前言
監控指標誠然是發現問題于微末之時的極佳手段,但指標往往有其表達的極限,在很多情況下,單獨看一個黃金指標并不能表征系統的健康程度,反而有可能被其迷惑,進而忽略相關問題,(本文所提及的Linux Kernel原始碼版本為4.18.10)
Bug現場
某天中午,某應用的999線突然升高,由于是個QPS高達幾十萬的查詢服務,1分鐘的升高就會影響數千個請求,初步判斷應用容量不夠,直接進行相關擴容,擴容后反而加劇了問題!不得已又做了一次緊急擴容,999線才恢復,這兩波操作過去,20多分鐘已經過去了,
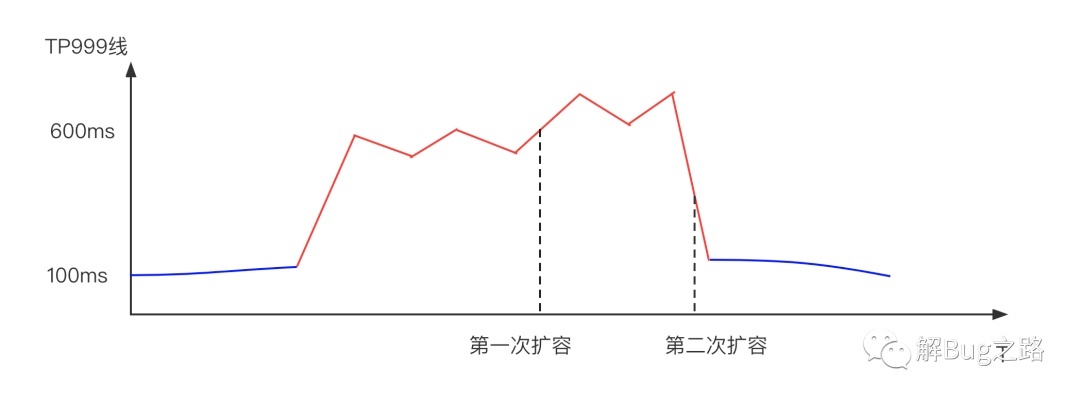
為了防止問題再次發生,我們必須要徹查相關原因,于是筆者也就參與了調查,
Young GC升高
首先是去看常用的指標,例如CPU idle, GC Time,發現有一些機器的CPU達到了60%,而在這些機器中,young gc有一個大幅度的增長,
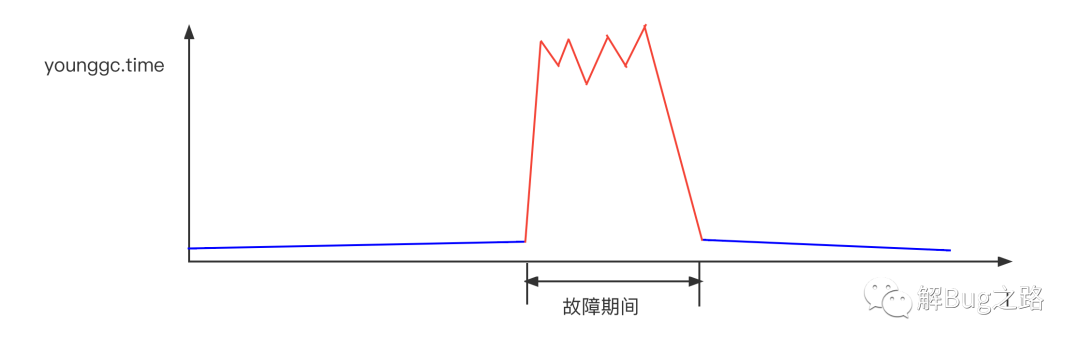
為什么Young GC升高
看上去GC問題,那么,筆者就開始思考為什么young gc升高,翻看gc日志,看到故障期間,不停的young gc,但這些young gc的表現很詭異,有時候young gc很快,只有數十毫秒,有時確達到了數百毫秒,而且這個耗時的跳躍沒什么規律,不是從某個時間點之后就一直是數百毫秒,而是數十和數百一直參雜著,
