
-
本文首先從聚合根的生命周期和生存環境出發,引出了Repository概念,并說明其本質是管理中間程序的集合容器(2.1節);
-
根據集合容器的概念,在領域角度去挖掘出Repository的職責,并提出了倉儲物體轉移模式用作對不同倉儲實作的對比標準(2.2節);
-
然后從實作例子出發,介紹了一種純記憶體實作的倉儲,用作體現倉儲最佳實作(3.1節);
-
繼續從實作例子出發,介紹了關系型資料庫下的倉儲特點,并描述面向持久化的倉儲的特點(3.4節);
2.1 聚合物體
-
標識:物體具有唯一標識,這個唯一標識使得物體和值物件區分開來;
-
狀態:物體是具有可以被改變的狀態,因此聚合物體無法被靜態描述;
-
生命周期:物體擁有生命周期,從物體的創建,到物體的狀態的終態;
-
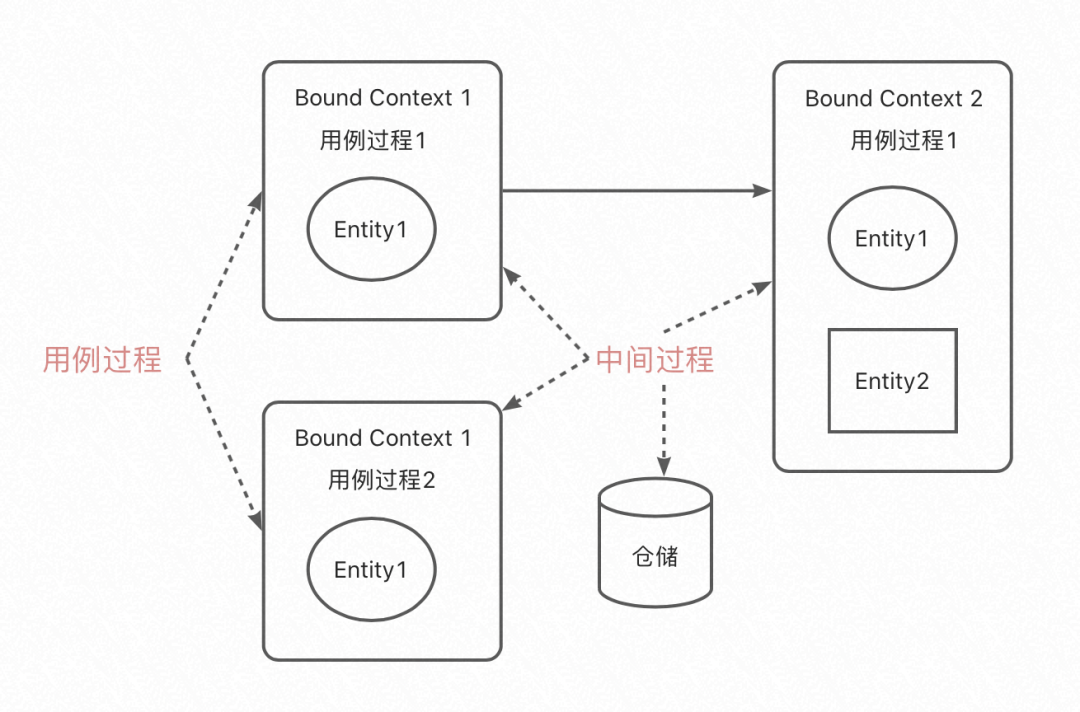
生存環境:物體的活動存在于各個背景關系中的領域服務或者應用服務中,其中分用例程序和中間程序;
-
用例程序:只要在執行用例程序的時候才需要物體的存在,其他時候,物體生命周期并沒有結束,而是處于中間狀態;
-
中間程序:當沒有任何用例在處理一個物體的時候,物體消失了嗎?沒有,它仍然存在生命周期內,這個時候我們認為物體正處在一種中間程序,
-
放置:建立一個新的聚合物體,這是一個聚合物體生命的開始,在用例程序結束后,把聚合物體放到倉儲中;
-
查找:把已經存在的聚合物體找出來,這是一個聚合物體的中間程序到用例程序的行為;
-
管理:它負責聚合物體的中間程序管理,并屏蔽掉中間程序的細節,向領域層提供統一的能力抽象,一些資料統計類的也可以在該范疇內;
-
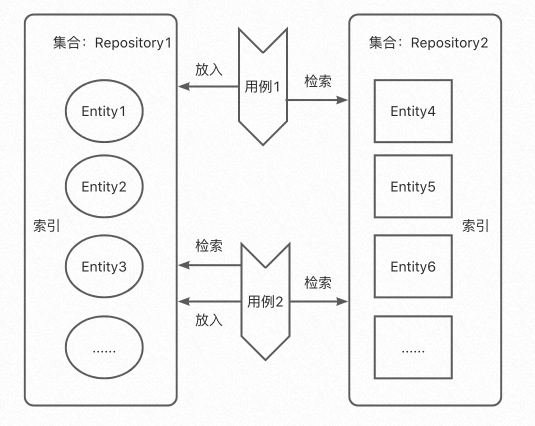
如何放置物體:為了方便管理,我們通常會采用分治把同一種型別的物體放在一起成為一個集合,相同型別和集合給了我們一個指導就是:倉儲的設計應該是一個聚合物體型別對應一個倉儲物體,具有一一對應關系,所以倉儲物體應該是一個保存相同型別元素的集合容器;
-
如何查找物體:我們知道物體具有唯一標識別,也具有其他特征屬性,所以為了查找物體,我們應該通過物體的唯一標識或者特征屬性去遍歷查找,倉儲應當提供這種功能,所以倉儲應該針對聚合物體欄位具有索引查找功能;
-
