
一、背景
1 后臺系統由集中式發展為分布式
隨著計算機系統的規模越來越大,業務量的迅速提升和互聯網的爆炸式增長,集中式系統采用大型主機單機部署帶來了一系列問題:系統大而復雜、難于維護、發生單點故障引起雪崩、擴展性差等,這些都使業務面臨巨大的壓力和嚴重的風險,為了解決集中式系統架構面臨的痛點,分布式系統架構逐步走上舞臺,分布式系統是一個硬體或軟體組件分布在不同的網路計算機上,彼此之間僅僅通過訊息傳遞進行通信和協調的系統,可以很好的解決系統擴容、可用性以及降低成本,
2 分布式系統架構引入的新問題
“天下沒有免費的午餐”,分布式系統架構帶來了優點的同時,也提出了一系列的挑戰:
(1)由于多節點甚至多地部署,節點之間的資料一致性如何保證?
(2)在并發場景下如何保證任務只被執行一次?
(3)一個節點掛掉不能提供服務時如何被集群知曉并由其他節點接替任務?
(4)存在資源共享時,資源的安全性和互斥性如何保證?
以上列舉了分布式系統中面臨的一些挑戰,需要一個協調機制來解決分布式集群中的問題,使得開發者更專注于應用本身的邏輯而不是關注分布式系統處理,
3 分布式協調組件
為解決分布式系統中面臨的這些問題,開發者們通過工程實踐創造了很多非常優秀的分布式系統協調組件,這些組件可以在分布式環境下,保證分布式系統的資料一致性和容錯性等,其中為我們熟知的有:ZooKeeper、ETCD、Consul 等,ZooKeeper 作為 Apache 的頂級開源專案,基于 Google Chubby 開源實作,在 Hadoop,Hbase,Kafka 等技術中充當核心組件的角色,雖然歷史悠久,但就像陳釀一樣,其設計思想和實作不論何時還是值得仔細學習和品味,
二、ZooKeeper
1 ZooKeeper 是什么
從理論概念角度解釋:ZooKeeper 是一個分布式的,開源的分布式應用程式協調服務,它是一個為分布式應用提供一致性服務的軟體,提供的功能包括:配置維護、域名服務、分布式同步、組服務等,
從資料讀寫角度解釋:ZooKeeper 是一個分布式的開源協調服務,用于分布式系統,ZooKeeper 允許你讀取、寫入資料和發現資料更新,資料按層次結構組織在檔案系統中,并復制到 ensemble(一個 ZooKeeper 服務器的集合)中所有的 ZooKeeper 服務器,對資料的所有操作都是原子的和順序一致的,ZooKeeper 通過 Zab 一致性協議在 ensemble 的所有服務器之間復制一個狀態機來確保這個特性,
2 ZooKeeper 的安裝與使用
“紙上得來終覺淺,絕知此事要躬行”,學習一個新的組件,我們先通過安裝使用,對配置、API 等有一個直觀的認識,也為后面動手實作一些功能部署好開發環境基礎,
2.1 ZooKeeper 下載與安裝
(1)ZooKeeper 使用 JAVA 語言開發,使用前需要先安裝 JDK(讀者自行安裝),安裝 JDK 后可在終端命令列中使用 java -version 命令查看版本(注意:本文均在 Linux 環境下指導演示),

(2)ZooKeeper 下載:https://zookeeper.apache.org/releases.html
在下載頁面分為最新的 Release 版本和最近的穩定 Release 版本,這里生產環境使用推薦穩定版本,點擊下載并上傳 apache-zookeeper-3.7.0-bin.tar.gz 到 Linux 服務器上,

(3)ZooKeeper 安裝:ZooKeeper 安裝分為集群安裝和單機安裝,生產環境一般為集群安裝,此處作為演示,使用一臺服務器來做模擬集群,也稱偽集群安裝(通過三個不同的檔案夾 zk1/zk2/zk3,模擬真實環境中的三臺服務器實體),
-
本篇中我們將要在本地開發機上安裝三個 zk 實體(可以認為在生產集群模式中,這是三臺不同的服務器),其安裝位置分別如下:
/Users/newboy/ZooKeeper/zk1 /Users/newboy/ZooKeeper/zk2 /Users/newboy/ZooKeeper/zk3 -
將上文中下載的 ZooKeeper 安裝包 apache-zookeeper-3.7.0-bin.tar.gz 上傳到第一個實體 zk1 檔案夾下,并使用如下命令進行解壓:
tar -xzvf apache-zookeeper-3.7.0-bin.tar.gz -
解壓完成后在 zk1 檔案夾下創建 data 和 log 目錄,分別用于存盤當前 zk 實體資料和日志:
mkdir data logs此時 zk1 檔案夾目錄結構如下所示:

-
創建 myid 檔案 在 zk1 的 data 目錄下,創建 myid 檔案,此檔案記錄節點 id,每個 zookeeper 節點都需要一個 myid 檔案來記錄節點在集群中的 id,此檔案中只能有一個數字,這里 zk1 實體 myid 中寫入一個 1 即可:
echo "1" >> /Users/newboy/ZooKeeper/zk1/data/myid // 實體zk1的myid賦值為1 echo "2" >> /Users/newboy/ZooKeeper/zk2/data/myid // 實體zk2的myid賦值為2 echo "3" >> /Users/newboy/ZooKeeper/zk3/data/myid // 實體zk3的myid賦值為3 -
進入 zk1 檔案夾下 apache-zookeeper-3.7.0-bin/conf/目錄,將組態檔 zoo_sample.cfg 重命名為 zoo.cfg,打開 zoo.cfg 進行配置,具體配置如下:
