-- 使用sql標簽抽取重復出現的SQL片段 --> <sql id="mySelectSql"> select emp_id,emp_name,emp_age,emp_salary,emp_gender from t_emp </sql> |
1.7.2 參考已抽取的SQL片段
|
<!-- 使用include標簽參考宣告的SQL片段 --> <include refid="mySelectSql"/> |
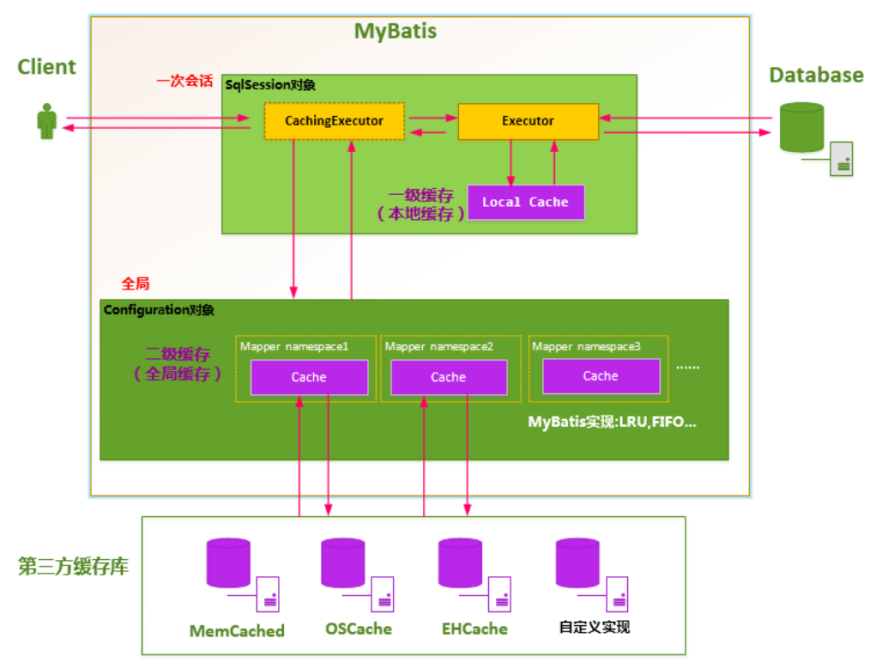
2.快取
2.1 快取機制
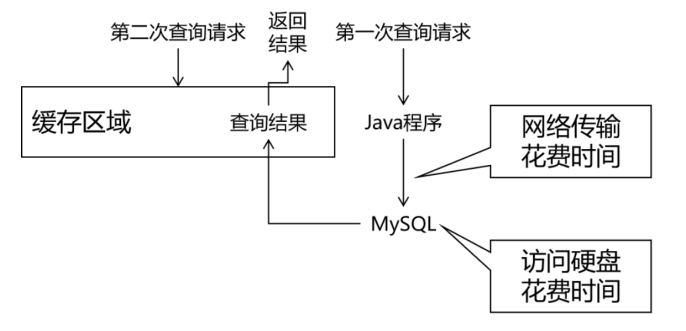
比如:以前農村裝水的水缸
2.2 一級快取和二級快取
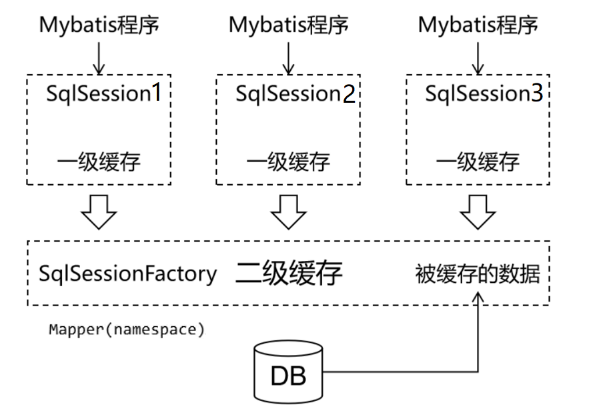
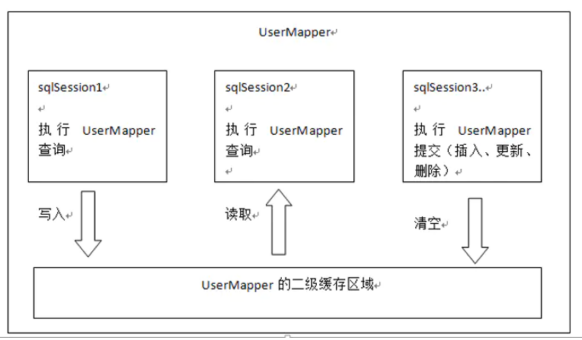
二級快取被所有的SqlSession共享,也就是能被訪問的,
一級快取是SqlSession級別的快取,在操作資料庫時需要構造 sqlSession物件,在物件中有一個資料結構(HashMap)用于存盤快取資料,不同的sqlSession之間的快取資料區域(HashMap)是互相不影響的,
二級快取是Mapper(namespace)級別的快取,多個SqlSession去操作同一個Mapper的sql陳述句,多個SqlSession可以共用二級快取,二級快取是跨SqlSession的,
第一次查詢,先將結果放入到一級快取,等SqlSession提交事務后,再將資料放入到二級快取,
2.2.1 一級快取和二級快取的使用順序
查詢的順序是:
1)先查詢二級快取,因為二級快取中可能會有其他程式已經查出來的資料,可以拿來直接使用,
2)如果二級快取沒有命中,再查詢一級快取
3)如果一級快取也沒有命中,則查詢資料庫
SqlSession關閉之前,會將一級快取中的資料會寫入二級快取
2.2.2 效用范圍
一級快取:SqlSession級別
二級快取:SqlSessionFactory級別
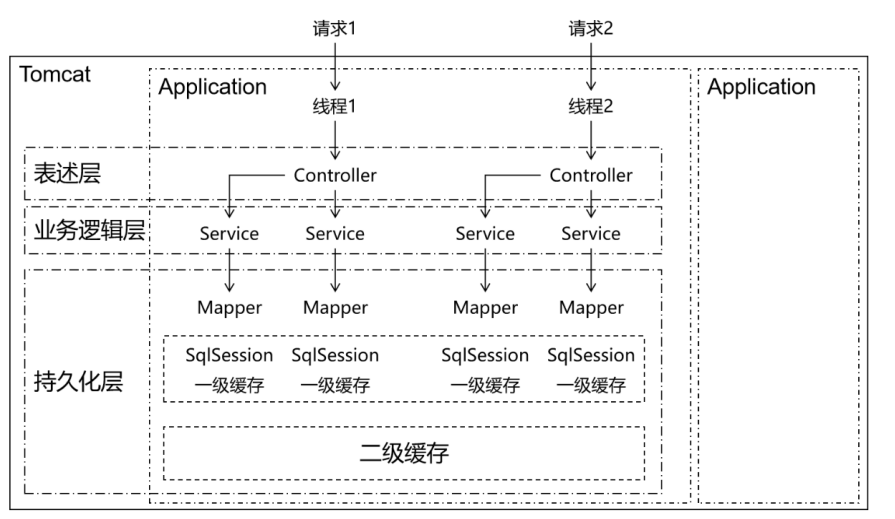
它們之間范圍的大小參考下面圖:
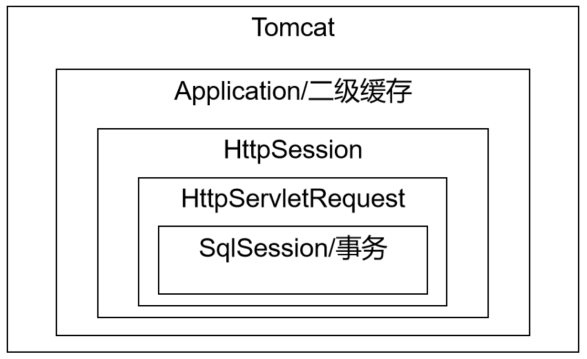
一個請求中可能包含多個事務 ------ 一個service方法(一個SqlSession)對應一個事務
注意:快取是用再查詢程序中的,增刪改,反而會破壞快取,造成快取和資料庫不一致,所以很多情況,執行了一個增刪改操作,他會把快取清空,
3. 一級快取
Mybatis默認開啟了一級快取
3.1 案例1:測驗一級快取是否存在
為了測驗快取失效,我們需要修改測驗類中的代碼,需要關閉SqlSessioin物件,然后重新開,再重新開的話,需要操作SqlSessionFactory,
如何測驗一級快取是否存在???同一個資料查兩次,但是只發了一條SQL陳述句[給資料庫],
3.1.1 證明一級快取存在
|
package com.hy.mybatis.test;
import java.io.IOException;
import org.apache.ibatis.io.Resources; import org.apache.ibatis.session.SqlSession; import org.apache.ibatis.session.SqlSessionFactory; import org.apache.ibatis.session.SqlSessionFactoryBuilder; import org.junit.Before; import org.junit.Test;
import com.hy.bean.Emp; import com.hy.mapper.EmpMapper;