如何查找倉儲:既然我們提到了需要用倉儲來查找物體,那么我們又是如何查到倉儲的呢?其實這個很簡單,如果一個聚合物體型別只具有一個倉儲型別,那么我們把倉儲設計為單例的就可以了,
-
一個聚合型別(也就是一個聚合根),最好對應一個倉儲(這個不是絕對的);
-
一個倉儲應該是單例的,便于先查到到倉儲,再查找到聚合物體(當然也不是絕對的);
-
倉儲應該是一個集合的抽象概念,并且負責屏蔽中間程序,包括其中的實作細節,如持久化和重建,它最好能讓客戶感覺它似乎就一直在記憶體中一樣;
-
倉儲作為聚合物體的集合,應該具有檢索物體的功能,如果從技術角度看,那么將一直持有聚合物體參考;
2.2 倉儲職責
-
我們的一個用例服務中很可能不需要使用聚合物體本身,而僅使用到符合某種條件的聚合的數量,因此我們沒必要查出聚合物體進行統計;
-
具體的基礎設施資料庫實作,對統計性能有著顯著的性能優化,為了使用這些中間技術的優點,把統計這種細節的操作委托給倉儲是一個很好的選擇,
-
統計和查詢有很多時候的應用場景是不修改聚合根狀態的,所以這種情況你可能沒必要使用倉儲完成這件事,CQRS的思想要求我們去分離查詢,建立查詢模型,所以建立一套查詢模型去做這件事是一個好的解耦實踐,
-
規格是一個謂詞,封裝了業務規則,可以明確表達一個特定物體是否滿足該規格標準;
-
規則是值物件,可以組合使用,其組合實作與SQL的拼湊非常契合,使得其十分適合應用在倉儲;
-
規格的概念引入,使得我們對物體多種檢索的需求程序做到了通用化;
-
好的規格實作,鏈式 API 呼叫,可以使得編程變得靈活,表達能力強流暢;
-
倉儲生成唯一標識別:在利用資料庫能力生成唯一ID的時候(例如TDDL的Sequence),因為倉儲本身封裝資料庫細節,所以倉儲可以單獨提供這種功能,例如 DomainRepository.getInstance().newEntityId() 方法,回傳一個由資料庫管理的唯一ID,
-
倉儲提供工廠方法:聚合物體的創建,不一定是由領域服務完成的,如果我們的聚合物體具有創建模板,那么我們可以假設倉儲本身具有大量的新物件池待使用,所以可以這樣創建物體:DomainRepository.getInstance().newXXEntity() 回傳聚合物體(該方式Evric不推薦);
-