tickTime=2000 # 單位時間,其他時間都是以這個倍數來表示 initLimit=10 # 節點初始化時間,10倍單位時間(即十倍tickTime) syncLimit=5 # 心跳最大延遲周期 dataDir=/Users/newboy/ZooKeeper/zk1/data # 該實體對應的資料目錄(上文步驟3創建) dataLogDir=/Users/newboy/ZooKeeper/zk1/logs # 該實體對應的日志目錄(上文步驟3創建) clientPort=2181 # 埠(每個實體不同) // 集群配置 server.1=127.0.0.1:8881:7771 # server.id=host:port:port server.2=127.0.0.1:8882:7772 # server.id=host:port:port server.3=127.0.0.1:8883:7773 # server.id=host:port:port集群配置中模版為 server.id=host:port:port,id 是上面 myid 檔案中配置的 id;ip 是節點的 ip,第一個 port 是節點之間通信的埠,第二個 port 用于選舉 leader 節點(在真正的集群模式下,不同服務器可以共用同一個 port,這里單機上演示為了避免埠沖突,選擇不同的埠),
-
zk2 和 zk3 的實體配置與 zk1 類似,為了方便我們可以直接拷貝 zk1 的配置到 zk2 和 zk3 檔案夾,然后修改各自的 zoo.cfg 和 data 目錄下的 myid 即可,拷貝命令:
cp -R zk1 zk2 cp -R zk1 zk3zk2 對應的 zoo.cfg:
tickTime=2000 # 單位時間,其他時間都是以這個倍數來表示 initLimit=10 # 節點初始化時間,10倍單位時間(即十倍tickTime) syncLimit=5 # 心跳最大延遲周期 dataDir=/Users/newboy/ZooKeeper/zk2/data # 該實體對應的資料目錄(上文步驟3創建) dataLogDir=/Users/newboy/ZooKeeper/zk2/logs # 該實體對應的日志目錄(上文步驟3創建) clientPort=2182 # 埠(每個實體不同) // 集群配置 server.1=127.0.0.1:8881:7771 # server.id=host:port:port server.2=127.0.0.1:8882:7772 # server.id=host:port:port server.3=127.0.0.1:8883:7773 # server.id=host:port:portzk3 對應的 zoo.cfg:
tickTime=2000 # 單位時間,其他時間都是以這個倍數來表示 initLimit=10 # 節點初始化時間,10倍單位時間(即十倍tickTime) syncLimit=5 # 心跳最大延遲周期 dataDir=/Users/newboy/ZooKeeper/zk3/data # 該實體對應的資料目錄(上文步驟3創建) dataLogDir=/Users/newboy/ZooKeeper/zk3/logs # 該實體對應的日志目錄(上文步驟3創建) clientPort=2183 # 埠(每個實體不同) // 集群配置 server.1=127.0.0.1:8881:7771 # server.id=host:port:port server.2=127.0.0.1:8882:7772 # server.id=host:port:port server.3=127.0.0.1:8883:7773 # server.id=host:port:port至此 zk 偽集群模式的安裝配置已經完成,整體目錄結構縱覽如下:
. ├── zk1 │ ├── data │ │ └── myid │ ├── logs │ └── apache-zookeeper-3.7.0-bin ├── zk2 │ ├── data │ │ └── myid │ ├── logs │ └── apache-zookeeper-3.7.0-bin └── zk3 │ ├── data │ │ └── myid ├── logs └── apache-zookeeper-3.7.0-bin(4)ZooKeeper 實體啟動及使用客戶端互動:
-
啟動剛剛創建的三個 zk 實體 (1) 啟動 zk1 實體,命令列運行下面命令:
// 啟動命令 /Users/newboy/ZooKeeper/zk1/apache-zookeeper-3.7.0-bin/bin/zkServer.sh start // 啟動結果 ZooKeeper JMX enabled by default Using config: /Users/newboy/ZooKeeper/zk1/apache-zookeeper-3.7.0-bin/bin/../conf/zoo.cfg Starting zookeeper ... STARTED(2) 同樣啟動 zk2 和 zk3 實體,命令列運行下面命令:
// 啟動zk2命令 /Users/newboy/ZooKeeper/zk2/apache-zookeeper-3.7.0-bin/bin/zkServer.sh start // 啟動zk3命令 /Users/newboy/ZooKeeper/zk3/apache-zookeeper-3.7.0-bin/bin/zkServer.sh start
-
連接實體 所有實體全部啟動過后,選擇任一實體進行連接,這里選擇實體 zk2,命令列輸入如下命令:
/Users/newboy/ZooKeeper/zk2/apache-zookeeper-3.7.0-bin/bin/zkCli.sh -server 127.0.0.1:2182
-
創建節點 連接之后,可以在當前實體上創建節點,類似于創建一個 kv 值或者檔案夾(ZK 的命令和可選引數讀者可以自行查看用戶手冊)
// 創建節點 create表示創建命令,/zk-demo為節點名稱 123為節點值 [zk: 127.0.0.1:2181(CONNECTED) 1] create /zk-demo 123 Created /zk-demo // 獲取節點值 get表示獲取 /zk-demo為需要獲取的節點名稱 [zk: 127.0.0.1:2181(CONNECTED) 2] get /zk-demo 123
-
在其他實體上獲取 zk2 實體創建的節點 由于 zk 會將節點寫入的值同步到集群中每個節點,從而保證資料的一致性,那么其他節點理論上也可以訪問到剛剛 zk2 創建的值,下面連接 zk1 來驗證下:
// 連接zk1 /Users/newboy/ZooKeeper/zk1/apache-zookeeper-3.7.0-bin/bin/zkCli.sh -server 127.0.0.1:2181 // 獲取zk2上創建的節點/zk-demo [zk: 127.0.0.1:2183(CONNECTED) 0] get /zk-demo 123可以看到,我們成功的在實體 zk1 上獲取到了實體 zk2 創建的節點,說明資料寫入 zk2 后,在各個節點間同步并實作了一致,zk 的下載、安裝和基本命令操作也就講完了,
3 ZooKeeper 能做什么
前文中,我們了解了 ZooKeeper 出現的背景,它是分布式系統中非常重要的中間件,分布式應用程式可以基于 ZooKeeper 實作:
-
資料的發布和訂閱 -
服務注冊與發現 -
分布式配置中心 -
命名服務 -
分布式鎖 -
Master 選舉 -
負載均衡 -
分布式佇列
可以看到 ZooKeeper 可以實作非常多的功能,之所以能夠實作各種不同的能力,源于 ZooKeeper 底層的資料結構和資料模型,
4 ZooKeeper 的資料結構和資料模型
1 Znode 資料節點
ZooKeeper 的資料節點可以視為樹狀結構,樹中的各節點被稱為 Znode(即 ZooKeeper node),一個 Znode 可以有多個子節點,ZooKeeper 中的所有存盤的資料是由 znode 組成,并以 key/value 形式存盤資料,整體結構類似于 linux 檔案系統的模式以樹形結構存盤,其中根路徑以 / 開頭:
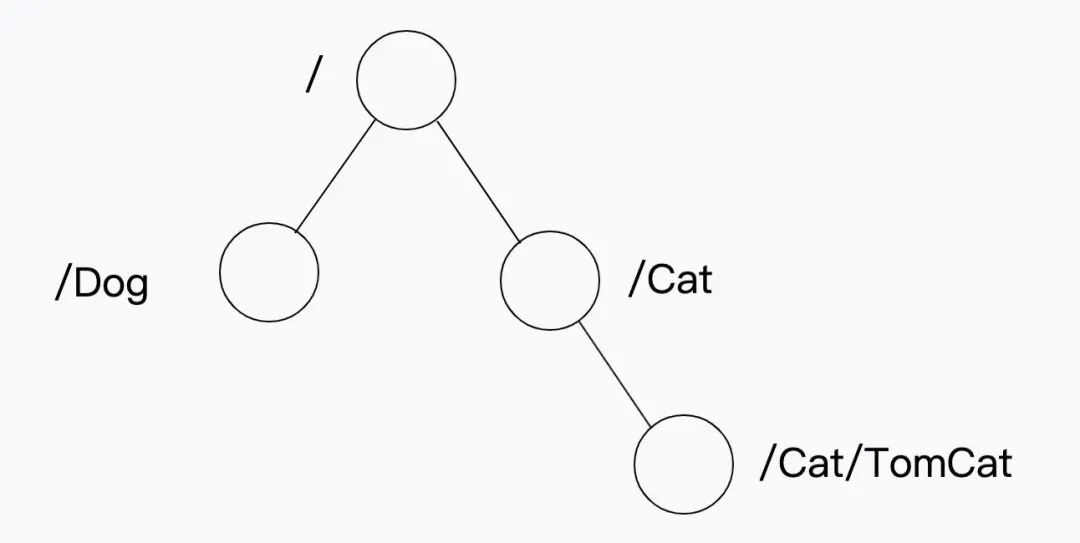
如上圖所示,在根目錄下我們創建 Dog 和 Cat 兩個不同的資料節點,Cat 節點下有 TomCat 這個資料存盤節點,整個 ZooKeeper 的樹形存盤結構就是這樣的 Znode 構成,并存盤在記憶體中,
命令列下使用 ZooKeeper 客戶端工具創建節點的程序如下:首先連接一個 zk 實體:
// 連接zk1
/Users/newboy/ZooKeeper/zk1/apache-zookeeper-3.7.0-bin/bin/zkCli.sh -server 127.0.0.1:2181創建節點:
[zk: 127.0.0.1:2181(CONNECTED) 5] create /Dog
Created /Dog
[zk: 127.0.0.1:2181(CONNECTED) 6] create /Cat
Created /Cat
[zk: 127.0.0.1:2181(CONNECTED) 7] create /Cat/TomCat
Created /Cat/TomCat使用 ls 命令查看各個目錄下的節點資料:
[zk: 127.0.0.1:2181(CONNECTED) 8] ls /
[Cat, Dog, zk-demo, zookeeper]
[zk: 127.0.0.1:2181(CONNECTED) 10] ls /Cat
[TomCat]Znode 節點類似于 Unix 檔案系統,但也有自己的特性:
(1)Znode 兼具檔案和目錄特點 既像檔案一樣維護著資料、資訊、時間戳等資料,又像目錄一樣可以作為路徑標識的一部分,并可以具有子 Znode,用戶對 Znode 具有增、刪、改、查等操作;
(2)Znode 具有原子性操作 讀操作將獲取與節點相關的所有資料,寫操作也將替換掉節點的所有資料;
(3) Znode 存盤資料大小有限制 每個 Znode 的資料大小至多 1M,但是常規使用中應該遠小于此值;
(4)Znode 通過路徑參考 如同 Unix 中的檔案路徑,路徑必須是絕對的,因此他們必須由斜杠字符來開頭,除此以外,他們必須是唯一的,也就是說每一個路徑只有一個表示,因此這些路徑不能改變,
2 Znode 節點型別
Znode 有兩種,分別為臨時節點和永久節點,節點的型別在創建時即被確定,并且不能改變,
臨時節點:該節點的生命周期依賴于創建它們的會話,一旦會話結束,臨時節點將被自動洗掉,當然可以也可以手動洗掉,臨時節點不允許擁有子節點,
永久節點:該節點的生命周期不依賴于會話,并且只有在客戶端顯式執行洗掉操作的時候,才能被洗掉,
Znode 還有一個序列化的特性,如果創建的時候指定的話,該 Znode 的名字后面會自動追加一個遞增的序列號,序列號對于此節點的父節點來說是唯一的,這樣便會記錄每個子節點創建的先后順序,因此組合之后,Znode 有四種節點型別:
-
PERSISTENT:永久節點
-
EPHEMERAL:臨時節點
-
PERSISTENT_SEQUENTIAL:永久順序節點
-
EPHEMERAL_SEQUENTIAL:臨時順序節點