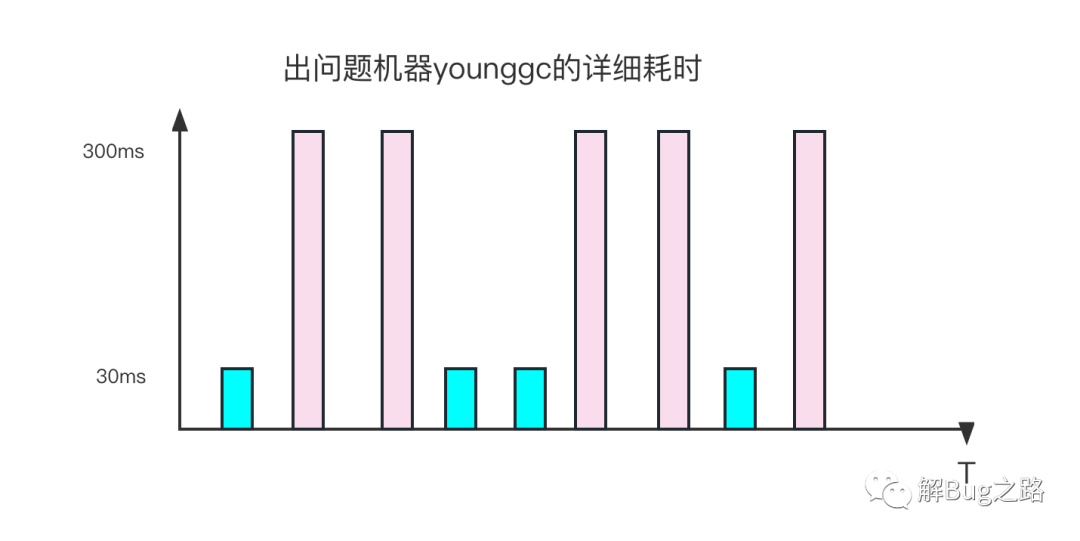
觀察young GC的詳細輸出,在數百毫秒的young GC時間里,大部分時間都在[Object Copy]上,令人奇怪的是,其Copy的Object大小確實差不多的,而這是個非常單純的查詢服務,故障期間,它的流量分布以及對應的Object分布不應該有非常大的變化,那么究竟是什么原因讓同樣大小以及數量的Object Copy會有十倍的差距呢?
再仔細觀察,不僅僅是Object Copy,在其它的GC階段也會出現時間暴漲的情況,只不過大部分集中在Object Copy而已,僅僅靠這些資訊是無法看出來相關問題的,
為什么只有部分機器Young GC升高
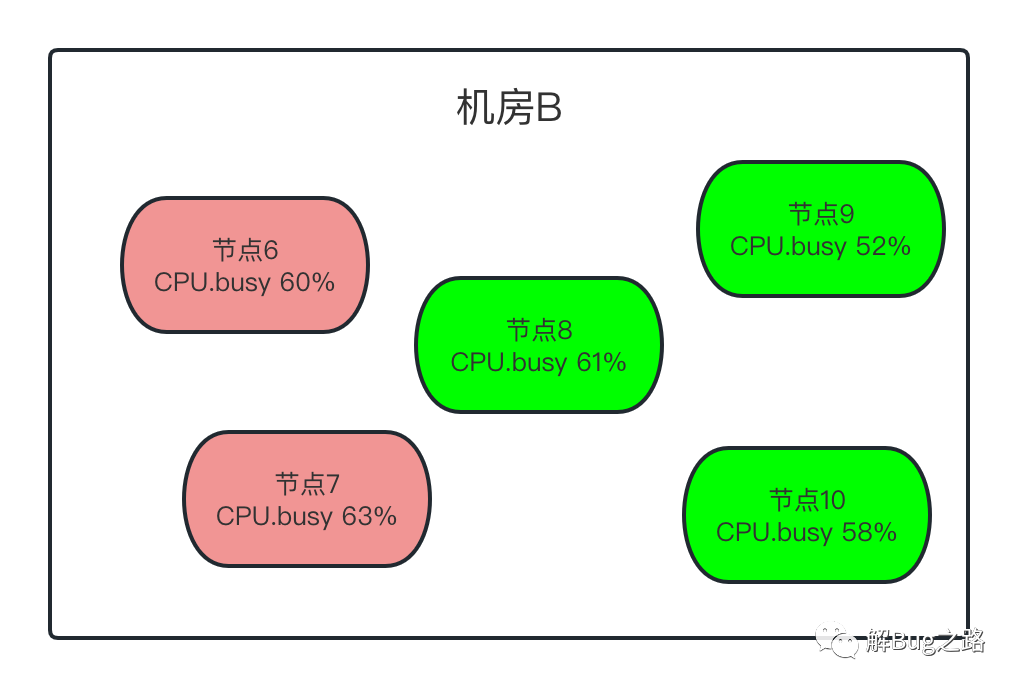
繼續觀察監控,發現問題出現在一部分機器上,而這部分機器都在一個機房(B機房)里面,另一個機房(A機房)的機器沒有受任何影響,當然,出問題的機器都出現了Young GC飆高的現象,難道兩個機房的流量分布不一樣?經過一番統計,發現介面的呼叫分布只是略微有些不同,但細細思考一下,如果是機房流量分布不一樣,由于同機房是負載均衡的,要出問題,也是同機房都出問題,但問題只集中B機房的一部分機器中,