作為Resource,我們通常會給它定一個URI(統一資源識別),用作全網唯一識別,但很少資源庫會定義URI,因為物體唯一標識已經足夠;
-
作為Resource,倉儲一但持有了資源,那么就一直持有并跟蹤資源,直到資源被洗掉;
-
作為Resource,倉儲有時會被當作是對遠程服務行程封裝的機制,這個時候倉儲有點像防腐層,但我不建議這樣做(國內部分書籍有這種介紹);
-
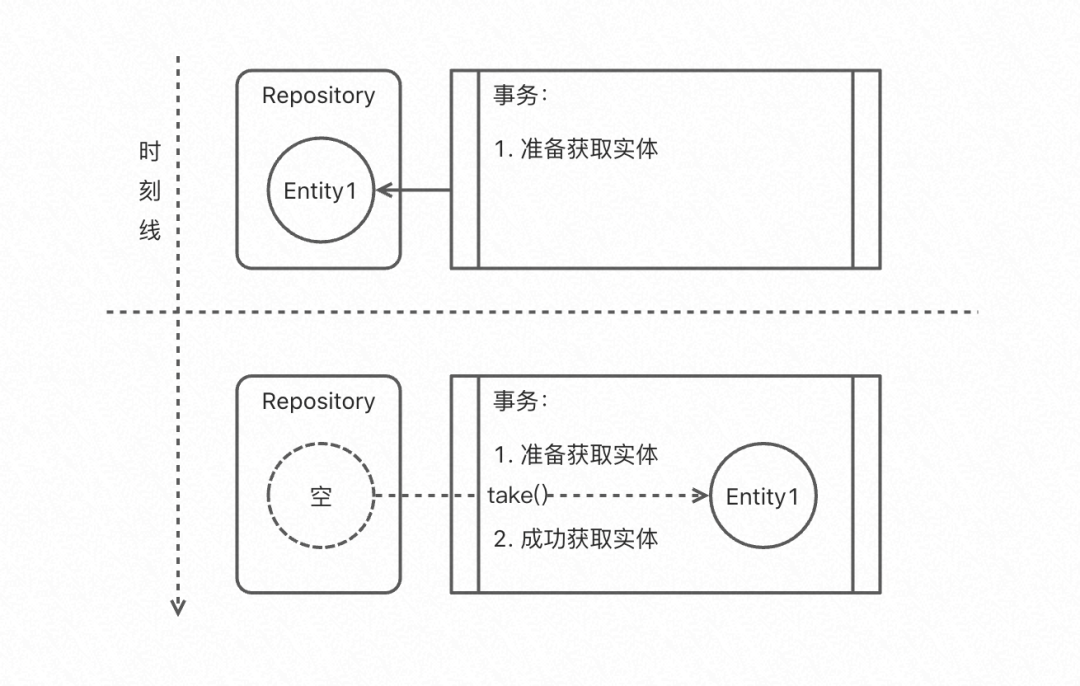
聚合物體一個時刻只能存在于一個用例程序或者一個倉儲實體中;
-
聚合物體無法同時存在在倉儲中和用例程序中;
-
聚合物體也無法同時存在于兩個用例程序中;
-
放置(put或save):把聚合物體從用例程序,放置到倉儲中,狀態變為中間程序,用例程序中不再擁有物體;
-
獲取(Take):用例程序運行中,需要把物體從中間程序,轉移到用例程序,完成這個操作后,倉儲將不再擁有物體,我特別用take而不是find表達了這種思想,
-
面向集合的資源庫:面向集合的倉儲提出的是完全按照集合的理念去設計倉儲,就似乎它就是Set資料結構一樣,所以他能自動去跟蹤聚合物體的變化
-
面向持久化的資源庫:面向持久化的倉儲,核心點是合并了插入和更新這兩種操作,統一用 save() 操作完全取代倉儲舊物體使得倉儲的功能更統一,這種資料存盤(如MongoDB等檔案資料庫)通常稱之為:面向聚合的資料庫(Aggregation-Oriented DataBase)或聚合存盤(Aggregation Store),
3.1 記憶體倉儲
public class CalendarRepository extends HashMap{
private Map<CalendarId,Calendar> calendars;
public CalendarRepository(){
this.calendars = new HashMap<CalendarId,Calendars>();
}
public void add(Calendar aCalendar){
this.calendars.put(aCalendar.getId,aCalendar);
}
public Calendar findCalendars(CalendarId calendarId){
