
一、什么是分布式鎖?
什么是分布式鎖?對于這個問題,相信很多同學是既熟悉又陌生,隨著分布式系統的快速發展與廣泛應用,針對共享資源的互斥訪問也成為了很多業務必須要面對的需求,這個場景下人們通常會引入分布式鎖來解決問題,我們通常會使用怎么樣的分布鎖服務呢?有開源的 MySQL,Redis,ZooKeeper,Etcd 等三方組件可供選擇,當然也有集團內自研的 Tair,Nuwa 等分布式鎖服務提供方,總的來看,我們對分布式鎖的需求可以大體劃分為以下兩類應用場景:
-
實作操作原子性:在單機環境中,為了實作多行程或多執行緒對共享資源操作程序的原子性,我們可以借助內核提供的 SpinLock 或 Mutex 機制,保證只有一個行程或執行緒操作共享資源,和單機環境對鎖的需求類似,在分布式環境中,我們通常會用分布式鎖控制多個機器上的節點并發操作,避免資料或狀態被破壞,
- 實作系統高可用:為了服務的高可用,往往需要部署多個節點實作服務冗余,避免單點故障造成的服務不可用,借助分布式鎖+服務發現實作的選主功能,節點根據搶鎖成功與否決定是否成為主節點對外提供服務,當發生節點宕機時,其他備份節點可以通過爭搶到分布式鎖的所有權,繼續提供訪問服務,
分布式鎖的業務需求、場景看起來比較簡單,但是事實上我們在使用分布式鎖程序中,總還是會提出這樣、那樣的新需求,看起來找不到一個分布式鎖場景的大一統的解決方案,那么,分布式鎖內部究竟是怎么實作的?或者說應該怎么實作呢?這個是我們這篇文章希望探討的,也希望我們的探討能夠讓讀者朋友對分布式鎖的原理有一定了解,在做技術選型的時候,也能夠有更多的指導,
二、設計模型
我們應該給分布式鎖建立怎么樣的設計模型呢?這個問題可以換個視角來看,我們應該建立怎么樣的合理性質來打造出一個分布式鎖模型?我們不妨參考一下來自業界的兩個定義,首先是 Apache Helix(開源社區一個風頭正勁的通用集群資源管理框架,它能被用作自動管理存在于集群節點上的磁區的,有副本的分布式資源)對于分布式鎖管理器的性質定義:a)均勻分布,不是先開始的節點獲取所有的分布式鎖;b)再調度的均衡性,需要妥善處理持有分布式鎖的節點意外退出后的鎖資源分配問題;c)再平衡,當有新的節點加入的時候,節點間的鎖資源應該再分配以達到均衡,看得出來,Helix 對分布式鎖模型的定義非常強調均衡性,考慮到它是負責集群內的磁區資源調度的,這個側重點并不讓人意外,

