熱度已經過了,但還是覺得有必要從架構設計的角度來討論一下此事,并用以往我的經驗來設計一套負載能力更好一些的系統,
先說一下基本的架構思路:
- 最大限度的避免計算,靜態化
- 不用資料庫,更新類操作使用APPEND模式的文本檔案
- 流程最短,最好是客戶端訪問的第一臺服務器就能完成全部作業
- 善用CDN
- 客戶端負載均衡
需求分析
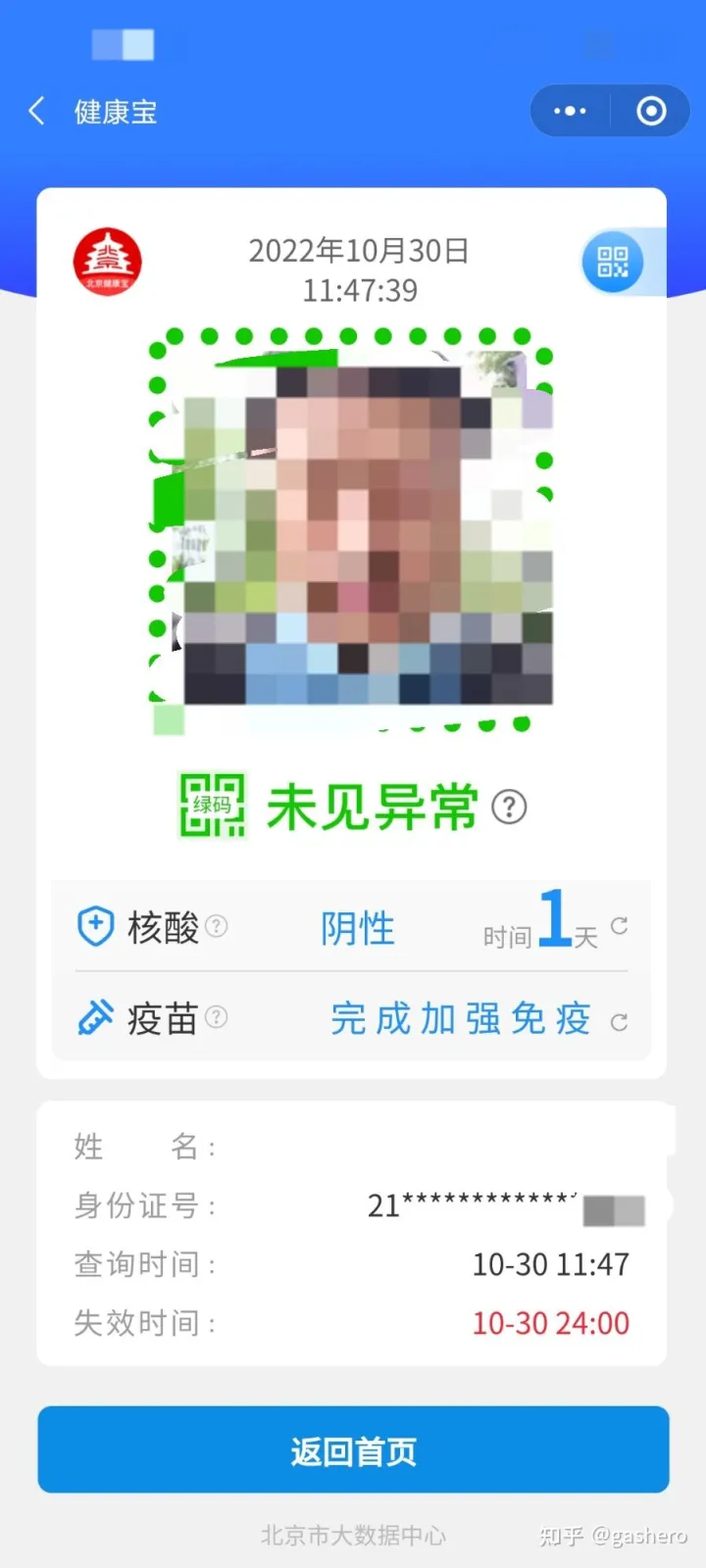
首先看一下北京>核酸的最高頻使用場景,進入一個場所時,掃碼登記,顯示健康碼狀態,下圖是我前些天的健康寶頁面結果,
這個基本的操作分解為幾個子操作:
- 掃碼:通過呼叫URL將人訪問過該地址的資訊記錄,以便有出現陽性時追訪
- 獲取當前人的健康碼狀態,顯示到頁面
頁面中顯示的欄位資訊包括:
- 健康碼狀態:綠碼/黃碼/紅碼等
- 最近一次核酸至今的時間:1天
- 疫苗接種情況
- 基本身份資訊:姓名、身份證號
- 時間:查詢時間,失效時間
常規設計思路與失效
一個只設計過常規MIS系統的工程師,滿足如上需求的常規做法如下:
- 建立資料庫,分別用幾個表格來記錄用戶資訊、核酸記錄、疫苗記錄、到訪記錄
- 用戶掃碼提交到訪資訊,就在到訪記錄表中INSERT一條新的記錄
- 健康碼頁面的顯示,依次去查詢如上四個表來獲取結果,其中后三個表需要排序后顯示創建日期最新的記錄
- 祭天,上線
然后遇到流量沖擊,系統崩潰,崩潰的原因分為幾個:
- 提交到訪資訊時,資料庫只能承受幾十到幾千QPS的INSERT請求,對其他掃碼請求無法處理,導致用戶提交的請求失敗
- 四個表的查詢,對資料庫造成了巨大的查詢壓力,資料庫服務器LOAD爆了
資深架構師的改造思路
5-10年經驗的工程師/架構師的典型改造思路:
- 資料庫橫向拆表到多個資料庫服務器,每個資料庫按照一定的負載均衡邏輯,只保留一部分資料,比如用戶ID整除10后的余數,分布到10臺資料庫,于是工程師熬夜加班,確保查詢時會根據負載均衡邏輯去正確的服務器查詢,提交到訪記錄時也會INSERT到正確的服務器
- 入口加負載均衡,DNS決議到多個機房的入口Load Balance,然后Load Balance再隨機分派給多臺后端服務器,多堆服務器提高處理能力
- 資料冗余降壓力:把最新一條的核酸記錄、疫苗記錄,作為冗余欄位寫入到用戶表里,這樣顯示健康寶頁面時就少查詢了兩個表
- 查詢時間、失效時間,兩個欄位在客戶端生成,不問資料庫要
- 搞個訊息佇列,先回傳給用戶查詢中,等個未知的時間都算完了再回傳
通過這樣一套操作下來,整個系統的負載能力能獲得幾十倍到幾百倍的提高,
但很不幸,有些時候就是會有數千倍甚至數萬倍的流量涌過來,
首問負責制
想要更強的負載能力,就需要若干改造思路,
所謂首問負責制,是讓用戶的請求盡量在第一個服務器就得到全部的滿足,如果不行,也要盡最大能力降低完成一個請求經歷的服務器數量,網路通常是整個系統里最慢的部分,服務器之間的互相呼叫也會嚴重的影響系統負載能力,
所以目標就是,讓用戶訪問的第一臺服務器就完成提交到訪記錄、獲取用戶健康寶全部資訊,
到訪記錄,扔掉資料庫,用檔案
