
文章分三部分展開陳述:ZooKeeper 核心知識、ZooKeeper 的典型應用實作原理、ZooKeeper 在中間件的落地案例,
為了應對大流量,現代應用/中間件通常采用分布式部署,此時不得不考慮 CAP 問題,ZooKeeper(后文簡稱 ZK)是面向 CP 設計的一個開源的分布式協調框架,將那些復雜且容易出錯的分布式一致性服務封裝起來,構成一個高效可靠的原語集,并以一系列簡單易用的介面提供給用戶使用,分布式應用程式可以基于它實作諸如 資料發布/訂閱、負載均衡、命名服務、集群管理、Master 選舉、分布式鎖、分布式佇列 等功能,ZK 之所以能夠提供上述一套分布式資料一致性解決方案,核心在于其設計精妙的資料結構、watcher 機制、Zab 一致性協議等,下面將依次剖析,
資料結構
ZK 在記憶體中維護了一個類似檔案系統的樹狀資料結構實作命名空間(如下),樹中的節點稱為 znode,
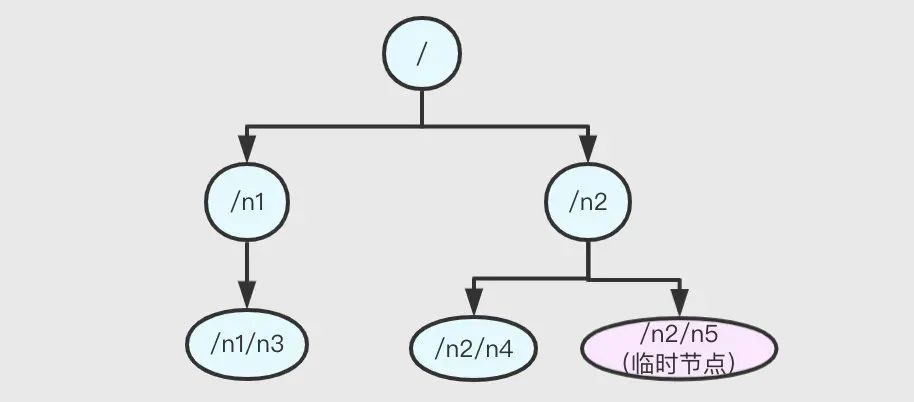
然而,znode 要比檔案系統的路徑復雜,既可以通過路徑訪問,又可以存盤資料,znode 具有四個屬性 data、acl、stat、children,如下
public class DataNode implements Record { byte data[]; Long acl; public StatPersisted stat; private Set<String> children = null; }
- data: znode 相關的業務資料均存盤在這里,但是,父節點不可存盤資料;
- children: 存盤當前節點的子節點參考資訊,因為記憶體限制,所以 znode 的子節點數不是無限的;
- stat: 包含 znode 節點的狀態資訊,比如: 事務 id、版本號、時間戳等,其中事務 id 和 ZK 的資料一直性、選主相關,下面將重點介紹;
- acl: 記錄客戶端對 znode 節點的訪問權限;
注意:znode 的資料操作具有原子性,讀操作將獲取與節點相關的所有資料,寫操作也將替換掉節點的所有資料,znode 可存盤的最大資料量是 1MB ,但實際上我們在 znode 的資料量應該盡可能小,因為資料過大會導致 zk 的性能明顯下降,每個 ZNode 都對應一個唯一的路徑,
事物 ID:Zxid
Zxid 由 Leader 節點生成,當有新寫入事件時,Leader 節點生成新的 Zxid,并隨提案一起廣播,Zxid 的生成規則如下:
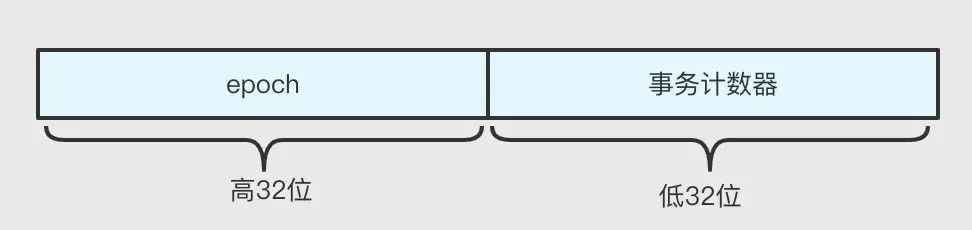
- epoch:任期/紀元,Zxid 的高 32 位, ZAB 協議通過 epoch 編號來區分 Leader 周期變化,每次一個 leader 被選出來,它都會有一個新的 epoch=(原來的 epoch+1),標識當前屬于那個 leader 的 統治時期;可以假設 leader 就像皇帝,epoch 則相當于年號,每個皇帝都有自己的年號;
- 事務計數器:Zxid 的低 32 位,每次資料變更,計數器都會加一;
zxid 是遞增的,所以誰的 zxid 越大,就表示誰的資料是最新的,每個節點都保存了當前最近一次事務的 Zxid,Zxid 對于 ZK 的資料一致性以及選主都有著重要意義,后邊在介紹相關知識時會重點講解其作用原理,
znode 型別
節點根據生命周期的不同可以將劃分為持久節點和臨時節點,持久節點的存活時間不依賴于客戶端會話,只有客戶端在顯式執行洗掉節點操作時,節點才消失;臨時節點的存活時間依賴于客戶端會話,當會話結束,臨時節點將會被自動洗掉(當然也可以手動洗掉臨時節點),注意:臨時節點不能擁有子節點,
節點型別是在創建時進行制定,后續不能改變,如create /n1 node1創建了一個資料為”node1”的持久節點/n1;在上述指令基礎上加上引數-e:create -e /n1/n3 node3,則創建了一個資料為”node3”的臨時節點 /n1/n3,