圖1 Helix 提出的分布式鎖管理器的性質
我們再看另一個大名鼎鼎的 Redis 對分布式鎖性質的定義,它提出了分布式鎖模型必須要遵守的三個原則:a)絕對互斥,同一時刻,只有一個客戶端能夠持有分布式鎖;b)最終可用,如果持有分布式鎖的客戶端意外退出了,那么相關的分布式鎖資源要能夠被重新再分配;c)服務容錯,提供分布式鎖的服務本身要具備容錯能力,即使部分節點崩潰,也不影響整體的分布式鎖服務,

圖2 Redis 提出的分布式鎖管理器的性質
結合自身的經驗,我們高度認同Redis對有關分布式鎖模型的基本約束條件,這些其實也是實作一個分布式鎖服務所必須要考慮的幾個屬性,并且,Redis相關的文章中也繼續探討了分布式鎖的其它的特性約束,事實上,如下圖3所示,我們從三個維度歸納總結一個分布式鎖模型落地需要考慮的性質,第一個維度是最基本的約束條件,與Redis提出的完全一致,我們稱之為:互斥性,可容錯,最終可用;第二層提出的分布式鎖管理器需要關注的一些鎖的特性,譬如搶鎖效率,分布式鎖的均衡性,鎖的切換精度,鎖的可重入性質等等,在這個之上,還有一個分布式鎖落地時候必須要考慮的事關資料一致性與正確性保證的約束,即可防護性以及應對好時鐘漂移的影響,
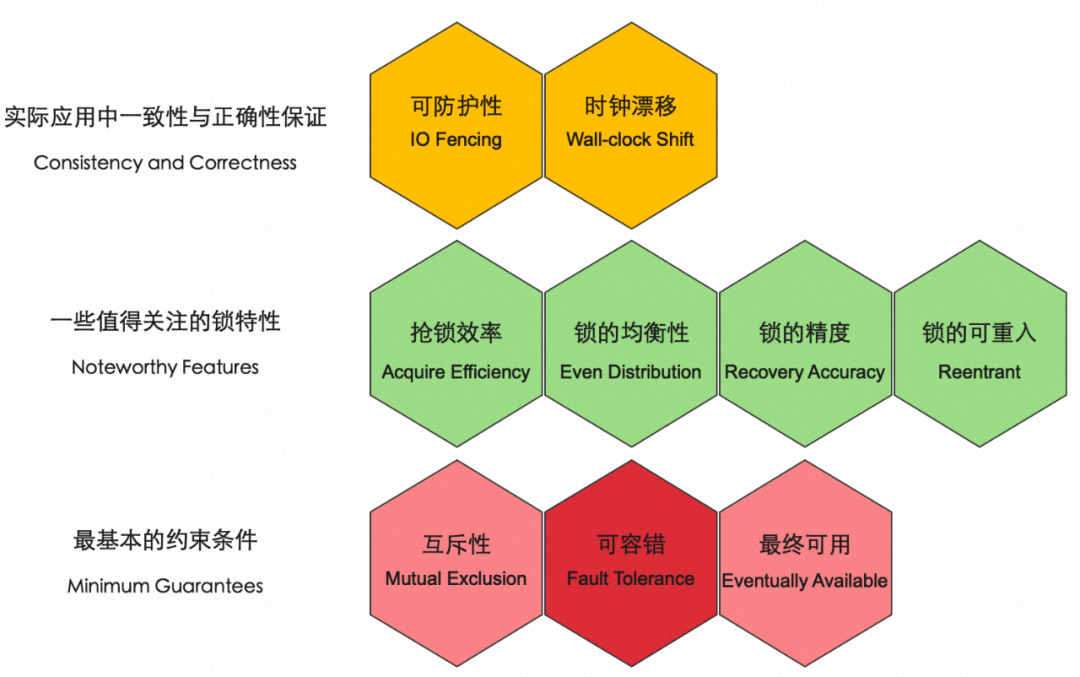
圖3 分布式鎖設計模型需要考慮的三個維度的性質
關于分布式鎖管理器實際落地需要考慮的資料一致性與正確性的話題,其中一個話題是墻上時間的不靠譜,這個可以引入非墻上時間MonoticTime來解決,本文就不在這個問題上做更多討論,另一個話題,實際使用分布式鎖服務來訪問共享資源的時候一定要輔助以Fencing能力方可做到資源訪問的絕對互斥性,大神Martin Kleppmann提供了一個非常好的案例說明,如下圖4所示,Client1首先獲取了分布式鎖的所有權,在操作資料的時候發生了GC,在長時間的"Stop-The-World"的GC程序中丟失了鎖的所有權,Client2爭搶到了鎖所有權,開始操作資料,結果等 Client1的GC完成之后,就會出現Client1,Client2同時操作資料的情形,造成資料不一致,