return this.calendars.get(calendarId);
}
}-
倉儲應該是一個集合實體,而且無法對倉儲進行重復的放置;
-
從倉儲獲取的聚合實體,應當和放置倉儲的實體具有完全一樣的狀態,在這里是原物件;
-
如果在倉儲之外對聚合實體進行了修改,無需“重新保存”聚合實體;
-
這種倉儲下的聚合物體,看起來更加像資源Resource;
public class CalendarRepository extends HashMap{
//存聚合物體
private Map<CalendarId,Calendar> calendars;
//標記物體被邏輯移除
private Map<CalendarId,Thread> calendarsTakenAway;
public CalendarRepository(){
this.calendars = new HashMap<CalendarId,Calendars>();
}
public synchronized void add(Calendar aCalendar){
this.calendars.put(aCalendar.getId,aCalendar);
//移除邏輯洗掉
calendarsTakenAway.remove(aCalendar.getId)
}
//注意我們改了命名方法,變為了take,獲取,體現倉儲不再擁有物體
public synchronized Calendar takeCalendars(CalendarId calendarId){
//如果已經被取過,無法再取
if(calendarsTakenAway.containsKey(calendarId)){
return null;
}
Calendar calendar = this.calendars.get(calendarId);
//邏輯洗掉
calendarsTakenAway.put(calendarId,Thread.currentThread());
return calendar;
}
}-
悲觀鎖:在一個調度者(執行緒)使用該聚合物體前,先對聚合物體進行加鎖,其他調度者則無法獲取物體進行操作
-
阻塞悲觀鎖:如果調度者發現聚合物體被鎖了之后,則停止調度直到等待得到物體鎖后繼續;
-