public class TestLevelOneCache1 { private SqlSessionFactory sqlSessionFactory; private Logger logger = null; @Before public void init() throws IOException { logger = LoggerFactory.getLogger(this.getClass()); sqlSessionFactory = new SqlSessionFactoryBuilder().build(Resources.getResourceAsStream("mybatis-config.xml")); }
@Test public void testLevelOneCache1_01() throws IOException { SqlSession session = sqlSessionFactory.openSession(); EmpMapper empMapper = session.getMapper(EmpMapper.class);
Emp emp1 = empMapper.selectById(1); Emp emp2 = empMapper.selectById(1); // 第二次是從快取中查詢出來的,
logger.info("是否相等:"+ (emp1 == emp2)); //true
session.commit(); session.close(); } } |
只發一條SQL陳述句,一級快取默認開啟,不需要欄位外的配置,二級快取需要開啟才有,現在沒有開,所以只有一級快取,

3.2 案例2:一級快取失效的情況:
1)同一個SqlSession兩次查詢期間提交了事務
2)同一個SqlSession兩次查詢期間執行了任何一次增刪改操作,不論是夠提交事務,都清空一級快取
3)同一個SqlSession但是查詢條件發生了變化
4)同一個SqlSession兩次查詢期間手動清空了快取
5)不是同一個SqlSession
總結:在執行commit,rollback時會清空一級快取
一級快取的清除還有以下兩個地方:
|
1、就是獲取快取之前會先進行判斷用戶是否配置了flushCache=true屬性(參考一級快取的創建代碼截圖),如果配置了則會清除一級快取, 2、MyBatis全域配置屬性localCacheScope配置為Statement時,那么完成一次查詢就會清除快取, |
3.2.1 同一個SqlSession兩次查詢期間提交了事務
|
public class TestLevelCache1 { private SqlSessionFactory sqlSessionFactory; private Logger logger = null; @Before public void init() throws IOException { logger = LoggerFactory.getLogger(this.getClass()); sqlSessionFactory = new SqlSessionFactoryBuilder().build(Resources.getResourceAsStream("mybatis-config.xml")); }
//1) 同一個SqlSession兩次查詢期間提交了事務 //1.1 沒有提交事務,使用一級快取 @Test public void testLevelOneCache1_01 () throws IOException { SqlSession session = sqlSessionFactory.openSession(); EmpMapper empMapper = session.getMapper(EmpMapper.class);
Emp emp1 = empMapper.selectById(1); Emp emp2 = empMapper.selectById(1); // 第二次是從快取中查詢出來的,
logger.info("是否相等:"+ (emp1 == emp2)); //true
session.commit(); session.close(); }
