我正在構建一個 TensorFlow 概率貝葉斯網路。在下面的示例中,我有一個簡單的 2 分布輸出,但兩個輸出都來自添加到網路的最后一個分布(忽略任何先前添加的分布)。這是一個具體的代碼示例,顯示了我在說什么。
匯入一些包和一些幫助代碼
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow.keras import layers, Model
import tensorflow_probability as tfp
ZERO_BUFFER = 1e-5
dist_lookup = {
'normal': {
'dist': tfp.distributions.Normal,
'count': 2,
'inputs': {
'loc': False,
'scale': True,
}
},
'exponential': {
'dist': tfp.distributions.Exponential,
'count': 1,
'inputs': {
'rate': True,
}
}
}
現在讓我們創建一些要使用的假資料。
n = 100000
np.random.seed(123)
x1 = np.ones(shape=(n, 1))
x2 = 2 * np.ones(shape=(n, 1))
x3 = 3 * np.ones(shape=(n, 1))
X = pd.DataFrame(np.concatenate([x1, x2, x3], axis=1), columns=['x1', 'x2', 'x3']).astype(int)
現在讓我們構建一個玩具模型來演示我在說什么。請注意,我正在嘗試使用for回圈構建分布層。如果我通過鍵入來手動構建每個分布層,我不會得到下面的奇怪行為。只有當我在for回圈中定義它時才會發生這種情況,但是我需要構建一個具有動態分布數量的更大模型,因此我需要能夠使用某種回圈來構建它。