為了對節點型別有更清楚的認識,在命令列下來模擬創建一個臨時節點:(1)首先連接 zk1 實體:
// 連接zk1
/Users/newboy/ZooKeeper/zk1/apache-zookeeper-3.7.0-bin/bin/zkCli.sh -server 127.0.0.1:2181(2)創建一個臨時節點:
// -e 表示該節點為臨時節點
[zk: 127.0.0.1:2181(CONNECTED) 12] create -e /Dog/Puppy 123
Created /Dog/Puppy(3)連接 zk2 實體,查看該臨時節點是否同步:
// 連接zk2
/Users/newboy/ZooKeeper/zk2/apache-zookeeper-3.7.0-bin/bin/zkCli.sh -server 127.0.0.1:2182
// 查詢/Dog/Puppy節點值
[zk: 127.0.0.1:2182(CONNECTED) 2] get /Dog/Puppy
123(4)斷開 zk1 實體的會話
[zk: 127.0.0.1:2181(CONNECTED) 16] quit
WATCHER::
WatchedEvent state:Closed type:None path:null
2022-03-15 15:39:55,807 [myid:] - INFO [main:ZooKeeper@1232] - Session: 0x1000c3279ae0000 closed
2022-03-15 15:39:55,807 [myid:] - INFO [main-EventThread:ClientCnxn$EventThread@570] - EventThread shut down for session: 0x1000c3279ae0000
2022-03-15 15:39:55,810 [myid:] - ERROR [main:ServiceUtils@42] - Exiting JVM with code 0(5)在 zk2 上查看該節點
[zk: 127.0.0.1:2182(CONNECTED) 3] get /Dog/Puppy
org.apache.zookeeper.KeeperException$NoNodeException: KeeperErrorCode = NoNode for /Dog/Puppy可以看到/Dog/Puppy 臨時節點隨著 zk1 實體會話的退出消失了,這就是臨時節點的特性,zk1 創建的臨時節點會隨著 zk1 實體連接的退出而消失,永久節點則只能通過 delete /Dog(節點名)洗掉才會消失,
3 ZooKeeper 的 Znode Watcher 機制
ZooKeeper 可以用來做資料的發布和訂閱,一個典型的發布/訂閱模型系統定義了一種一對多的訂閱關系,能夠讓多個訂閱者同時監聽某一個主題物件,當這個主題物件自身狀態變化時,會通知所有訂閱者,使它們能夠做出相應的處理,在 ZooKeeper 中,引入了Watcher 機制來實作這種分布式的通知功能,
ZooKeeper 允許 ZK 客戶端向服務端注冊一個 Watcher 監聽,當服務端的一些指定事件觸發了這個 Watcher,那么就會向指定客戶端發送一個事件通知,例如 ZK 客戶端監聽臨時節點/Cat,當該臨時節點消失時,則會由服務端觸發呼叫客戶端 WatchManager,客戶端從 WatchManager 中取出對應的 Watcher 物件來進行處理邏輯,
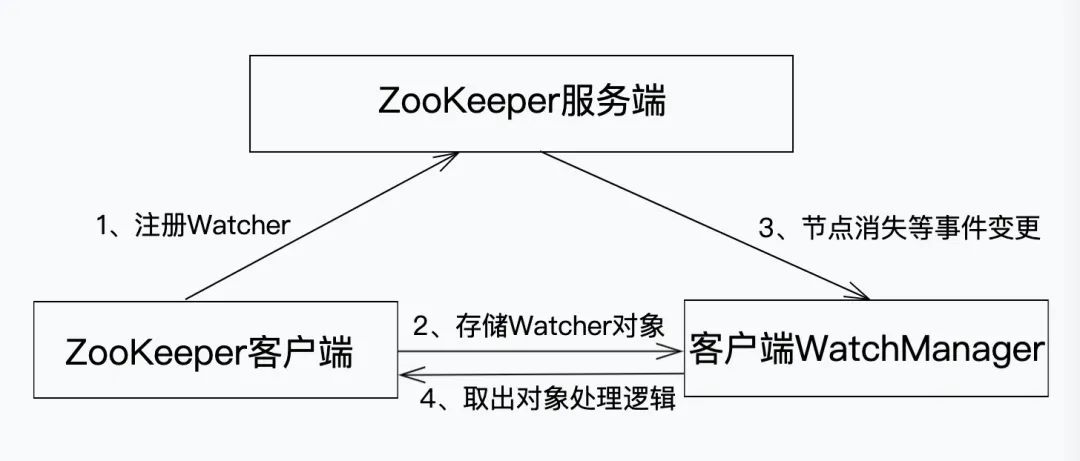
(1)客戶端首先將 Watcher 注冊到服務端,同時將 Watcher 物件保存到客戶端的 Watch 管理器中;(2)當 ZooKeeper 服務端監聽的資料狀態發生變化時,服務端會主動通知客戶端;(3)接著客戶端的 Watch 管理器會觸發相關 Watcher 來回呼相應處理邏輯,從而完成整體的資料發布/訂閱流程,
4 經典案例:基于 Znode 臨時順序節點+Watcher 機制實作公平分布式鎖
1、臨時順序節點:在介紹 Znode 節點時,我們提到過 Znode 節點有“臨時節點”這個型別,它會隨著客戶端連接的斷開而消失,同時節點型別可以選擇順序性,組合起來就是“臨時順序節點”,如下圖所示:
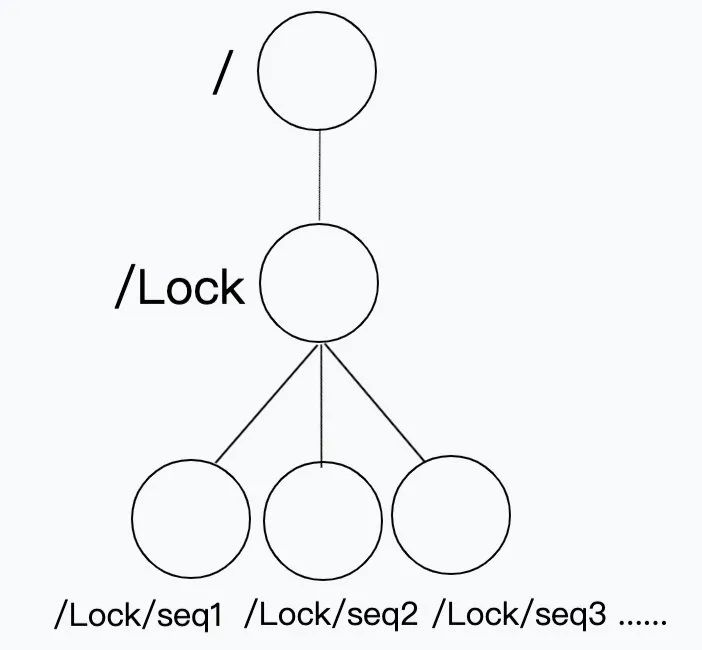
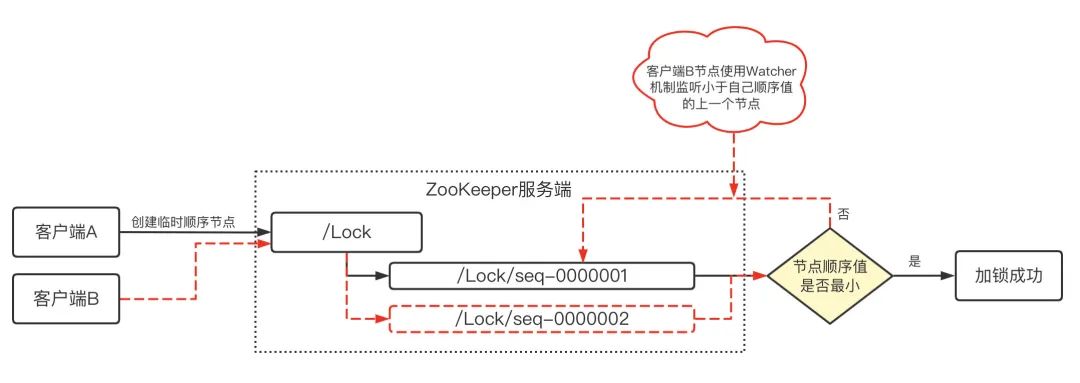
在根目錄“/”下創建分布式鎖“/Lock”節點目錄,/Lock 節點本身可以是永久節點,用于存放客戶端搶占創建的臨時順序節點,此時假設有兩個 ZK 客戶端 A 和 B 同時呼叫 Create 函式,在"/Lock"節點下創建臨時順序節點,A 比 B 網路延時更小,先創建,ZK 分配節點名稱為"/Lock/Seq0001", B 晚于 A 創建成功,ZK 分配節點名為"/Lock/Seq0002",ZK 負責維護這個遞增的順序節點名,
2、分布式鎖實作的具體流程 (1)如下圖,客戶端 A、B 同時在"/Lock"節點下創建臨時順序子節點,可以理解為同時搶占分布式鎖,A 先于 B 創建成功,此時分配的節點為“/Lock/seq-0000001”,由于 A 創建成功,并且臨時順序節點的順序值序號最小,代表它是最先獲取到該鎖,此時加鎖成功,
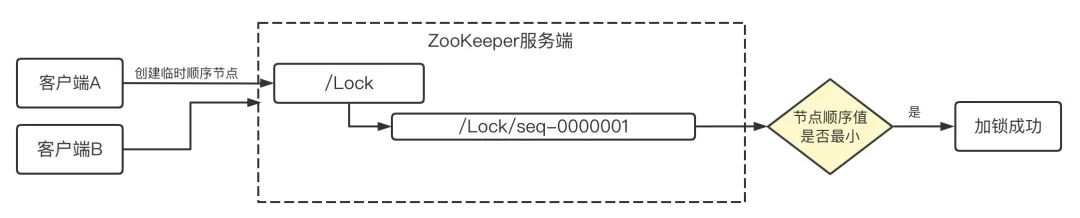
(2)如下圖,(紅色虛線)客戶端 B 晚于 A 創建臨時順序節點,此時 ZK 分配的節點順序值為“/Lock/seq-0000002”,B 創建成功之后,它的順序值大于 A 的順序值,不是最小順序值,此時說明 A 已經搶占到分布式鎖,這個時候 B 就使用 Watcher 監聽機制,監聽次小于自己的臨時順序節點 A 的狀態變化,