//1.2 兩次查詢中間,提交了事務,清空一級快取 @Test public void testLevelOneCache1_02() throws IOException { SqlSession session = sqlSessionFactory.openSession(); EmpMapper empMapper = session.getMapper(EmpMapper.class);
Emp emp1 = empMapper.selectById(1); session.commit(); Emp emp2 = empMapper.selectById(1); // 由于進行了事務的提交,所以又發送了一條查詢陳述句,
logger.info("是否相等:"+ (emp1 == emp2)); //false session.close(); }
} |


3.2.2 同一個SqlSession兩次查詢期間執行了任何一次增刪改操作,并且提交了事務

|
@Test public void testLevelOneCache01_4() { SqlSession sqlSession = sqlSessionFactory.openSession();
EmpMapper empMapper = sqlSession.getMapper(EmpMapper.class);
Emp emp1 = empMapper.selectById(1);
//Emp newEmp = new Emp(2L, "范冰冰ILoveYou", null, null, null, null); //empMapper.updateById(newEmp); //更新但是不提交事務
empMapper.deleteById(8); //執行了洗掉沒有,提交事務也,重新一遍
Emp emp2 = empMapper.selectById(1); //logger.debug(emp2.toString()); logger.debug("是否相等:" + (emp1 == emp2));
sqlSession.commit(); sqlSession.close(); } |
|
// 2.2 @Test public void testLevelOneCache2_02() throws IOException { SqlSession session = sqlSessionFactory.openSession();
EmpMapper empMapper = session.getMapper(EmpMapper.class);
Emp emp1 = empMapper.selectById(1); //查詢后,將物件放入一級快取
empMapper.deleteById(7); //執行了delete操作,但是并沒有提交 session.commit();
Emp emp11 = empMapper.selectById(1); //提交了事務,一級快取清空 logger.info("是否相等:"+ (emp1 == emp11)); //false
session.commit(); session.close(); } |

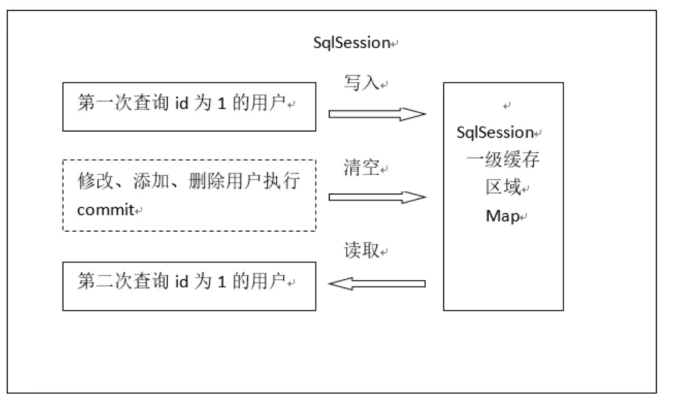
第一次發起查詢用戶id為1的用戶資訊,先去找快取中是否有id為1的用戶資訊,如果沒有,從資料庫查詢用戶資訊,將查詢到的用戶資訊存盤到一級快取中,
如果中間sqlSession去執行插入、更新、洗掉,并且commit,清空SqlSession中的一級快取,這樣做的目的為了讓快取中存盤的是最新的資訊,避免臟讀,
第二次發起查詢用戶id為1的用戶資訊,先去找快取中是否有id為1的用戶資訊,快取中有,直接從快取中獲取用戶資訊,如果沒有,則重新發出一條查詢陳述句,
3.2.3 同一個SqlSession但是查詢條件發生了變化
|