非阻塞悲觀鎖:如果調度者發現聚合物體被鎖了之后,不等待鎖,立即回傳做其他用例;
-
樂觀鎖:一個調度者認為沖突可能性不大,所以可以先獲取聚合物體進行事務操作,但是當它想把聚合持久化的時候,發現有人操作過這個聚合,則回滾自己所有的操作,
3.2 關系型資料庫倉儲
public class BusinessService {
@Resource
private TaskDao taskDao;
@Resource
private SubTaskDao subTaskDao;
@Transactional
public void onFinished(String subTaskId,String taskId){
//查出所有子任務
List<SubTask> subTasks = subTaskDao.getAllSubTask(taskId);
//找出回傳的子任務
SubTask callBackTask = subTasks.stream()
.filter(e->subTaskId.equals(e.getSubTaskId)).findAny();
//更新子任務狀態
callBackTask.setFinished(true);
//如果所有子任務完成,更新主任務狀態
if(allFinished(subTasks)){
taskDao.updateStateById(taskId,TaskStatusEnum.FINISHED);
}
//更新一個欄位
subTaskDao.updateStateById(subTaskId,TaskStatusEnum.FINISHED);
}
}public class BusinessDomainService {
public void onFinished(String subTaskId,String taskId){
//獲取物體的時候記錄快照
Task task = DomainRepository.getInstance().taskOf(taskId);
//聚合物體負責業務邏輯
task.subTaskFinished(subTaskId);
//倉儲自己識別到底哪個欄位變化了,然后更新該欄位(簡稱diff)
DomainRepository.getInstance().put(task);
}
}