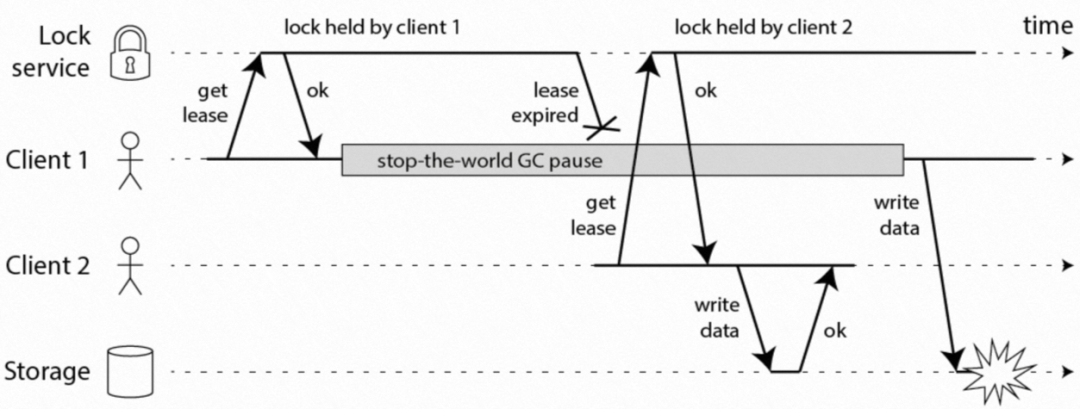
圖4 缺乏Fencing保護的分布式鎖可能導致資料不一致
針對上述問題,解決方案是引入共享資源訪問的IO Fence能力,如下圖5所示,全域鎖服務提供全域自增的 Token,Client1拿到鎖回傳的Token是33,并帶入存盤系統,發生 GC,當Client2 搶鎖成功回傳 Token 34,帶入存盤系統,存盤系統會拒絕后續Token小于34的請求,那么經過了長時間GC重新恢復后的 Client 1再次寫入資料的時候,因為底層存盤系統記錄的Token已經更新,攜帶Token 值為33的請求會被直接拒絕,從而達到了資料保護的效果,
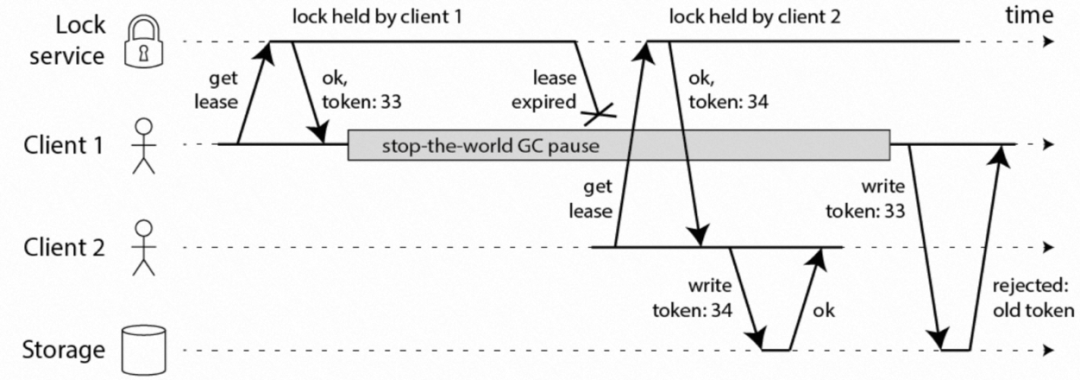
圖5 基于 Fencing 的資料一致性保障
回到文章的主旨,如何實作一個高效的分布式鎖管理器呢?首先,拋出一個觀點,分布式鎖管理器也可以按照控制平面與資料平面進行切分,圖3中提到的分布式鎖性質可以劃分到不同的平面分別負責,我們的這個觀點其實并非首創,事實上在OSDI'20的Best Paper -《Virtual Consensus in Delos》一文,Facebook的研究團隊針對一致性協議的設計做了深入探討,非常的精彩,文章里面提到了類似Raft這類分布式一致性協議,里面也同樣可以分拆出管控平面與資料平面,前者負責容錯、成員變更、角色調整,后者負責定序與持久化,通過解耦兩個平面,一下子讓共識協議變得很靈活,

圖6 Delos 中 Virtual Consensus 對管控資料平面的觀點
我們分布式鎖模型的實作是否也可以參考類似的思路呢?將容錯、成員變更等負責的邏輯轉移至管控平面,而資料平面負責分布式鎖的其它譬如互斥,最終可用,搶鎖效率等等功能,答案是肯定的,好吧,即使這樣的思路也并非我們首創,在資料庫領域,一直有這么個流派來演進這類的分布式鎖系統,它們被統稱為 DLM(Distributed Lock Manager),典型的有 Oracle RAC,GFS2,OCFS2,GPFS,我們接下來好好說道說道DLM,
三、何謂DLM?