// 3. 同一個SqlSession但是查詢條件發生了變化 @Test public void testLevelOneCache3_01() throws IOException { SqlSession session = sqlSessionFactory.openSession();
EmpMapper empMapper = session.getMapper(EmpMapper.class);
Emp emp1 = empMapper.selectById(1); //查詢后,將物件放入一級快取 //查詢的是emp_id為2的員工資訊,一級快取中并沒有所以重新發出一條SQL陳述句 Emp emp2 = empMapper.selectById(2); session.commit(); session.close(); } |

3.2.4 同一個SqlSession兩次查詢期間手動清空了快取
|
// 4)同一個SqlSession兩次查詢期間手動清空了快取 @Test public void testLevelOneCache4() throws IOException { SqlSession session = sqlSessionFactory.openSession();
EmpMapper empMapper = session.getMapper(EmpMapper.class);
Emp emp1 = empMapper.selectById(1); session.clearCache(); Emp emp2 = empMapper.selectById(1); // 由于兩次查詢中間清空了一級快取,所以又發送了一條查詢陳述句, logger.info("是否相等:"+ (emp1 == emp2)); //false
session.commit(); session.close(); } |

3.2.5 不是同一個SqlSession
|
// 5)不是同一個SqlSession @Test public void testLevelOneCache1_05() throws IOException { SqlSession session01 = sqlSessionFactory.openSession(); SqlSession session02 = sqlSessionFactory.openSession(); EmpMapper empMapper01 = session01.getMapper(EmpMapper.class); EmpMapper empMapper02 = session02.getMapper(EmpMapper.class); Emp emp1 = empMapper01.selectById(1); // 由于是不同的SqlSession,所以又發送了一條查詢陳述句,各自有各自的一級快取, Emp emp2 = empMapper02.selectById(1);
logger.info("是否相等:"+ (emp1 == emp2)); //false session01.commit(); session02.commit(); session01.close(); session02.close(); } |

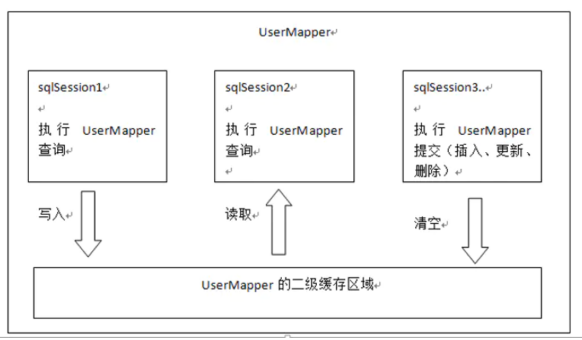
4. 二級快取[mybatis自帶的二級快取]
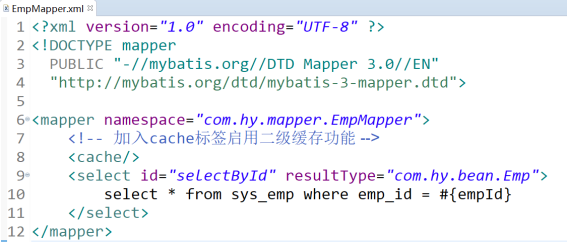
4.1 使用二級快取步驟
1)在想要使用二級快取的EmpMapper映射檔案中加入cache標簽
開啟全域二級快取配置:<setting name="cacheEnabled" value="https://www.cnblogs.com/lijili/archive/2022/08/27/true"></setting>
2)讓物體類支持序列化
public class Emp implements Serializable{
private static final long serialVersionUID = 1L;
