
Without music, life would be a mistake. ― Friedrich Nietzsche1. QQ音樂高可用架構體系全景
故障無處不在,而且無法避免,(分布式計算謬誤)
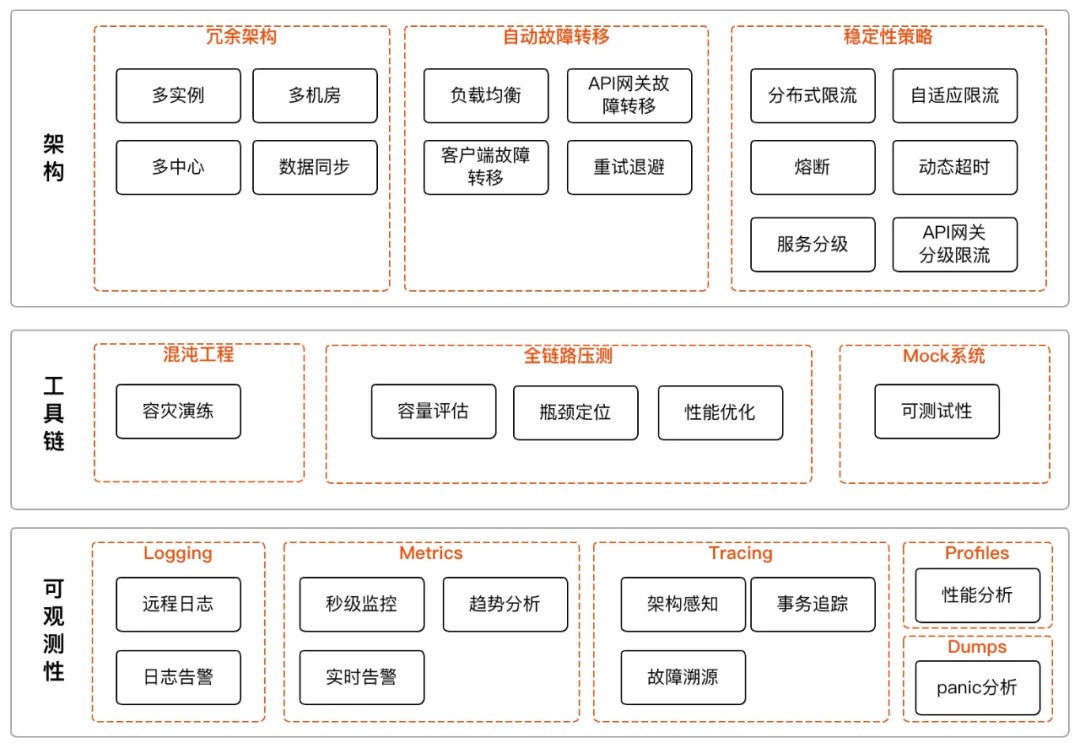
在分布式系統建設的程序中,我們思考的重點不是避免故障,而是擁抱故障,通過構建高可用架構體系來獲得優雅應對故障的能力,QQ音樂高可用架構體系包含三個子系統:架構、工具鏈和可觀測性,
-
架構:架構包括冗余架構、自動故障轉移和穩定性策略,高可用架構的基礎是通過冗余架構來避免單點故障,其中,基礎設施的冗余包括集群部署、多機房部署,多中心部署等;軟體架構上要支持橫向擴展、負載均衡和自動故障轉移,這樣系統就具備了基礎的容災容錯能力,在冗余架構的基礎之上,可以通過一系列穩定性策略來進一步提升架構的可用性,穩定性策略包括分布式限流,熔斷,動態超時等, -
工具鏈:工具鏈指一套可互相集成和協作的工具,從外圍對架構進行實驗和測驗以達到提升架構可用性的目的,包括混沌工程和全鏈路壓測等,混沌工程通過注入故障的方式,來發現系統的脆榷訓節并針對性地加固,幫助我們提升系統的可用性,全鏈路壓測通過真實、高效的壓測,來幫助業務完成性能測驗任務,進行容量評估和瓶頸定位,保障系統穩定, -
可觀測性:通過觀測系統的詳細運行狀態來提升系統的可用性,包括日志、指標、全鏈路跟蹤、性能分析和panic分析,可觀測性可以用于服務生命周期的所有階段,包括服務開發,測驗,發布,線上運行,混沌工程,全鏈路壓測等各種場景,
2. 容災架構:
業內主流的容災方案,包括異地冷備,同城雙活,兩地三中心,異地雙活/多活等,
-
異地冷備:冷備中心不作業,成本浪費,關鍵時刻不敢切換, -
同城雙活:同城仍然存在很多故障因素(如自然災害)導致整體不可用, -
異地雙活/多活:雙寫/多寫對資料一致性是個極大挑戰,有些做法是按用戶ID哈希,使用戶跟資料中心系結,避免寫沖突問題,但這樣一來舍棄了就近接入的原則,而且災難發生時要手動調度流量,也無法做到API粒度的容災,
容災架構的選型我們需要衡量投入產出比,不要為了預防哪些極低概率的風險事件而去投入過大的成本,畢竟業務的規模和收入才是重中之重,QQ音樂的核心體驗是聽歌以及圍繞聽歌的一系列行為,這部分業務以只讀服務為主,而寫容災需要支持雙寫,帶來的資料一致性風險較大,且有一定的實施成本,綜合權衡,我們舍棄寫容災,采用一寫雙讀的異地雙活模式,
2.1. 異地雙中心
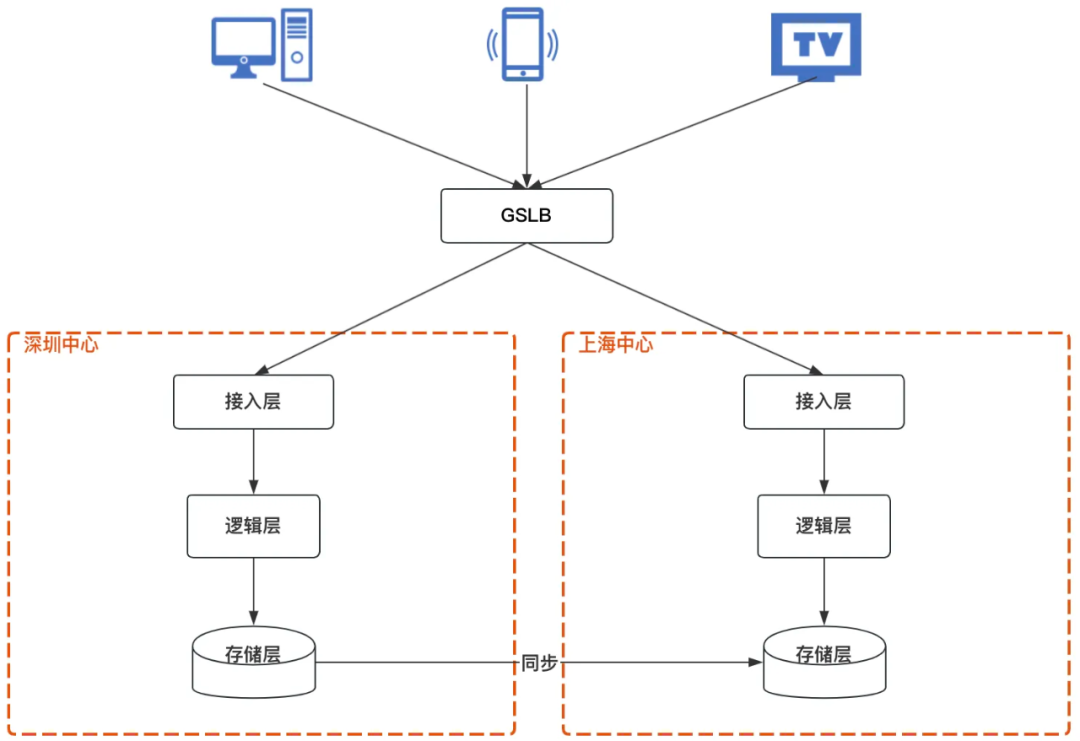
在原有深圳中心的基礎上,建設上海中心,覆寫接入層、邏輯層和存盤層,形成異地雙中心,
-
接入層:深圳中心和上海中心各部署一套STGW和API網關,通過GSLB把流量按就近原則劃分為兩份,分配給深圳中心和上海中心,深圳中心和上海中心做流量隔離, -
邏輯層:服務做讀寫分離,深圳部署讀/寫服務,上海部署只讀服務,上海的寫請求由API網關路由到深圳中心處理, -
存盤層:深圳中心和上海中心各有一套存盤,寫服務從深圳寫入存盤,通過同步中心/存盤組件同步到上海,同步中心/存盤組件確保兩地資料的一致性,同步方式有兩種,對于有建設異地同步能力的組件Cmongo和CKV+,依賴存盤組件的異地同步能力,其他不具備異地同步能力的,如ckv,tssd等老存盤,使用同步中心進行同步,
2.2. 自動故障轉移