public class Task {
private List<SubTask> subTasks;
private TaskStatusEnum status;
public void subTaskFinished(subTaskId){
//找出回傳的子任務
SubTask callBackTask = subTasks.stream()
.filter(e->subTaskId.equals(e.getSubTaskId)).findAny();
//更新子任務狀態
callBackTask.setFinished(true);
//如果所有子任務完成,更新主任務狀態
if(allFinished(subTasks)){
status = TaskStatusEnum.FINISHED;
}
}
}-
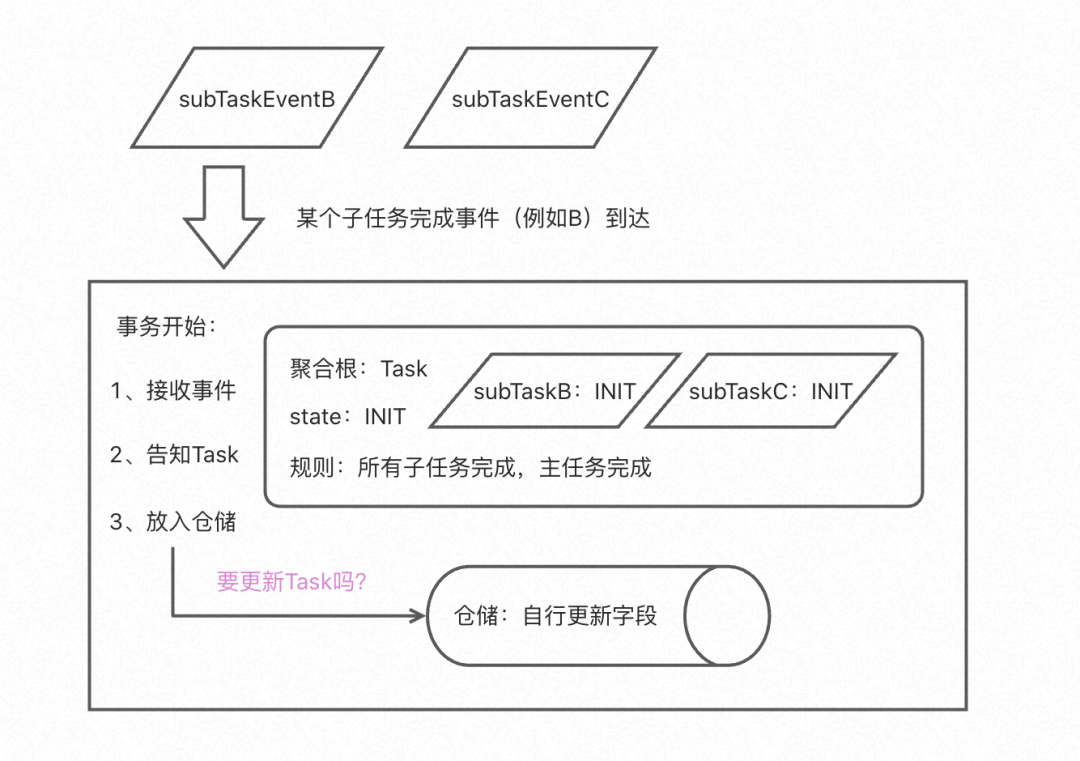
聚合內部一致性:聚合根的存在,最主要是的封裝和管理聚合內部各種物體的關聯和耦合,包括代碼耦合和資料耦合,所以上面的task本身持有所有subTask的參考,而且負責subTask和task的state狀態業務規則一致,此時,這個事務處理程序,就無法感知Task封裝的一致性邏輯是否由subTask引起了Task物體自身的狀態變化成為FINISHED,所以diff的實作就很有必要,
-
領域服務的純粹性:如上圖所示,因為設定Task的狀態規則是由聚合根負責,所以領域服務是不感知的,必須要靠diff,但是如果把diff這個邏輯寫在領域服務中,不如把邏輯寫在倉儲中,因為我們也不應該讓領域服務去關注一些技術上的邏輯,增加領域服務邏輯的復雜性,其實這樣做,剛好就是倉儲本身的職責,封裝diff后的倉儲讓領域服務感覺到聚合物體一直在記憶體中一樣,
-
聚合根的重建工序:在DAO中,我們可以直接方便從ORM框架中回傳資料物件,但是聚合根卻不能,因為聚合根是由多個DO組成的,我們的持久化中間件(不管是MySQL關系型還是MongoDB檔案型)無法給我們回傳一個聚合根物體,所以倉儲還得老老實實的把ORM中獲取到的DO組裝為Entity和Value Object,且要保證查找到的物體是要和原來的物體一摸一樣的,這意味著需要“重建”物體的操作;
-