這里我們使用mybaits自帶的二級快取,后面我們使用第三方的二級快取EHCache,
3)SqlSession提交事務時才會將查詢到的資料存入二級快取
|
@Test public void testLevelTwoCache() { // 測驗二級快取存在:使用兩個不同SqlSession執行查詢 // 說明:SqlSession提交事務時才會將查詢到的資料存入二級快取 // 所以本例并沒有能夠成功從二級快取獲取到資料 SqlSession sqlSession01 = sqlSessionFactory.openSession(); SqlSession sqlSession02 = sqlSessionFactory.openSession();
EmpMapper empMapper01 = sqlSession01.getMapper(EmpMapper.class); EmpMapper empMapper02 = sqlSession02.getMapper(EmpMapper.class);
//[00:01:07.699] [DEBUG] [main] [com.hy.mapper.EmpMapper] [Cache Hit Ratio [com.hy.mapper.EmpMapper]: 0.0] Emp emp01 = empMapper01.selectById(1); //[00:01:07.746] [DEBUG] [main] [com.hy.mapper.EmpMapper] [Cache Hit Ratio [com.hy.mapper.EmpMapper]: 0.0] Emp emp02 = empMapper02.selectById(1);
logger.info("是否相等:"+ (emp1 == emp2)); //false sqlSession01.commit(); sqlSession01.close();
sqlSession02.commit(); sqlSession02.close(); } |
修改代碼;
|
@Test public void testSecondLevelCache2() { SqlSession sqlSession01 = sqlSessionFactory.openSession(); SqlSession sqlSession02 = sqlSessionFactory.openSession();
EmpMapper empMapper01 = sqlSession01.getMapper(EmpMapper.class); EmpMapper empMapper02 = sqlSession02.getMapper(EmpMapper.class);
Emp emp01 = empMapper01.selectById(1);
sqlSession01.commit(); sqlSession01.close(); Emp emp02 = empMapper02.selectById(1);
//false 注意,從二級快取中new了一個新的物件,所以emp01和emp02不是同一個物件 logger.info("是否相等:"+ (emp1 == emp2)); sqlSession02.commit(); sqlSession02.close(); } |

雖然兩個物件不相等,但是注意:只發出了一條查詢陳述句,
日志中列印的Cache Hit Ratio叫做快取命中率
快取命中率=命中快取的次數/查詢的總次數
4)mybatis序列化的特點
mybatis的二級快取是屬于序列化,序列化的意思就是從記憶體中的資料傳到硬碟中,這個程序就是序列化;
反序列化意思就是相反而已;
也就是說,mybatis的二級快取,實際上就是將資料放進了硬碟檔案中去了;
現在呢,你僅僅的將Emp類給序列化了,如果有父類Person、級聯屬性,它們是不會跟著被序列化的,所以光這些是不夠的;
很簡單,如果Emp需要序列化,但是這個類中還有其他類的屬性,僅需將其他類也實作序列化介面即可!