create 命令還有一個可選引數-s 用于指定創建的節點是否具有順序特性,創建順序節點時,zk 會在路徑后面自動追加一個 遞增的序列號 ,這個序列號可以保證在同一個父節點下是唯一的,利用該特性我們可以實作分布式鎖 等功能,
基于 znode 的上述兩組特性,兩兩組合后可構建 4 種型別的節點:
- PERSISTENT:永久節點
- EPHEMERAL:臨時節點
- PERSISTENT_SEQUENTIAL:永久順序節點
- EPHEMERAL_SEQUENTIAL:臨時順序節點
Watcher 監聽機制
Watcher 監聽機制是 ZK 非常重要的一個特性,ZK 允許 Client 端在指定節點上注冊 Watcher,監聽節點資料變更、節點洗掉、子節點狀態變更等事件,當特定事件發生時,ZK 服務端會異步通知注冊了相應 Watcher 的客戶端,通過該機制,我們可以利用 ZK 實作資料的發布和訂閱等功能,
Watcher 監聽機制由三部分協作完成:ZK 服務端、ZK 客戶端、客戶端的 WatchManager 物件,作業時,客戶端首先將 Watcher 注冊到服務端,同時將 Watcher 物件保存到客戶端的 Watch 管理器中,當 ZK 服務端監聽的資料狀態發生變化時,服務端會主動通知客戶端,接著客戶端的 Watch 管理器會觸發相關 Watcher 來回呼相應處理邏輯,
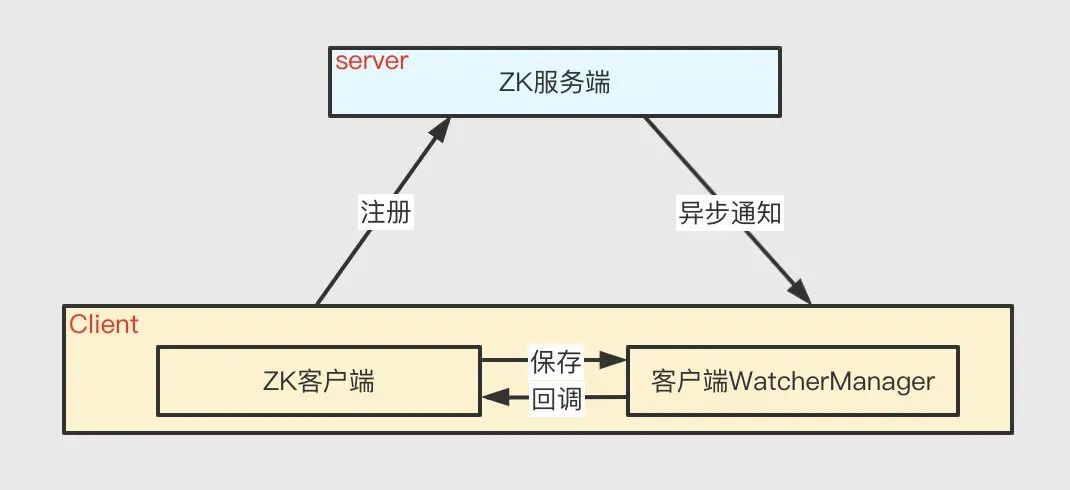
注意:
- watcher 變更通知是一次性的:當資料發生變化的時候, ZK 會產生一個 watcher 事件,并且會發送到客戶端,但是客戶端只會收到一次通知,如果后續這個節點再次發生變化,那么之前設定 Watcher 的客戶端不會再次收到訊息,可以通過回圈監聽去達到永久監聽效果,
- 客戶端 watcher 順序回呼:watcher 回呼是順序串行化執行的,只有回呼后客戶端才能看到節點最新的狀態,watcher 回呼邏輯不應太復雜,否則可能影響 watcher 執行,
- 不會告訴節點變化前后的具體內容:watchEvent 是最小的通信單元,結構上包含通知狀態、事件型別和節點路徑,但是,不會告訴節點變化前后的具體內容,
- 時效性:watcher 只有在當前 session 徹底失效時才會無效,若在 session 有效期內快速重連成功,則 watcher 依然存在,仍可收到事件通知,
ZK 集群
為了確保服務的高可用性,ZK 采用集群化部署,如下:
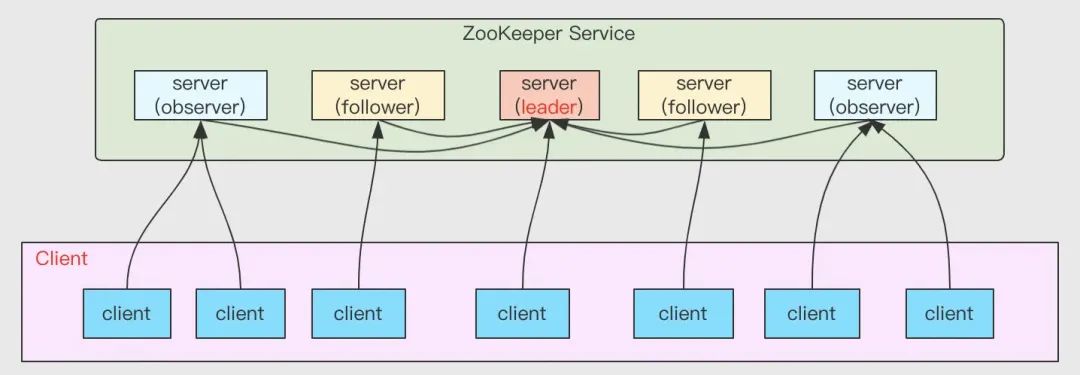
ZK 集群服務器有三種角色:Leader、Follower 和 Observer
- Leader:一個 ZK 集群同一時間只會有一個實際作業的 Leader,它會發起并維護與各 Follwer 及 Observer 間的心跳,所有的寫操作必須要通過 Leader 完成再由 Leader 將寫操作廣播給其它服務器,
- Follower:一個 ZK 集群可同時存在多個 Follower,它會回應 Leader 的心跳,Follower 可直接處理并回傳客戶端的讀請求,同時會將寫請求轉發給 Leader 處理,參與事務請求 Proposal 的投票及 Leader 選舉投票,
- Observer:Observer 是 3.3.0 版本開始引入的一個服務器角色,一個 ZK 集群可同時存在多個 Observer, 功能與 Follower 類似,但是,不參與投票,
“早期的 ZooKeeper 集群服務運行程序中,只有 Leader 服務器和 Follow 服務器,隨著集群規模擴大,follower 變多,ZK 在創建節點和選主等事務性請求時,需要一半以上節點 AC,所以導致性能下降寫入操作越來越耗時,follower 之間通信越來越耗時,為了解決這個問題,就引入了觀察者,可以處理讀,但是不參與投票,既保證了集群的擴展性,又避免過多服務器參與投票導致的集群處理請求能力下降,”
