目錄
- 什么是RabbitMQ?
- 為什么使用MQ?MQ的優點
- 訊息中間件比對
- RabbitMQ
- RocketMQ
- Kafka
- 選型建議
- MQ 有哪些常見問題?ranbbitMQ如何解決這些問題?
- MQ 有哪些常見問題?
- 訊息的順序問題
- 訊息的重復問題
- 訊息積壓
- rabbitMQ如何解決這些問題?
- rabbitMQ解決訊息的順序方案
- rabbitMQ解決訊息的重復問題方案
- rabbitMQ解決訊息積壓方案
- RabbitMQ訊息的可靠傳輸?訊息丟失怎么辦?
- 生產者的訊息確認機制
- 消費者的訊息確認機制
- 訊息佇列的持久化
- RabbitMQ高可用
- MQ 有哪些常見問題?
什么是RabbitMQ?
RabbitMQ是一款開源的,Erlang撰寫的,基于AMQP協議的訊息中間件
為什么使用MQ?MQ的優點
-
異步處理 - 相比于傳統的串行、并行方式,提高了系統的吞吐量,
-
應用解耦 - 系統間通過訊息通信,不用關心其他系統的處理,
-
流量削鋒 - 可以通過訊息佇列長度控制請求量,可以緩解短時間內的高并發請求,
-
訊息通訊 - 訊息佇列一般都內置了高效的通信機制,因此也可以用在純訊息通訊上,比如實作點對點訊息佇列,或者聊天室等,
-
日志處理 - 解決大量日志傳輸,
訊息中間件比對
ActiveMQ、RabbitMQ、RocketMQ、Kafka有什么優缺點?
| ActiveMQ | RabbitMQ | RocketMQ | Kafka | ZeroMQ | |
|---|---|---|---|---|---|
| 單機吞吐量 | 比RabbitMQ低 | 2.6w/s(訊息做持久化) | 11.6w/s | 17.3w/s | 29w/s |
| 開發語言 | Java | Erlang | Java | Scala/Java | C |
| 主要維護者 | Apache | Mozilla/Spring | Alibaba | Apache | iMatix,創始人已去世 |
| 成熟度 | 成熟 | 成熟 | 開源版本不夠成熟 | 比較成熟 | 只有C、PHP等版本成熟 |
| 訂閱形式 | 點對點(p2p)、廣播(發布-訂閱) | 提供了4種:direct, topic ,Headers和fanout,fanout就是廣播模式 | 基于topic/messageTag以及按照訊息型別、屬性進行正則匹配的發布訂閱模式 | 基于topic以及按照topic進行正則匹配的發布訂閱模式 | 點對點(p2p) |
| 持久化 | 支持少量堆積 | 支持少量堆積 | 支持大量堆積 | 支持大量堆積 | 不支持 |
| 順序訊息 | 不支持 | 不支持 | 支持 | 支持 | 不支持 |
| 性能穩定性 | 好 | 好 | 一般 | 較差 | 很好 |
| 集群方式 | 支持簡單集群模式,比如'主-備',對高級集群模式支持不好, | 支持簡單集群,'復制'模式,對高級集群模式支持不好, | 常用 多對'Master-Slave' 模式,開源版本需手動切換Slave變成Master | 天然的‘Leader-Slave’無狀態集群,每臺服務器既是Master也是Slave | 不支持 |
