我有一個 R 資料框,其中某些列的值(SNPs - Single Nucleotide Polymorphism)被編碼為 1,2 和 3,如下所示..(僅從 100 列中選擇了 2 列)
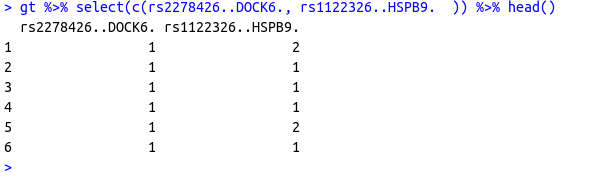
對于每個 SNP,我有另一個資料框用于這些代碼的基因型,如下所示
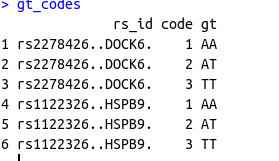
gt現在我想根據資料幀解碼資料幀中的代碼1,2和3,gt_codes并制作如下資料幀
我已將樣本資料作為dput. 有人可以幫幫我嗎。
structure(list(rs2278426..DOCK6. = c(1L, 1L, 1L, 1L, 1L, 1L,
1L, 2L, 1L, 1L), rs1122326..HSPB9. = c(2L, 1L, 1L, 1L, 2L, 1L,
1L, 2L, 1L, 1L)), row.names = c(NA, 10L), class = "data.frame")
structure(list(rs_id = c("rs2278426..DOCK6.", "rs2278426..DOCK6.",
"rs2278426..DOCK6.", "rs1122326..HSPB9.", "rs1122326..HSPB9.",
"rs1122326..HSPB9."), code = c(1, 2, 3, 1, 2, 3), gt = c("AA",
"AT", "TT", "AA", "AT", "TT")), class = "data.frame", row.names = c(NA,
-6L))
uj5u.com熱心網友回復:
這是一個基于
- 將原始資料從寬變長,
- 與映射表
gt_codes進行連接以用新值替換舊值,然后 - 再次將資料從長變寬。
library(dplyr)
library(tidyr)
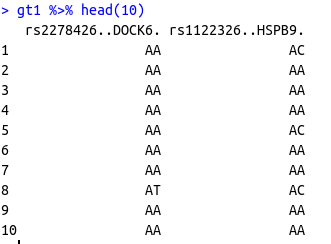
df %>%
mutate(row = 1:n()) %>%
pivot_longer(-row, names_to = "rs_id", values_to = "code") %>%
left_join(gt_codes, by = c("rs_id", "code")) %>%
select(-code) %>%
pivot_wider(names_from = "rs_id", values_from = "gt") %>%
select(-row)
## A tibble: 10 × 2
# rs2278426..DOCK6. rs1122326..HSPB9.
# <chr> <chr>
# 1 AA AC
# 2 AA AA
# 3 AA AA
# 4 AA AA
# 5 AA AC
# 6 AA AA
# 7 AA AA
# 8 AT AC
# 9 AA AA
#10 AA AA
樣本資料
gt_codes <- data.frame(
rs_id = c(rep("rs2278426..DOCK6.", 3), rep("rs1122326..HSPB9.", 3)),
code = c(1:3, 1:3),
gt = c("AA", "AT", "TT", "AA", "AC", "CC"))
df <- structure(list(rs2278426..DOCK6. = c(1L, 1L, 1L, 1L, 1L, 1L,
1L, 2L, 1L, 1L), rs1122326..HSPB9. = c(2L, 1L, 1L, 1L, 2L, 1L,
1L, 2L, 1L, 1L)), row.names = c(NA, 10L), class = "data.frame")
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/532171.html
標籤:r数据框
上一篇:用符號分隔數字列