ZK 集群中通常有很多服務器,那么如何區分不同的服務器的角色呢?可以通過服務器的狀態進行區分
- LOOKING:尋找 Leader 狀態,當服務器處于該狀態時,它會認為當前集群中沒有 Leader,因此需要進入 Leader 選舉狀態,
- LEADING:領導者狀態,表明當前服務器角色是 Leader,
- FOLLOWING:跟隨者狀態,同步 leader 狀態,參與投票,表明當前服務器角色是 Follower,
- OBSERVING:觀察者狀態,同步 leader 狀態,不參與投票,表明當前服務器角色是 Observer,
ZK 集群是一主多從的結構,所有的所有的寫操作必須要通過 Leader 完成,Follower 可直接處理并回傳客戶端的讀請求,那么如何保證從 Follower 服務器讀取的資料與 Leader 寫入的資料的一致性呢?Leader 萬一由于某些原因崩潰了,如何選出新的 Leader,如何保證資料恢復?Leader 是怎么選出來的?
Zab 一致性協議
ZK 專門設計了 ZAB 協議(Zookeeper Atomic Broadcast)來保證主從節點資料的一致性,下面分別從 client 向 Leader 和 Follower 寫資料場景展開陳述,
寫 Leader 場景資料一致性
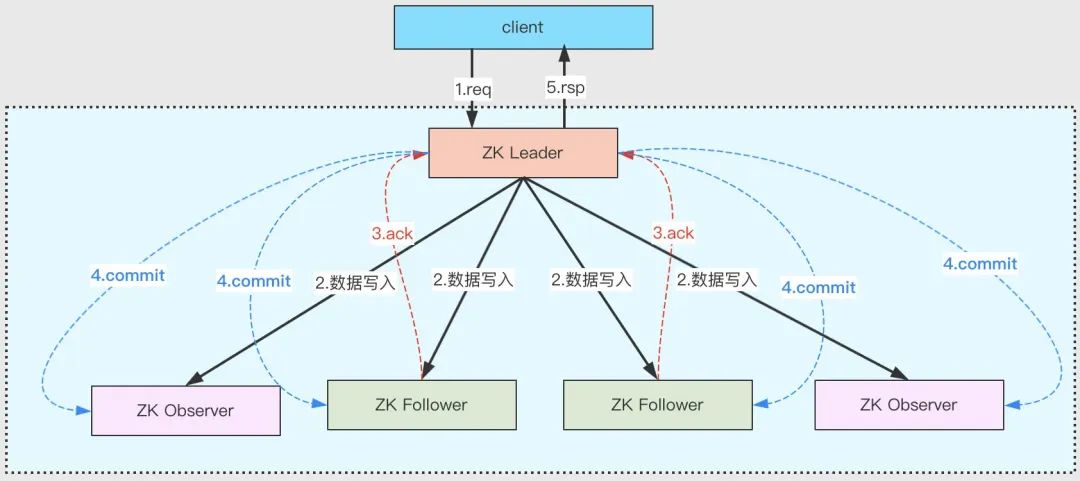
- 客戶端向 Leader 發起寫請求
- Leader 將寫請求以 Proposal 的形式發給所有 Follower 并等待 ACK
- Follower 收到 Leader 的 Proposal 后回傳 ACK
- Leader 得到過半數的 ACK(Leader 對自己默認有一個 ACK)后向所有的 Follower 和 Observer 發送 Commmit
- Leader 將處理結果回傳給客戶端
注意:
- Leader 不需要得到所有 Follower 的 ACK,只要收到過半的 ACK 即可,同時 Leader 本身對自己有一個 ACK,上圖中有 4 個 Follower,只需其中兩個回傳 ACK 即可,因為(2+1) / (4+1) > 1/2
- Observer 雖然無投票權,但仍須同步 Leader 的資料從而在處理讀請求時可以回傳盡可能新的資料
寫 Follower 場景資料一致性
1.客戶端向 Follower 發起寫請求, Follower 將寫請求轉發給 Leader 處理;
- 其它流程與直接寫 Leader 無任何區別
注意:Observer 與 Follower 寫流程相同
最終一致性
Zab 協議訊息廣播使用兩階段提交的方式,達到主從資料的最終一致性,為什么是最終一致性呢?從勺ò干知資料寫入程序核心分成下面兩階段:
- 第一階段:Leader 資料寫入事件作為提案廣播給所有 Follower 結點;可以寫入的 Follower 結點回傳確認資訊 ACK,
- 第二階段:Leader 收到一半以上的 ACK 資訊后確認寫入可以生效,向所有結點廣播 COMMIT 將提案生效,
根據寫入程序的兩階段的描述,可以知道 ZooKeeper 保證的是最終一致性,即 Leader 向客戶端回傳寫入成功后,可能有部分 Follower 還沒有寫入最新的資料,所以是最終一致性,ZooKeeper 保證的最終一致性也叫順序一致性,即每個結點的資料都是嚴格按事務的發起順序生效的,ZooKeeper 集群的寫入是由 Leader 結點協調的,真實場景下寫入會有一定的并發量,那 Zab 協議的兩階段提交是如何保證事務嚴格按順序生效的呢?ZK 事物的順序性是借助上文中的 Zxid 實作的,Leader 在收到半數以上 ACK 后會將提案生效并廣播給所有 Follower 結點,Leader 為了保證提案按 ZXID 順序生效,使用了一個 ConcurrentHashMap,記錄所有未提交的提案,命名為 outstandingProposals,key 為 ZXID,Value 為提案的資訊,對 outstandingProposals 的訪問邏輯如下:
- Leader 每發起一個提案,會將提案的 ZXID 和內容放到 outstandingProposals 中,作為待提交的提案;
- Leader 收到 Follower 的 ACK 資訊后,根據 ACK 中的 ZXID 從 outstandingProposals 中找到對應的提案,對 ACK 計數;
- 執行 tryToCommit 嘗試將提案提交:判斷流程是,先判斷當前 ZXID 之前是否還有未提交提案,如果有,當前提案暫時不能提交;再判斷提案是否收到半數以上 ACK,如果達到半數則可以提交;如果可以提交,將當前 ZXID 從 outstandingProposals 中清除并向 Followers 廣播提交當前提案;
Leader 是如何判斷當前 ZXID 之前是否還有未提交提案的呢?由于前提是保證順序提交的,所以 Leader 只需判斷 outstandingProposals 里,當前 ZXID 的前一個 ZXID 是否存在,代碼如下:

所以 ZooKeeper 是通過兩階段提交保證資料的最終一致性,并且通過嚴格按照 ZXID 的順序生效提案保證其順序一致性的,
選主原理
ZK 中默認的并建議使用的 Leader 選舉演算法是:基于 TCP 的 FastLeaderElection,在分析選舉原理前,先介紹幾個重要的引數,
- 服務器 ID(myid):每個 ZooKeeper 服務器,都需要在資料檔案夾下創建一個名為 myid 的檔案,該檔案包含整個 ZooKeeper 集群唯一的 ID(整數),該引數在選舉時如果無法通過其他判斷條件選擇 Leader,那么將該 ID 的大小來確定優先級,
- 事務 ID(zxid):單調遞增,值越大說明資料越新,權重越大,
- 邏輯時鐘(epoch-logicalclock):同一輪投票程序中的邏輯時鐘值是相同的,每投完一次值會增加,
ZK 的 leader 選舉存在兩類,一個是服務器啟動時 leader 選舉,另一個是運行程序中服務器宕機時的 leader 選舉,下面依次展開介紹,以下兩節引自從 0 到 1 詳解 ZooKeeper 的應用場景及架構 ,
服務器啟動時的 leader 選舉
1、各自推選自己:ZooKeeper 集群剛啟動時,所有服務器的 logicClock 都為 1,zxid 都為 0,各服務器初始化后,先把第一票投給自己并將它存入自己的票箱,同時廣播給其他服務器,此時各自的票箱中只有自己投給自己的一票,如下圖所示:
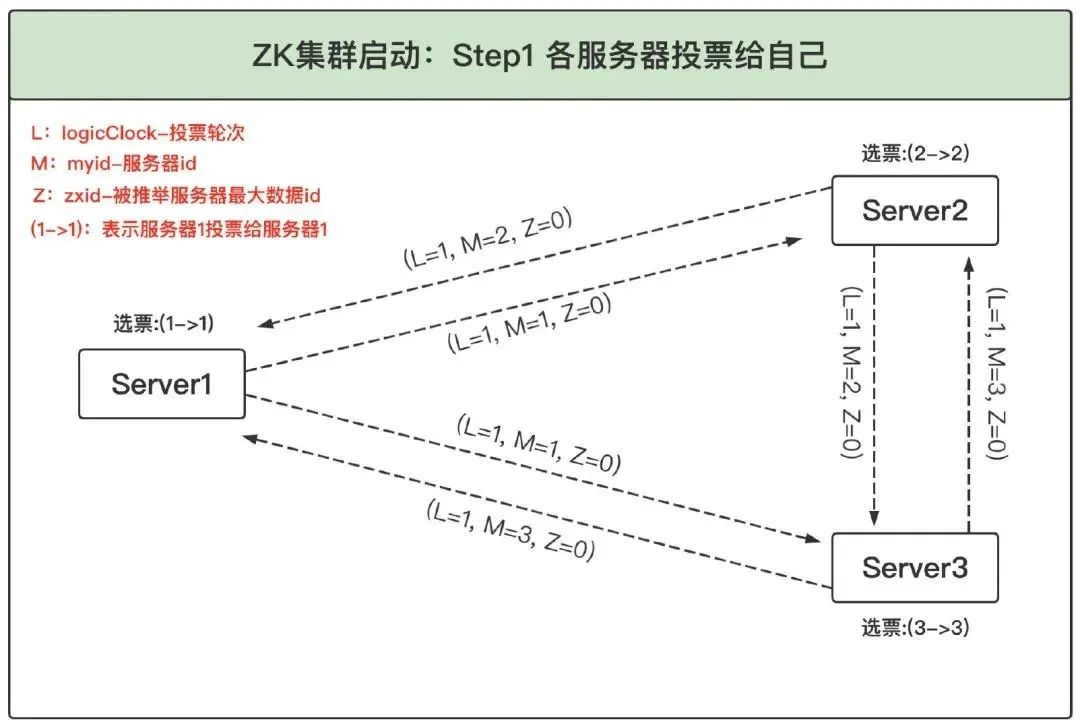
2、更新選票:第一步中各個服務器先投票給自己,并把投給自己的結果廣播給集群中的其他服務器,這一步其他服務器接收到廣播后開始更新選票操作,以 Server1 為例流程如下:
(1)Server1 收到 Server2 和 Server3 的廣播選票后,由于 logicClock 和 zxid 都相等,此時就比較 myid;
(2)Server1 收到的兩張選票中 Server3 的 myid 最大,此時 Server1 判斷應該遵從 Server3 的投票決定,將自己的票改投給 Server3,接下來 Server1 先清空自己的票箱(票箱中有第一步中投給自己的選票),然后將自己的新投票(1->3)和接收到的 Server3 的(3->3)投票一起存入自己的票箱,再把自己的新投票決定(1->3)廣播出去,此時 Server1 的票箱中有兩票:(1->3),(3->3);
(3)同理,Server2 收到 Server3 的選票后也將自己的選票更新為(2->3)并存入票箱然后廣播,此時 Server2 票箱內的選票為(2->3),(3->3);
(4)Server3 根據上述規則,無須更新選票,自身的票箱內選票仍為(3->3);