拆建規則(Convertor):倉儲應當知道怎么拆,就應該怎么復原,所以它應該有一套拆解和重建規則,并根據此規則進行復原,Convertor是維護這種規則的一種工具,我建議采用這種命名類封裝拆建規則
-
事件溯源(Event Sourcing):還有一種重建工廠的實作是利用物體的快照+物體的領域事件集合回放來恢復聚合物體,有興趣的同學可以了解一下事件溯源;
-
聚合根與關聯單例:關聯單例是一種特殊的重建工序,我用一個領域事件監聽器來說明,例如我們的聚合根物體實作了觀察者模式,聚合根為主題,內部持有一些單例監聽器物件串列,其中一個監聽器用作監聽聚合根的狀態變化發送領域事件,那么這個監聽器也應該讓倉儲負責拆解和恢復,
-
實作復雜:因為聚合的復雜性所以我們其實作起來也非常困難,其中最好模型能配合實作這種復雜性,
-
犯錯成本:正如DAO的某個介面只對一個屬性更新,那么無論代碼有何種bug,最多只會寫錯一個欄位,但倉儲全量化更新后,我們在未知情況下手一抖,那么將可能覆寫其他本應安全欄位,所以這也提高了我們的犯錯成本,斷言是解決的一種較好方案
關系型倉儲實作方案:倉儲必須要讓客戶感覺它似乎就一直在記憶體中一樣;但上面提到的 Diff 邏輯讓倉儲的使用和實作變得困難,設計者需要在整個背景關系角度了解倉儲的原理細節,因為要追求性能和安全的實作,還要只針對已經變化的欄位更新,忽略無變化欄位,其中Vaughn Vernon在《實作領域驅動設計》里面提到了兩個方法,來解決這個問題:
-
隱式讀時復制:在查找聚合物體的時候,記錄下聚合物體的所有狀態,然后在更新的時候,用新狀態diff舊的狀態,只對特定欄位進行更新;
-
隱式寫時復制:在查找到集合物體的時候,倉儲把聚合物體的更新操作隱式委派給倉儲的某種機制進行,所以每次更新狀態物體狀態倉儲都能跟蹤到,并在這個時候對該值標記為臟資料,最后倉儲在事務結束的時候把臟資料給刷盤,
public interface TaskRepository{
//相當于findTask,獲取到的Task會被隱式追蹤復制
public Task taskOf(String taskId);
public void addTask(Task task);
public void removeTask(String taskId);
//其他/統計/集合操作等
//......
}-