| 管理界面 | 一般 | 較好 | 一般 | 無 | 無 |
RabbitMQ
-
可以支撐高并發、高吞吐量、性能很高,同時有非常完善便捷的后臺管理界面可以使用,
-
另外,他還支持集群化、高可用部署架構、訊息高可靠支持,功能較為完善,
-
RabbitMQ的開源社區很活躍,較高頻率的版本迭代,來修復發現的bug以及進行各種優化,因此綜合考慮過后,公司采取了RabbitMQ,
-
RabbitMQ也有一點缺陷,就是他自身是基于erlang語言開發的,所以導致較為難以分析里面的原始碼,也較難進行深層次的原始碼定制和改造,需要較為扎實的erlang語言功底,
RocketMQ
-
開源的,經過阿里生產環境的超高并發、高吞吐的考驗,性能卓越,同時還支持分布式事務等特殊場景,
-
RocketMQ是基于Java語言開發的,適合深入閱讀原始碼,有需要可以站在原始碼層面解決線上問題,包括原始碼的二次開發和改造,
Kafka
-
Kafka提供的訊息中間件的功能明顯較少一些,相對上述幾款MQ中間件要少很多,
-
Kafka的優勢在于專為超高吞吐量的實時日志采集、實時資料同步、實時資料計算等場景,
-
Kafka在大資料領域中配合實時計算技術(比如Spark Streaming、Storm、Flink)使用的較多,但是在傳統的MQ中間件使用場景中較少采用,
選型建議
RabbitMQ, erlang 語言阻止了大量的 Java 工程師去深入研究和掌控它,對公司而言,幾乎處于不可控的狀態,但是確實人家是開源的,比較穩定的支持,活躍度也高;
RocketMQ, 越來越多的公司會去用 RocketMQ,確實很不錯,畢竟是阿里出品,但社區可能有突然黃掉的風險(目前 RocketMQ 已捐給 Apache,但 GitHub 上的活躍度其實不算高)對自己公司技術實力有絕對自信的,推薦用 RocketMQ
中小型公司,技術實力較為一般,技術挑戰不是特別高,用 RabbitMQ 是不錯的選擇;大型公司,基礎架構研發實力較強,用 RocketMQ 是很好的選擇
如果是大資料領域的實時計算、日志采集等場景,用 Kafka 是業內標準的,絕對沒問題,社區活躍度很高,絕對不會黃,何況幾乎是全世界這個領域的事實性規范
MQ 有哪些常見問題?ranbbitMQ如何解決這些問題?
MQ 有哪些常見問題?
訊息的順序問題
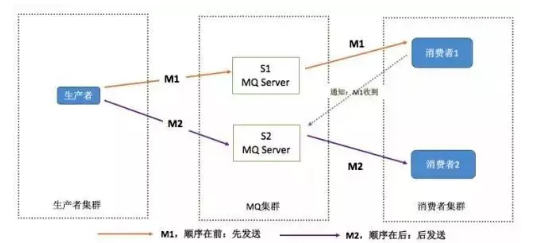
訊息有序指的是可以按照訊息的發送順序來消費,
假如生產者產生了 2 條訊息:M1、M2,假定 M1 發送到 S1,M2 發送到 S2,要保證 M1 先于 M2 被消費順序,
訊息的重復問題
造成訊息重復的常見原因是:網路不可達,重試機制造成,
所以解決這個問題的辦法就是繞過這個問題,那么問題就變成了:如果消費端收到兩條一樣的訊息,應該怎樣處理?
訊息積壓
由于消費者速率遠低于生產者,或者是消費者宕機,訊息中間件中有大量訊息積壓到佇列中
rabbitMQ如何解決這些問題?