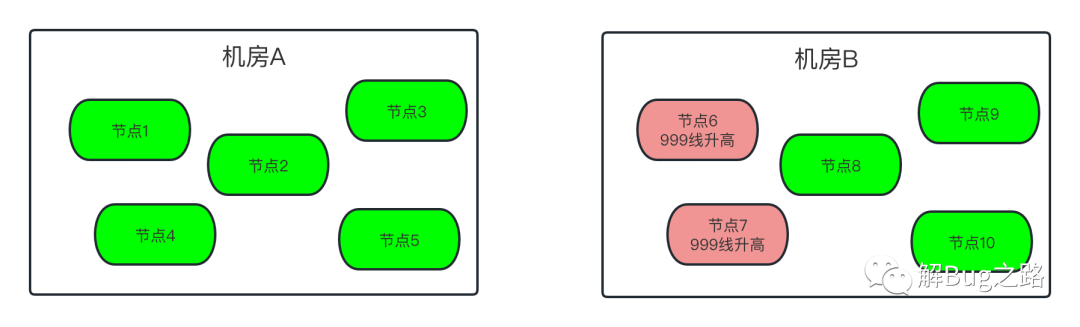
尋找這些機器的共同特征
young gc都大幅升高
那么既然只有一部分機器出問題,那么筆者開始搜索起這些機器的共同特征,young gc在這部分機器耗時都大幅增長,但由于筆者尚不能通過gc日志找出原因,那么就尋找了其它特征,
CPU.Busy
首先,是CPU.busy指標,筆者發現,出問題的機器CPU都在60%左右,但是,正常的節點CPU也有60%的,也有50%的,特征不是很明顯,
delta_nr_throttled和delta_throttled_time
在筆者觀察某臺故障機器監控指標的時候發現,發現delta_nr_throttled和delta_throttled_time這個指標大幅度升高,
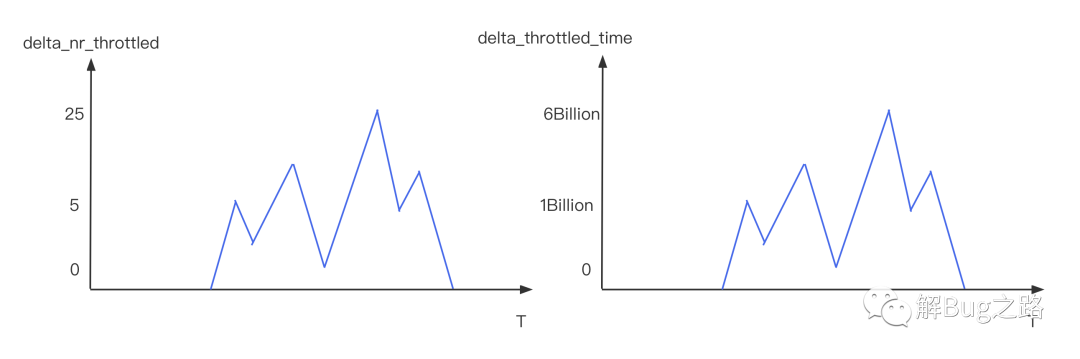
我們看下這兩個指標的含義
nr_throttled:
Linux Doc: Number of times the group has been throttled/limited.