(3)如下圖,當 A 客戶端因宕機或者完成處理邏輯而斷開鏈接時,A 創建的臨時順序節點會隨之消失,此時由于客戶端 B 已經監聽了 A 臨時順序節點的狀態變化,當消失事件發生時,Watcher 監聽器邏輯會回呼客戶端 B,B 重新開始獲取鎖,注意此時不是 B 再次創建節點,而是獲取"/Lock"下的臨時順序節點,發現自己的順序值最小,那么就加鎖成功,
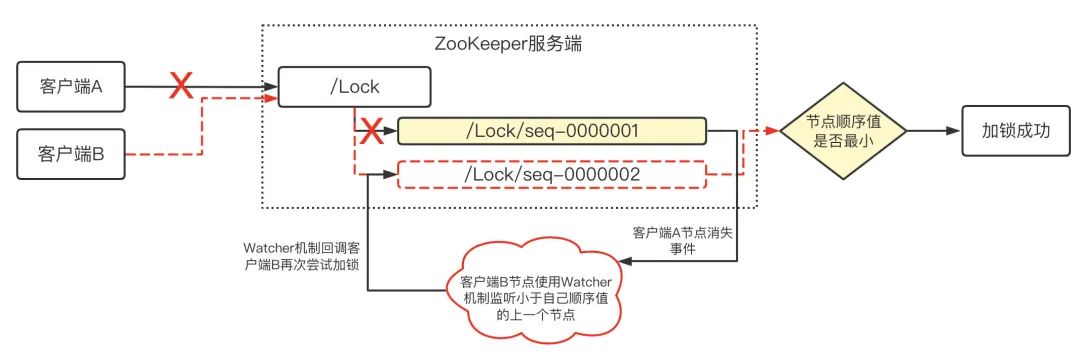
如果有 C、D 甚至更多的客戶端同時搶占,原理都是一致的,他們會依次排隊,監聽自己之前(節點順序值次小于自己)的節點,等待他們的狀態發生變化時,再去重新獲取鎖,
這里使用臨時順序節點和 Watcher 機制實作了一個公平分布式鎖,還有很多其他用法,如只使用臨時節點實作非公平分布式鎖,篇幅所限,讀者可以自行探索,
三、深入 ZooKeeper 一致性協議原理
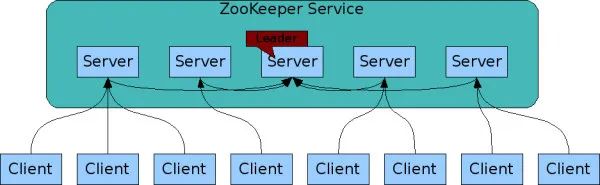
上圖是 ZooKeeper 的整體架構,ZooKeeper Service 是服務端集群,也是整個組件的核心,客戶端的讀寫請求都是它來處理,ZK 下載安裝章節模擬的 zk1/zk2/zk3 就可以認為是一個 ZK 服務端集群,我們在 zk2 中寫入的節點值,在 zk1 和 zk3 實體中也能讀到這個節點值,zk2 會話退出后臨時節點在其他服務器上也同樣消失了,ZK 服務端是通過什么機制實作資料在各個節點之間的同步,從而保證一致性?當有節點出現故障時又是如何保證正常提供對外服務?這就涉及到 ZooKeeper 的核心-分布式一致性原理,
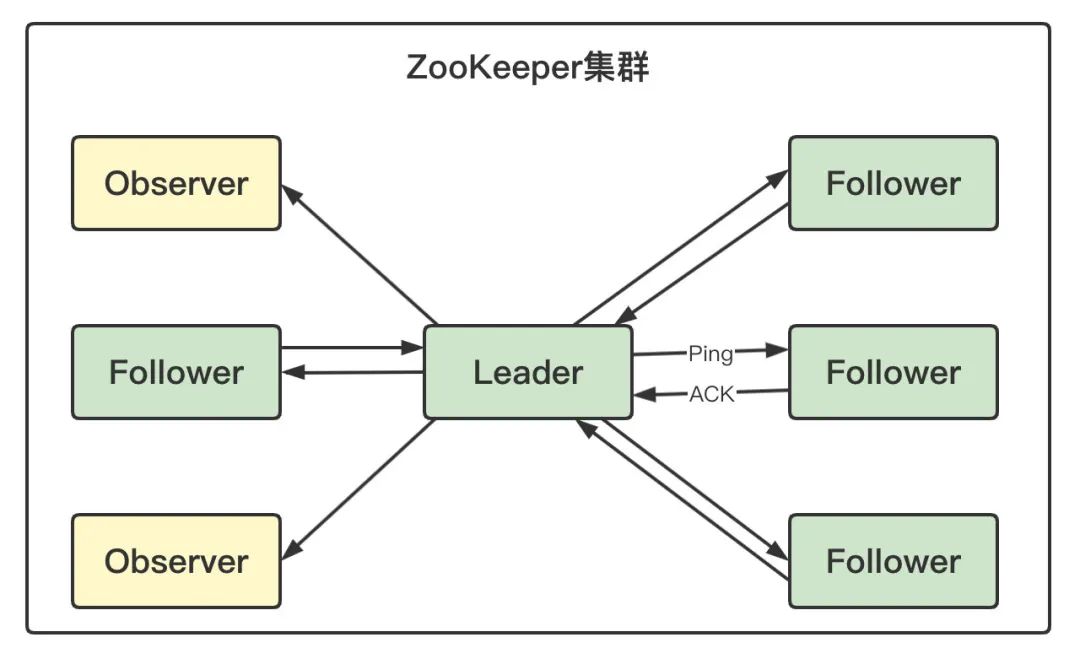
1 ZooKeeper 服務端角色
-
Leader 一個 ZooKeeper 集群同一時間只會有一個實際作業的 Leader,它會發起并維護與各 Follwer 及 Observer 間的心跳,所有的寫操作必須要通過 Leader 完成再由 Leader 將寫操作廣播給其它服務器,
-
Follower 一個 ZooKeeper 集群可能同時存在多個 Follower,它會回應 Leader 的心跳,Follower 可直接處理并回傳客戶端的讀請求,同時會將寫請求轉發給 Leader 處理,并且負責在 Leader 處理寫請求時對請求進行投票,
-
Observer 角色與 Follower 類似,但是無投票權,
1、早期的 ZooKeeper 集群服務運行程序中,只有Leader服務器和Follow服務器 2、隨著集群規模擴大,follower變多,ZK在創建節點和選主等事務性請求時,需要一半以上節點AC,所以導致性能下降寫入操作越來越耗時,follower之間通信越來越耗時 3、為了解決這個問題,就引入了觀察者,可以處理讀,但是不參與投票,既保證了集群的擴展性,又避免過多服務器參與投票導致的集群處理請求能力下降`
2 一致性協議-ZAB
ZooKeeper 為了保證集群中各個節點讀寫資料的一致性和可用性,設計并實作了 ZAB 協議,ZAB 全稱是 ZooKeeper Atomic Broadcast,也就是 ZooKeeper 原子廣播協議,這種協議支持崩潰恢復,并基于主從模式,同一時刻只有一個 Leader,所有的寫操作都由 Leader 節點主導完成,而讀操作可通過任意節點完成,因此 ZooKeeper 讀性能遠好于寫性能,更適合讀多寫少的場景,
一旦 Leader 節點宕機,ZAB 協議的崩潰恢復機制能自動從 Follower 節點中重新選出一個合適的替代者,即新的 Leader,該程序即為領導選舉,領導選舉程序,是 ZAB 協議中最為重要和復雜的程序,
3. ZAB 協議讀寫流程
3.1 ZAB 寫流程
3.1.1 寫 Leader
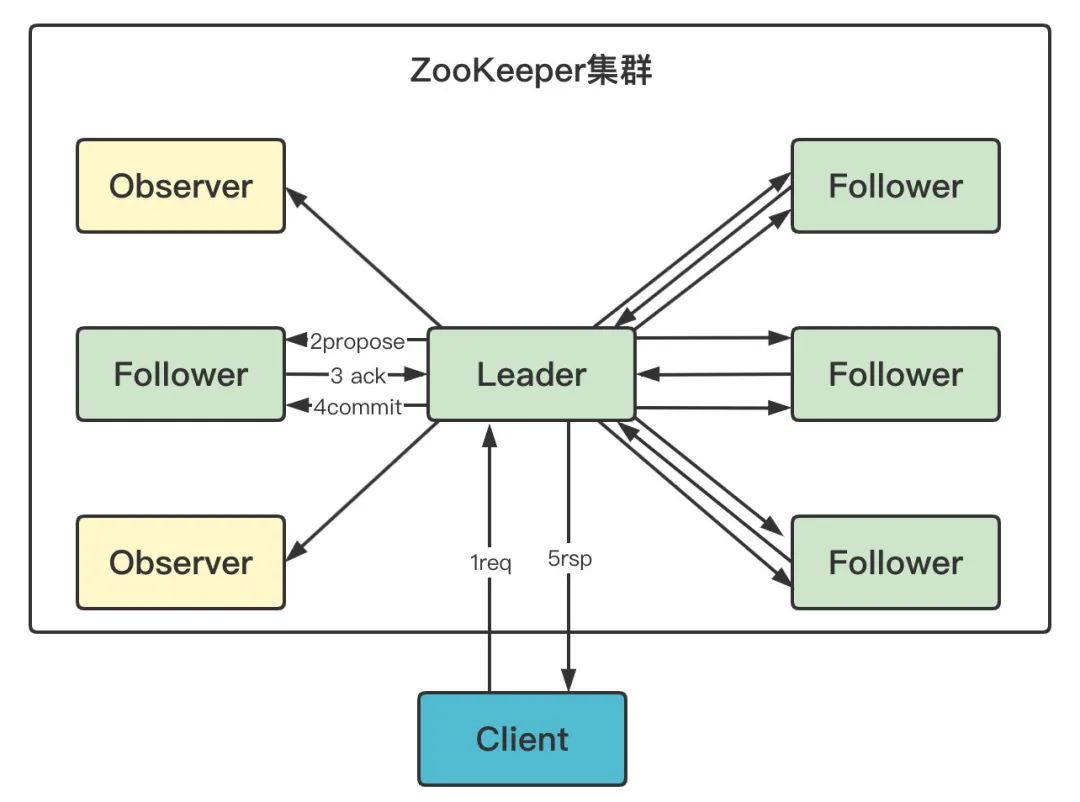
由上圖可見,通過 Leader 進行寫操作,主要分為五步:
-
客戶端向 Leader 發起寫請求 -
Leader 將寫請求以 Proposal 的形式發給所有 Follower 并等待 ACK -
Follower 收到 Leader 的 Proposal 后回傳 ACK -
Leader 得到過半數的 ACK(Leader 對自己默認有一個 ACK)后向所有的 Follower 和 Observer 發送 Commmit -
Leader 將處理結果回傳給客戶端
注意Leader并不需要得到Observer的ACK,即Observer無投票權
Leader不需要得到所有Follower的ACK,只要收到過半的ACK即可,同時Leader本身對自己有一個ACK,上圖中有4個Follower,只需其中兩個回傳ACK即可,因為(2+1) / (4+1) > 1/2
Observer雖然無投票權,但仍須同步Leader的資料從而在處理讀請求時可以回傳盡可能新的資料`
3.1.2 寫 Follower
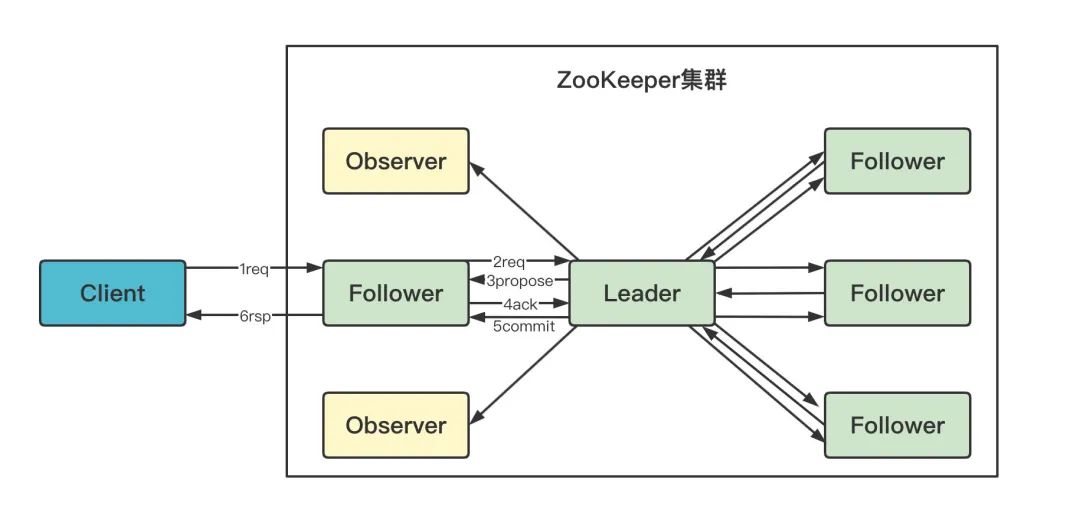
從上圖可見:
-
Follower 可接受寫請求,但不能直接處理,而需要將寫請求轉發給 Leader 處理 -
Observer 與 Follower 寫流程相同 -
除了多了一步請求轉發,其它流程與直接寫 Leader 無任何區別
3.2 ZAB 讀流程
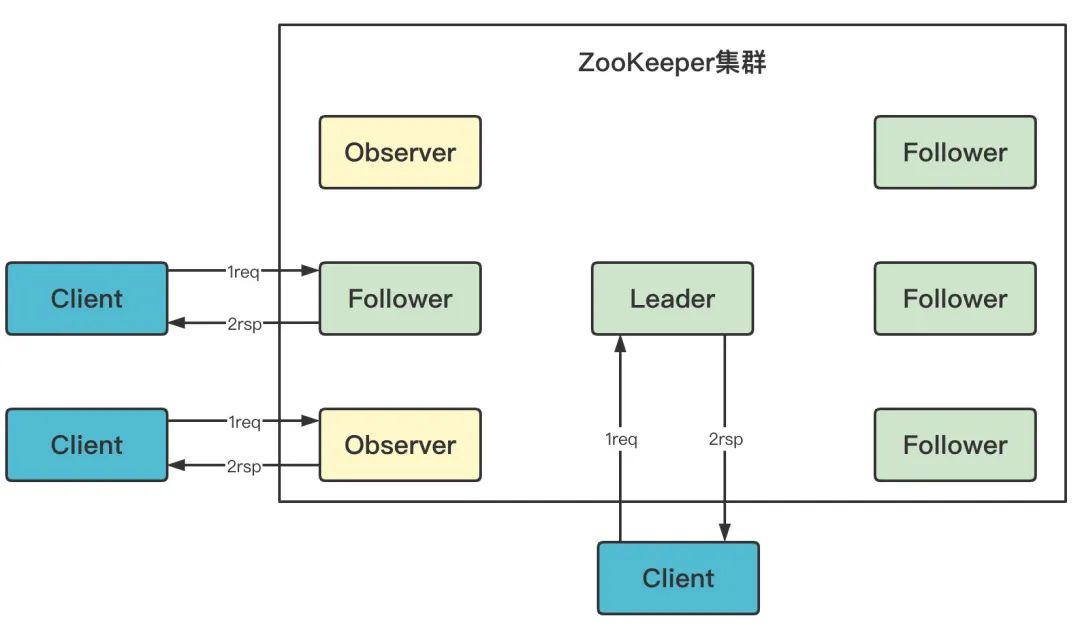