DLM 的思想來自《The VAX/VMS Distributed Lock Manager》,在1984年首次應用于 VAX/VMS V4.0,接下來,我們以 Oracle RAC 為例,來說明下 DLM 的設計思路,
Oracle RAC 運行于集群之上,基于記憶體融合技術,使得 Oracle 資料庫具備高可用性和極致性能,如果集群內的一個節點發生故障,Oracle 可以繼續在其余的節點上運行,為了保證多個節點寫入記憶體 Page 程序的一致性,使用分布式鎖管理器(DLM)處理分布式鎖資源的分配和釋放,
如圖7所示,DLM 是一個去中心化的設計,集群中的所有節點都是對等的,每個節點都維護了部分鎖資訊,那么申請鎖時,應該由誰來決定鎖的分配呢 ? 在 DLM 中,每把鎖都有 Master 的概念,由 Master 統一協調、授權,決定是否允許加鎖或解鎖,每個節點都有可能成為鎖的 Master,每個節點管理這些鎖資源時,將這些鎖資源通過樹狀結構進行組織,通過對樹節點的父子繼承關系可以優化鎖的粒度,提升加解鎖的效率,
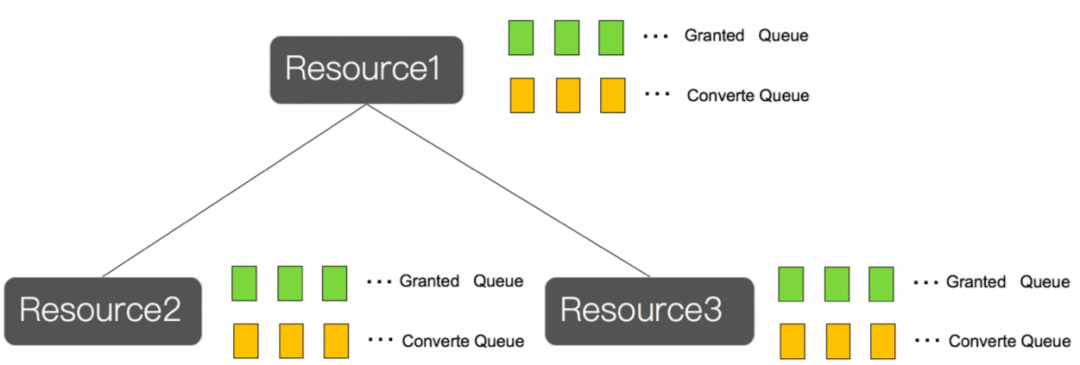
圖7 DLM的分布式鎖角色關系
在加鎖或解鎖程序中,涉及到以下幾類節點: a)Requester: 發起加鎖或解鎖的節點;b)DirectoryNode: 鎖的目錄節點,存放著鎖的 Master 被哪個節點鎖持有這類資訊;d)Master: 鎖的持有者,實際管理者,負責鎖的分配,釋放,下面我們用具體示例來描述分布鎖的分配、釋放的具體程序,例子里面存在A, B, C 3個節點,其中A 為 Requester,B 為 DirectoryNode, C 為 Master 節點,
3.1 加鎖程序
圖 8 是需要到其他節點上加鎖的程序,是所有加鎖情況中最耗時的情況,最多需要 2 輪互動,當資源在本地建立后,后續對于具有繼承關系的資源在本地加鎖就可以了,無需和其他節點進行互動:
1. 節點 A 對資源 R1 加鎖,首先在本地構造該鎖物件,也稱為鎖的 shadow,但此時 A 節點并未加鎖成功;
2. 節點 A,對資源 R1 通過哈希計算出 R1 對應的目錄管理者為節點 B;
3. 節點 A 請求節點 B,節點 B 的記錄上顯示 R1 的鎖的 Master 在 C 上;
4. 節點 A 向節點 C 發起對 R1 加鎖請求;