異地容災支持自動故障轉移才有意義,如果災難發生后,我們在災難發現、災難回應以及評估遷移風險上面浪費大量時間,災難可能已經恢復,
我們最初的方案是,客戶端對兩地接入IP進行動態評分(請求成功加分,請求失敗減分),取最優的IP接入來達到容災的效果,經過近兩年多的外網實踐,遇到一些問題,動態評分演算法敏感度高會導致流量在兩地頻繁漂移,演算法敏感度低起不了容災效果,而演算法調優依賴客戶端版本更新也導致成本很高,
后來我們基于異地自適應重試對容災方案做了優化,核心思想是在API網關上做故障轉移,降低客戶端參與度,
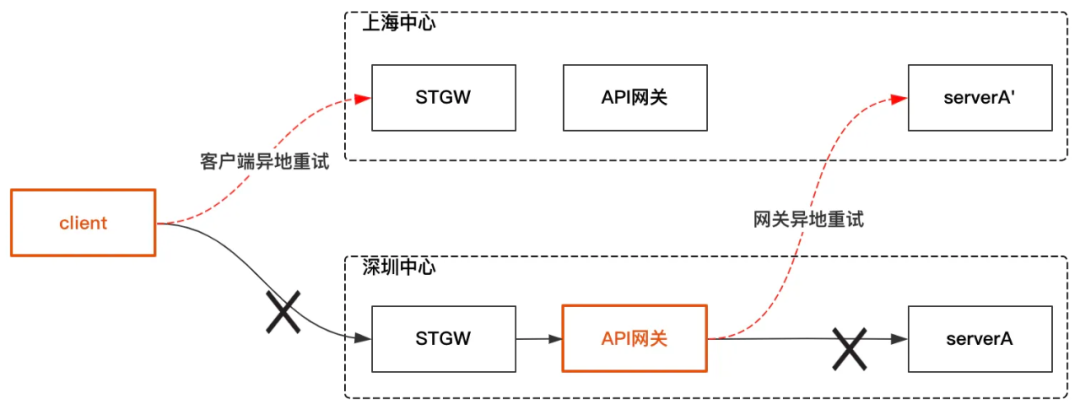
方案主要有兩點:
-
API網關故障轉移:當本地中心API回傳失敗時(包括觸發熔斷和限流),API網關把請求路由到異地處理,以此解決API故障的場景, -
客戶端故障轉移:當API網關發生超時的時候,客戶單進行異地重試,如果網關有回包,即使API回傳失敗,客戶端也不重試,解決API網關故障的場景,
使用最新方案后,API網關重試比客戶端調度更可控,雙中心流量相對穩定,一系列自適應限流和熔斷策略也抵消重試帶來的請求量放大問題,接下來介紹方案細節,
2.3. API網關故障轉移
API網關故障轉移需要考慮重試流量不能壓垮異地,否則會造成雙中心同時雪崩,這里我們做了一個自適應重試的方案,在異地成功率下降的時候,取消重試,
自適應重試方案:
-
引入重試視窗:如果當前周期視窗為10,則最多只能重試10次,超過的部分丟棄, -
網關請求服務失敗,判斷重試視窗是否耗光,如果耗光則不重試,如果還有余額,重試異地,
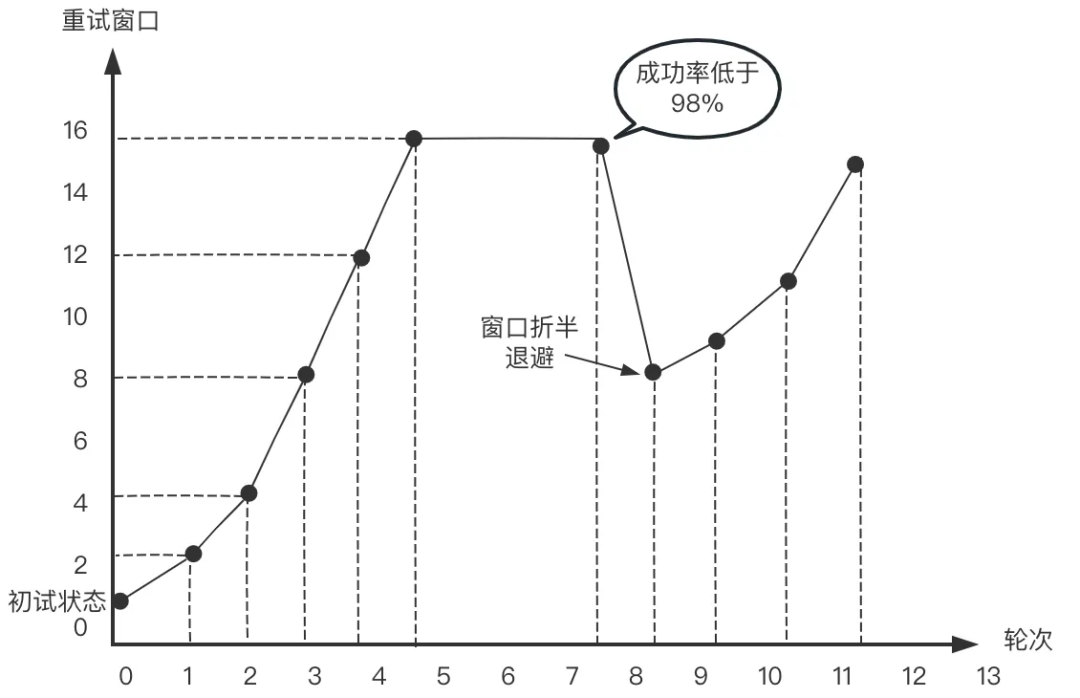
上述方案中的重試視窗,由探測及退避策略決定:
-
探測策略:當探測成功率正常時,增大下一次視窗并繼續探測,通過控制視窗大小,避免重試流量瞬間把異地打垮, -
退避策略:在探測成功率出現例外時,重試視窗快速退避, -
增加重試開關,控制整體及服務兩個維度的重試,
探測策略及退避策略圖示:
探測策略及退避策略的演算法描述:
// 設第 i 次探測的視窗為 f(i),實際探測量為 g(i),第 i 次探測的成功率為 s(i),第 i 次本地總請求數為 t,
// 那么第 i+1 次探測的視窗為 f(i+1),取值如下:
if s(i) = [98%, 100%] // 第 i 次探測成功率 >= 98%,探測正常
if g(i) >= f(i) // 如果第 i 次實際探測量等于當前視窗,增大第 i+1 次視窗大小
f(i+1) = f(i) + max (min ( 1% * t, f(i) ) , 1)
else
f(i+1) = f(i) // 如果第 i 次實際探測量小于當前視窗,第 i+1 次探測視窗維持不變
else
f(i+1) = max(1,f(i)/2) // 如果第 i 次探測例外,第 i+1 次視窗退避置 1
// 其中,重試視窗即 f(i) 初始大小為 1,演算法中引數及細節,根據實際測驗和線上效果進行調整,自適應重試效果:
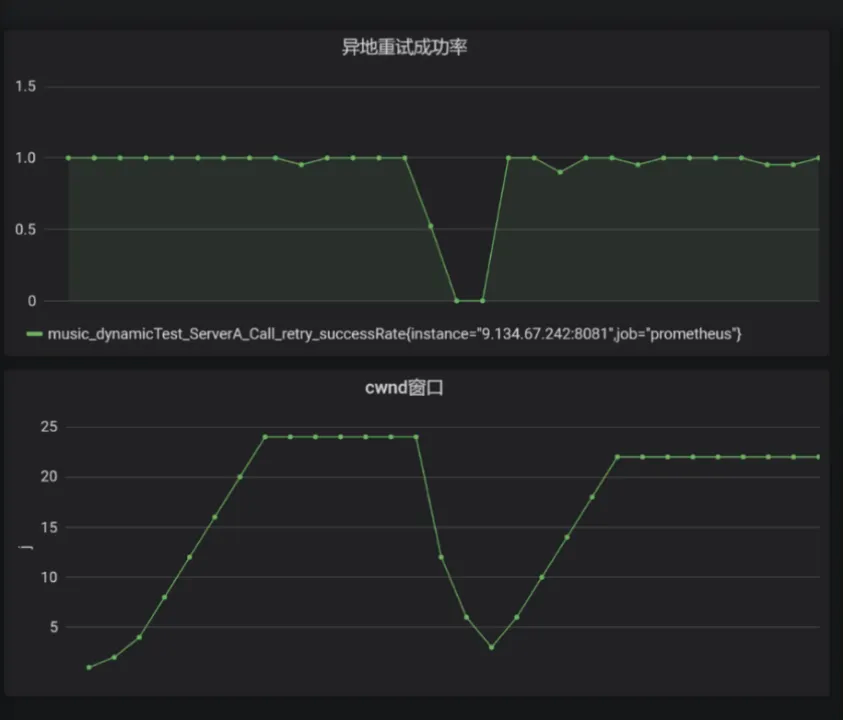
2.4. 客戶端故障轉移
-
當客戶端未收到回應時,說明API網關例外或者網路不通,客戶端重試異地, -
當客戶端收到回應,而http狀態碼為5xx,說明API網關例外,客戶端重試異地,當http狀態碼正常,說明API網關正常,此時即使API失敗也不重試, -
當雙中心均超時,探測網路是否正常,如果網路正常,說明兩地API網關均例外,所有客戶端請求凍結一段時間,