中文解釋: CGROUP被限制的數量
delta_nr_throttled: 是通過取間隔1分鐘的兩個點,計算出每分鐘CGROUP被限制的數量
throttled_time:
linux Doc: The total time duration (in nanoseconds) for which entities of the group have been throttled.
中文解釋: 某個CGroup被限制的時間
delta_throttled_time: 通過取間隔1分鐘的兩個點,計算出每分鐘CGROUP被限制的總時間
由于線上應用這邊采用的是docker容器,所以會有這兩個指標,而這兩個指標表明了,這個CGroup由于CPU消耗太高而被宿主機的Kernel限制運行,而令人奇怪的是,這些機器的CPU最多只有60%左右,按理來說只有達到100%才能被限制(throttled/limit),
宿主機CPU飆升
既然是宿主機限制了相關docker容器,那么很自然的聯想到宿主機出了問題,統計了一下出故障容器在宿主機上的分布,發現出問題的所有容器都是集中出現在兩臺宿主機上!
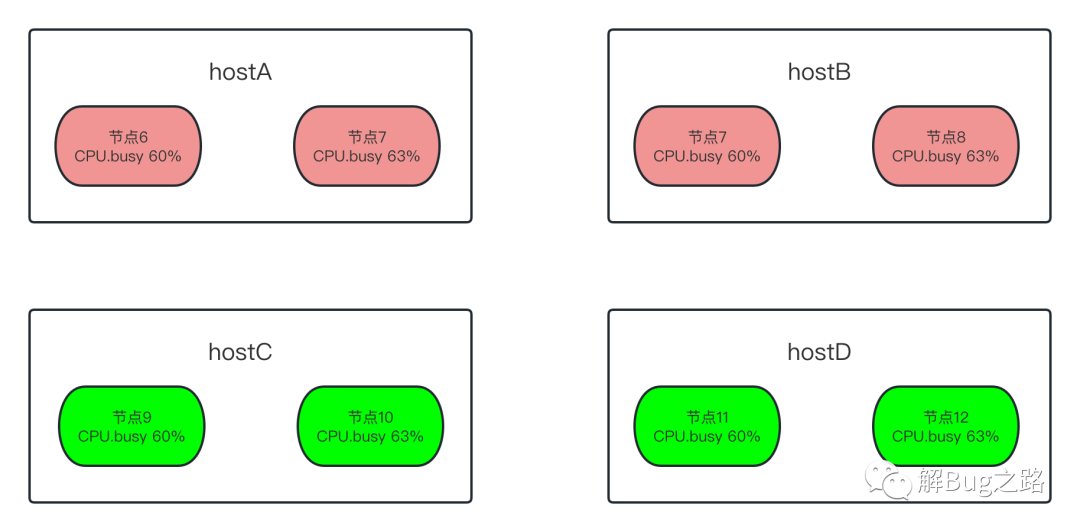
查看了下這兩臺宿主機的CPU Busy,發現平均已經90%多了,
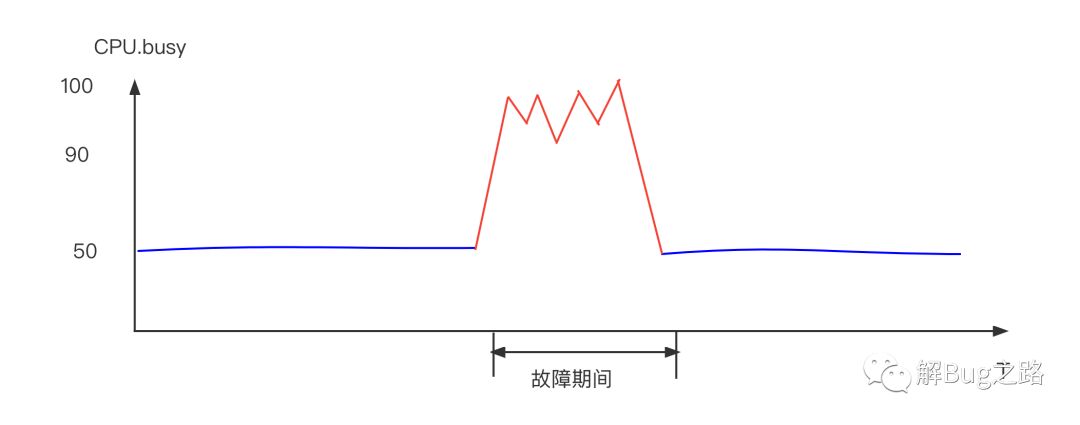
宿主機超賣
詳細觀察了下這兩個宿主機,發現它們超賣非常嚴重,而且當前這個出問題的應用非常集中的部署在這兩個宿主機上,一臺48核的宿主機,僅僅出問題的這個應用就分配了10個,而且分配的資源是每個容器8核(實際上是時間片),那么按照,每個容器使用了60%計算,正好用滿了這個宿主機的核
60% * 10 * 8 = 48 正好和宿主機的48核相對應,
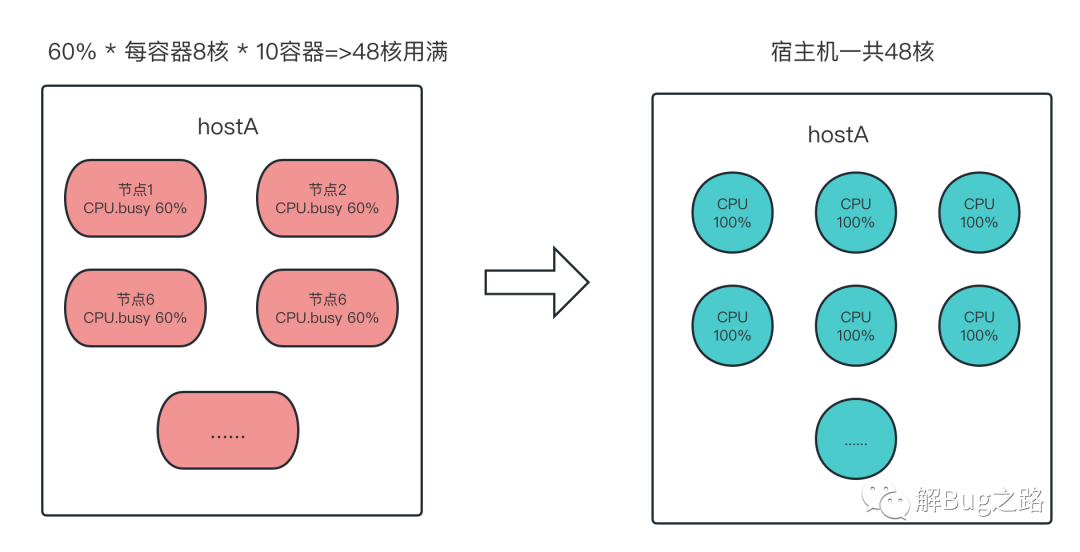