比如Emp類繼承了Person父類,那么父類也需要實現Serializable這個介面;
4.2 二級快取失效的條件
與一級快取一樣,二級快取也會存在失效的條件的,下面我們就來探究一下哪些情況會造成二級快取失效,
4.2.1 第一次SqlSession 未提交
SqlSession 在未提交的時候,SQL 陳述句產生的查詢結果還沒有放入二級快取中,這個時候 SqlSession2 在查詢的時候是感受不到二級快取的存在的
4.2.2 更新對二級快取影響
與一級快取一樣,更新操作對二級快取造成影響,下面用三個 SqlSession來進行模擬,第一個 SqlSession 只是單純的查詢并提交,第二個 SqlSession 用于查詢二級快取是否失效,第三個 SqlSession2 用于執行更新操作,
|
@Test public void testLevelTwoCache01_03() { SqlSession sqlSession1 = sqlSessionFactory.openSession(); SqlSession sqlSession2 = sqlSessionFactory.openSession(); SqlSession sqlSession3 = sqlSessionFactory.openSession();
EmpMapper empMapper1 = sqlSession1.getMapper(EmpMapper.class); EmpMapper empMapper2 = sqlSession2.getMapper(EmpMapper.class); EmpMapper empMapper3 = sqlSession3.getMapper(EmpMapper.class);
Emp emp1 = empMapper1.selectById(1); logger.info(emp1.toString()); sqlSession1 .commit(); //清空一級快取,加入二級快取
Emp emp2 = empMapper2.selectById(1); logger.info(emp2.toString()); //從二級快取中查詢出來 logger.info("是否是同一個物件:"+(emp1==emp2)); sqlSession2.commit();
Emp newEmp = new Emp(1L,"垃圾張文宏",null,null,null,null); empMapper3.updateById(newEmp); sqlSession3.commit();
Emp emp22 = empMapper2.selectById(1); logger.info(emp22.toString()); //從二級快取中查詢出來 logger.info("是否是同一個物件:"+(emp1==emp22)); sqlSession2.commit();
sqlSession1.close(); sqlSession2.close(); } |
因為所有的 insert,delete,uptede 都會觸發快取的重繪,從而導致二級快取失效,所以二級快取適合在讀多寫少的場景中開啟,
|
1) 每個增刪改標簽都有默認清空快取配置:flushCache="true",不過這是默認的是一級和二級快取都清空 2)每個select標簽都默認配置了useCache="true": |
4.2.3 測驗時的問題
測驗的時候,sqlSessionFactory不同,自然也會導致二級快取失效 ,
4.2.4 測驗時的問題
|
@Test public void testLevelTwoCache04() { SqlSession sqlSession01 = sqlSessionFactory.openSession(); SqlSession sqlSession02 = sqlSessionFactory.openSession(); SqlSession sqlSession03 = sqlSessionFactory.openSession();
EmpMapper empMapper01 = sqlSession01.getMapper(EmpMapper.class); EmpMapper empMapper02 = sqlSession02.getMapper(EmpMapper.class); EmpMapper empMapper03 = sqlSession03.getMapper(EmpMapper.class);
Emp emp01 = empMapper01.selectById(1); System.out.println(emp01); Emp newEmp = new Emp(1L, "范冰冰", "fbbfbb", null, null, null, null,null); empMapper02.updateByCondition(newEmp);
sqlSession02.commit(); sqlSession02.close();
Emp emp02 = empMapper01.selectById(1); System.out.println(emp02);
System.out.println(emp01 == emp02); }
[com.hy.mapper.EmpMapper] [Cache Hit Ratio [com.hy.mapper.EmpMapper]: 0.0] [com.hy.mapper.EmpMapper.selectById] [==> Preparing: select * from sys_emp where emp_id = ?] [com.hy.mapper.EmpMapper.selectById] [==> Parameters: 1(Long)] [com.hy.mapper.EmpMapper.selectById] [<== Total: 1] Emp [empId=1, empName=范冰冰222, empPwd=fbb, empGender=f, empSalary=30000.0, empStatus=y [com.hy.mapper.EmpMapper.updateByCondition] [==> Preparing: update sys_emp SET emp_name = ? where emp_id = ?] [com.hy.mapper.EmpMapper.updateByCondition] [==> Parameters: 范冰冰(String), 1(Long)] [com.hy.mapper.EmpMapper.updateByCondition] [<== Updates: 1] [com.hy.mapper.EmpMapper] [Cache Hit Ratio [com.hy.mapper.EmpMapper]: 0.0] Emp [empId=1, empName=范冰冰222, empPwd=fbb, empGender=f, empSalary=30000.0, empStatus=y true |
4.3 二級快取應該開啟嗎
一級快取默認是開啟的,而二級快取是需要我們手動開啟的,那么我們什么時候應該開啟二級快取呢?