3. 穩定性策略:
3.1. 分布式限流
即使我們在容量規劃上投入大量精力,根據經驗充分考慮各種請求來源,評估出合理的請求峰值,并在生產環境中準備好足夠的設備,但預期外的突發流量總會出現,對我們規劃的容量造成巨大沖擊,極端情況下甚至會導致雪崩,我們對容量規劃的結果需要堅守不信任原則,做好防御式架構,
限流可以幫助我們應對突發流量,我們有幾個選擇:
-
固定視窗計算器優點是簡單,但存在臨界場景無法限流的情況, -
漏桶是通過排隊來控制消費者的速率,適合瞬時突發流量的場景,面對恒定流量上漲的場景,排隊中的請求容易超時餓死, -
令牌桶允許一定的突發流量通過,如果下游(callee)處理不了會有風險, -
滑動視窗計數器可以相對準確地完成限流,
我們采用的是滑動視窗計數器,主要考慮以下幾點:
-
超過限制后微服務框架直接丟棄請求, -
對原有架構不引入關鍵依賴,用分布式限流的方式代替全域限流,
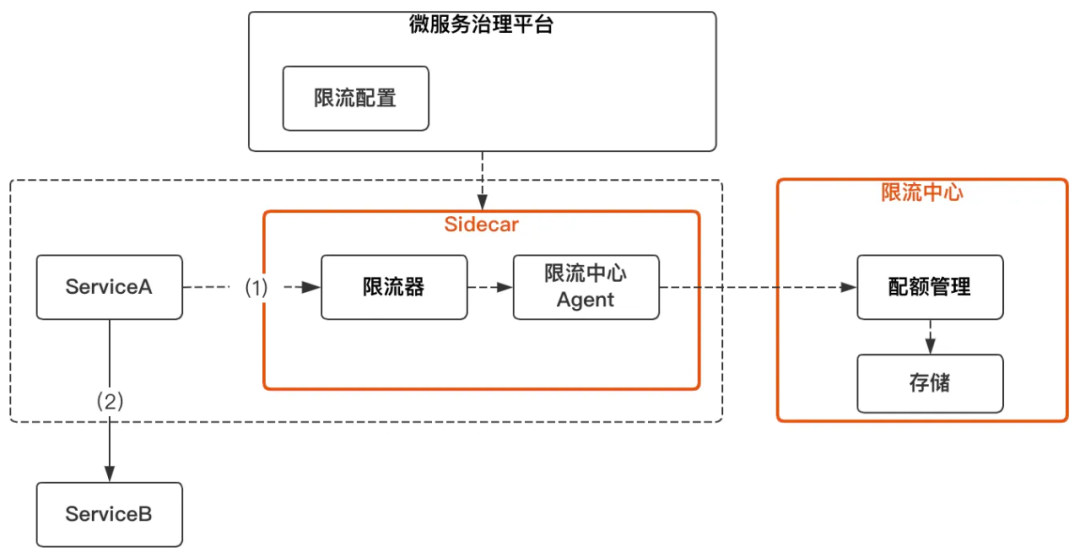
上圖描述ServceA到ServiceB之間的RPC呼叫程序中的限流:
-
Sidecar用于接管微服務的信令控制,限流器則以插件的方式集成到Sidecar,限流器通過限流中心Agent,從限流中心獲取限流結果資料, -
ServiceA發起請求到ServiceB前,通過Sidecar的限流器判斷是否超出限制,如果超出,則進入降級邏輯, -
限流中心采用滑動視窗的方式,計算每個Service的限流資料,
限流演算法的選擇,還有一種可行的方案是,框架提供不同的限流組件,業務方根據業務場景來選擇,但也要考慮成本,社區也有Sentinel等成熟解決方案,新業務可以考慮集成現成的方案,
3.2. 自適應限流
上一節的分布式限流是在Client-side限制流量,即請求量超出閾值后在主調直接丟棄請求,被調不需要承擔拒絕請求的資源開銷,可最大程度保護被調,然而,Client-side限制流量強依賴主調接入分布式限流,這一點比較難完全受控,同時,分布式限流在集群擴縮容后需要及時更新限流閾值,而全量微服務接入有一定的維護成本,而且分布式限流直接丟棄請求更偏剛性,作為分布式限流的互補能力,自適應限流是在Server-side對入口流量進行控制,自動嗅探負載、入口QPS、請求耗時等指標,讓系統的入口QPS和負載達到一個平衡,確保系統以高水位QPS正常運行,而且不需要人工維護限流閾值,相比分布式限流,自適應限流更偏柔性,
指標說明:
| 指標名稱 | 指標含義 |
|---|---|
| CPU usage | 當系統CPU使用率超過閾值啟動自適應限流 |
| inflight | 系統中正在處理的請求數量 |
| qps | 視窗內每個桶的請求處理成功的量 |
| MaxQPS | 滑動視窗中QPS的最大值 |
| rt | 視窗內每個桶的請求成功的回應耗時 |
| MinRt | 滑動視窗中回應延時的最小值 |
演算法原理:
根據Little's Law,inflight = 延時 QPS,則最優inflight為MaxPass MinRt,當系統當前inflight超過最優inflight,執行限流動作,
用公式表示為:cpu > 800 AND InFlight > (MaxQPS * MinRt)
其中MaxQPS和MinRt的估算需要增加平滑策略,避免秒殺場景下最優inflight的估算失真,
限流效果:
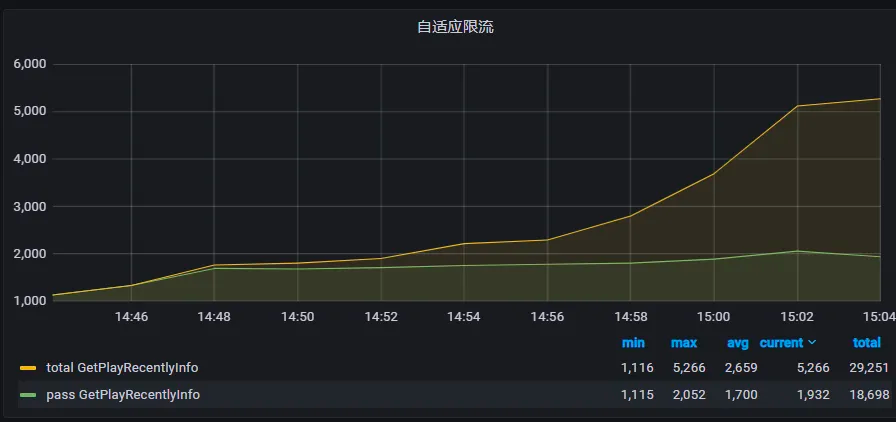