5. 節點 C 維護 R1 的鎖請求佇列,如果允許 A 加鎖,則回傳成功;
6. A 更新本地 R1 鎖 shadow 相關資訊,加鎖完成,
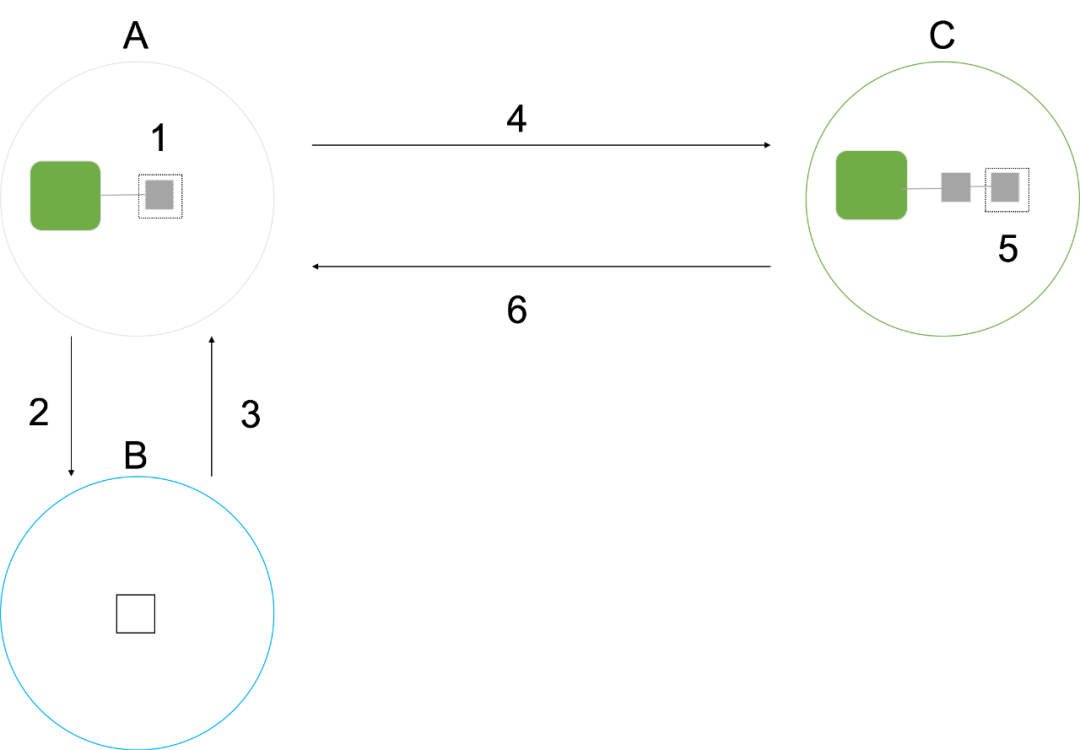
圖8 DLM的加鎖程序
3.2 解鎖程序
圖 9 展示了解鎖的程序,也比較直觀,如下三個步驟:
1. 節點 A 對資源 R1 解鎖,洗掉本地構造該鎖物件;
2. 節點 A 請求節點 C,請求將 A 的鎖釋放;
3. 若 A 是佇列中最后一個請求者,則節點 C 將發送請求給 B,將 R1 從目錄中摘除,以便后續其他節點能夠成為鎖的 Master ,否則,C 節點僅僅將 A 從 R1 的加鎖佇列移除,
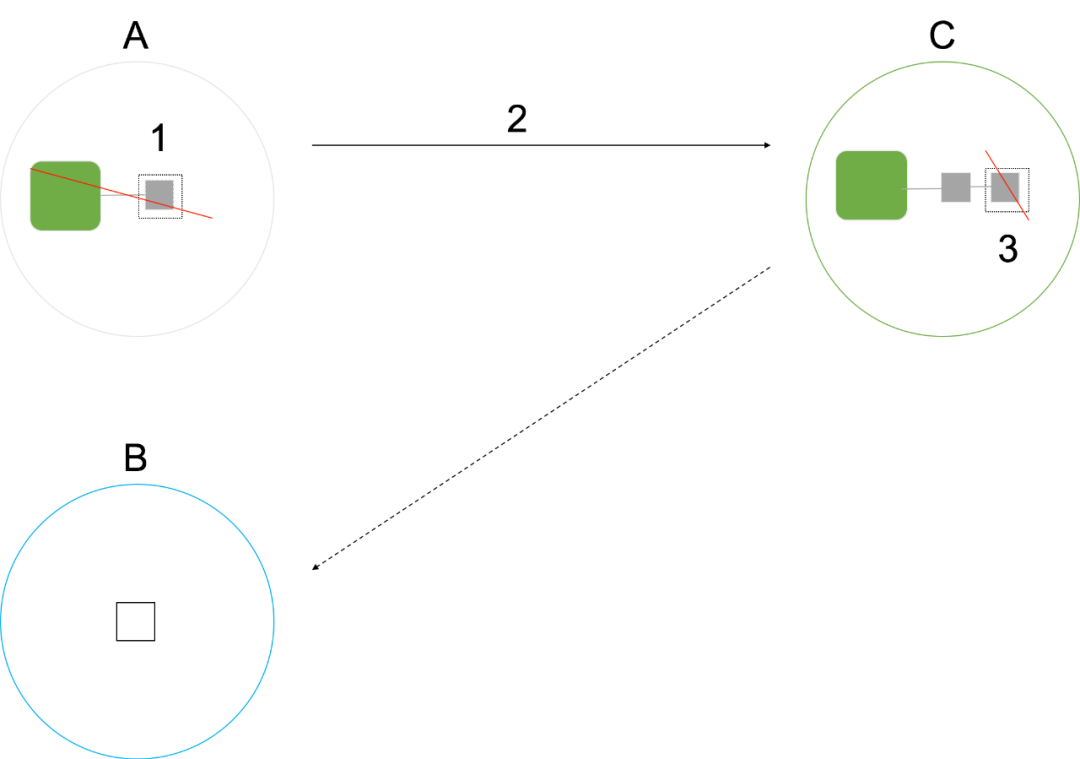
圖9 DLM的解鎖程序
3.3 成員變更
上述的加鎖和解鎖程序,僅僅是普通的一次加解鎖程序,那么集群出現節點故障、集群增刪節點,如何控制分布式鎖能夠被正常路由和分配呢?在 DLM 中,存在 Connection Manager 角色,除了負責各個節點的網路通信,還有一個重要功能是在集群節點發生增刪時,節點間首先選舉出 leader 節點進行協調,每個節點均有可能成為 leader 節點,在發生節點增加或洗掉時會下述程序:
- 重建節點拓補:leader 節點通過兩階段投票方式向集群其他節點發起通告,告知當前集群節點拓撲情況,其他節點有權利接受或拒絕該資訊,若對該拓撲圖未達成一致( 其他節點拒絕該拓撲資訊 ),leader 會休眠一段時間,其他節點執行 leader 選舉,新 leader 會向其他節點發出通告,通過該方式,實作集群中所有節點對全域拓撲圖以及鎖資源的路由演算法達成一致,在成員變更期間,仍可以發起搶鎖請求,但這些請求會在請求佇列中,并不能搶鎖成功,成員變更完后,這些請求按照發起順序被重新發出,
-
重建節點鎖資訊:leader 會通知其他節點對鎖資訊進行重建,重建程序拆分為多個階段,當所有節點完成一個階段后,leader 會通知集群所有節點進入下一個階段,在重建程序中,任一節點發生故障,均需要重新發起選舉和重建流程,重建分為以下階段: 1) 節點清空目錄資訊(鎖的路由表)以及節點持有的鎖,這是因為鎖資源資訊需要重新路由;2) 對于之前節點持有的鎖,按照原來的路由策略和順序重新發起加鎖,這個程序會將整個集群的鎖的目錄資訊重新建立起來,鎖的 Master 重新確定,由于每個節點對僅對自身重新加鎖,那么對于發生故障被洗掉節點而言,它之前持有的鎖 Master 會被新節點替代;3) 所有節點完成重新加鎖流程后,就可以執行正常的加解鎖流程了,