rabbitMQ解決訊息的順序方案
RabbitMQ:拆分多個 queue,每個 queue 一個 consumer,就是多一些 queue 而已,確實是麻煩點;或者就一個 queue 但是對應一個 consumer,然后這個 consumer 內部用記憶體佇列做排隊,然后分發給底層不同的 worker 來處理,
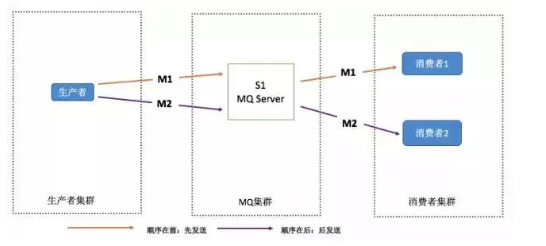
缺陷:
-
并行度就會成為訊息系統的瓶頸(吞吐量不夠)
-
更多的例外處理,比如:只要消費端出現問題,就會導致整個處理流程阻塞,我們不得不花費更多的精力來解決阻塞的問題,通過合理的設計或者將問題分解來規避,
-
不關注順序的應用實際大量存在
-
佇列無序并不意味著訊息無序,所以從業務層面來保證訊息的順序而不僅僅是依賴于訊息系統,是一種更合理的方式,
其他解決方案
-
方案一:消費端使用redis存盤訊息記錄表,通過redis鎖,控制消費者按照順序消費,
-
方案三:采用RocketMQ順序消費機制;(不建議使用,會降低系統吞吐量)
rabbitMQ解決訊息的重復問題方案
消費端處理訊息的業務邏輯需要保持冪等性,使用redis存盤訊息id作為日志表,只要保持冪等性,不管來多少條重復訊息,最后處理的結果都一樣,保證每條訊息都有唯一編號和redis添加一張日志表來記錄已經處理成功的訊息的 ID,如果新到的訊息 ID 已經在日志表中,那么就不再處理這條訊息,
rabbitMQ解決訊息積壓方案
出現訊息積壓的問題,首先要排除掉消費者宕機的問題,其次,再根據監控面板,觀察消費者和生產者消費訊息及生產訊息的速率,
- 生產者速率增加:一般電商系統大促時,比較常見,往往的應對手段是擴容消費端的實體數或服務降級,
- 消費者速率減少:檢查一下日志是否有大量的消費錯誤,或是消費執行緒卡死或是等待資源鎖死,
- 速率無變化:可能是消費失敗導致的一條訊息反復消費,從而拖慢整個系統的消費速度
RabbitMQ訊息的可靠傳輸?訊息丟失怎么辦?
RabbitMQ提供了訊息確認機制來確保訊息的可靠傳輸
訊息訊息確認機制包括兩部分:生產者到訊息中間件,即訊息的發布確認,訊息中間件到消費者,即訊息的消費確認,
生產者的訊息確認機制
rabbit的生產者客戶端提供了訊息發布的回呼介面,一旦生產者訊息到交換機失敗,則會觸發回呼,同理,交換機到訊息佇列也有回呼介面,一旦交換機向訊息佇列投遞訊息失敗,則會觸發回呼,
/**
* 訊息->交換機 回呼函式
* ack:true 發送成功 false: 發送失敗
*/
private final RabbitTemplate.ConfirmCallback confirmCallback = (correlationData, ack, cause) -> {
//可以增加補償機制
if (!ack) {
log.error("sendMsg:=======> Msg To Exchange Failed! Cause:{}", cause);
}
};
/**
* 交換機->訊息佇列 回呼函式
* 發送失敗:觸發returnCallback回呼函式
*/
private final RabbitTemplate.ReturnCallback returnCallback = (message, replyCode, replyText, exchange, routingKey) ->
//可以增加補償機制
log.error("sendMsg:=======> Exchange To Queue Failed! Message:{} Exchange:{} RoutingKey:{} Replay:{}", message.toString(), exchange, routingKey, replyText);
消費者的訊息確認機制
rabbitMQ開啟手動確認訊息,消費端需要收到訊息之后,手動ack才可表示訊息消費成功,否則可以投遞到死信佇列或者訊息重試,