3.3. 熔斷
在微服務系統中,服務會依賴于多個服務,并且有一些服務也依賴于它,如下圖,“統一權限”服務,依賴歌曲權限配置、購買資訊、會員身份等服務,綜合判斷用戶是否擁有對某首歌曲進行播放/下載等操作的權限,而這些權限資訊,又會被歌單、專輯等歌曲串列服務依賴,
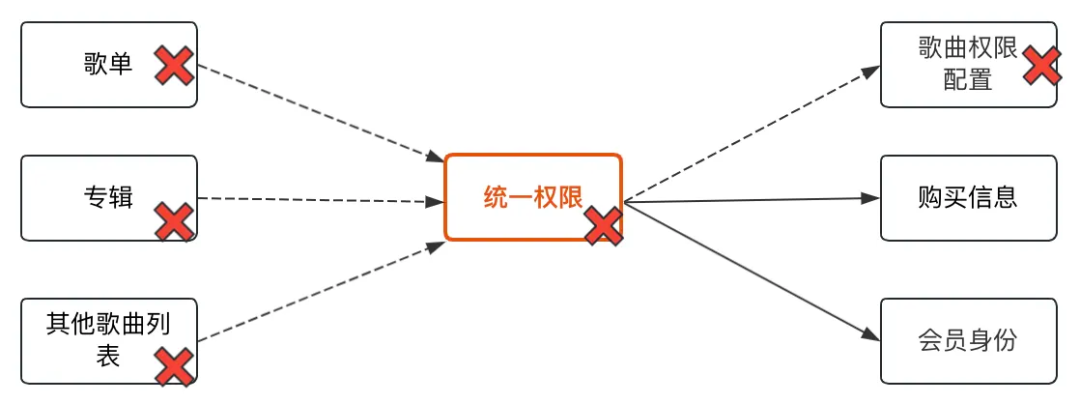
當“統一權限”服務的其中一個依賴服務(比如歌曲權限配置服務)出現故障,“統一權限”服務只能被動的等待依賴服務報錯或者請求超時,下游連接池會逐漸被耗光,入口請求大量堆積,CPU、記憶體等資源逐漸耗盡,導致服務宕掉,而依賴“統一權限”服務的上游服務,也會因為相同的原因出現故障,一系列的級聯故障最侄訓導致整個系統宕掉,
合理的解決方案是斷路器和優雅降級,通過盡早失敗來避免區域不穩定而導致的整體雪崩,
傳統熔斷器實作Closed、Half Open、Open三個狀態,當進入Open狀態時會拒絕所有請求,而進入Closed狀態時瞬間會有大量請求,服務端可能還沒有完全恢復,會導致熔斷器又切換到Open狀態,一種比較剛性的熔斷策略,SRE熔斷只有打Closed和Half-Open兩種狀態,根據請求成功率自適應地丟棄請求,盡可能多地讓請求成功請求到服務端,是一種更彈性的熔斷策略,QQ音樂采用更彈性的SRE熔斷器:
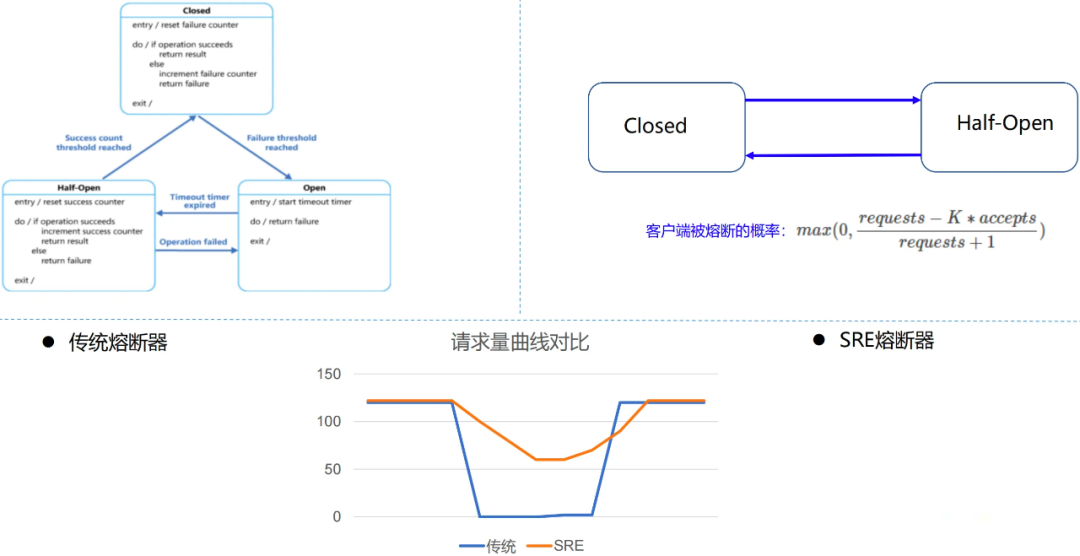
-
requests:視窗時間內的請求總數, -
accepts:正常處理的請求數量, -
K:敏感度,K越小丟棄概率越大,一般在1.5~2之間,
正常情況下,requests 等于 accepts,所以丟棄概率為0,隨著正常處理的請求減少,直到 requests 等于 K * accepts ,一旦超過這個限制,熔斷器就會打開,并按照概率丟棄請求,
3.4. 動態超時
超時是一件很容易被忽視的事情,在早期架構發展階段,相信大家都有因為遺漏設定超時或者超時設定太長導致系統被拖慢甚至掛起的經歷,隨著微服務架構的演進,超時逐漸被標準化到RPC中,并可通過微服務治理平臺快捷調整超時引數,但仍有不足,傳統超時會設定一個固定的閾值,回應時間超過閾值就回傳失敗,在網路短暫抖動的情況下,回應時間增加很容易產生大規模的成功率波動,另一方面,服務的回應時間并不是恒定的,在某些長尾條件下可能需要更多的計算時間,為了有足夠的時間等待這種長尾請求回應,我們需要把超時設定足夠長,但超時設定太長又會增加風險,超時的準確設定經常困擾我們,
其實我們的微服務系統對這種短暫的延時上漲具備足夠的容忍能力,可以考慮基于EMA演算法動態調整超時時長,EMA演算法引入“平均超時”的概念,用平均回應時間代替固定超時時間,只要平均回應時間沒有超時即可,而不是要求每次都不能超時,主要演算法:總體情況不能超標;平均情況表現越好,彈性越大;平均情況表現越差,彈性越小,
如下圖,當平均回應時間(EMA)大于超時時間限制(Thwm),說明平均情況表現很差,動態超時時長(Tdto)就會趨近至超時時間限制(Thwm),降低彈性,當平均回應時間(EMA)小于超時時間限制(Thwm),說明平均情況表現很好,動態超時時長(Tdto)就可以超出超時時間限制(Thwm),但會低于最大彈性時間(Tmax),具備一定的彈性,
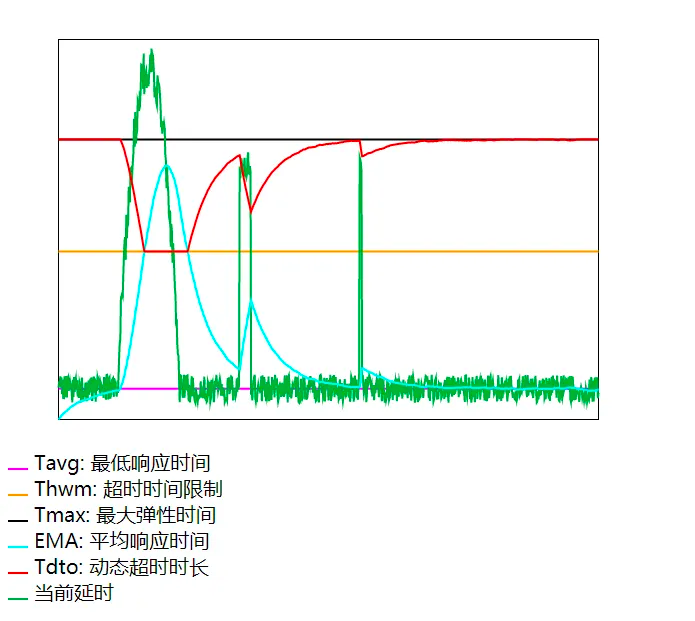