從上述程序,我們可以看到集群發生節點成員變更時,恢復程序是非常復雜的,為了減少這種情況的發生,當一個節點通信失敗后,會等待一定時間,超過該間隔后仍無法正常通信,才會執行洗掉節點的流程,一個節點如果僅是發生重啟,沒有達到需要觸發成員變更的閾值,那么只需要恢復這個節點就可以了,在這個程序中,僅僅該節點的鎖相關資訊丟失了,對于集群的其他節點沒有影響,重啟程序中,發往該節點的請求將會被 Pending 住,直到該節點恢復,
發生重啟的節點,上面大部分鎖仍能恢復,節點上的鎖由兩部分組成,一部分為Local Lock,表示發起加鎖的為節點自身,另一部分為 Remote Lock,表示由其他節點發起的加鎖,對于Local Lock,其他節點沒有資訊無法恢復,但不存在競爭,也無需恢復;對于 RemoteLock,可以從其他節點的 shadow 資訊中進行恢復,
3.4 些許思考
從成員變更程序,我們可以看到,Connection Manager 在DLM中承擔了極其關鍵的角色,這個也是整個設計中最為復雜的地方,當出現節點故障時,由 Connection Manager 統一協調鎖的重新分配,事實上承擔了我們所謂的分布式鎖管控平面的作業,DLM的優點是什么?負責分布式鎖資源分配的資料平面不用考慮整個系統的容錯,可以很均衡地讓更多機器參與到資源分配,并且鎖資源資訊不需要落盤,不需要走共識協議做容錯,只需要關注搶鎖的互斥性和搶鎖效率問題,這個搶鎖效率,服務水平擴展能力都將非常有優勢,
通過上述對 DLM 的加鎖,解鎖及成員變更程序進行剖析,這個里面還是有比較清晰的管控平面與資料平面的解耦設計,當然,實作程序很復雜,特別是failover這塊恢復邏輯,但這種思想還是非常好的,值得我們做架構設計時候借鑒,尤其要提到一點,不同于 DLM 起源的 1980 年代,后期業界有了 Paxos/Raft/EPaxos 等共識協議,我們也有了類似 ZooKeeper/Etcd 等基于共識協議的一致性協議,我們的分布式鎖管理器的管控平面完全可以用起來這些成熟的三方組件,
四、最佳實踐