def create_dist_lambda_kwargs(prior_input_count: int, input_dict: dict, t):
kwargs = dict()
for j, (param, use_softplus) in enumerate(input_dict.items()):
x = prior_input_count j
if use_softplus:
kwargs[param] = ZERO_BUFFER tf.nn.softplus(t[..., prior_input_count j])
else:
kwargs[param] = t[..., prior_input_count j]
return kwargs
input_layer = layers.Input(X.shape[1])
# distributions = ['exponential', 'normal']
distributions = ['normal', 'exponential']
dists = list()
reshapes = list()
total = 0
for i in range(len(distributions)):
param_count = dist_lookup[distributions[i]]['count']
dist_class = dist_lookup[distributions[i]]['dist']
dists.append(
tfp.layers.DistributionLambda(
lambda t: dist_class(
**create_dist_lambda_kwargs(
prior_input_count=total,
input_dict=dist_lookup[distributions[i]]['inputs'],
t=t,
)
)
)(input_layer)
)
reshapes.append(layers.Reshape((1,))(dists[i]) )
total = param_count
total = 0
output = layers.Concatenate()(reshapes)
model = Model(input_layer, output)
model.compile(loss='mse', optimizer='adam', metrics=['mae', 'mse'])
奇怪的是,如果我洗掉上面回圈total = 0之后的行,for上面的代碼就會崩潰。我假設這與下面的另一個問題有關。
現在,如果我使用輸入資料進行預測(記住輸入資料的所有行都是相同的),那么我應該從我們可以繪制的兩個輸出分布中獲得一個大樣本。
pred = model.predict(X)
fig, (ax1, ax2) = plt.subplots(1, 2)
fig.set_size_inches(10, 5)
for i, ax in enumerate((ax1, ax2)):
ax.hist(pred[:, i], bins=50)
ax.set_xlabel(f'Output{i 1} Value')
ax.set_title(f'Output{i 1} Histogram')
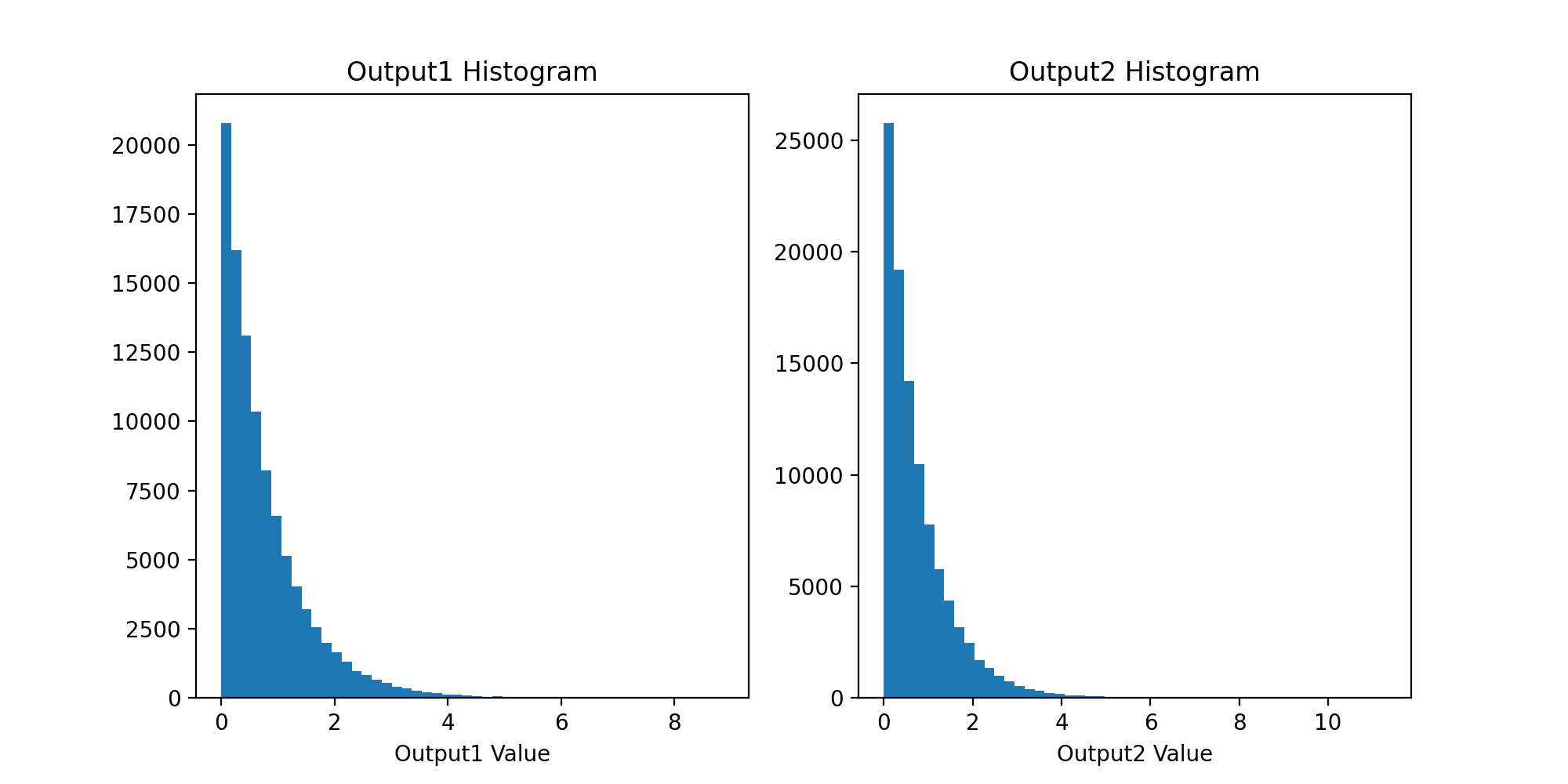
如果該'exponential'值是distributions串列中的最后一個值,則該圖類似于下圖;兩個輸出看起來都像指數分布
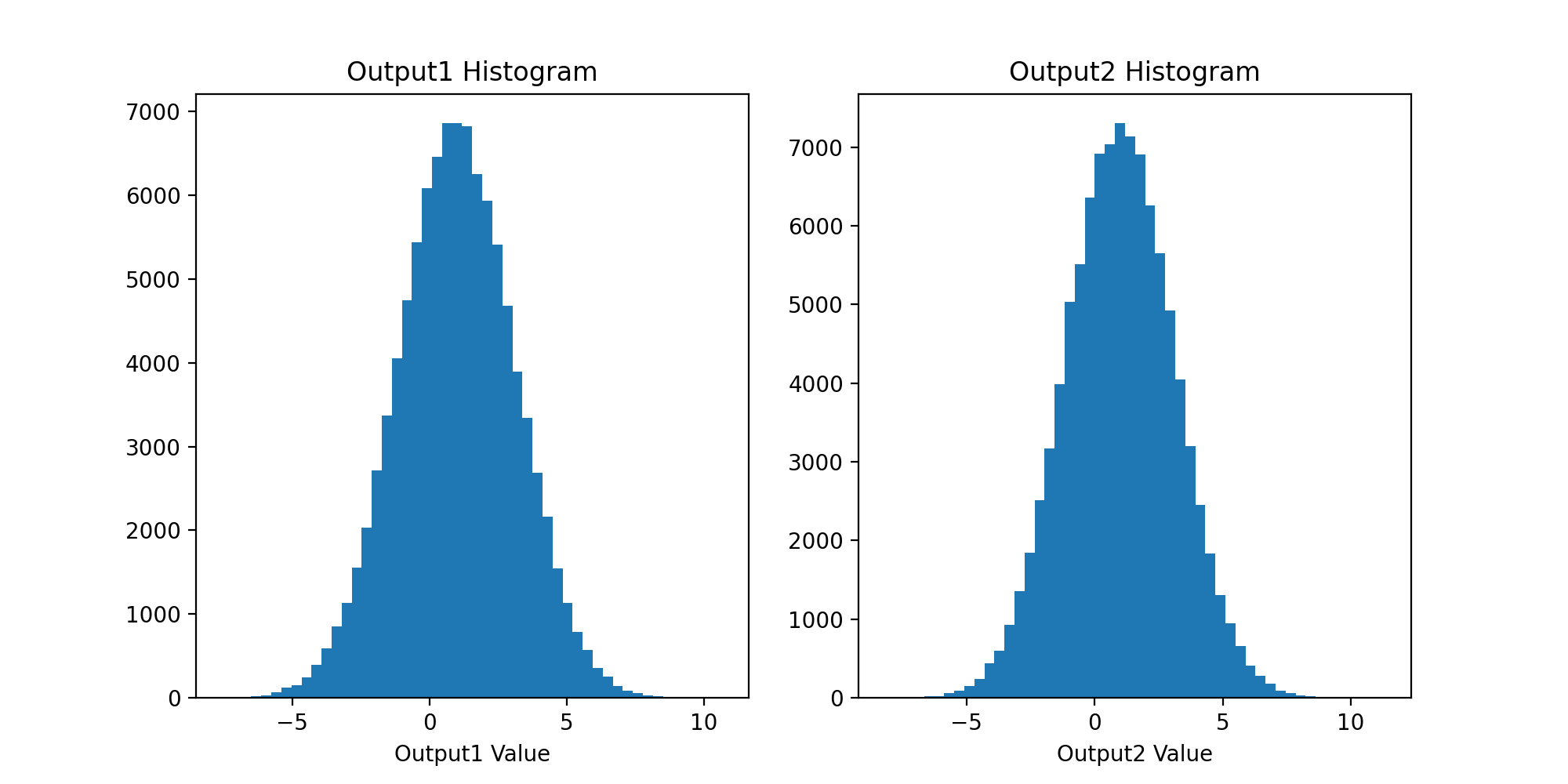
如果該'normal'值是distributions串列中的最后一個值,則該圖類似于下圖;兩個輸出看起來都像一個正態分布
所以,我的問題是為什么模型構建會被for回圈混淆,并將兩個輸出都視為回圈中創建的最后一個分布for,以及如何修復代碼以使其按預期作業?
uj5u.com熱心網友回復:
我還沒有閱讀整個問題,但是當您在回圈中創建 lambda 時,您肯定會遇到這個問題。
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/531699.html