為降低使用門檻,QQ音樂微服務只提供超時時間限制(Thwm)和最大彈性時間(Tmax)兩個引數的設定,并可在微服務治理平臺調整引數,演算法實作參考:https://github.com/jiamao/ema-timeout
3.5. 服務分級
我們做了很多彈性能力,比如限流,我們是否可以根據服務的重要程度來決策丟棄請求,此外,在架構迭代的程序中,有許多涉及整體系統的大工程,如微服務改造,容器化,限流熔斷能力落地等專案,我們需要根據服務的重要程度來決策哪些服務先行,
如何為服務確定級別:
-
1級:系統中最關鍵的服務,如果出現故障會導致用戶或業務產生重大損失,比如登錄服務、流媒體服務、權限服務、數專服務等, -
2級:對于業務非常重要,如果出現故障會導致用戶體驗受到影響,但是不會完全無法使用我們的系統,比如排行榜服務、評論服務等, -
3級:會對用戶造成較小的影響,不容易注意或很難發現,比如用戶頭像服務,彈窗服務等, -
4級:即使失敗,也不會對用戶體驗造成影響,比如紅點服務等,
服務分級的應用場景:
-
核心介面運營質量日報:每日郵件推送1級服務和2級服務的觀測資料, -
SLA:針對1級服務和2級服務,制定SLO, -
API網關根據服務分級限流,優先確保1級服務通過, -
重大專案參考服務重要程度制定優先級計劃,如容災演練,大型活動壓測等,
3.6. API網關分級限流
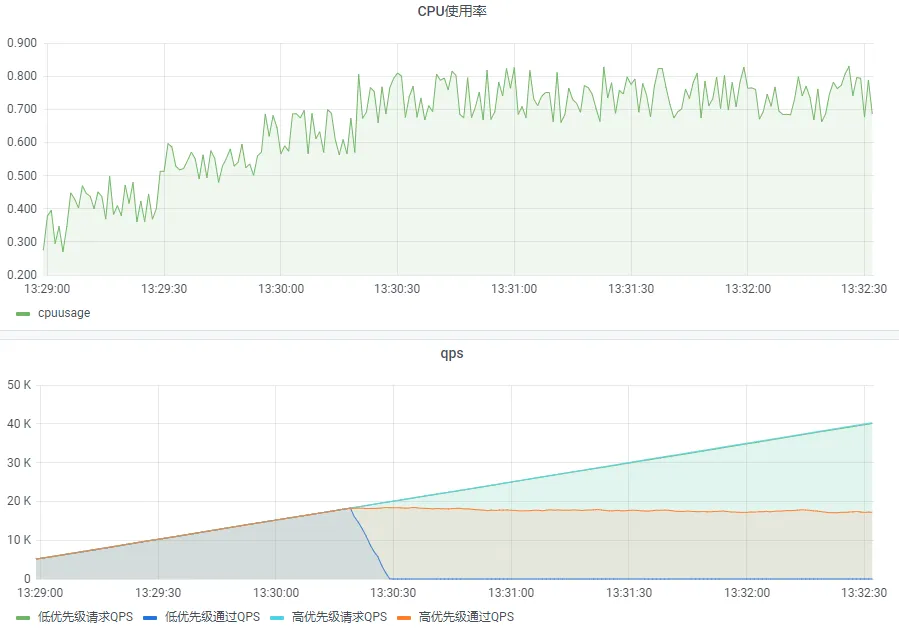
API網關既是用戶訪問的流量入口,也是后臺業務回應的最終出口,其可用性是QQ音樂架構體系的重中之重,除了支持自適應限流能力,針對服務重要程度,當觸發限流時優先丟棄不重要的服務,
效果如下圖,網關高負載時,2級、3級、4級服務丟棄,只有1級服務通過,
4. 工具鏈:
隨著產品的迭代,系統不斷在變更,性能、延時、業務邏輯、用戶量等因素的變化都有可能引入新的風險,而現有的架構彈性能力可能不足以優雅地應對新的風險,事實上,即使架構考慮的場景再多,外網仍然存在很多未知的風險,在某些特殊條件滿足后就會引發故障,一般情況下,我們只能等著告警出現,當告警出現后,復盤總結,討論規避方案,進行下一輪的架構優化,應對故障的方式比較被動,
那么,我們有沒有辦法變被動為主動?在故障觸發之前,盡可能多地識別風險,針對性地加固和防范,而不是等著故障發生,業界有比較成熟的理論和工具,混沌工程和全鏈路壓測,
4.1. 混沌工程
混沌工程通過在生產環境上進行實驗,注入網路超時等故障,主動找出系統中的脆榷訓節,不斷提升系統的彈性,
TMEChaos 以ChaosMesh為底層故障注入引擎,結合TME微服務架構、mTKE容器平臺打造成云原生混沌工程實驗平臺,支持豐富的故障模擬型別,具有強大的故障場景編排能力,方便研發同學在開發測驗中以及生產環境中模擬現實世界中可能出現的各類例外,幫助驗證架構設計是否合理,系統容錯能力是否符合預期,為組織提供常態化應急回應演練,幫助業務推進高可用建設,
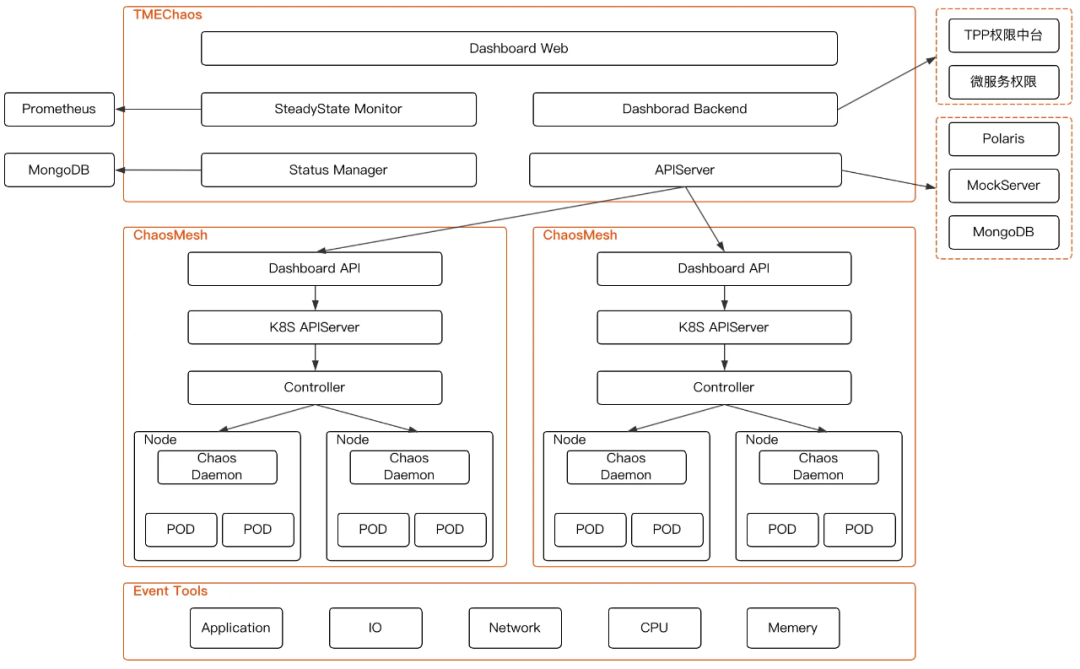
-
TMEChaos Dashboard Web:TMEChaos的可視化組件,提供了一套用戶友好的 Web 界面,用戶可通過該界面對混沌實驗進行操作和觀測, -
TMEChaos Dashboard Backend:NodeJS實作的Dashboard中間層,為Web提供Rest API介面,并進行TMEOA權限/微服務權限驗證, -
TMEChaos APIServer:TMEChaos的邏輯組件,主要負責服務維度的爆炸半徑設定,ChaosMesh多集群管理、實驗狀態管理、Mock行為注入, -