Leader/Follower/Observer 都可直接處理讀請求,從本地記憶體中讀取資料并回傳給客戶端即可,由于處理讀請求不需要服務器之間的互動,Follower/Observer 越多,整體可處理的讀請求量越大,也即讀性能越好,ZooKeeper官方檔案資料,Client數量1000時,讀寫性能比10:1
4 ZooKeeper Leader 選舉演算法
4.1 選舉演算法
ZooKeeper 中默認的并建議使用的 Leader 選舉演算法是:基于 TCP 的 FastLeaderElection,其他選舉演算法被廢棄,集群模式下 zoo.cfg 組態檔中有引數可配選舉演算法:

4.2 FastLeaderElection 選舉引數決議
(1)選舉演算法引數myid:每個 ZooKeeper 服務器,都需要在資料檔案夾下創建一個名為 myid 的檔案,該檔案包含整個 ZooKeeper 集群唯一的 ID(整數),例如,我們第二章中部署的 zk1/zk2/zk3 三個實體,其 myid 分別為 1、2 和 3,在組態檔中其 ID 與 hostname 必須一一對應,如下所示,在該組態檔中,server.后面的 id 即為 myid,該引數在選舉時如果無法通過其他判斷條件選擇 Leader,那么將該 ID 的大小來確定優先級,
// 集群配置
server.1=127.0.0.1:8881:7771 # server.id=host:port:port
server.2=127.0.0.1:8882:7772 # server.id=host:port:port
server.3=127.0.0.1:8883:7773 # server.id=host:port:portzxid:用于標識一次更新操作的 ID,為了保證順序性,該 zxid 必須單調遞增,因此 ZooKeeper 使用一個 64 位的數來表示,高 32 位是 Leader 的 epoch,從 1 開始,每次選出新的 Leader,epoch 加一,低 32 位為該 epoch 內的序號,每次有寫操作低 32 位加一,每次 epoch 變化,都將低 32 位的序號重置,這樣保證了 zxid 的全域遞增性,之前看到過有博主使用中國古代的年號來解釋這個欄位,非常形象:萬歷十五年,萬歷是 epoch,十五年是序號選票資料結構,每個服務器在進行選舉時,發送的選票包含如下關鍵資訊:
struct Vote {
logicClock // 邏輯時鐘,表示該服務器發起的第多少輪投票
state // 當前服務器的狀態 (LOOKING-不確定Leader狀態 FOLLOWING-跟隨者狀態 LEADING-領導者狀態 OBSERVING-觀察者狀態)
self_myid // 當前服務器的myid
self_zxid // 當前服務器上所保存的資料的最大zxid
vote_myid // 被推舉的服務器的myid
vote_zxid // 被推舉的服務器上所保存的資料的最大zxid
}節點服務器狀態,每個服務器所處的狀態時下面狀態中的一種:
-
LOOKING 不確定 Leader 狀態,該狀態下的服務器認為當前集群中沒有 Leader,會發起 Leader 選舉, -
FOLLOWING 跟隨者狀態,表明當前服務器角色是 Follower,并且它知道 Leader 是誰, -
LEADING 領導者狀態,表明當前服務器角色是 Leader,它會維護與 Follower 間的心跳, -
OBSERVING 觀察者狀態,表明當前服務器角色是 Observer,與 Folower 唯一的不同在于不參與選舉,也不參與集群寫操作時的投票,
4.3 選舉投票流程
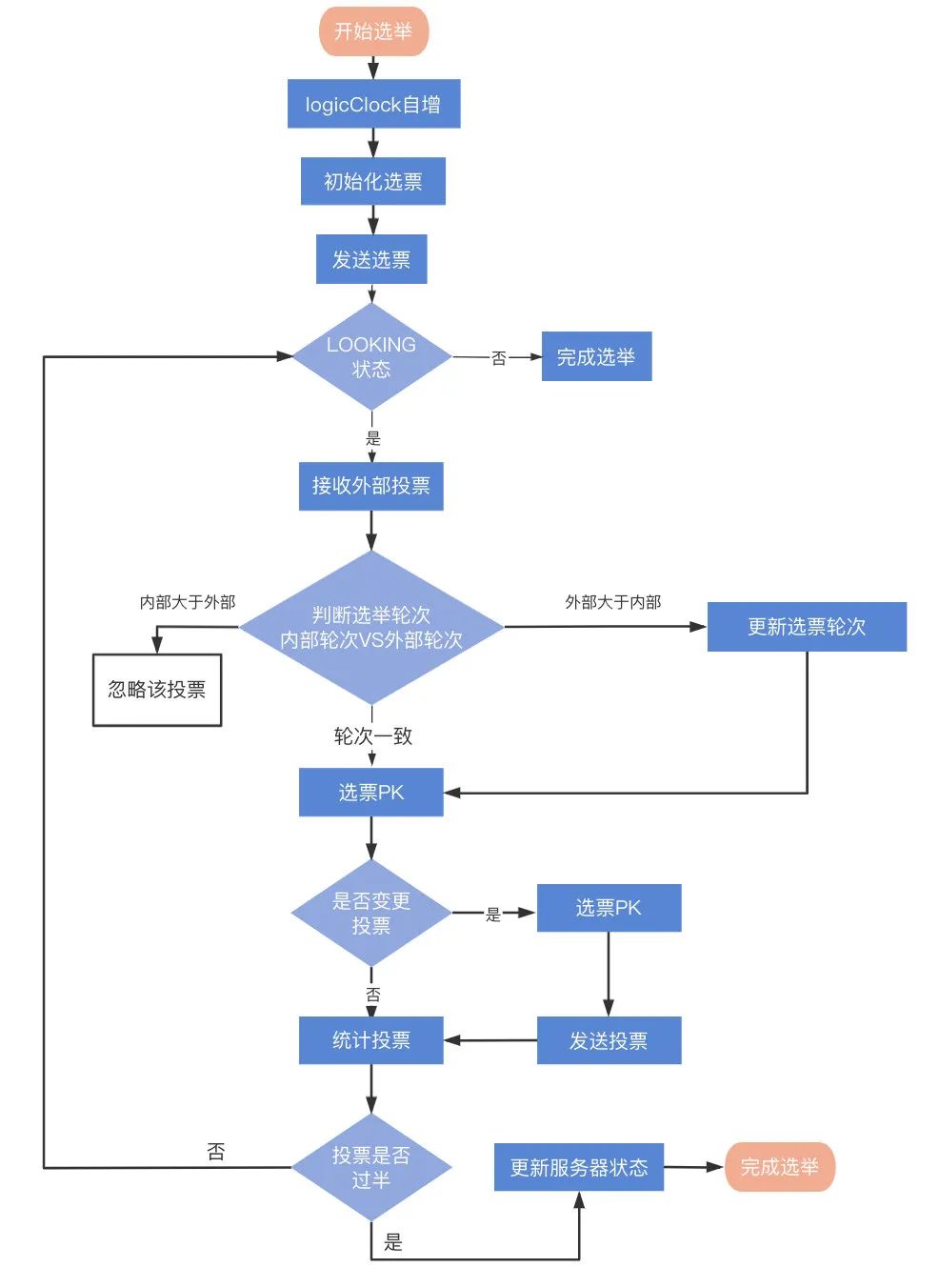
每個服務器的一次選舉流程:
-
自增選舉輪次:即 logicClock 加一,ZooKeeper 規定所有有效的投票都必須在同一輪次中,每個服務器在開始新一輪投票時,會先對自己維護的 logicClock 進行自增操作,
-
初始化選票:每個服務器在開始進行新一輪的投票之前,會將自己的投票箱清空,然后初始化自己的選票,在初始化階段,每臺服務器都會將自己推選為 Leader,也就是將票都投給自己,例如:服務器 1、2、3 都投票給自己(1->1), (2->2),(3->3),
-
發送初始化選票:每個服務器通過廣播將初始化投給自己的票廣播出去,讓其他服務器接收,
-
接收外部投票:服務器會嘗試從其它服務器獲取投票,并記入自己的投票箱內,如果無法獲取任何外部投票,則會確認自己是否與集群中其它服務器保持著有效連接,如果是,則再次發送自己的投票;如果否,則馬上與之建立連接,
-
判斷選舉輪次:收到外部投票后,首先會根據投票資訊中所包含的 logicClock 來進行不同處理,(1)如果大于當前服務的選票中的選舉次數,那么則會更新當前服務的 logicClock,并且清空所有收到的選票,再次拿選票和外部投票進行選票的比較,確定是否真的要更改自身的選票,然后重新發送選票資訊;(2)如果外部選票的選舉次數小于當前服務實體的選舉次數,那么直接無視掉這個選票資訊,并且繼續發送自身的選票出去;(3)如果外部選票和自身服務實體的選舉次數一致,那么就需要進入選票之間的比較操作,
-
選票 PK:選票 PK 是基于(self_myid, self_zxid)與(vote_myid, vote_zxid)的對比,
(1)外部投票的 logicClock 大于自己的 logicClock,則將自己的 logicClock 及自己的選票的 logicClock 變更為收到的 logicClock;