用戶到訪記錄,是個寫入操作,是嚴重的系統瓶頸,解決辦法就是不用資料庫,用檔案來存盤到訪記錄,
例如我們在首問服務器上建立一個文本檔案,用檔案系統級的鎖來保護防止并發寫入,每當有用戶請求時,就用APPEND模式,在該檔案的末尾添加一行到訪記錄,比如{"UserID":userID,"PlaceID":PlaceID},這樣的性能相比資料庫會有數十倍的提高,如果資料庫為了查詢方便而引入了索引,則會快更多,
每天生成的資料檔案則收納起來備份存盤,
必然有讀者問,寫入檔案了,還怎么查詢,
首先查詢到訪記錄是個低頻需求,每個人都需要寫入,但沒有發現陽性要進行排查時是不需要進行查詢的,另外當需要查詢時,可以在收納起來的存盤里,用grep來進行查詢,這樣可以分別指定UserID或PlaceID來獲得結果,以及用另一套方式來在各個首問服務器上用grep查詢實時的到訪記錄,
把資料庫查詢變成了文本檔案的字串查詢,雖然查詢復雜度變成了線性的,但因為單個記錄變得極小,只有小幾十個位元組,按64位元組計算,查詢速度還是回比資料庫快很多倍,
用戶資訊KV庫
用戶資訊的庫也可以扔掉資料庫,用上一節類似的方式,把核酸記錄和疫苗記錄表,全都變成資料檔案,而且核酸記錄和疫苗記錄的檔案也不會被頻繁查詢,因為可以將其最新一條同樣冗余記錄到用戶資訊表里,
而用戶資訊表則是用檔案的方式記錄,每個用戶一個JSON檔案,檔案名對應UserID,檔案內容里包含該用戶的姓名、身份證號、最新一次核酸日期/結果、最新一次疫苗日期,然后該服務器把全部的用戶資訊檔案組織起來放在檔案系統里,簡單的辦法是用btrfs等檔案系統,把全部用戶的JSON檔案都放在一個目錄里,或者用古典的辦法,把UserID分成每2或3個字符一段,建立多層目錄來存盤,避免單個目錄里檔案過多,
總之,客戶端知道自己的UserID,而通過UserID可以輕易的定位到服務器上的用戶資訊JSON檔案,一個用戶的資訊內容是很少的,按256位元組算,1億用戶需要存盤空間約為25GB,這點容量顯然每臺服務器上都存一份是可行的,而且每個服務器(虛擬機)給分的記憶體大一點,還能讓這些資料庫都處在檔案系統快取中,獲得與記憶體相同的速度,比SSD更快,
用戶的核酸和疫苗資訊更新是低頻需求,一個3000萬人的城市,每天3000萬次請求頂天了,這點請求量可以輕易用一臺服務器來管理全部人的用戶資訊JSON檔案,然后同步到各個首問服務器提供查詢,因為每個首問服務器都包含了全部用戶的資訊,所以連資深架構師的后端負載均衡都免了,
全部用戶的資訊,可以考慮用rsync之類的,來從中心服務器同步到各個首問服務器,也可以考慮打包成zip檔案、BerkeleyDB之類的,來提供整體更新,用分開的檔案方式的妙用更大,
到這一步,事實上客戶端訪問自己的健康寶資訊,就已經變成了一次請求的兩步操作,第一步在到訪記錄檔案里加一行記錄,第二步是回傳用戶資訊JSON檔案,已經可以實作首問服務器的直接回應了,而做到這一步,就能實作了比最初設計數百倍到上千倍的性能提升,
使用大殺器CDN
如上的改造已經可以把所有現存服務器的性能發揮到機制,大概率此時的瓶頸在于服務器帶寬,CPU、記憶體、SSD IO大概率全都用不滿,但服務器的帶寬用滿了,以現代這些服務器的性能,每臺服務器跑滿10Gbps的帶寬來滿足這些需求都沒啥問題,