(5)Server1 與 Server2 重新投給 Server3 的選票廣播出去后,由于三個服務器最新選票都相同,最后三者的票箱內都包含三張投給服務器 3 的選票,
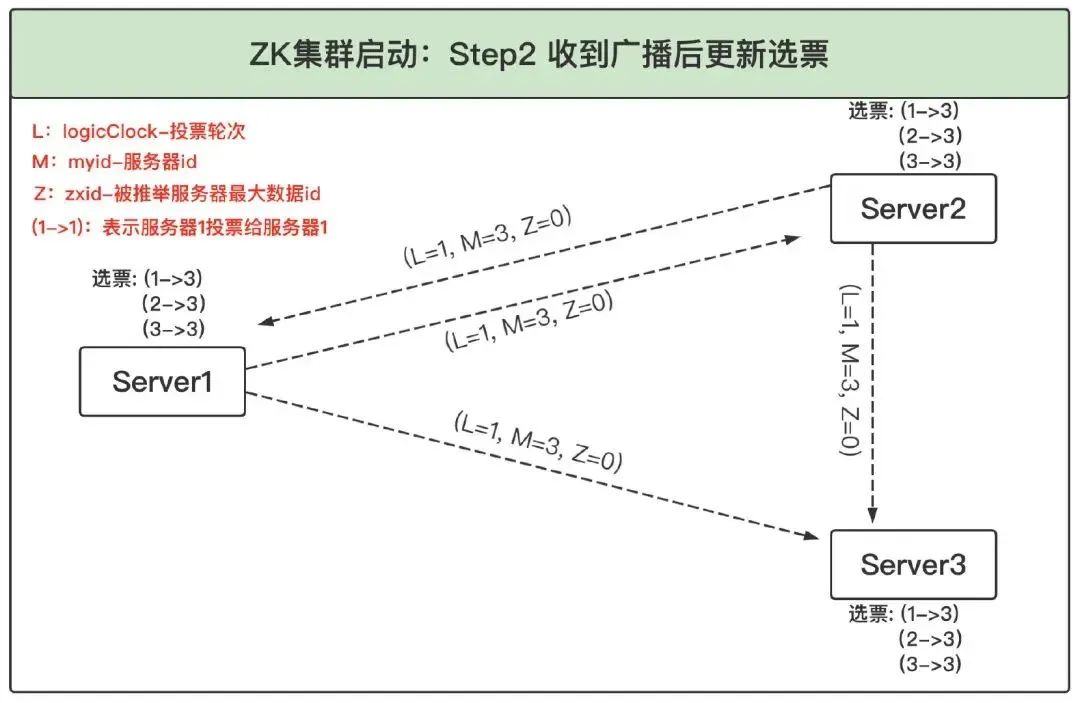
3、根據選票確定角色:根據上述選票,三個服務器一致認為此時 Server3 應該是 Leader,因此 Server1 和 Server2 都進入 FOLLOWING 狀態,而 Server3 進入 LEADING 狀態,之后 Leader 發起并維護與 Follower 間的心跳,
運行時 Follower 重啟選舉
本節討論 Follower 節點發生故障重啟或網路產生磁區恢復后如何進行選舉,
1、Follower 重啟投票給自己:Follower 重啟,或者發生網路磁區后找不到 Leader,會進入 LOOKING 狀態并發起新的一輪投票,
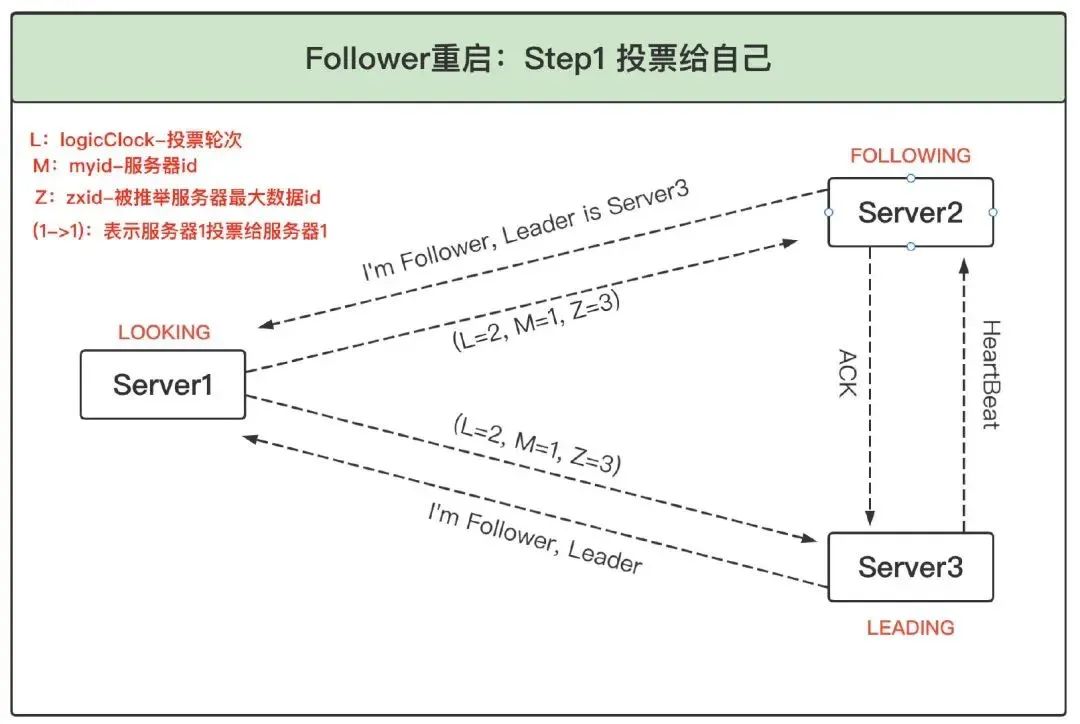
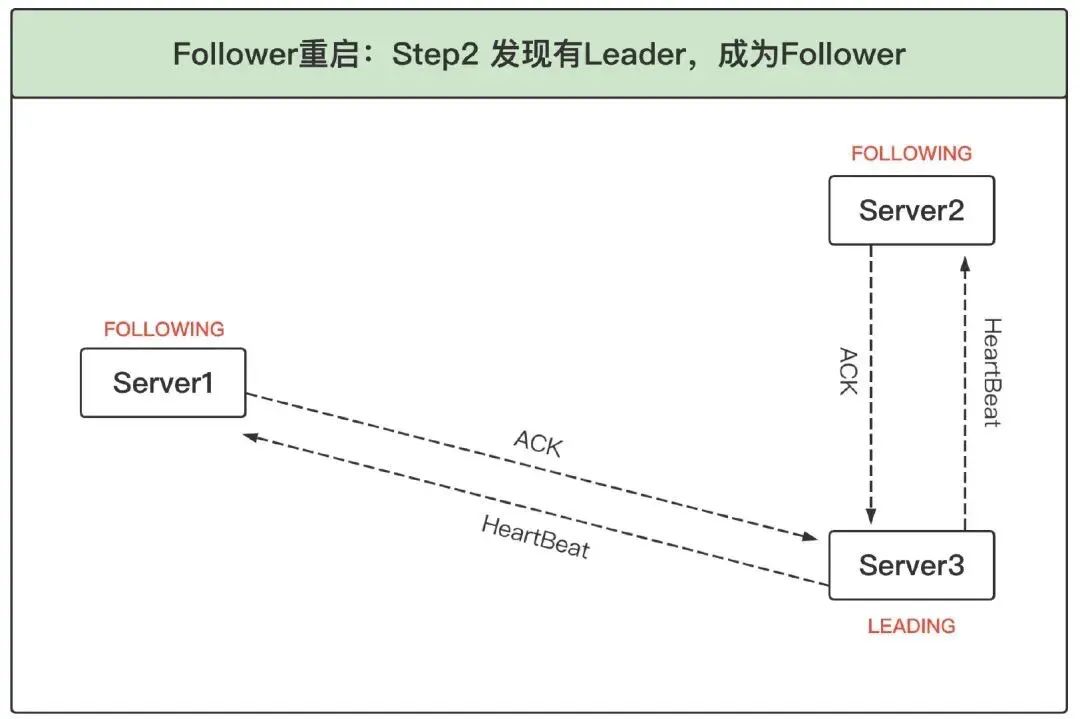
2、發現已有 Leader 后成為 Follower:Server3 收到 Server1 的投票后,將自己的狀態 LEADING 以及選票回傳給 Server1,Server2 收到 Server1 的投票后,將自己的狀態 FOLLOWING 及選票回傳給 Server1,此時 Server1 知道 Server3 是 Leader,并且通過 Server2 與 Server3 的選票可以確定 Server3 確實得到了超過半數的選票,因此服務器 1 進入 FOLLOWING 狀態,
運行時 Leader 重啟選舉
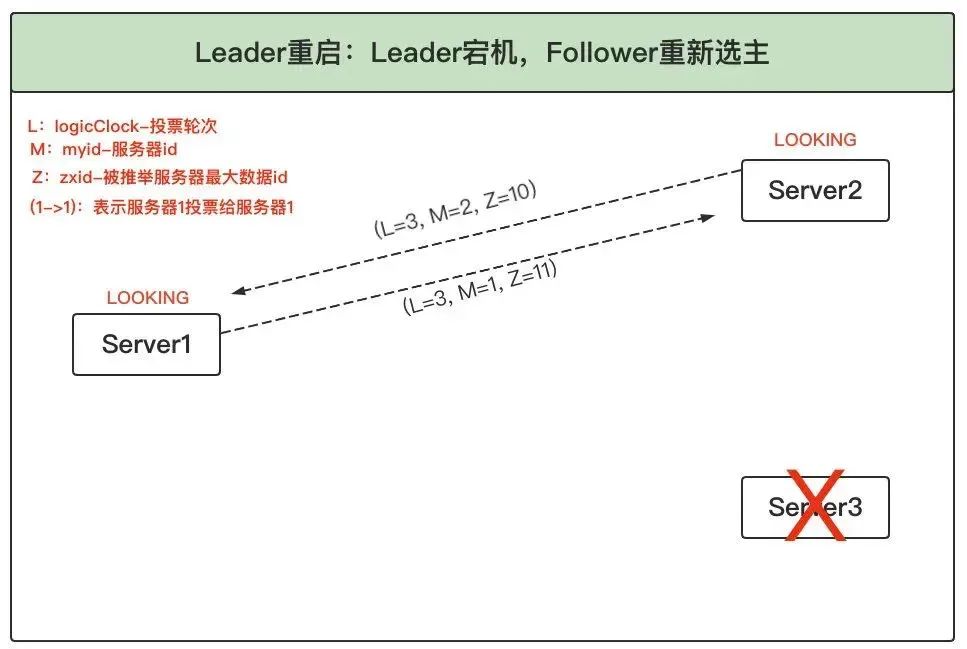
Follower 發起新投票:Leader(Server3)宕機后,Follower(Server1 和 2)發現 Leader 不作業了,因此進入 LOOKING 狀態并發起新的一輪投票,并且都將票投給自己,同時將投票結果廣播給對方,
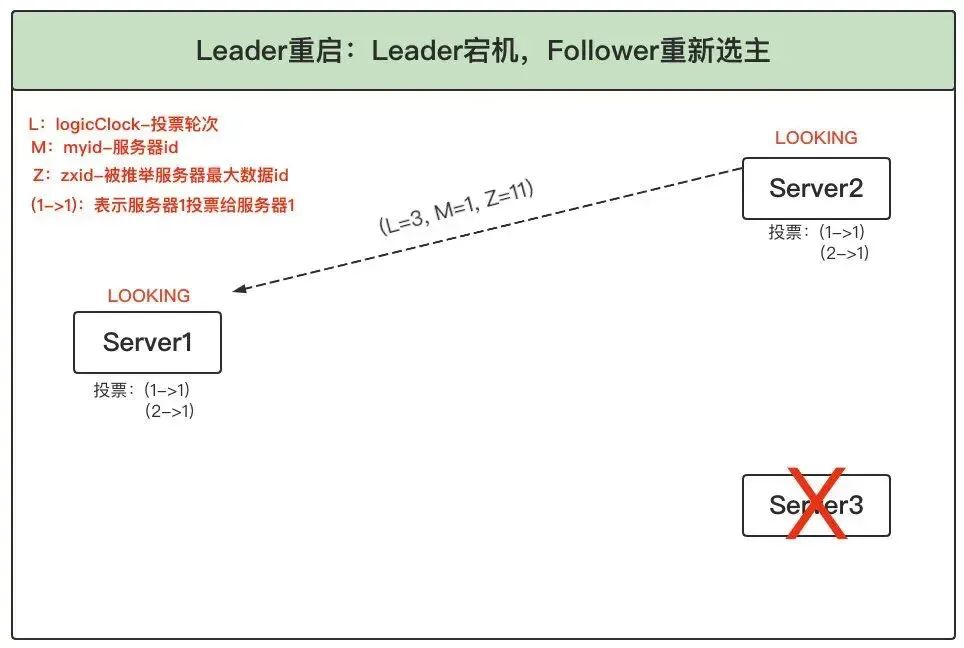
2、更新選票:(1)Server1 和 2 根據外部投票確定是否要更新自身的選票,這里跟之前的選票 PK 流程一樣,比較的優先級為:logicLock > zxid > myid,這里 Server1 的引數(L=3, M=1, Z=11)和 Server2 的引數(L=3, M=2, Z=10),logicLock 相等,zxid 服務器 1 大于服務器 2,因此服務器 2 就清空已有票箱,將(1->1)和(2->1)兩票存入票箱,同時將自己的新投票廣播出去 (2)服務器 1 收到 2 的投票后,也將自己的票箱更新,
3、重新選出 Leader:此時由于只剩兩臺服務器,服務器 1 投票給自己,服務器 2 投票給 1,所以 1 當選為新 Leader,
4、舊 Leader 恢復發起選舉:之前宕機的舊 Leader 恢復正常后,進入 LOOKING 狀態并發起新一輪領導選舉,并將選票投給自己,此時服務器 1 會將自己的 LEADING 狀態及選票回傳給服務器 3,而服務器 2 將自己的 FOLLOWING 狀態及選票回傳給服務器 3,
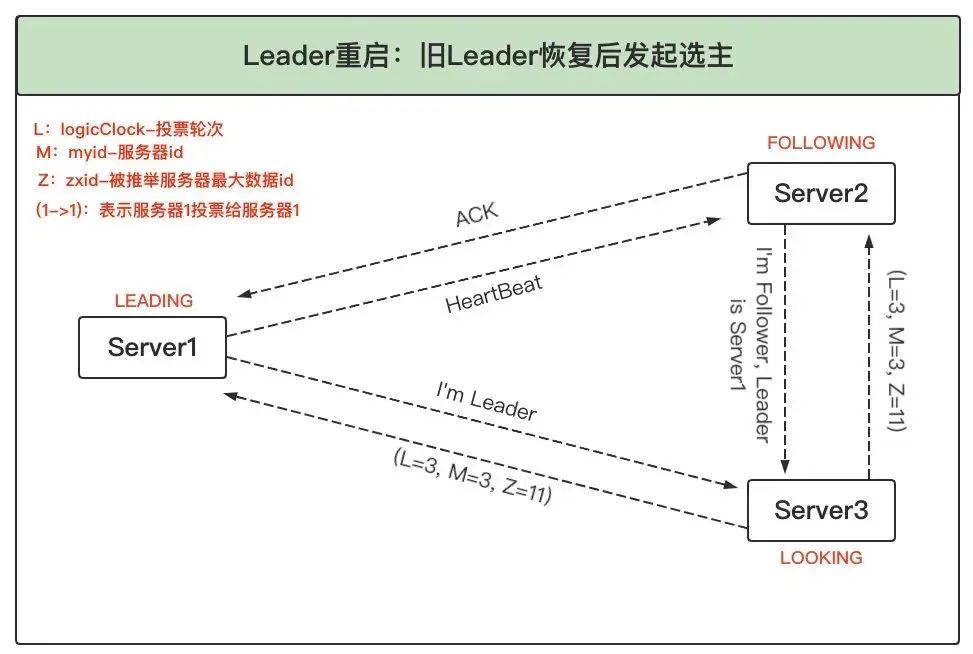
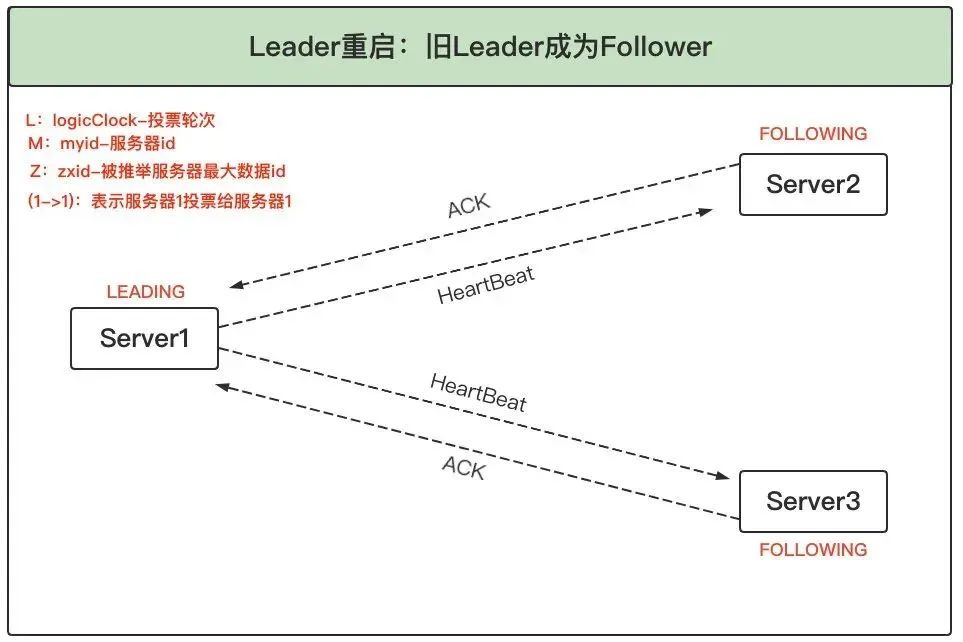
5、舊 Leader 成為 Follower:服務器 3 了解到 Leader 為服務器 1,且根據選票了解到服務器 1 確實得到過半服務器的選票,因此自己進入 FOLLOWING 狀態,
腦裂
對于一主多從類的集群應用,通常要考慮腦裂問題,腦裂會導致資料不一致,那么,什么是腦裂?簡單點來說,就是一個集群有兩個 master,通常腦裂產生原因如下:
- 假死:由于心跳超時(網路原因導致的)認為 Leader 死了,但其實 Leader 還存活著,
- 腦裂:由于假死會發起新的 Leader 選舉,選舉出一個新的 Leader,但舊的 Leader 網路又通了,導致出現了兩個 Leader ,有的客戶端連接到老的 Leader,而有的客戶端則連接到新的 Leader,
通常解決腦裂問題有 Quorums(法定人數)方式、Redundant communications(冗余通信)方式、仲裁、磁盤鎖等方式,ZooKeeper 采用 Quorums 這種方式來防止“腦裂”現象,只有集群中超過半數節點投票才能選舉出 Leader,
典型應用場景
資料發布/訂閱
我們可基于 ZK 的 Watcher 監聽機制實作資料的發布與訂閱功能,ZK 的發布訂閱模式采用的是推拉結合的方式實作的,實作原理如下:
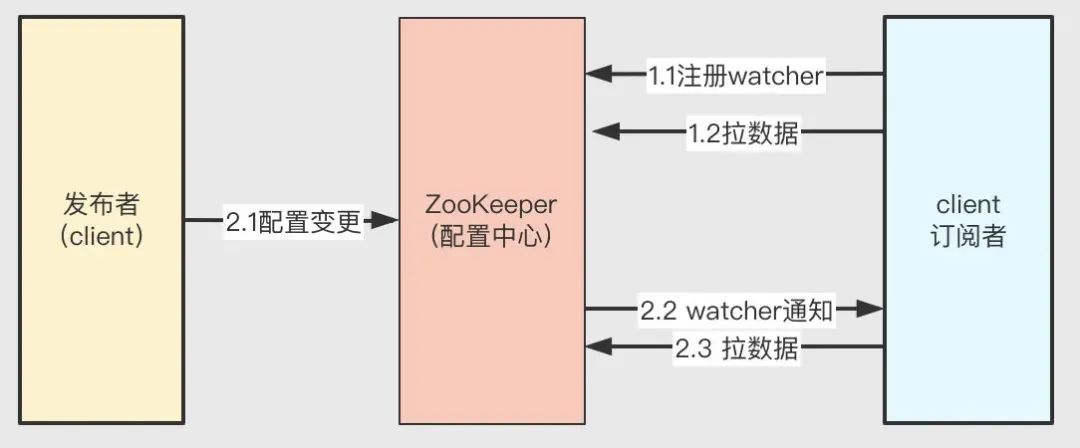
- 當集群中的服務啟動時,客戶端向 ZK 注冊 watcher 監聽特定節點,并從節點拉取資料獲取配置資訊;
- 當發布者變更配置時,節點資料發生變化,ZK 會發送 watcher 事件給各個客戶端;客戶端在接收到 watcher 事件后,會從該節點重新拉取資料獲取最新配置資訊,
注意:Watch 具有一次性,所以當獲得服務器通知后要再次添加 Watch 事件,
負載均衡
利用 ZK 的臨時節點、watcher 機制等特性可實作負載均衡,具體思路如下:
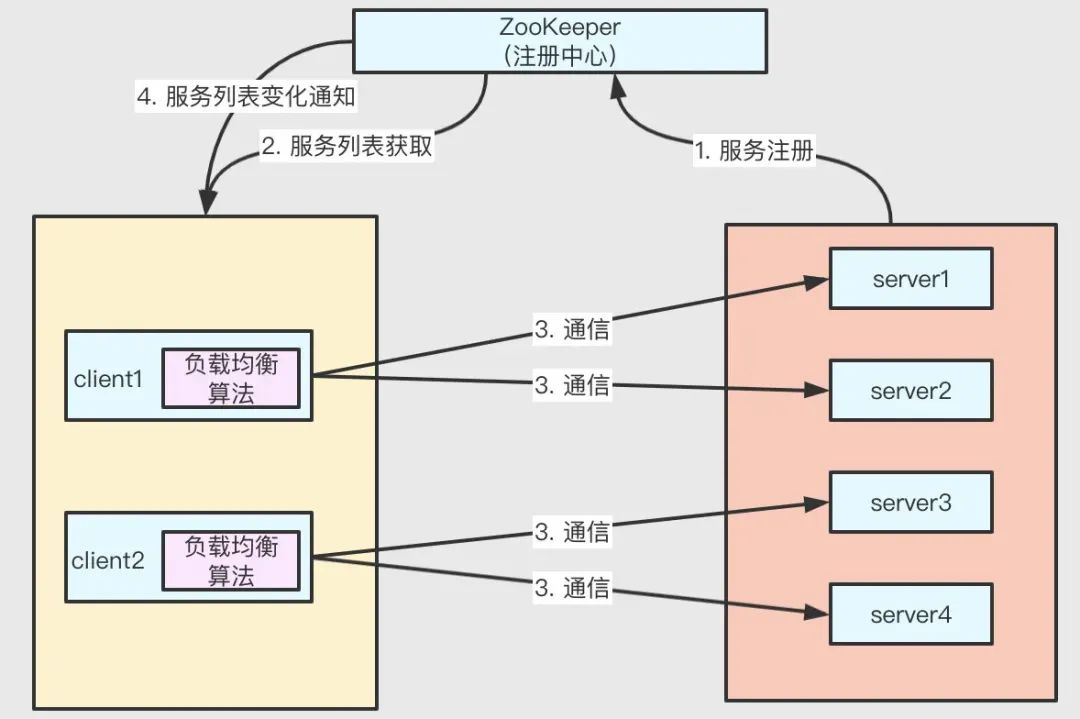
把 ZK 作為一個服務的注冊中心,基本流程:
- 服務提供者 server 啟動時在 ZK 進行服務注冊(創建臨時檔案);
- 服務消費者 client 啟動時,請求 ZK 獲取最新的服務存活串列并注冊 watcher,然后將獲得服務串列保存到本地快取中;
- client 請求 server 時,根據自己的負載均衡演算法,從服務器串列選取一個進行通信,
- 若在運行程序中,服務提供者出現例外或人工關閉不能提供服務,臨時節點失效,ZK 探測到變化更新本地服務串列并異步通知到服務消費者,服務消費者監聽到服務串列的變化,更新本地快取
注意:服務發現可能存在延遲,因為服務提供者掛掉到快取更新大約需要 3-5s 的時間(根據網路環境不同還需仔細測驗),為了保證服務的實時可用,client 請求 server 發生例外時,需要根據服務消費報錯資訊,進行重負載均衡重試等,
命名服務
命名服務是指通過指定的名字來獲取資源或者服務的地址、提供者等資訊,以 znode 的路徑為名字,znode 存盤的資料為值,可以很容易構建出一個命名服務,例如 Dubbo 使用 ZK 來作為其命名服務,如下
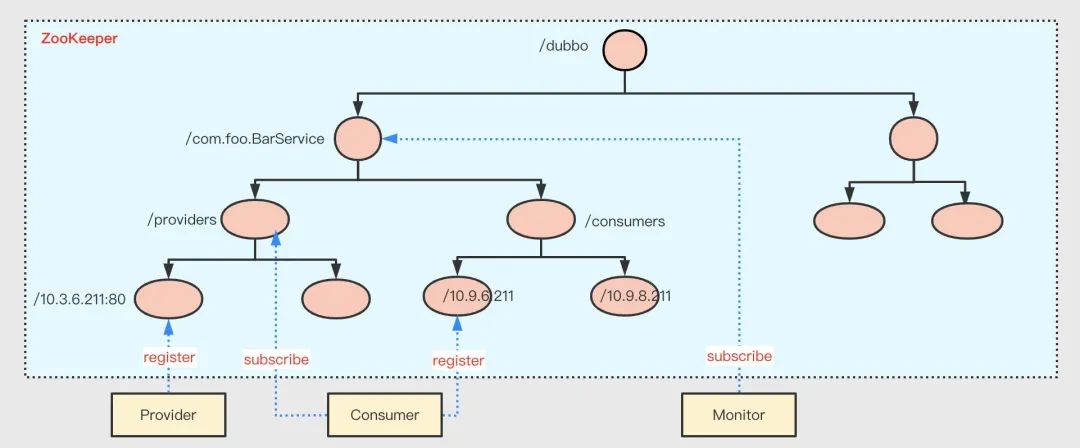
- 所有 Dubbo 相關的資料都組織在
/dubbo的根節點下; - 二級目錄是服務名,如
com.foo.BarService; - 三級目錄有兩個子節點,分別是
providers和consumers,表示該服務的提供者和消費者; - 四級目錄記錄了與該服務相關的每一個應用實體的 URL 資訊,在
providers下的表示該服務的所有提供者,而在consumers下的表示該服務的所有消費者,舉例說明,com.foo.BarService的服務提供者在啟動時將自己的 URL 資訊注冊到/dubbo/com.foo.BarService/providers下;同樣的,服務消費者將自己的資訊注冊到相應的consumers下,同時,服務消費者會訂閱其所對應的providers節點,以便能夠感知到服務提供方地址串列的變化,
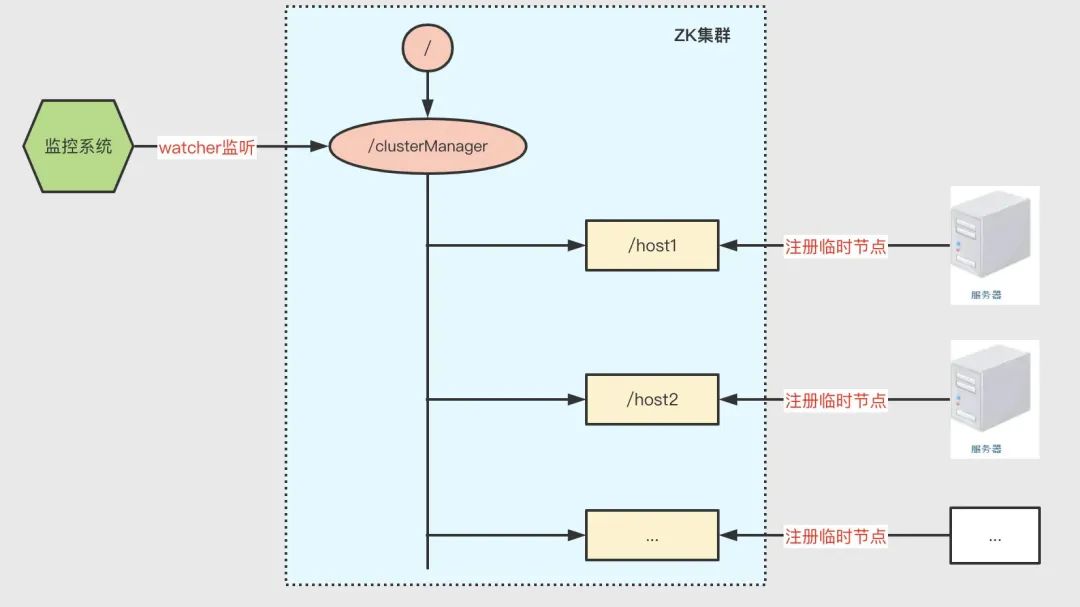
集群管理
基于 ZK 的臨時節點和 watcher 監聽機制可實作集群管理,集群管理通常指監控集群中各個主機的運行時狀態、存活狀況等資訊,如下圖所示,主機向 ZK 注冊臨時節點,監控系統注冊監聽集群下的臨時節點,從而獲取集群中服務的狀態等資訊,