(2)若 logicClock 一致,則對比二者的 vote_zxid,若外部投票的 vote_zxid 比較大,則將自己的票中的 vote_zxid 與 vote_myid 更新為收到的票中的 vote_zxid 與 vote_myid 并廣播出去,另外將收到的票及自己更新后的票放入自己的票箱,如果票箱內已存在(self_myid, self_zxid)相同的選票,則直接覆寫;
(3)若二者 vote_zxid 一致,則比較二者的 vote_myid,若外部投票的 vote_myid 比較大,則將自己的票中的 vote_myid 更新為收到的票中的 vote_myid 并廣播出去,另外將收到的票及自己更新后的票放入自己的票箱,
-
統計選票:如果已經確定有過半服務器認可了自己的投票(可能是更新后的投票),則終止投票,否則繼續接收其它服務器的投票,
-
更新服務器狀態:投票終止后,服務器開始更新自身狀態,若過半的票投給了自己,則將自己的服務器狀態更新為 LEADING,否則將自己的狀態更新為 FOLLOWING,
同時還需要注意的一點是,即使選票超過半數了,選出 Leader 服務實體了,也不是立刻結束,而是等待 200ms,確保沒有丟失其他服務的更優的選票,
5 ZooKeeper 集群啟動選舉流程圖解
5.1 集群啟動領導選舉
1、各自推選自己:ZooKeeper 集群剛啟動時,所有服務器的 logicClock 都為 1,zxid 都為 0,各服務器初始化后,先把第一票投給自己并將它存入自己的票箱,同時廣播給其他服務器,此時各自的票箱中只有自己投給自己的一票,如下圖所示:
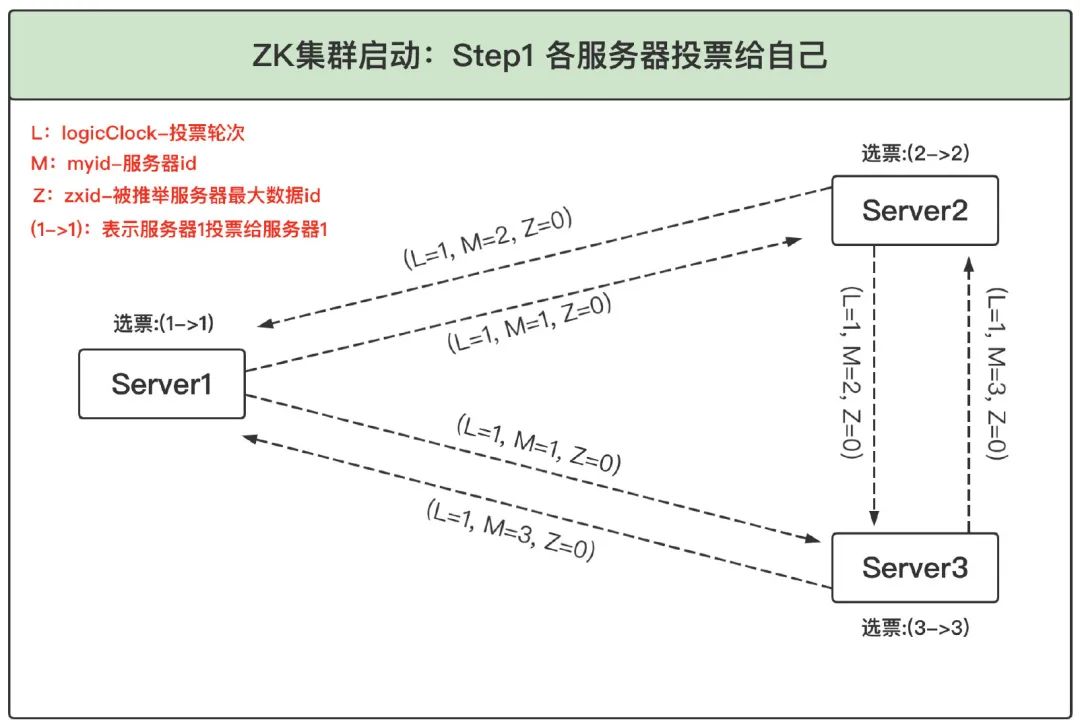
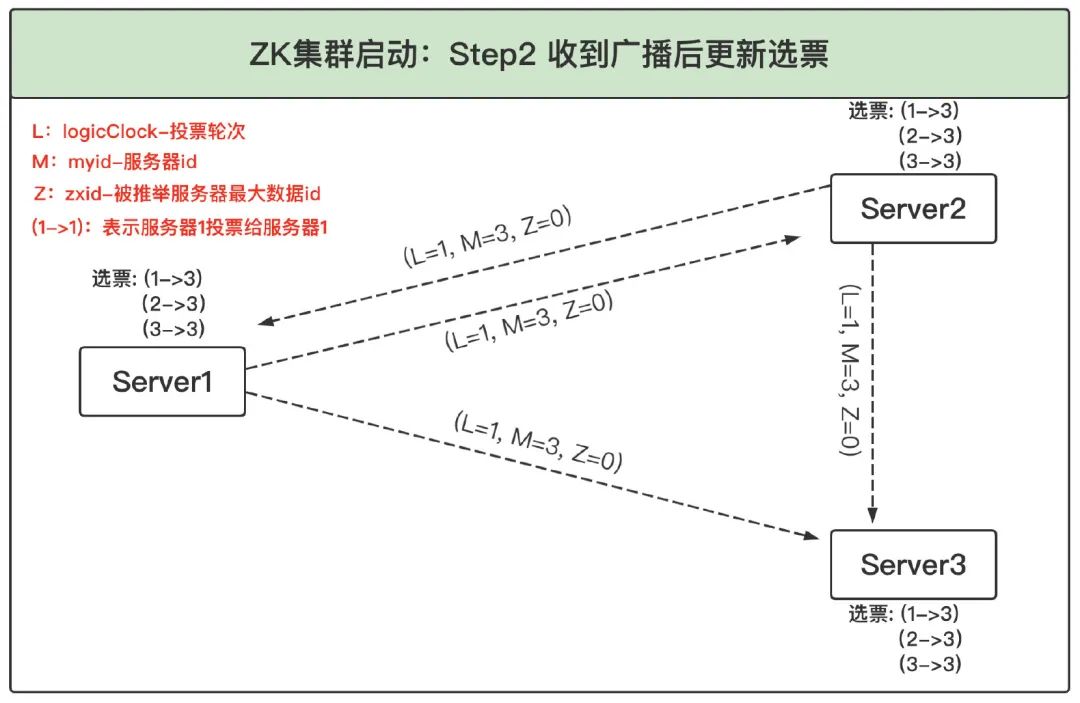
2、更新選票:第一步中各個服務器先投票給自己,并把投給自己的結果廣播給集群中的其他服務器,這一步其他服務器接收到廣播后開始更新選票操作(如果對此規則不熟悉,可以對照4.3 選舉投票流程小節),以 Server1 為例流程如下:
(1)Server1 收到 Server2 和 Server3 的廣播選票后,由于 logicClock 和 zxid 都相等,此時就比較 myid;
(2)Server1 收到的兩張選票中 Server3 的 myid 最大,此時 Server1 判斷應該遵從 Server3 的投票決定,將自己的票改投給 Server3,接下來 Server1 先清空自己的票箱(票箱中有第一步中投給自己的選票),然后將自己的新投票(1->3)和接收到的 Server3 的(3->3)投票一起存入自己的票箱,再把自己的新投票決定(1->3)廣播出去,此時 Server1 的票箱中有兩票:(1->3),(3->3);
(3)同理,Server2 收到 Server3 的選票后也將自己的選票更新為(2->3)并存入票箱然后廣播,此時 Server2 票箱內的選票為(2->3),(3->3);
(4)Server3 根據上述規則,無須更新選票,自身的票箱內選票仍為(3->3);
(5)Server1 與 Server2 重新投給 Server3 的選票廣播出去后,由于三個服務器最新選票都相同,最后三者的票箱內都包含三張投給服務器 3 的選票,
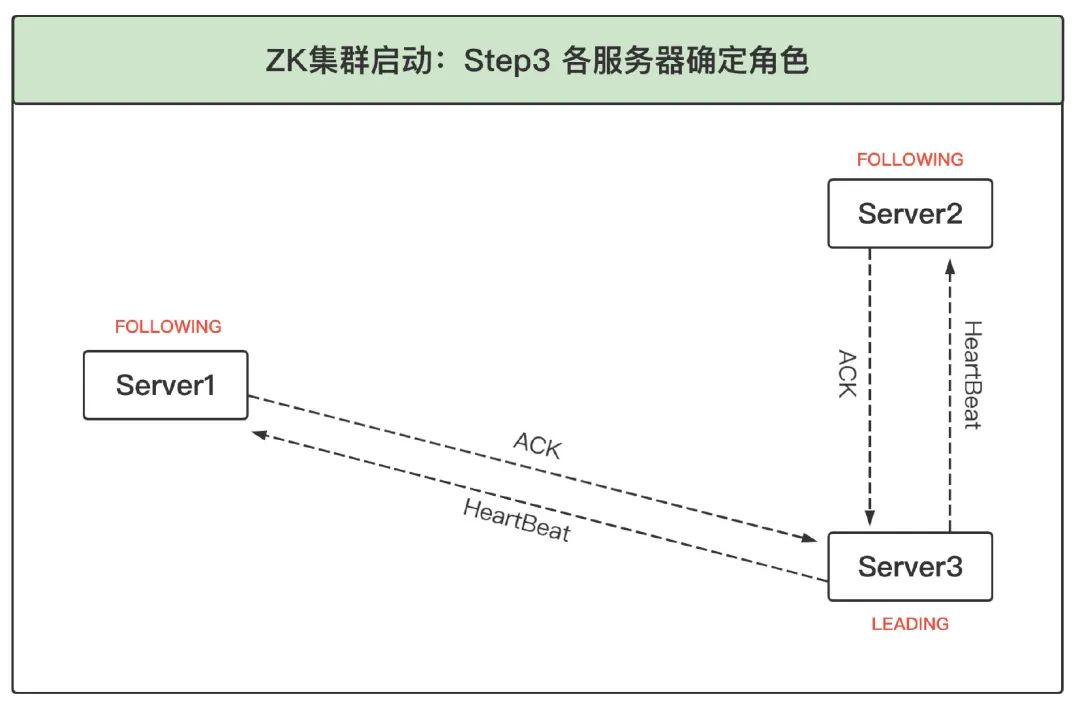
3、根據選票確定角色:根據上述選票,三個服務器一致認為此時 Server3 應該是 Leader,因此 Server1 和 Server2 都進入 FOLLOWING 狀態,而 Server3 進入 LEADING 狀態,之后 Leader 發起并維護與 Follower 間的心跳,
5.2 Follower 重啟選舉
本節討論 Follower 節點發生故障重啟或網路產生磁區恢復后如何進行選舉,1、Follower 重啟投票給自己:Follower 重啟,或者發生網路磁區后找不到 Leader,會進入 LOOKING 狀態并發起新的一輪投票,
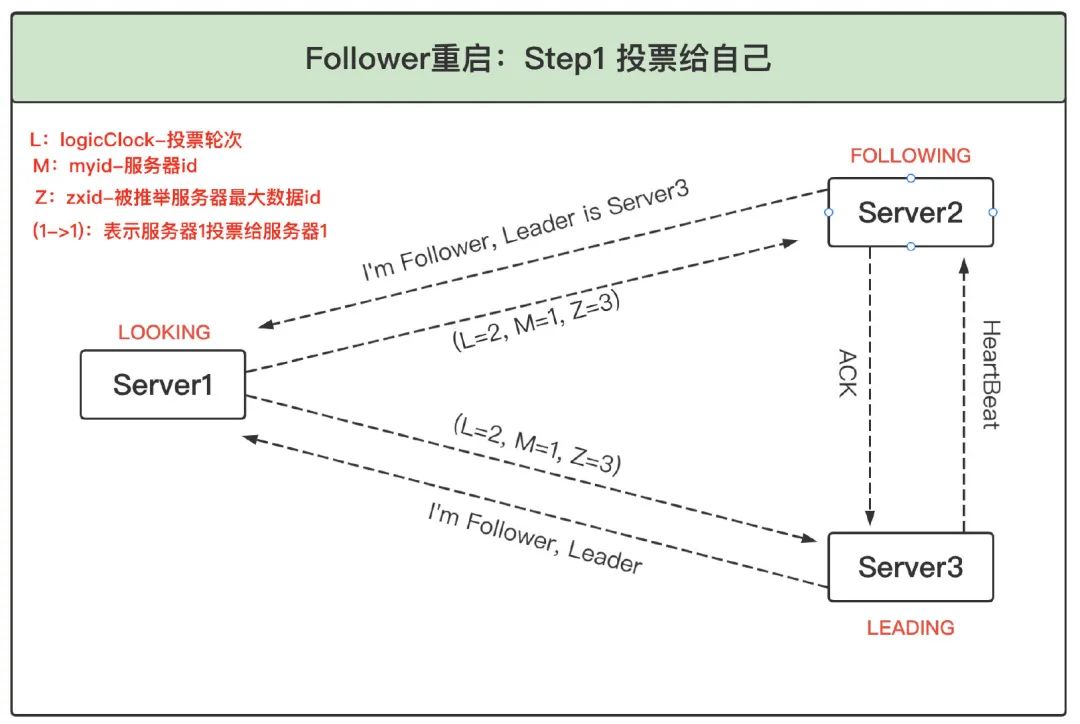
2、發現已有 Leader 后成為 Follower:Server3 收到 Server1 的投票后,將自己的狀態 LEADING 以及選票回傳給 Server1,Server2 收到 Server1 的投票后,將自己的狀態 FOLLOWING 及選票回傳給 Server1,此時 Server1 知道 Server3 是 Leader,并且通過 Server2 與 Server3 的選票可以確定 Server3 確實得到了超過半數的選票,因此服務器 1 進入 FOLLOWING 狀態,
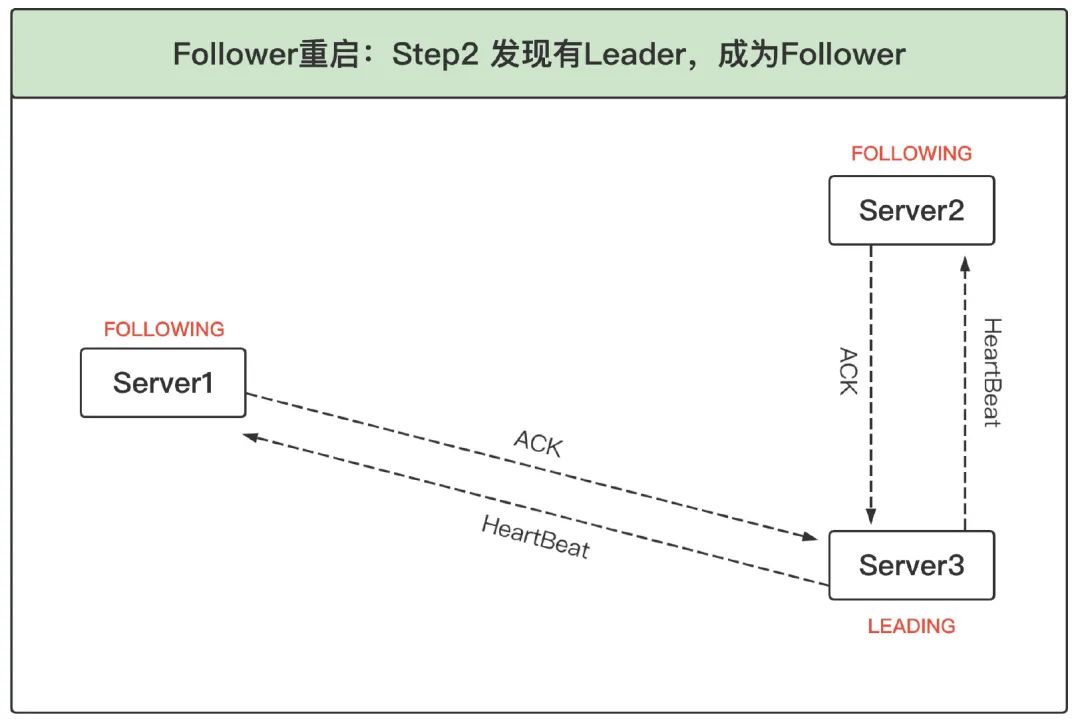
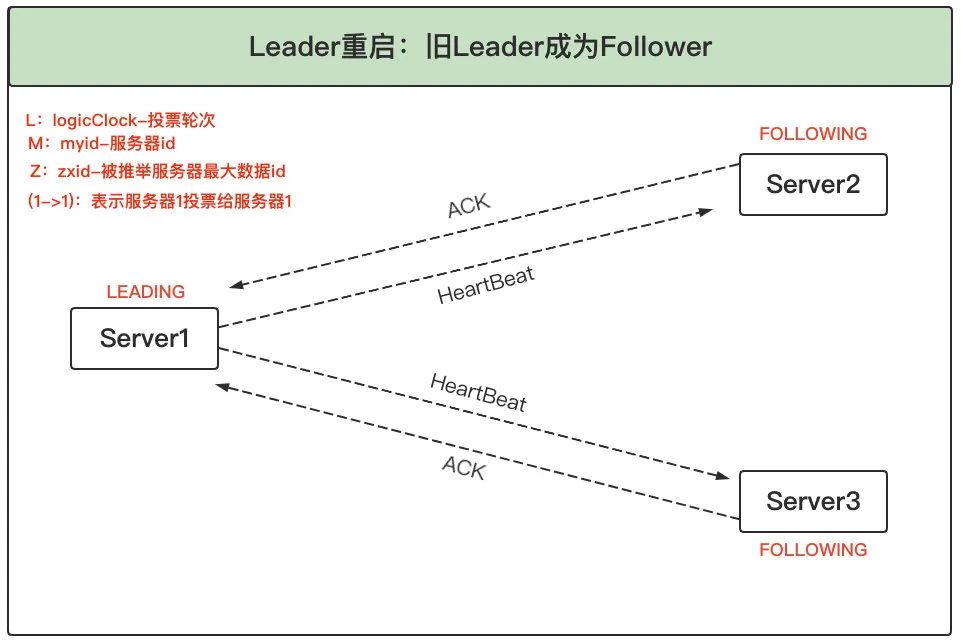
5.3 Leader 宕機重啟選舉
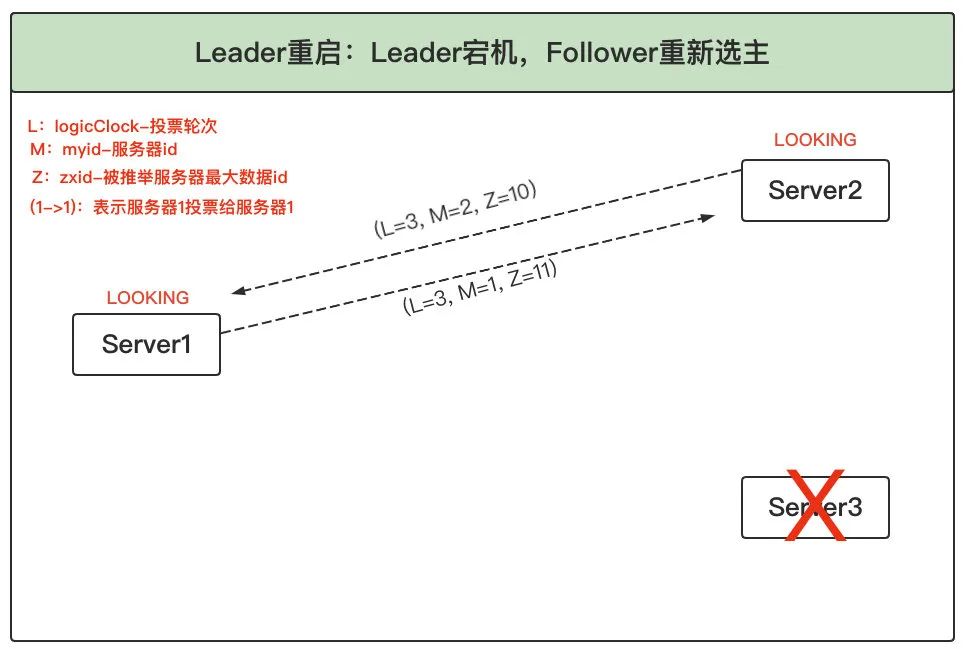
1、Follower 發起新投票:Leader(Server3)宕機后,Follower(Server1 和 2)發現 Leader 不作業了,因此進入 LOOKING 狀態并發起新的一輪投票,并且都將票投給自己,同時將投票結果廣播給對方,
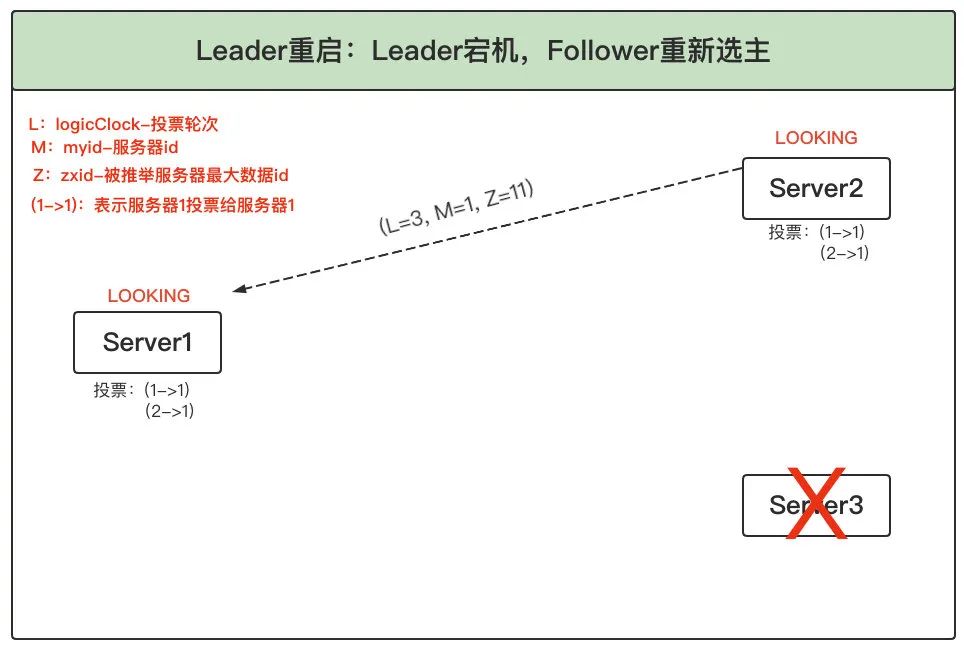
2、更新選票:(1)Server1 和 2 根據外部投票確定是否要更新自身的選票,這里跟之前的選票 PK 流程一樣,比較的優先級為:logicLock > zxid > myid,這里 Server1 的引數(L=3, M=1, Z=11)和 Server2 的引數(L=3, M=2, Z=10),logicLock 相等,zxid 服務器 1 大于服務器 2,因此服務器 2 就清空已有票箱,將(1->1)和(2->1)兩票存入票箱,同時將自己的新投票廣播出去 (2)服務器 1 收到 2 的投票后,也將自己的票箱更新,