Status Manager:負責查詢各ChaosMesh集群中的實驗狀態同步到TMEChaos的存盤組件, -
SteadyState Monitor:穩態指標組件,負責監控混沌實驗運行程序中IAAS層/服務相關指標,如果超出閾值自動終止相關實驗, -
ChaosMesh Dashboard API:ChaosMesh 對外暴露的Rest API介面層,用于實驗的增刪改查,直接跟K8S APIServer互動, -
Chaos Controller Manager:ChaosMesh 的核心邏輯組件,主要負責混沌實驗的調度與管理,該組件包含多個 CRD Controller,例如 Workflow Controller、Scheduler Controller 以及各類故障型別的 Controller, -
Chaos Daemon:ChaosMesh 的主要執行組件,以 DaemonSet 的方式運行,該組件主要通過侵入目標 Pod Namespace 的方式干擾具體的網路設備、檔案系統、內核等,
4.2. 全鏈路壓測
上一節的混沌工程是通過注入故障的方式,來發現系統的脆榷訓節,而全鏈路壓測,則是通過注入流量給系統施加壓力的方式,來發現系統的性能瓶頸,并幫助我們進行容量規劃,以應對生產環境各種流量沖擊,
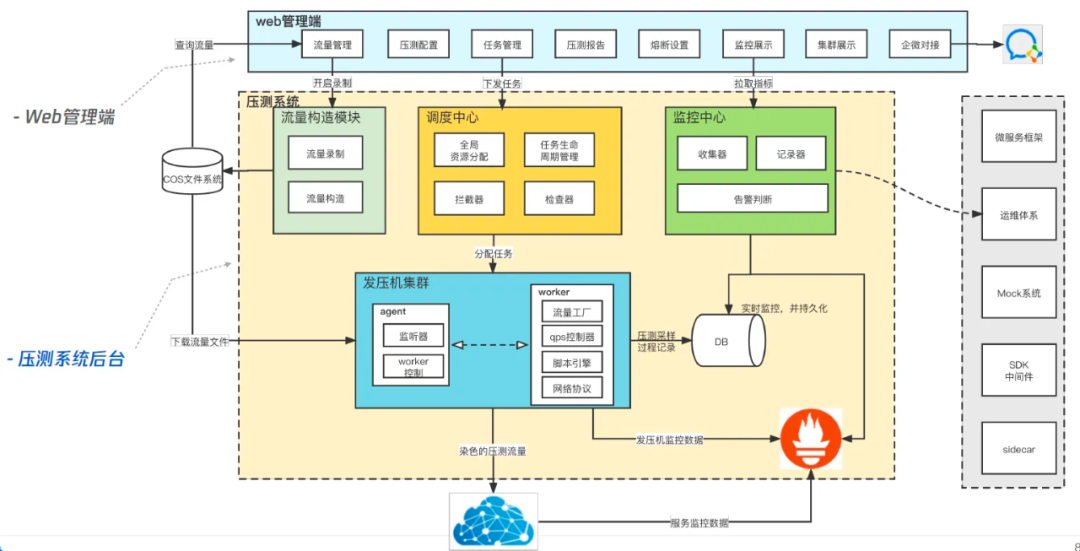
全鏈路壓測的核心模塊有4個:流量構造、流量染色、壓測引擎和智能監控,
-
流量構造:為了保證真實性,從正式環境API網關抽樣采集真實流水,同時也提供自定義流量構造, -
流量染色:全鏈路壓測在生產環境進行,生產環境需要具備資料與流量隔離能力,不能影響到原有的用戶資料、BI報表以及推薦演算法等等,要實作這個目標,首先要求壓測流量能被識別,我們采用的做法是在RPC的context里面增加染色標記,所有的壓測流量都帶有這個染色標記,并且這些標記能夠隨RPC呼叫關系進行傳遞,然后,業務系統根據標記識別壓測流量,在存盤時,將壓測資料存盤到影子存盤而不是覆寫原有資料, -
壓測引擎:對接各類協議,管理發壓資源,以可調節的速率發送請求, -
智能監控:依靠可觀測能力,收集鏈路資料并展示,根據熔斷規則智能熔斷,
5. 可觀測性:
隨著微服務架構和基礎設施變得越來越復雜,傳統監控已經無法完整掌握系統的健康狀況,此外,服務等級目標要求較小的故障恢復時間,所以我們需要具備快速發現和定位故障的能力,可觀測性可以幫助我們解決這些問題,
指標、日志和鏈路追蹤構成可觀測的三大基石,為我們提供架構感知、瓶頸定位、故障溯源等能力,借助可觀測性,我們可以對系統有更全面和精細的洞察,發現更深層次的系統問題,從而提升可用性,
在實踐方面,目前業界已經有很多成熟的技術堆疊,包括Prometheus,Grafana,ELK,Jaeger等,基于這些技術堆疊,我們可以快速搭建起可觀測系統,
5.1. Metrics
指標監控能夠從宏觀上對系統的狀態進行度量,借助QPS、成功率、延時、系統資源、業務指標等多維度監控來反映系統整體的健康狀況和性能,
我們基于Prometheus構建聯邦集群,實作千萬指標的采集和存盤,提供秒級監控,搭配Grafana做可視化展示,
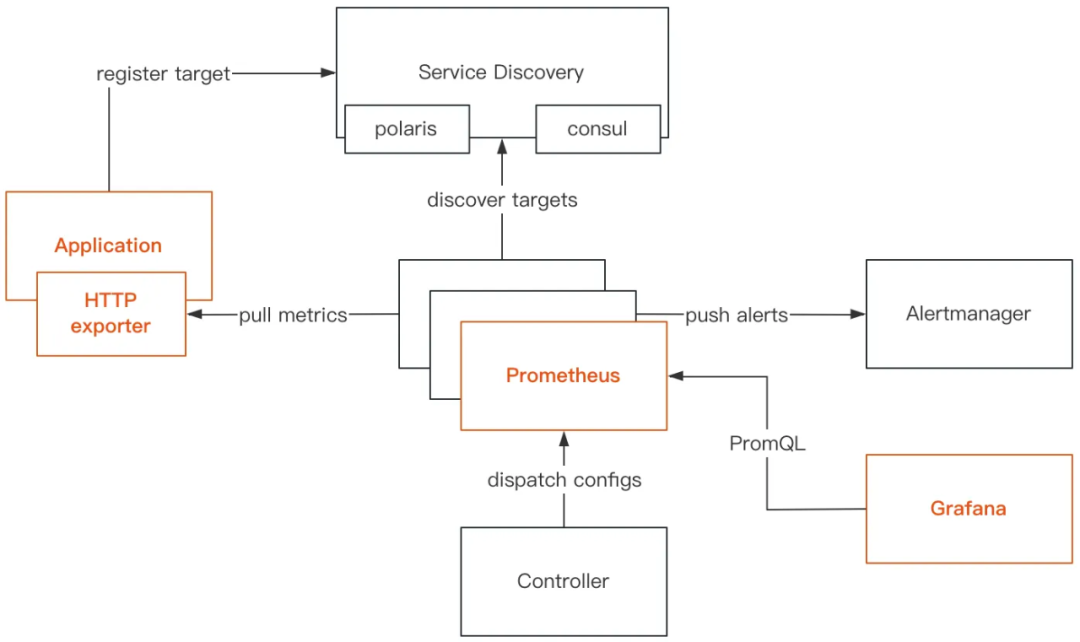
我們在微服務框架中重點提供四個黃金指標的觀測:
-
Traffic(QPS) -