為什么第一次擴容后加劇了問題
因為這次是通過API自動擴容,而由于打散度計算的原因,還是擴容到了這兩臺已經不堪重負的CPU上,同時應用啟動加載時候的CPU消耗也加劇了宿主機CPU的消耗,
為什么第二次擴容之后999線恢復正常
因為第二次直接通過API手動擴容,一次性在10多臺宿主機上機器上擴了一倍的機器,這樣分配在這兩臺不堪重負的宿主機上的應用流量降低到一半左右,進而使得999線恢復正常,
為什么容器相關的CPU busy在宿主機已經接近100%的情況下,依舊只展示60%的
很明顯的,容器的CPU Busy在很大程度上誤導了我們的決策,在之前的容量壓測中,壓到期望的TPS時候CPU Busy只有50%多,而且基本是按照TPS線性增長的,就使得我們覺得這個應用在當前的資源下容量是綽綽有余,畢竟CPU Busy顯示的還是非常健康的,
但沒想到,在壓測CPU 50%多的時候,其實已經到了整個應用容量的極限,線上的流量和壓測流量的構造有稍微一點的區別,讓CPU漲了個5%左右,過了那個宿主機CPU的臨界點,進而就導致了應用出現了非常高的999線,
容器CPU busy和idle的計算
為了探究這個問題,筆者就不得不看下容器的CPU busy是如何計算出來的,畢竟Linux的CGroup并沒有提供CPU Busy這個指標,翻閱了一下監控的計算公式,
每隔5秒取一下cpuacct.usage的資料
cat /sys/fs/cgroup/cpu/cpuacct.usage
CPU.busy = (cpuacct.usage(T秒) - cpuacct.usage(T-5秒))/((5秒)*CPU核數)
CPU.idle = 1- CPU.busy
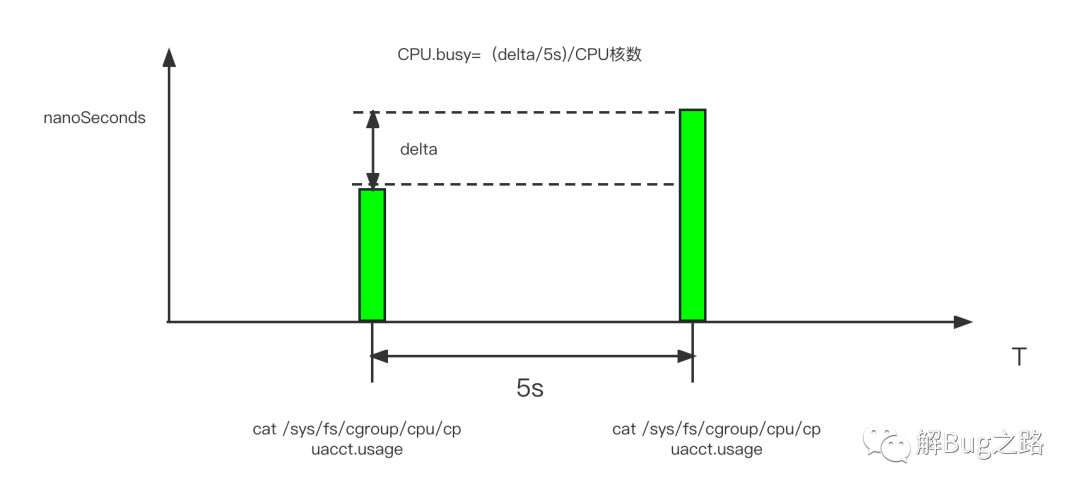
那么我們可以看一下cpuacct.usage是如何計算的,Kernel的代碼實作為:
cpuusage_read