阿里云存盤部門擁有著從塊存盤到檔案存盤,物件存盤,日志存盤,以及表格存盤等全球最完整的存盤產品體系,圖 10 展示了當前存盤產品采用的非常通用的基于磁區調度模型的系統架構,整個業務系統按照管控平面與資料平面來劃分,其中資料平面將用戶的存盤空間按照一定規則分割成若干磁區,在運行時一個磁區會被分配至某個服務器提供服務,一個服務器可以同時加載多個磁區,磁區不使用本機檔案系統存盤持久化資料,其擁有的全部資料均會存盤在盤古分布式檔案系統中的特定目錄,基于如此的磁區調度模型,當某個服務器發生宕機的時候,它承載的磁區需要被重新調度,快速遷移至其它健康的服務器繼續提供服務,
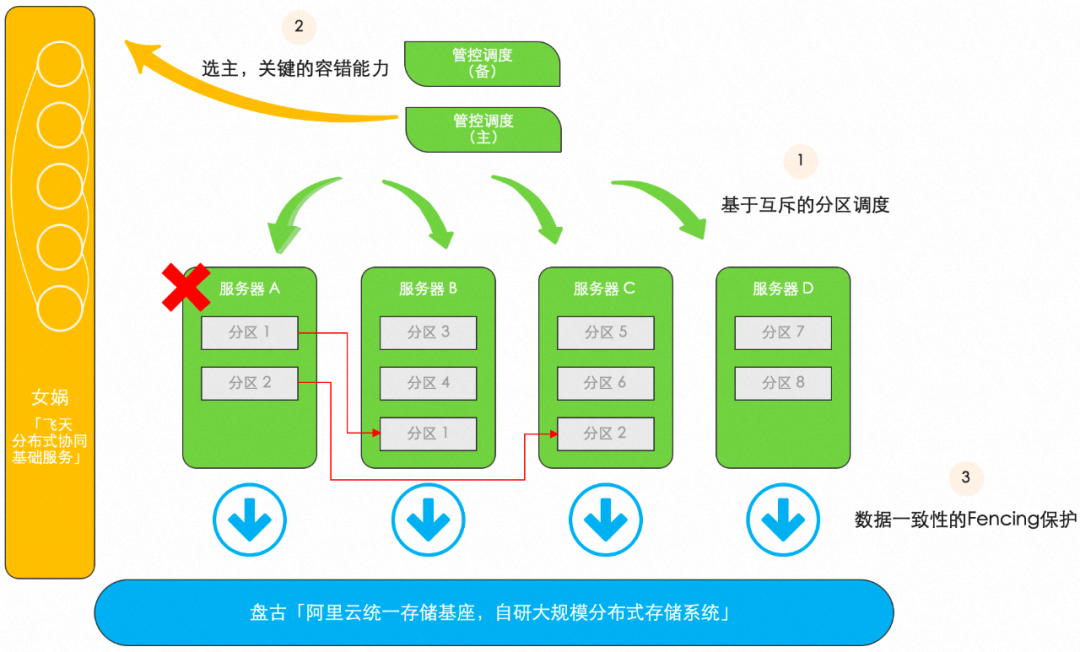
圖10 云存盤基于盤古+女媧的通用的磁區調度設計框架
在云存盤的磁區調度模型中,有關磁區資源的互斥訪問(即任何時刻任一個磁區必須至多為某一臺服務器所加載并提供讀寫訪問服務)是存盤系統提供資料一致性的基石,必須得到保障,事實上,云存盤的最佳實踐中有著類似 DLM 的設計哲學,將分布式鎖管理器的容錯問題抽離出來,借助女媧-飛天分布式協同基礎服務提供的選主功能來實作,進而可以專注在分布式鎖資源的調度策略:
1)管控調度器負責具體磁區資源的互斥分配,這里結合不同存盤業務的特殊需要,可以演進出不同的調度策略,從分布式鎖的均衡性,分布式鎖的搶鎖效率,分布式鎖的切換精度等不同維度做專項優化;2)分布式鎖管理器中最復雜的容錯能力,通過依賴女媧選主功能實作,并且通過女媧的服務發現能力實作管控節點平滑上下線;
3)存盤系統的資料最終均存放在盤古-飛天分布式存盤檔案系統,從具體的磁區資料,到管控調度的元資料,這些資訊都會放入盤古,盤古提供了高可靠高性能的存盤服務以及 Fencing 保護能力,保障資料一致性;
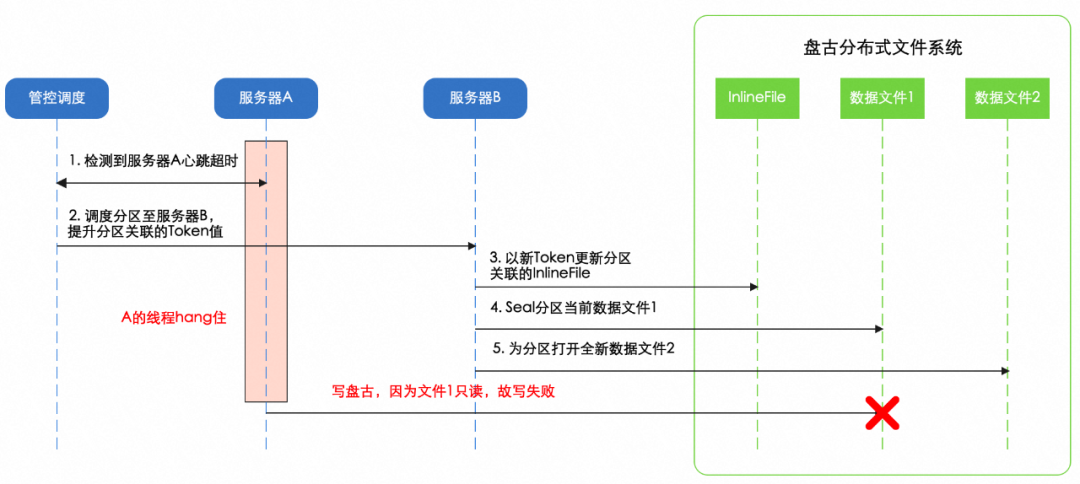
圖11 基于盤古分布式檔案系統提供的 Fencing 保護
分布式鎖提供 Fencing 保護的核心點是在訪問共享資源的時候帶上 Token 檢查,盤古作為存盤的統一的基座,通過引入特殊的 InlineFile 檔案型別,配合 SealFile 操作,實作了類似的 IO Fence 保護能力:a)SealFile 操作用來關閉已經打開的檔案,防止分布式鎖舊的占有者繼續寫資料;b)為每個磁區引入 InlineFile,針對盤古檔案的元資料操作關聯 InlineFile 相關的 CAS 判斷,進而可以防止分布式鎖舊的占有者打開新的檔案,如圖 11 所示,這兩塊功能結合起來事實上也是提供了存盤系統中的寫資料 Token 檢查支持,