Master 選舉
ZK 中某節點同一層子節點,名稱具有唯一性,所以,多個客戶端創建同一節點時,只會有一個客戶端成功,利用該特性,可以實作 maser 選舉,具體如下:
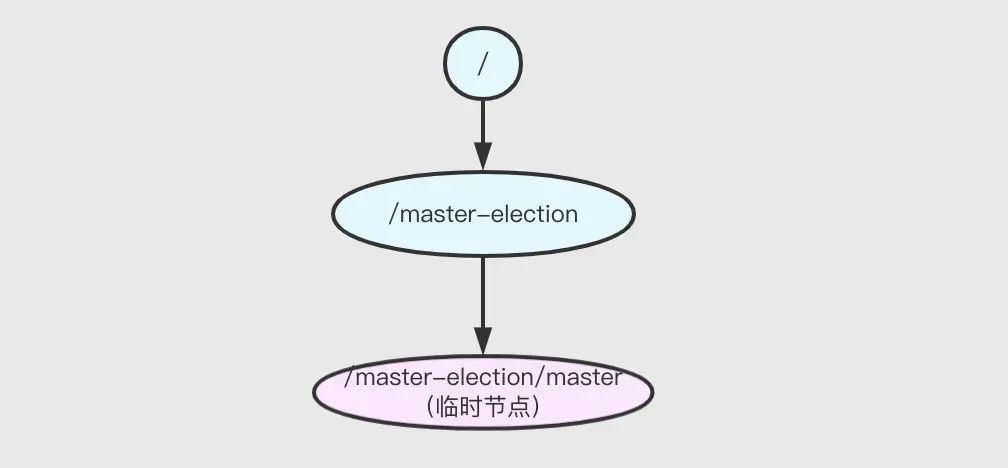
- 多個客戶端同時競爭創建同一臨時節點/master-election/master,最終只能有一個客戶端成功,這個成功的客戶端成為 Master,其它客戶端置為 Slave,
- Slave 客戶端都向這個臨時節點的父節點/master-election 注冊一個子節點串列的 watcher 監聽,
- 一旦原 Master 宕機,臨時節點就會消失,zk 服務器就會向所有 Slave 發送子節點變更事件,Slave 在接收到事件后會競爭創建新的 master 臨時子節點,誰創建成功,誰就是新的 Master,
分布式鎖
基于 ZK 的臨時順序節點和 Watcher 機制可實作公平分布式鎖,下面具體看下多客戶端獲取及釋放 zk 分布式鎖的整個流程及背后的原理,下面程序引自七張圖徹底講清楚 ZooKeeper 分布式鎖的實作原理【石杉的架構筆記】 ,
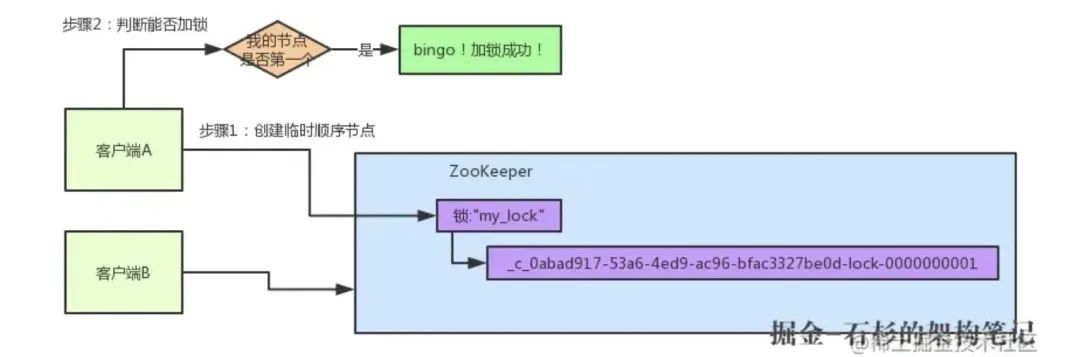
假如說客戶端 A 先發起請求,就會搞出來一個順序節點,大家看下面的圖,Curator 框架大概會弄成如下的樣子:
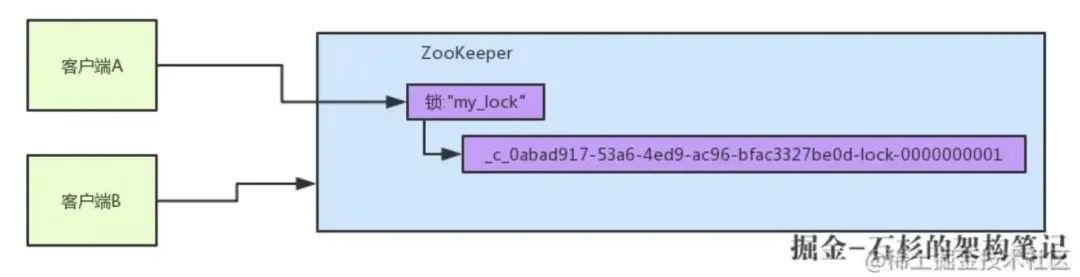
這一大坨長長的名字都是 Curator 框架自己生成出來的,然后,因為客戶端 A 是第一個發起請求的,所以給他搞出來的順序節點的序號是"1",接著客戶端 A 會查一下"my_lock"這個鎖節點下的所有子節點,并且這些子節點是按照序號排序的,這個時候大概會拿到這么一個集合:

接著客戶端 A 會走一個關鍵性的判斷:唉!兄弟,這個集合里,我創建的那個順序節點,是不是排在第一個啊?如果是的話,那我就可以加鎖了啊!因為明明我就是第一個來創建順序節點的人,所以我就是第一個嘗試加分布式鎖的人啊!bingo!加鎖成功!大家看下面的圖,再來直觀的感受一下整個程序,
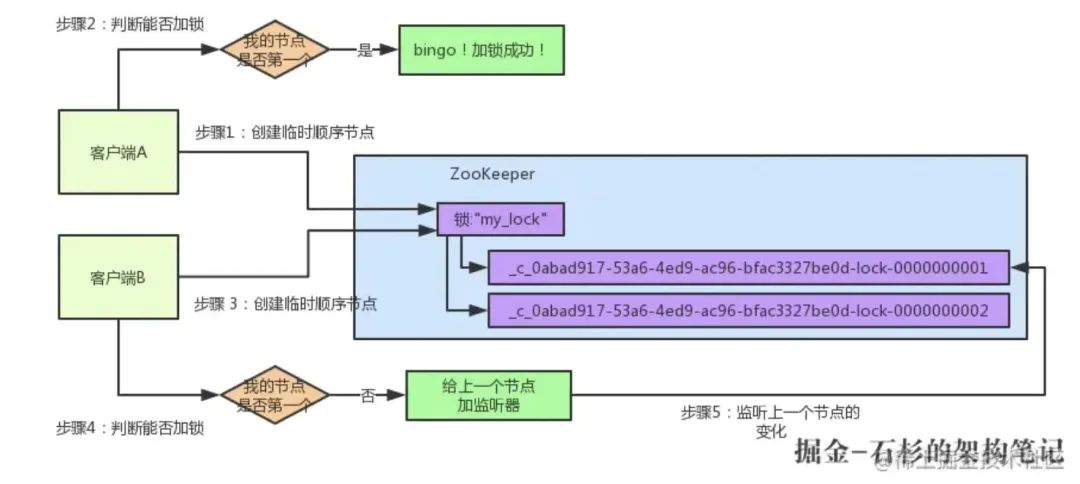
假如說客戶端 A 加完鎖完后,客戶端 B 過來想要加鎖,這個時候它會干一樣的事兒:先是在"my_lock"這個鎖節點下創建一個臨時順序節點,因為是第二個來創建順序節點的,所以 zk 內部會維護序號為"2",接著客戶端 B 會走加鎖判斷邏輯,查詢"my_lock"鎖節點下的所有子節點,按序號順序排列,此時看到的類似于:

同時檢查自己創建的順序節點,是不是集合中的第一個?明顯不是,此時第一個是客戶端 A 創建的那個順序節點,序號為"01"的那個,所以加鎖失敗!加鎖失敗了以后,客戶端 B 就會通過 ZK 的 API 對他的順序節點的上一個順序節點加一個監聽器, 即對客戶端 A 創建的那個順序節加監聽器!如下
接著,客戶端 A 加鎖之后,可能處理了一些代碼邏輯,然后就會釋放鎖,那么,釋放鎖是個什么程序呢?
其實很簡單,就是把自己在 zk 里創建的那個順序節點,也就是:
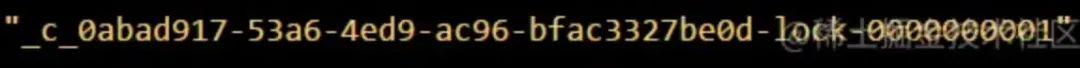
這個節點被洗掉,
洗掉了那個節點之后,zk 會負責通知監聽這個節點的監聽器,也就是客戶端 B 之前加的那個監聽器,說:兄弟,你監聽的那個節點被洗掉了,有人釋放了鎖,
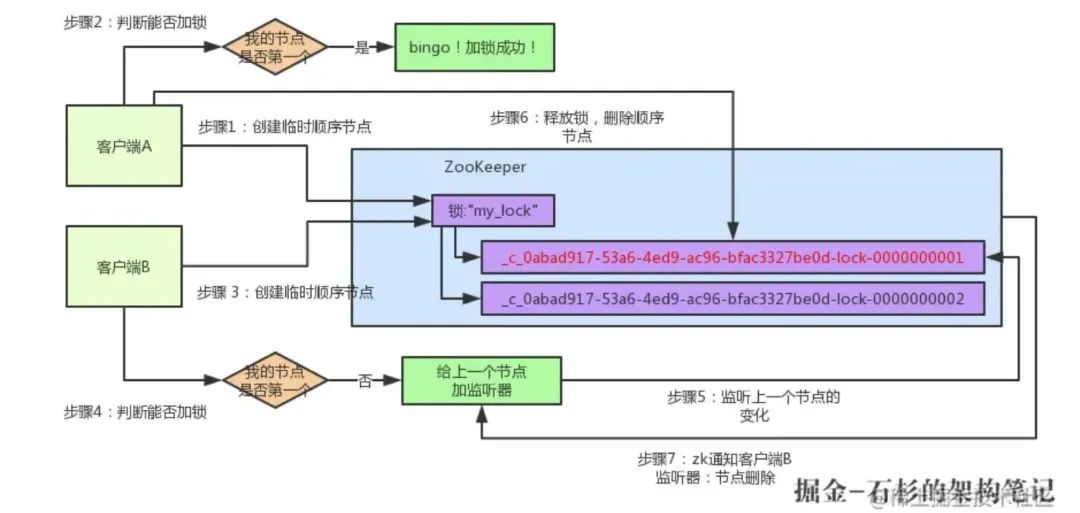
此時客戶端 B 的監聽器感知到了上一個順序節點被洗掉,也就是排在他之前的某個客戶端釋放了鎖,
此時,就會通知客戶端 B 重新嘗試去獲取鎖,也就是獲取"my_lock"節點下的子節點集合,此時為:

集合里此時只有客戶端 B 創建的唯一的一個順序節點了!