|->__cpuusage_read
|->cpuacct_cpuusage_read
static u64 __cpuusage_read(struct cgroup_subsys_state *css,
enum cpuacct_stat_index index)
{
/* 獲取當前對應cgroup中的cpuacct結構體*/
struct cpuacct *ca = css_ca(css);
......
/* 遍歷所有可能的CPU */
for_each_possible_cpu(i)
totalcpuusage += cpuacct_cpuusage_read(ca, i, index);
return totalcpuusage;
}
static u64 cpuacct_cpuusage_read(struct cpuacct *ca, int cpu,
enum cpuacct_stat_index index)
{
// 從當前cgroup中獲取對應相應的cpuusage結構體
struct cpuacct_usage *cpuusage = per_cpu_ptr(ca->cpuusage, cpu);
......
/* i=0計算的是user space的usage,i=1計算的是kernel space的usage */
for (i = 0; i < CPUACCT_STAT_NSTATS; i++)
data += cpuusage->usages[i];
}
由代碼可見,其計算是將所有CPU中的關于當前CGroup的cpuusage->usages中的user和system time相加,進而獲取到最終此,那么我們可以進一步看下CGroup中的cpuusage是如何計算的,這邊筆者以我們常用的CFS(完全公平調度的代碼實作為例):
/* 相關的一條cpuusage代碼路徑如下 *.