我們看到,就云存盤的 DLM 實作中,有一個通用的基于磁區的調度器,有女媧提供容錯保障,由盤古提供資源的 Fencing 保護,這個就是云存盤的最佳實踐,
五、總結
分布式鎖提供了分布式環境下共享資源的互斥訪問,在分布式系統中應用十分廣泛,這篇文章從分布式鎖的性質出發,探討了分布式鎖的模型設計,就分布式鎖系統,我們探討了控制平面與資料平面解耦的架構設計,并介紹了阿里云存盤場景下分布式鎖的最佳實踐,期望我們的分享對于讀者朋友有所幫助,
參考文獻
1.How to do distributed locking -- Martin Kleppmann:https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html2.Distributed Lock Manager -- Apache Helix:https://helix.apache.org/1.0.2-docs/recipes/lock_manager.html3.Distributed Locks with Redis -- Redis:https://redis.io/docs/reference/patterns/distributed-locks/4.The VAX/VMS Distributed Lock Manager -- VMS Software:https://wiki.vmssoftware.com/Distributed_Lock_Manager5.Cache Fusion: Extending Shared-Disk Clusters with Shared Caches -- Oracle RAC:http://www.dia.uniroma3.it/~vldbproc/086_683.pdf
作者丨安凱歌(云秋)
本文來自博客園,作者:古道輕風,轉載請注明原文鏈接:https://www.cnblogs.com/88223100/p/Talk-about-the-design-model-of-distributed-locks.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/520706.html
標籤:其他