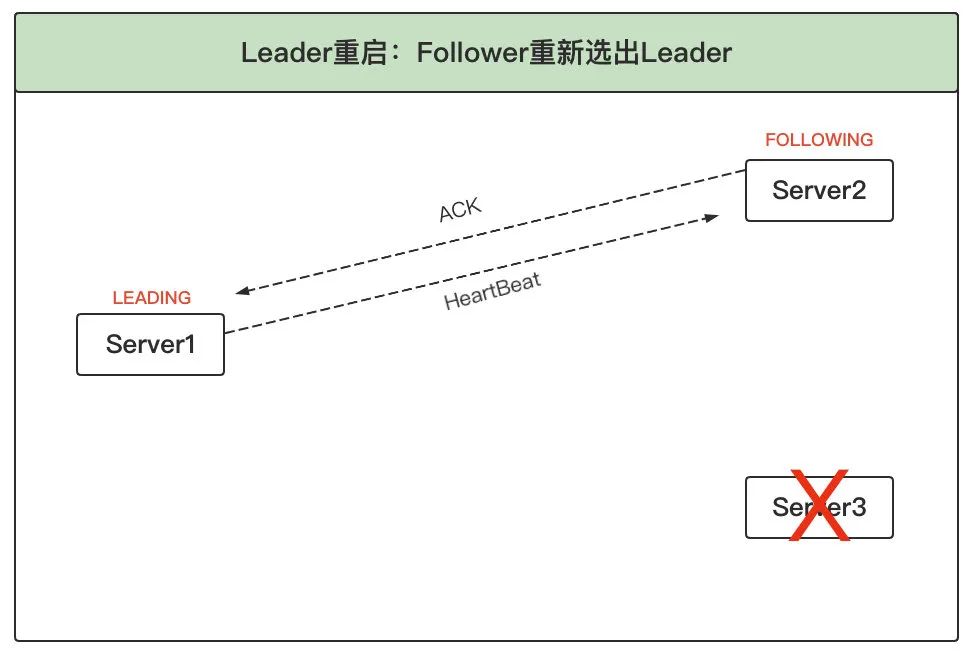
3、重新選出 Leader:此時由于只剩兩臺服務器,服務器 1 投票給自己,服務器 2 投票給 1,所以 1 當選為新 Leader,
4、舊 Leader 恢復發起選舉:之前宕機的舊 Leader 恢復正常后,進入 LOOKING 狀態并發起新一輪領導選舉,并將選票投給自己,此時服務器 1 會將自己的 LEADING 狀態及選票回傳給服務器 3,而服務器 2 將自己的 FOLLOWING 狀態及選票回傳給服務器 3,
5、舊 Leader 成為 Follower:服務器 3 了解到 Leader 為服務器 1,且根據選票了解到服務器 1 確實得到過半服務器的選票,因此自己進入 FOLLOWING 狀態,
6 commit 過的資料不丟失
ZK 的資料寫入都是通過 Leader,一條資料寫入程序中,ZK 服務集群中只有超過一半的服務器回傳給 Leader ACK 后,Leader 服務器才會 Commit 這條訊息,同步到每一個節點,已經被過 Leader commit,也就是被過半節點同步過的訊息,在 Leader 宕機之后,重新選舉出 Leader 這個訊息也不會丟失,但是未被 commit 也就是未被過半節點復制到的訊息則會丟失,
四、參考文獻 && 鳴謝
-
https://forthe77.github.io/2019/03/25/one-zookeeper-deploy/ -
https://blog.nowcoder.net/n/16f13a7d72b2496c8ff4da080f777a5a -
https://blog.csdn.net/Weixiaohuai/article/details/112788171 -
https://www.cnblogs.com/IcanFixIt/p/7818592.html -
https://www.runoob.com/w3cnote/zookeeper-znode-data-model.html -
https://www.cnblogs.com/reycg-blog/p/10208585.html -
https://dbaplus.cn/news-141-1875-1.html -
https://www.infoq.cn/article/us5gjqqz8bmbeha25io0 -
20 共識演算法:一次性說清楚 Paxos、Raft 等演算法的區別 -
http://learn.lianglianglee.com/專欄/24講吃透分布式資料庫-完/20 共識演算法:一次性說清楚 Paxos、Raft 等演算法的區別.md -
https://juejin.cn/post/6907151199141625870 -
https://lotabout.me/2019/QQA-What-is-Sequential-Consistency/ -
http://fishleap.top/pages/a958bc/#_6-%E4%B8%80%E8%87%B4%E6%80%A7%E7%AE%97%E6%B3%95 -
https://developer.aliyun.com/article/768655 https://www.cnblogs.com/aspirant/p/8994227.html -
https://blog.xiaohansong.com/lamport-logic-clock.html http://icyfenix.cn/distribution/consensus/ -
https://dbaplus.cn/news-141-2053-1.html https://www.infoq.cn/article/dvaaj71f4fbqsxmgvdce -
https://segmentfault.com/a/1190000039760185 -
https://blog.csdn.net/chenshijie2011/article/details/118075170?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1.pc_relevant_default&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1.pc_relevant_default&utm_relevant_index=2 -
https://javaedge.blog.csdn.net/article/details/110585930?spm=1001.2101.3001.6650.4&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-4.pc_relevant_default&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-4.pc_relevant_default&utm_relevant_index=7
作者:jacli
本文來自博客園,作者:古道輕風,轉載請注明原文鏈接:https://www.cnblogs.com/88223100/p/Explain-ZooKeeper-application-scenario-and-architecture-from-0-to-1.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/542235.html
標籤:其他