pick_next_task_fair
|->put_prev_entity
|->update_curr
|->cgroup_account_cputime /* 其中還包含對當前cgroup的parentGroup的修正*/
|->cpuacct_charge
void cpuacct_charge(struct task_struct *tsk, u64 cputime)
{
struct cpuacct *ca;
int index = CPUACCT_STAT_SYSTEM;
struct pt_regs *regs = task_pt_regs(tsk);
/* 判斷是system time還是user time */
if (regs && user_mode(regs))
index = CPUACCT_STAT_USER;
rcu_read_lock();
/* 將相關的CPU運行時間入賬 */
for (ca = task_ca(tsk); ca; ca = parent_ca(ca))
this_cpu_ptr(ca->cpuusage)->usages[index] += cputime;
rcu_read_unlock();
}
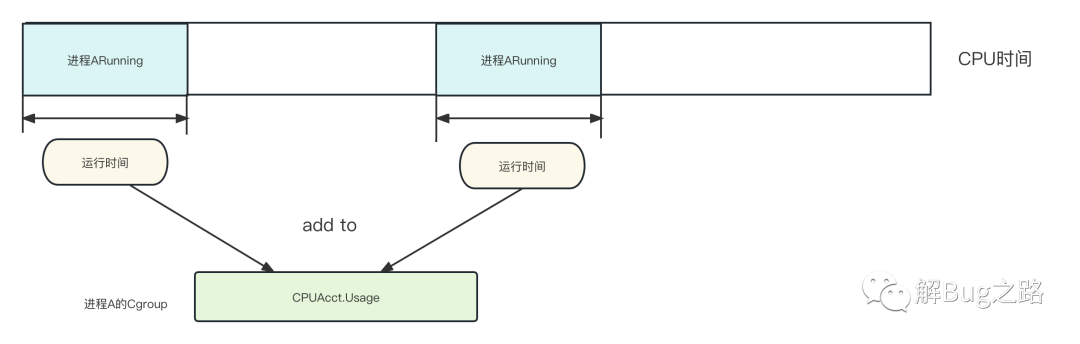
由上面代碼可知,kernel會在行程間切換的時候,將當前行程的運行時間記入到相關,那么就是這個cputime的計算了,
/* 一個cfs_rq可以是一個task行程,也可以是一個cgroup,代表的是完全公平調度runqueue中的一個元素 */
static void update_curr(struct cfs_rq *cfs_rq){
/* 這個now=rq->clock_task,clock_task回傳的rq->clock減去處理IRQs竊取的時間,其計算不在本文描述范圍內 , 不考慮IRQ的話,可以認為等于此rq的總運行時間*/
u64 now = rq_clock_task(rq_of(cfs_rq));
/* 這個delta_exec表明了在這一次的運行中,此cfs_rq(行程orCgroup)實際運行了多長時間*/
delta_exec = now - curr->exec_start;
curr->exec_start = now;
......
/* 將這一次行程在當前CFS調度下運行的時間更新如相關cgroup的usage */
cgroup_account_cputime(curtask, delta_exec);
.....
}
好了,翻了一大堆代碼,我們的cpuusage實際上就是這個cgroup在這一次CFS的kernel調度時間片中實際運行的時間,而我們的應用主要是一個Java行程,那么其基本就是這個Java行程運行了多長時間,值得注意的是,每個CPU的調度都會進行這樣的計算,如下圖所示:
那么我們來看一下在超賣情況下的表現,如下圖所示:
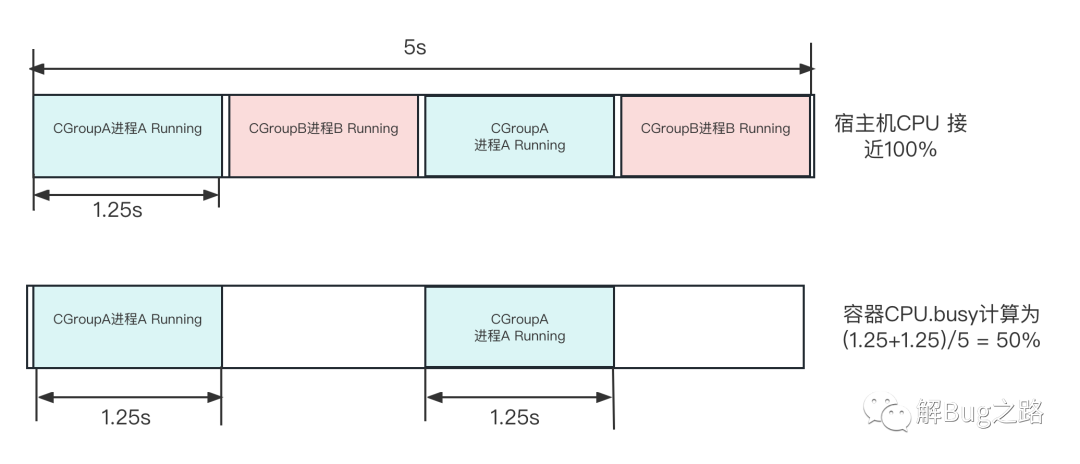
(圖中1.25s只是為了繪圖方便,實際調度時間切片非常小)
如果超賣了,而且行程都比較繁忙,那么每個CGroup肯定不能完全的占用宿主機的CPU,指定到某個CPU上就勢必會有多個CGroup交替進行,而之前的容器CPU.Busy計算公式