訊息佇列的持久化
還有一種常見情況是,我們經常會遇到需要重啟中間件,或者是中間件宕機的問題,那么就需要開啟訊息持久化,否則會發生訊息還沒來得及消費會丟失的問題,
-
將queue的持久化標識durable設定為true,則代表是一個持久的佇列
-
發送訊息的時候將deliveryMode=2
RabbitMQ高可用
rabbitMQ有三種模式:單機模式、普通集群模式、鏡像集群模式
- 單機模式:就是部署一個rabbitMQ實體
- 集群模式:意思就是在多臺機器上啟動多個 RabbitMQ 實體,每個機器啟動一個,你創建的 queue,只會放在一個 RabbitMQ 實體上,但是每個實體都同步 queue 的元資料(元資料可以認為是 queue 的一些配置資訊,通過元資料,可以找到 queue 所在實體),你消費的時候,實際上如果連接到了另外一個實體,那么那個實體會從 queue 所在實體上拉取資料過來,這方案主要是提高吞吐量的,就是說讓集群中多個節點來服務某個 queue 的讀寫操作,
- 鏡像集群模式:這種模式,才是所謂的 RabbitMQ 的高可用模式,跟普通集群模式不一樣的是,在鏡像集群模式下,你創建的 queue,無論元資料還是 queue 里的訊息都會存在于多個實體上,就是說,每個 RabbitMQ 節點都有這個 queue 的一個完整鏡像,包含 queue 的全部資料的意思,然后每次你寫訊息到 queue 的時候,都會自動把訊息同步到多個實體的 queue 上,RabbitMQ 有很好的管理控制臺,就是在后臺新增一個策略,這個策略是鏡像集群模式的策略,指定的時候是可以要求資料同步到所有節點的,也可以要求同步到指定數量的節點,再次創建 queue 的時候,應用這個策略,就會自動將資料同步到其他的節點上去了,這樣的話,好處在于,你任何一個機器宕機了,沒事兒,其它機器(節點)還包含了這個 queue 的完整資料,別的 consumer 都可以到其它節點上去消費資料,壞處在于,第一,這個性能開銷也太大了吧,訊息需要同步到所有機器上,導致網路帶寬壓力和消耗很重!RabbitMQ 一個 queue 的資料都是放在一個節點里的,鏡像集群下,也是每個節點都放這個 queue 的完整資料,
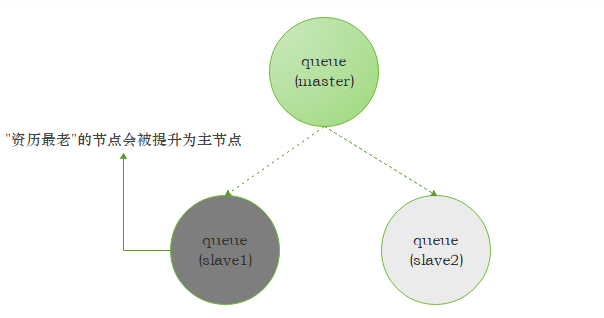
鏡像集群節點圖
slave 會準確地按照 master 執行命令順序進行動作,故 slave 和 master 上維護的狀態應該也是相同的,如果master 由于某種原因宕機了,那么"資源最老"的slave會被提升為新的master,
根據slave 加入的時間排序,時間最長的 slave 即為"資歷最老",發送到鏡像佇列的所有的訊息會被同時發往 master 和所有的slave,如果此時 master 掛掉了,訊息還會在 slave 上,這樣 slave 提升為 master 的時候訊息也不會丟失
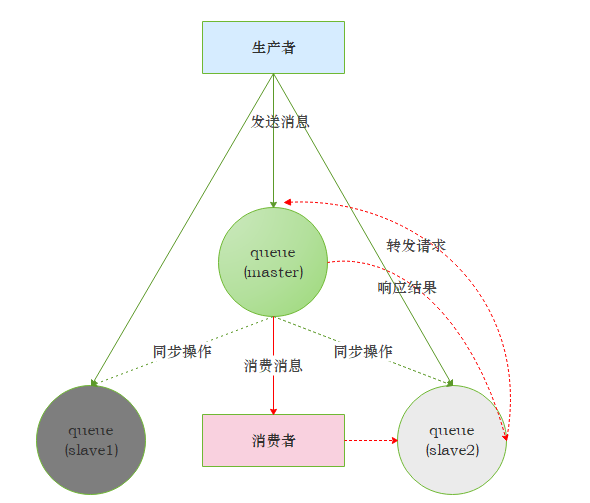
鏡像集群作業模式圖
除發送訊息(Basic.Publish)外的所有動作都只會向 master 發送,然后再由 master 將命令執行的結果廣播給各個 slave,如果消費者與 slave 建立連接并進行訂閱訊息,其實質上都是從 master 上獲取訊息,只不過看似是從 slave 上消費而已,比如:消費者與 slave 建立了 TCP 連接之后執行一個 Basic.GET 的操作,那么首先是由 slave 將 Basic.GET 請求發往 master,再由 master 準備好資料回傳給 slave,最后由 slave投遞給消費者,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/542642.html
標籤:其他
下一篇:認知篇:CQRS架構模式的本質