1、因為所有的(insert,delete,uptede)都會觸發快取的重繪,從而導致二級快取失效,所以二級快取適合在讀多寫少的場景中開啟,
2、因為二級快取針對的是同一個namespace,所以建議是在單表操作的Mapper中使用,或者是在相關表的Mapper檔案中共享同一個快取,
5 EHCache快取

5.1 EHCache簡介
第三方的快取產品
官網地址:https://www.ehcache.org/

5.2 整合操作
|
<!-- Mybatis EHCache整合包 --> <dependency> <groupId>org.mybatis.caches</groupId> <artifactId>mybatis-ehcache</artifactId> <version>1.2.1</version> </dependency>
<dependency> <groupId>ch.qos.logback</groupId> <artifactId>logback-classic</artifactId> <version>1.2.3</version> </dependency> |
2.5.2.1 Mybatis環境
在Mybatis環境下整合EHCache,前提當然是要先準備好Mybatis的環境,
|
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.hy</groupId> <artifactId>springmvc006</artifactId> <version>0.0.1</version> <packaging>war</packaging>
<properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding> <maven.compiler.encoding>UTF-8</maven.compiler.encoding> </properties>
<dependencies> <!-- https://mvnrepository.com/artifact/org.projectlombok/lombok --> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.20</version> </dependency>
<!-- https://mvnrepository.com/artifact/com.alibaba/druid --> <!-- 資料庫連接池 --> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>1.2.9</version> </dependency>
<dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-databind </artifactId> <version>2.12.1</version> </dependency>
<!-- mybaits相關jar包 --> <!-- https://mvnrepository.com/artifact/org.mybatis/mybatis --> <dependency> <groupId>org.mybatis</groupId> <artifactId>mybatis</artifactId> <version>3.5.6</version> </dependency>
<!-- Mybatis EHCache整合包 --> <dependency> <groupId>org.mybatis.caches</groupId> <artifactId>mybatis-ehcache</artifactId> <version>1.2.1</version> </dependency>
<!-- https://mvnrepository.com/artifact/ch.qos.logback/logback-classic --> <!-- logback日志 slf4j日志門面的一個具體實作 --> <dependency> <groupId>ch.qos.logback</groupId> <artifactId>logback-classic</artifactId> <version>1.2.3</version> </dependency>
<dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> <scope>test</scope> </dependency>
<dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.49</version> </dependency> <!-- mybaits相關jar包 --> </dependencies>
<build> <plugins> <!-- 指定jdk,防止update project --> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <configuration> <source>1.8</source> <target>1.8</target> <!-- 專案編碼 --> <encoding>UTF-8</encoding> </configuration> </plugin> </plugins> </build> </project> |
這是一個EHCache和mybatis的整合包,但是會講EHCache核心包傳遞進來,

2.5.2.2 各主要jar包

作用
2.5.2.3 整合EHCache
創建EHCache組態檔, ehcache.xml
|
<?xml version="1.0" encoding="utf-8" ?> <ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="../config/ehcache.xsd"> <!-- 磁盤保存路徑 --> <diskStore path="f:\hy\ehcache"/>
<defaultCache maxElementsInMemory="1000" maxElementsOnDisk="10000000" eternal="false" overflowToDisk="true" timeToIdleSeconds="120" timeToLiveSeconds="120" diskExpiryThreadIntervalSeconds="120" memoryStoreEvictionPolicy="LRU"> </defaultCache> </ehcache> |

2.5.2.4 指定快取管理器的具體型別
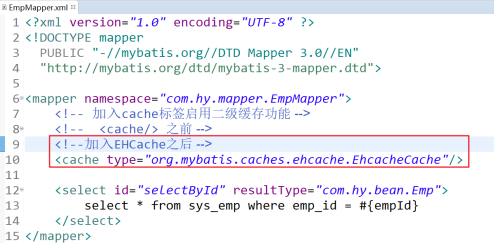
還是到查詢操作所的EmpMapper組態檔中,找到之前設定的cache標簽:
logback.xml
|
<?xml version="1.0" encoding="UTF-8"?> <configuration debug="true"> <!-- 指定日志輸出的位置 --> <appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender"> <encoder> <!-- 日志輸出的格式 --> <!-- 按照順序分別是:時間、日志級別、執行緒名稱、列印日志的類、日志主體內容、換行 --> <pattern>[%d{HH:mm:ss.SSS}] [%-5level] [%thread] [%logger] [%msg]%n</pattern> </encoder> </appender>
<!-- 設定全域日志級別,日志級別按順序分別是:TRACE > DEBUG > INFO > WARN > ERROR > FATAL --> <!-- 指定任何一個日志級別都只列印當前級別和后面級別的日志, --> <root level="DEBUG"> <!-- 指定列印日志的appender,這里通過“STDOUT”參考了前面配置的appender --> <appender-ref ref="STDOUT" /> </root>
<!-- 根據特殊需求指定區域日志級別 --> <logger name="com.hy.mapper" level="DEBUG" /> </configuration> |

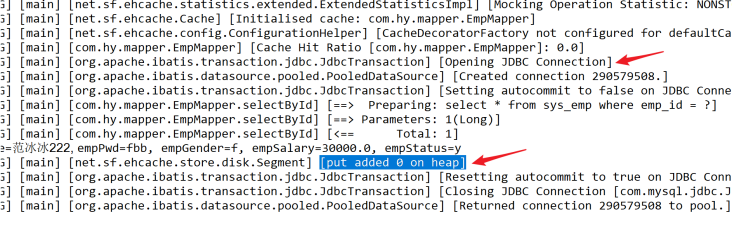
5.3 EHCache組態檔說明
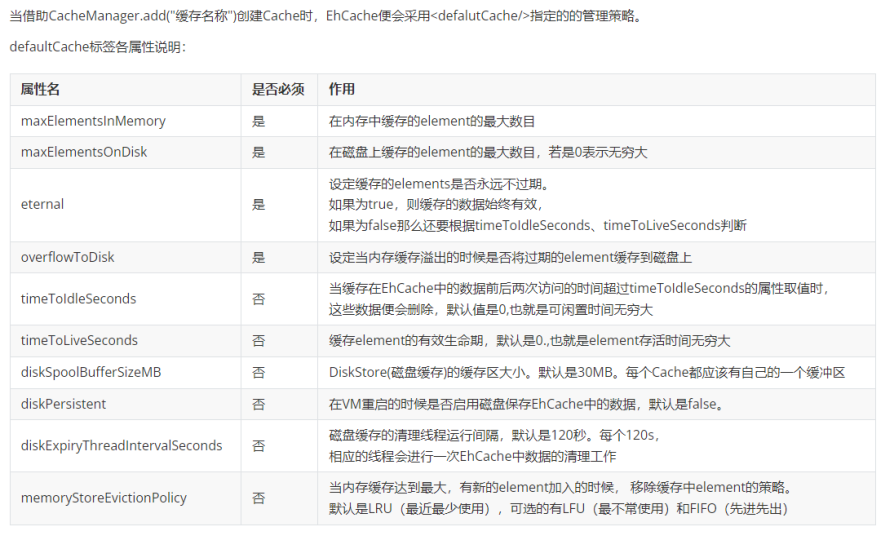
 改成10秒,10秒后釋放,
改成10秒,10秒后釋放,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/502945.html
標籤:其他