Latency(延時) -
Error(成功率) -
Staturation(資源利用率)
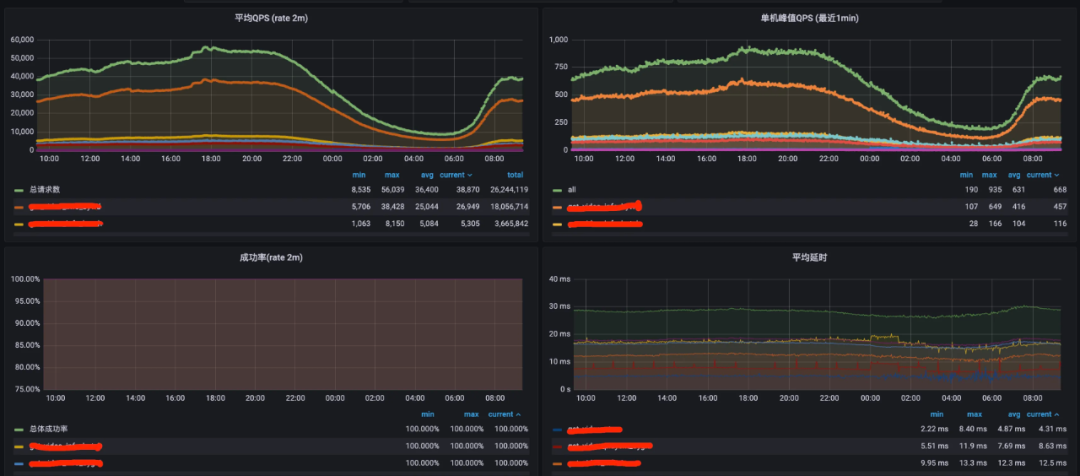
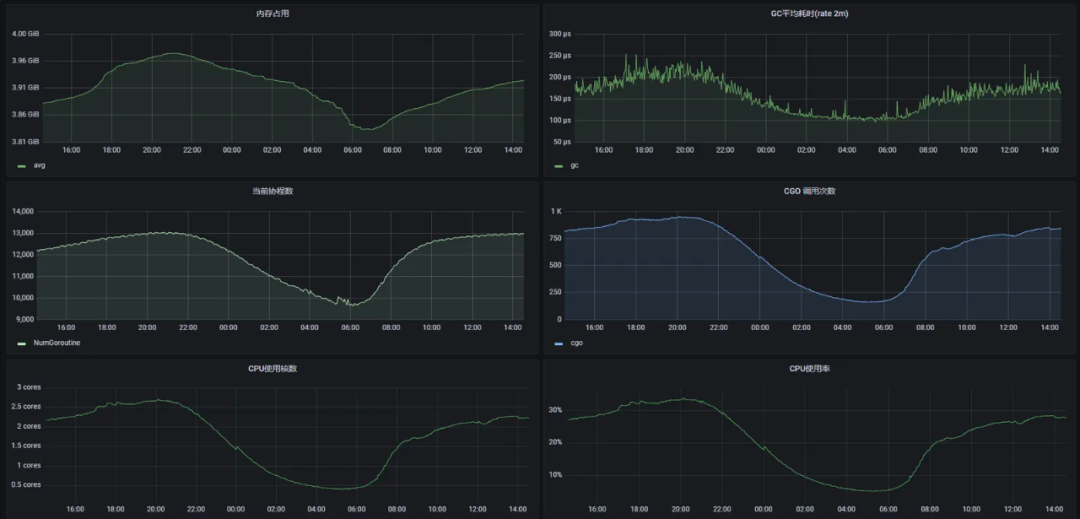
QQ音樂Metrics解決方案優勢:
-
秒級監控:QQ音樂存在多個高并發場景,數專、演唱會直播、明星空降評論/社區等,會帶來比日常高出幾倍甚至數十倍的流量,而且流量集中在活動開始頭幾秒,容量評估難度極大,我們通過搭建Prometheus聯邦,每3秒抓取一次資料,實作了準實時監控,并對活動進行快照采集,記錄活動發生時所有微服務的請求峰值,用于下次同級別藝人的峰值評估, -
歷史資料回溯:QQ音樂海量用戶及上萬微服務,每天產生的資料量級很大,當我們需要回溯近一個月甚至一年前的指標趨勢時,性能是個極大挑戰,由于歷史資料的精度要求不高,我們通過Prometheus聯邦進行階梯降采樣,可以永久存放歷史資料,同時也極大降低存盤成本,
5.2. Logging
隨著業務體量壯大,機器數量龐大,使用SSH檢索日志的方式效率低下,我們需要有專門的日志處理平臺,從龐大的集群中收集日志并提供集中式的日志檢索,同時我們希望業務接入日志處理平臺的方式是無侵入的,不需要使用特定的日志列印組件,
我們使用ELK(ElasticSearch、Logstash、Kibana)構建日志處理平臺,提供無侵入、集中式的遠程日志采集和檢索系統,
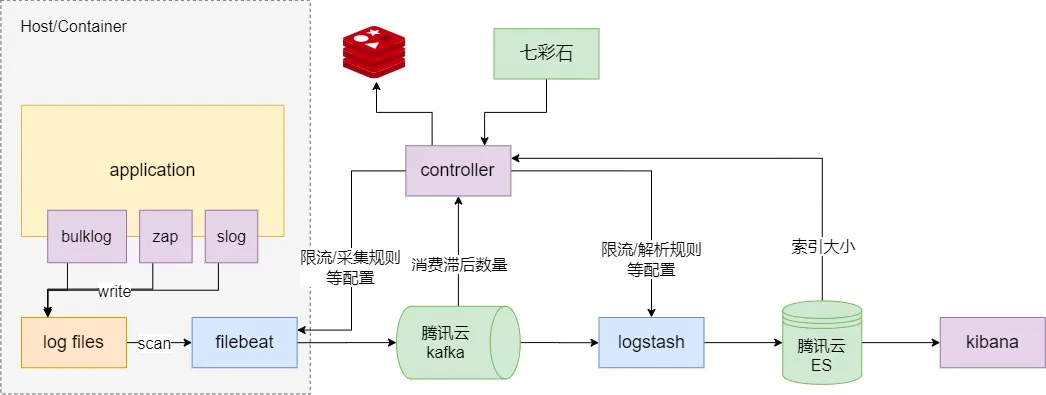
-
Filebeat 作為日志采集和傳送器,Filebeat監視服務日志檔案并將日志資料發送到Kafka, -
Kafka 在Filebeat和Logstash之間做解耦, -
Logstash 決議多種日志格式并發送給下游, -
ElasticSearch 存盤Logstash處理后的資料,并建立索引以便快速檢索, -
Kibana 是一個基于ElasticSearch查看日志的系統,可以使用查詢語法來搜索日志,在查詢時制定時間和日期范圍或使用正則運算式來查找匹配的字串,
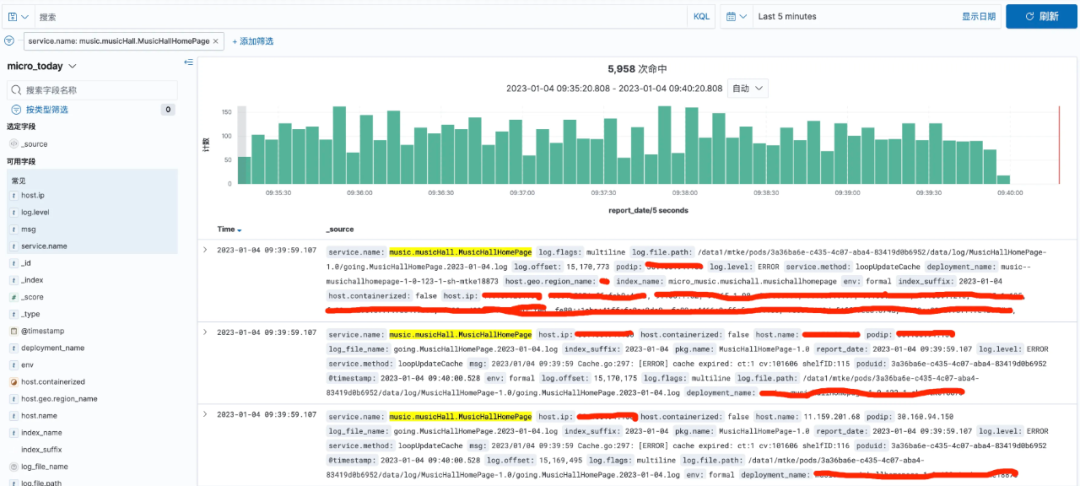
下圖為音樂館首頁服務的遠程日志:
5.3. Tracing
在微服務架構的復雜分布式系統中,一個客戶端請求由系統中大量微服務配合完成處理,這增加了定位問題的難度,如果一個下游服務回傳錯誤,我們希望找到整個上游的呼叫鏈來幫助我們復現和解決問題,類似gdb的backtrace查看函式的呼叫堆疊幀和層級關系,
Tracing在觸發第一個呼叫時生成關聯標識Trace ID,我們可以通過RPC把它傳遞給所有的后續呼叫,就能關聯整條呼叫鏈,Tracing還通過Span來表示呼叫鏈中的各個呼叫之間的關系,
我們基于jaeger構建分布式鏈路追蹤系統,可以實作分布式架構下的事務追蹤、性能分析、故障溯源、服務依賴拓撲,
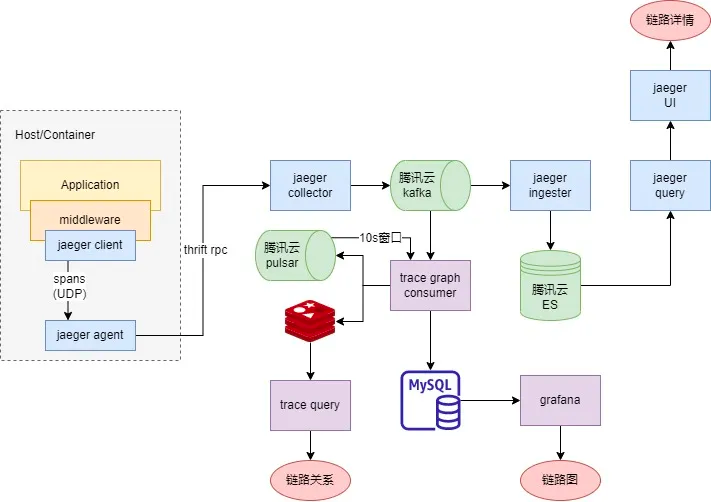
-
jaeger-agent 作為代理,把jaeger client發送的spans轉發到jaeger-collector, -
jaeger-collector 接收來自jaeger-agent上報的資料,驗證和清洗資料后轉發至kafka, -
jaeger-ingester 從kafka消費資料,并存盤到ElasticSearch, -
jaeger-query 封裝用于從ElasticSearch中檢索traces的APIs,