然后呢,客戶端 B 判斷自己居然是集合中的第一個順序節點,bingo!可以加鎖了!直接完成加鎖,運行后續的業務代碼即可,運行完了之后再次釋放鎖,
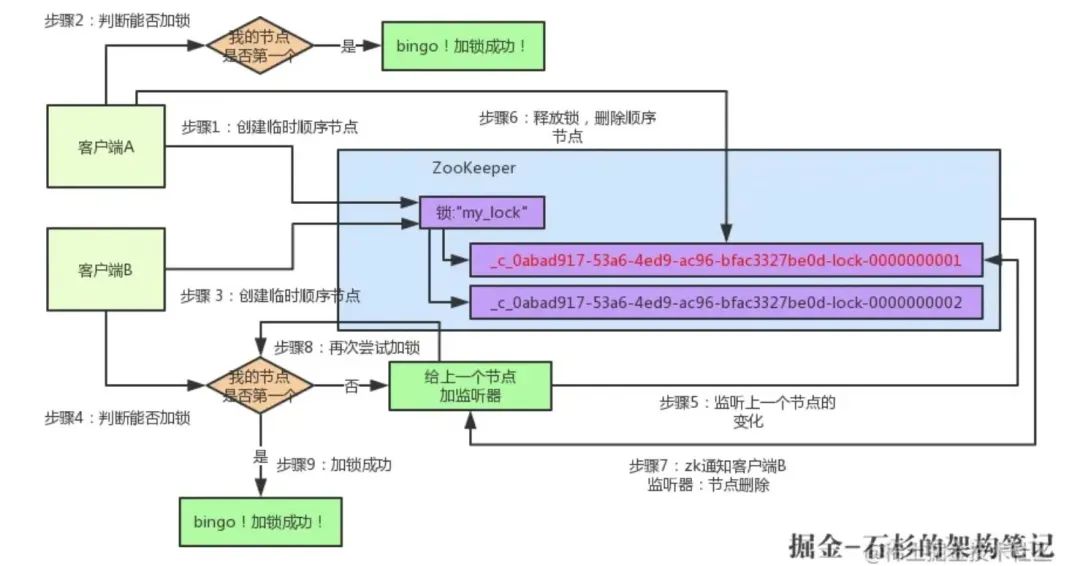
注意:利用 ZK 實作分布式鎖時要避免出現驚群效應,上述策略中,客戶端 B 通過監聽比其節點順序小的那個臨時節點,解決了驚群效應問題,
分布式佇列
基于 ZK 的臨時順序節點和 Watcher 機制可實作簡單的 FIFO 分布式佇列,ZK 分布式佇列和上節中的分布式鎖本質是一樣的,都是基于對上一個順序節點進行監聽實作的,具體原理如下:
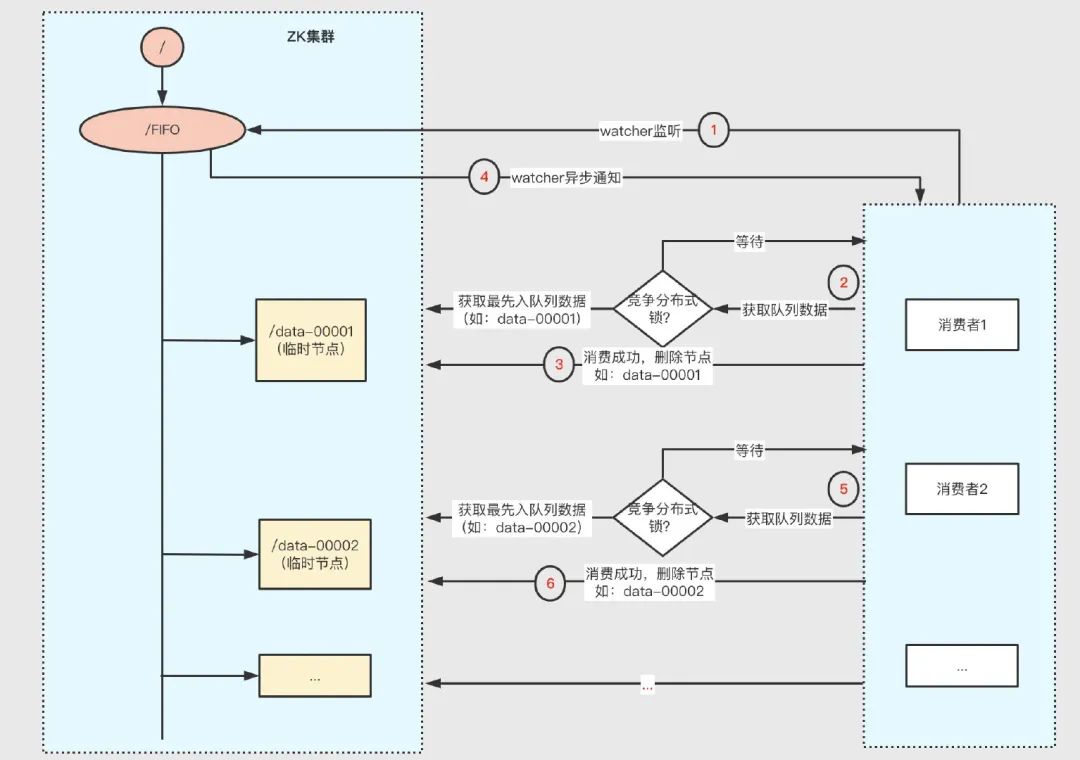
- 利用順序節點的有序性,為每個資料在/FIFO 下創建一個相應的臨時子節點;且每個消費者均在/FIFO 注冊一個 watcher;
- 消費者從分布式佇列獲取資料時,首先嘗試獲取分布式鎖,獲取鎖后從/FIFO 獲取序號最小的資料,消費成功后,洗掉相應節點;
- 由于消費者均監聽了父節點/FIFO,所以均會收到資料變化的異步通知,然后重復 2 的程序,嘗試消費佇列資料,依此回圈,直到消費完畢,
中間件落地案例
Kafka
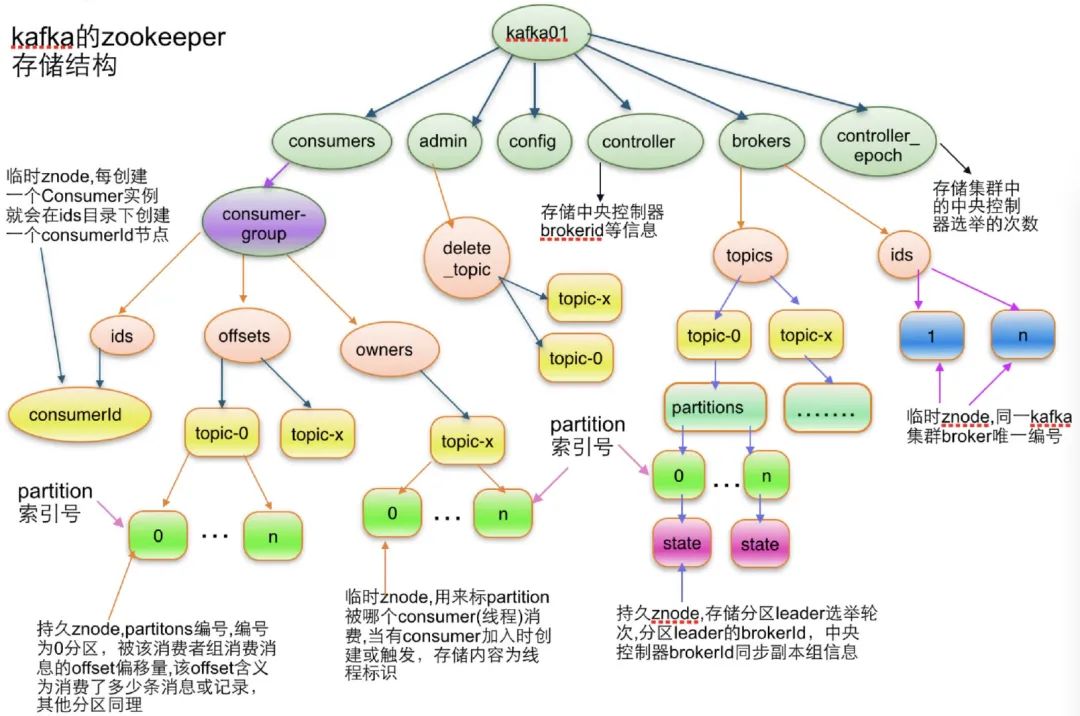
ZK 在 Kafka 集群中扮演著極其重要的角色,Kafka 中很多資訊都在 ZK 中維護,如 broker 集群資訊、consumer 集群資訊、 topic 相關資訊、 partition 資訊等,Kafka 的很多功能也是基于 ZK 實作的,如 partition 選主、broker 集群管理、consumer 負載均衡等,限于篇幅本文將不展開陳述,這里先附一張網上截圖大家感受下,詳情將在 Kafka 專題中細聊,
Dubbo
Dubbo 使用 Zookeeper 用于服務的注冊發現和配置管理,詳情見上文“命名服務”,
參考文獻
https://mp.weixin.qq.com/s/tiAQQXbh7Tj45_1IQmQqZg
https://www.jianshu.com/p/68b45694026c
https://time.geekbang.org/column/article/239261
https://blog.csdn.net/lihao21/article/details/51810395
https://zhuanlan.zhihu.com/p/378018463
https://juejin.cn/post/6974737393324654628
https://blog.csdn.net/liuao107329/article/details/78936160
https://blog.csdn.net/en_joker/article/details/78799737
https://blog.51cto.com/u_15077535/4199740
https://juejin.cn/post/6844903729406148622
https://blog.csdn.net/Saintmm/article/details/124110149
https://www.wumingx.com/linux/zk-kafka.html
作者:mosun本文來自博客園,作者:古道輕風,轉載請注明原文鏈接:https://www.cnblogs.com/88223100/p/ZooKeeper-core-general-knowledge.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/541053.html
標籤:架構設計
上一篇:go-淺學設計模式隨記
下一篇:ZooKeeper 核心通識