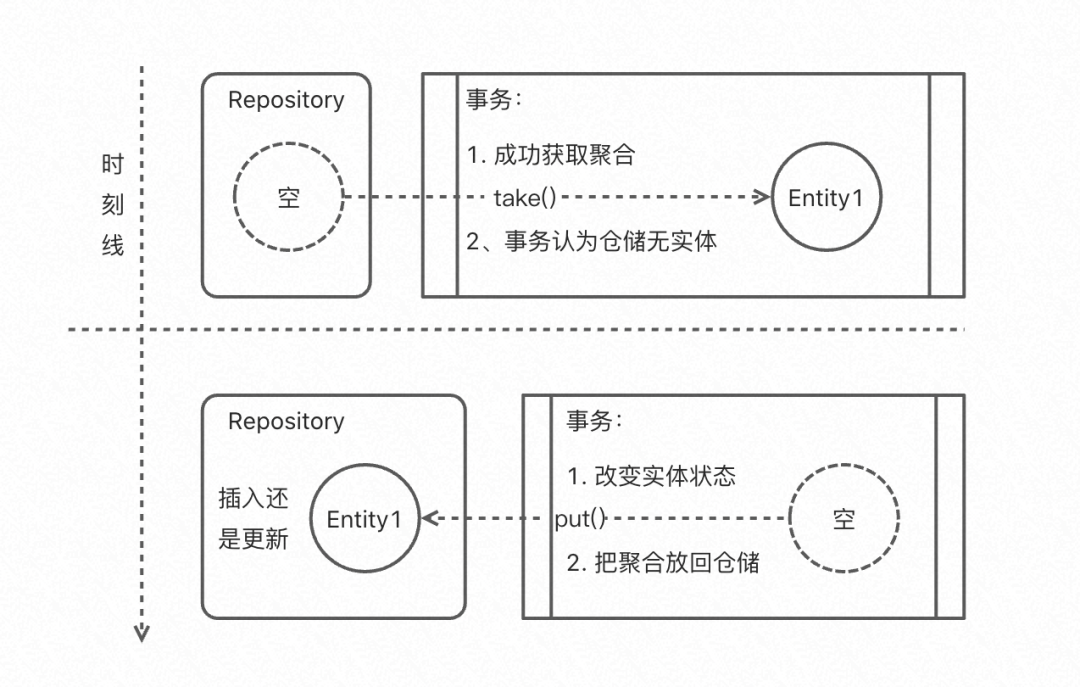
領域服務視覺:在獲取(take)到聚合物體后,領域服務可以認為倉儲中的聚合物體是不存在的(即使倉儲沒有洗掉聚合物體);
-
合并插入和更新(全覆寫):倉儲沒有所謂的更新操作,只有直接放置聚合物體到倉儲中,可以讓倉儲判斷該插入還是全量更新(其實和用隱式跟蹤實作部分更新差別不大,隱式跟蹤更安全但多一個復制操作),或者我們直接一點,完全洗掉物體后再次插入或者全覆寫物體;
-
洗掉:不管是否改進模型,當聚合物體生命周期結束都需要去真正的洗掉物體,這一點確實不好統一;
-
樂觀鎖:我們可以在實作的時候在關系型倉儲中采用樂觀鎖保證一個聚合物體不會存在于不同的領域事務中,因為樂觀鎖只會讓其中一個成功;
-
優點:所以它最大的優點就是無需跟蹤物體,而是以轉移的聚合物體為主;
-
缺點:因為倉儲實作要全量覆寫整個聚合狀態,所以只適合用在類檔案資料庫,對于關系型資料庫則需要復雜的隱式讀/寫跟蹤了;
-
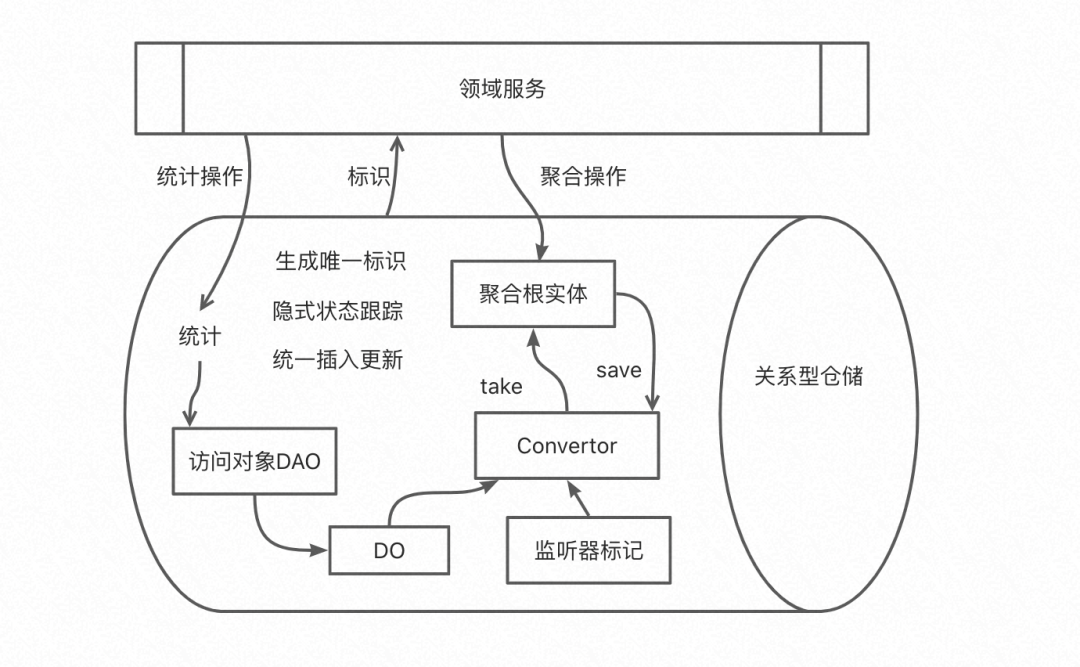
訪問物件DAO:可以封裝一層Mapper,或者其他ORM框架,提供DO以及其他統計資料;
-
Convertor:維護拆解規則和重建規則,同時復制聚合根監聽器的一些組裝;
-
DO:資料物件,一般和關系型資料表一一對應;
-
隱式狀態跟蹤:實作一套隱式讀時復制和隱式寫時復制狀態跟蹤的邏輯;
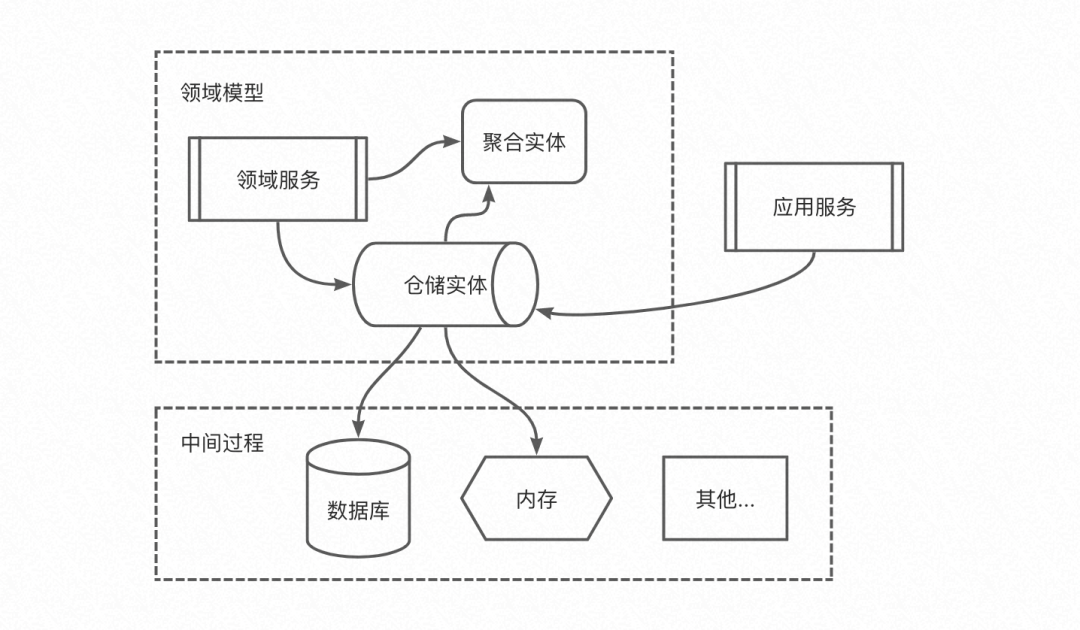
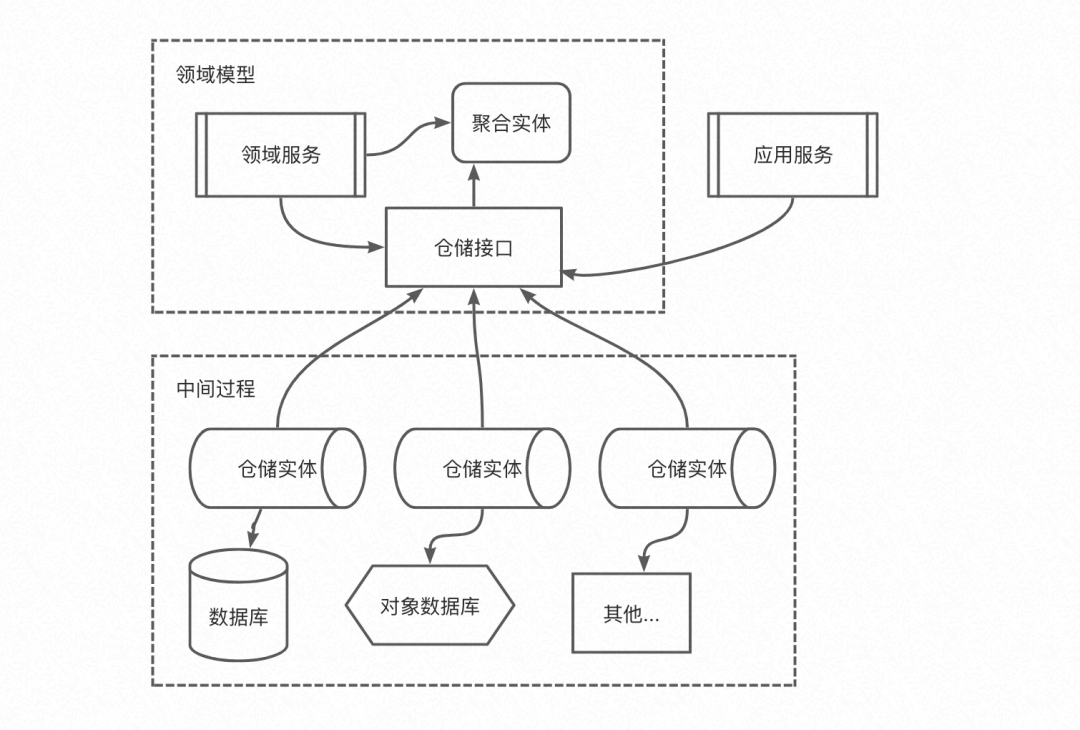
3.3 倉儲的架構
參考書籍:
《領域驅動設計》Eric Evans [著].趙俐[譯]2016.. 人民郵電出版社
本文來自博客園,作者:古道輕風,轉載請注明原文鏈接:https://www.cnblogs.com/88223100/p/DDD_in-depth-design-and-implementation-of-repository-from-a-domain-perspective.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/542969.html
標籤:領域驅動設計
下一篇:函式式編程思維讀后總結與感想