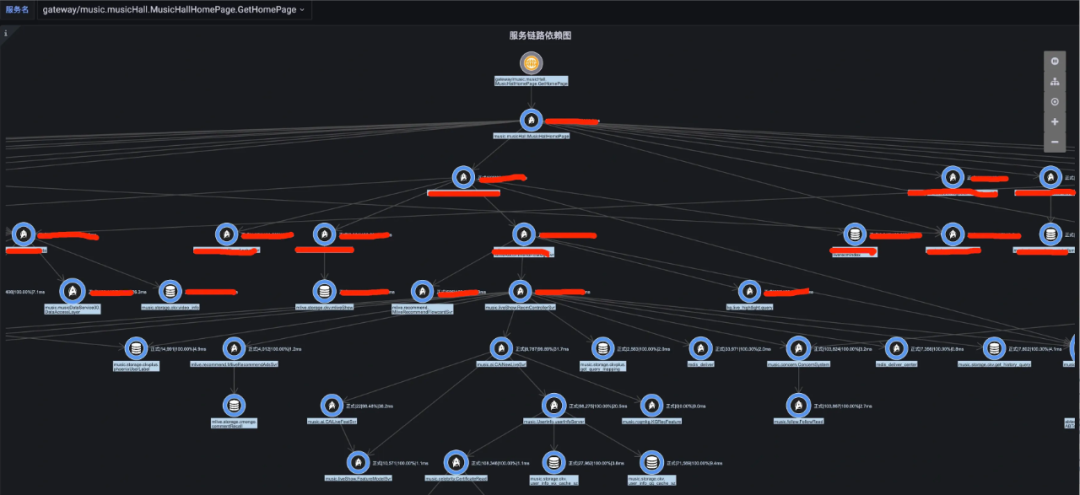
下圖為音樂館首頁服務的鏈路圖:
5.4. Profiles
想必大家都遇到過服務在凌晨三點出現CPU毛刺,一般情況下,我們需要增加pprof分析代碼,然后等待問題復現,問題處理完后刪掉pprof相關代碼,效率底下,如果這是個偶現的問題,定位難度就更大,我們需要建設一個可在生產環境使用分析器的系統,
建設這個系統需要解決三個問題:
-
性能資料采集后需要持久化,方便回溯分析, -
可視化檢索和分析性能資料, -
分析器在生產環境采集資料會有額外開銷,需要合理采樣,
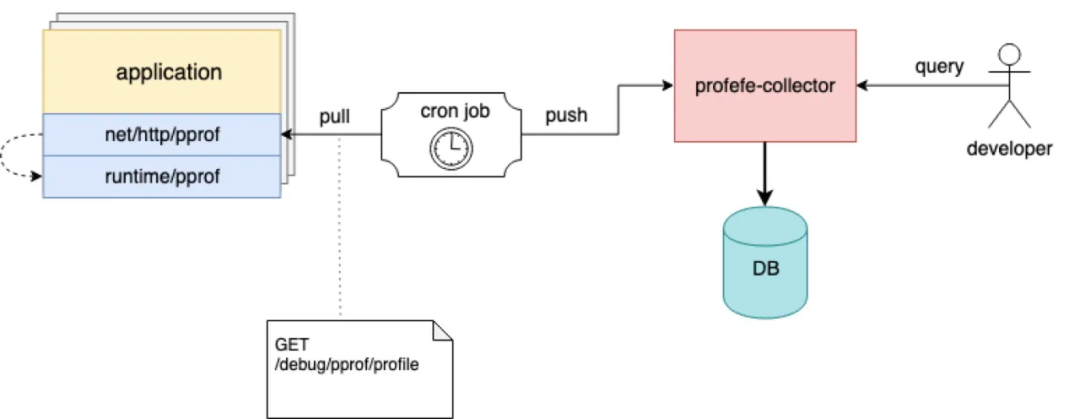
我們基于conprof搭建持續性能分析系統:
-
線上服務根據負載以及采樣決定采集時機,并暴露profile介面, -
conprof定時將profile資訊采集并存盤, -
conprof提供統一的可視化平臺檢索和分析,
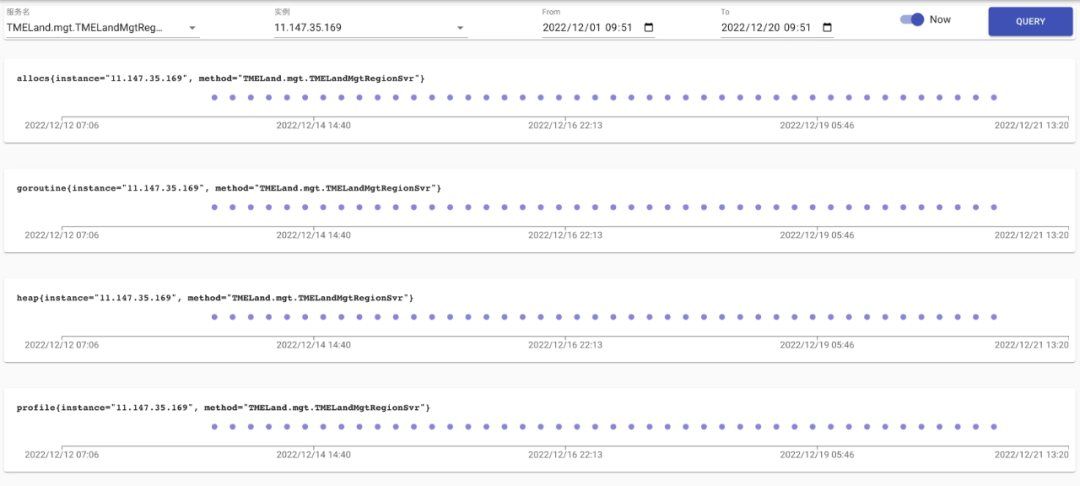
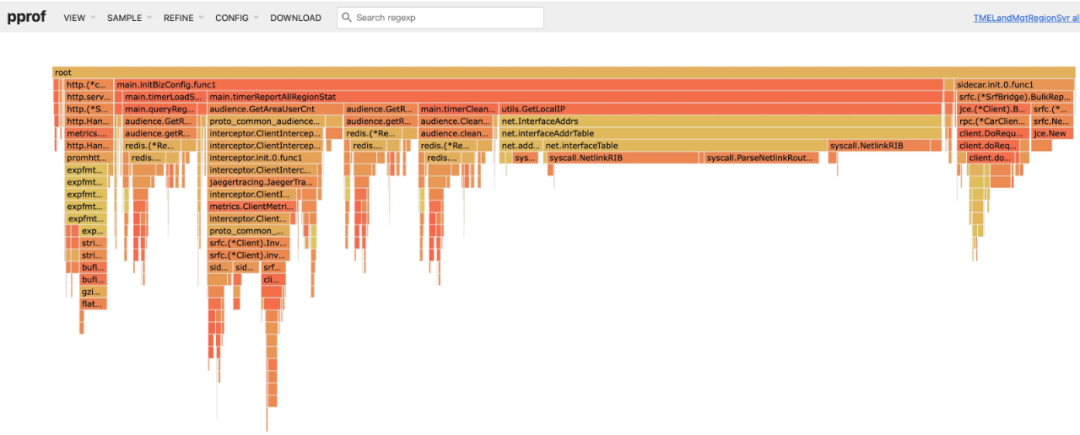
如下圖,我們可以通過服務名、實體、時間區間來檢索profile資訊,每一個點對應一個記錄,
5.5. Dumps
傳統的方式是在行程崩潰時把行程記憶體寫入一個鏡像中以供分析,或者把panic資訊寫到日志中,core dumps的方式在容器環境中實施困難,panic資訊寫入日志則容易被其他日志沖掉且感知太弱,QQ音樂使用的方式是在RPC框架中以攔截器的方式注入,發生panic后上報到sentry平臺,
6. 總結
本文從架構、工具鏈、可觀測三個維度,介紹了QQ音樂多年來積累的高可用架構實踐,先從架構出發,介紹了雙中心容災方案以及一系列穩定性策略,再從工具鏈維度,介紹如何通過工具平臺對架構進行測驗和風險管理,最后介紹如何通過可觀測來提升架構可用性,這三個維度的子系統緊密聯系,相互協同,架構的脆弱性是工具鏈和可觀測性的建設動力,工具鏈和可觀測性的不斷完善又會反哺架構的可用性提升,
此外,QQ音樂微服務建設、Devops建設、容器化建設也是提升可用性的重要因素,單體應用不可用會導致所有的功能不可用,而微服務化按單一職責拆分服務,可以很好地處理服務不可用和功能降級問題,Devops把服務生命周期的管理自動化,通過持續集成、持續測驗、持續發布等來降低人工失誤的風險,容器化最大程度降低基礎設施的影響,讓我們能夠將更多精力放在服務的可用性上,此外,資源隔離,HPA,健康檢查等,也在一定程度上提升可用性,
至此,基礎架構提供了各種高可用的能力,但可用性最侄訓是要回歸業務架構本身,業務系統需要根據業務特性選擇最優的可用性方案,并在系統架構中遵循一些原則,如最大限度減少關鍵依賴;冪等性等可重試設計;消除擴容瓶頸;預防和緩解流量峰值;過載時做好優雅降級等等,而更重要的一點是,我們需要時刻思考架構如何支撐業務的長期增長,
作者|馮煦亮
本文來自博客園,作者:古道輕風,轉載請注明原文鏈接:https://www.cnblogs.com/88223100/p/QQ-music-high-availability-architecture.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/546886.html
標籤:其他
上一篇:軟體架構模式
下一篇:觀察者模式——學習筆記