假定每個請求的網路通信為16KB,那么10Gbps可以到625,000 qps,或者說每秒完成62.5萬人的掃碼和獲取健康寶資訊,3000萬人的查詢,也就是48秒的事情,原則上單臺服務器就足以滿足一個3000萬人城市的健康寶查詢需求了,這625,000qps的請求,實際的SSD寫入按之前的64Byte,讀取按256Byte計算,對應了寫入速度40MB/s,讀取速度160MB/s,SSD表示加上讀取索引和檔案系統快取,還是很輕松的,
但更變態一點,如果我們需要更大的系統容量,可以輕易滿足全世界70億人的健康寶系統呢?
首問服務器的業務在設計時就擁有良好的橫向擴展能力,但帶寬就成了問題,簡單的解決辦法是引入CDN,我們的業務已經變成了URL里給出UserID就能獲取JSON的樣子了,這對CDN來說簡直是太完美的需求了,源站可以在HTTP里開啟etag,這樣沒更新的用戶JSON資料就可以回傳304給CDN的溯源請求,有更新的則可以輕易的同步給CDN,CDN的快取時長可以設定為1分鐘之類的,
客戶端也可以設定負載均衡策略,確保訪問服務器時優先問自己輪巡的CDN,比如自己的UserID尾號是1,那么就總是訪問域名尾號里帶有1的CDN域名,這樣可以使得CDN服務器的快取命中率獲得極大的提高,減小了快取濺出和溯源的壓力,
阿里云CDN的總帶寬是150Tbps,結合我們單臺服務器按10Gbps處理,可以容納15000臺服務器的服務能力,或者說請求處理能力9,375,000,000 qps,或者說每秒可以完成93.75億人的健康寶查詢請求,這差不多就夠了,
小結
2011年,我就是使用了如上方法的一部份,在果殼網的一次推廣活動中輕易頂住了壓力,彼時的果殼網已經有了近10臺服務器,但因為壓力沒那么大,所以平時主要就兩臺服務器在處理請求,日常每天20萬PV,30M的BGP帶寬,而那次推廣活動當天涌來了470萬PV,請求量比平時增加了23.5倍,高峰帶寬跑到1G多,但最終這些請求在這些架構和CDN帶寬的支持下,非常輕松的頂了過去,
縮短計算流程,用資料檔案替代資料庫,使用CDN,把這些技巧用好,用來應付大流量系統是很好用的,仔細分析如上的架構設計可知,負責回應用戶請求的部份甚至不需要編程,而是用良好配置的nginx就夠了,而資料同步,各類搜索則是可以用python腳本方便的實作,瓶頸在IO上,也根本凸顯不出各種語言的性能差異,良好的架構設計來極大的降低編碼實作的作業量,并幾十上百倍的提高系統性能,是享受架構設計樂趣的好方式,

作者:gashero
本文來自博客園,作者:古道輕風,轉載請注明原文鏈接:https://www.cnblogs.com/88223100/p/How-hard-it-is-to-make-a-nucleic-acid-system-that-doesnt-collapse.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/526918.html
標籤:其他
上一篇:01 設計模式入門
下一篇:01 設計模式入門