CPU.busy = (cpuacct.usage(T秒) - cpuacct.usage(T-5秒))/((5秒)*CPU核數)
反應的實際上是這個容器在這個CPU(核)上運行了多長時間,而完全不能反應CPU的繁忙程度,
如果不超賣,每個CGroup被均勻的分到各自的CPU上互不影響(當然如果cgroup綁核了那隔離性更好),那么這個計算公式才能夠比較準確的反映CPU的情況,
nr_throttled和throttled_time
在Kernel中這兩個引數表示由于分配給Cgroup的cfs_quota_us時間片額度用完,進而導致被內核限制,限制的次數為nr_throttled,限制的總時間為throttled_time,
cat /sys/fs/cgroup/cpuacct/cpu.cfs_period_us 100000(100ms)
cat /sys/fs/cgroup/cpuacct/cpu.cpu.cfs_quota_us 800000(800ms) 因為有8個核,所以分配了800ms
cat /sys/fs/cgroup/cpuset/cpuset.cpus 基本打散到所有的CPU上
但這邊和上面的推論有一個矛盾的點,如果由于CPU超賣而引起的問題的話,那么每個CGroup并不能分到800ms這樣總的時間片,因為按照上面的推算,每個CGroup最多分到60% * 800=480ms的時間片,而這個時間片是不應該觸發nr_throttled和throttled_time的!

就在筆者對著Kernel原始碼百思不得其解之際,筆者發現Linux Kernel在5.4版本有個優化
https://lwn.net/Articles/792268/
sched/fair: Fix low cpu usage with high throttling by removing expiration of cpu-local slices
也就是說在5.4版本之前,在一些場景下low cpu usage依舊能導致cgroup被throttled,而這個場景即是:
that highly-threaded, non-cpu-bound applications
running under cpu.cfs_quota_us constraints can hit a high percentage of
periods throttled
高度執行緒化,非CPU密集的應用程式在CPU.cfs_quota_us約束下運行時,可能會有很高的周期被限制,同時不會消耗分配的配額,
出故障的應用使用了大量的執行緒去處理請求,同時也有大量的IO操作(操作分布式快取),符合此Bug的描述,
# 那么到底是內核Bug還是超賣是主因呢?
這個疑問當然靠對比來解決,我們在故障之后,做了一次壓測(CPU.Busy > 60%),這次應用是不超賣的,這次delta_nr_throttled和delta_throttled_time依舊存在,不過比故障時的數量少了一個數量級,
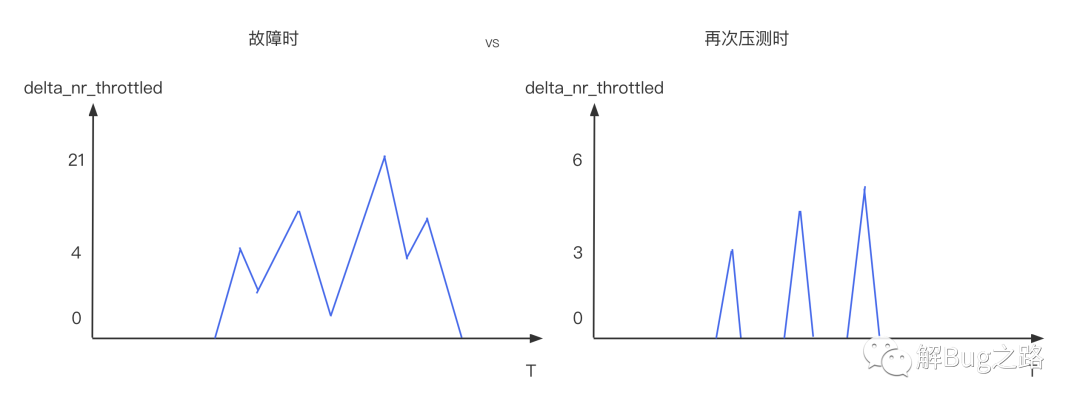
同時999線從故障時候的暴漲6倍變成了只增長1倍,
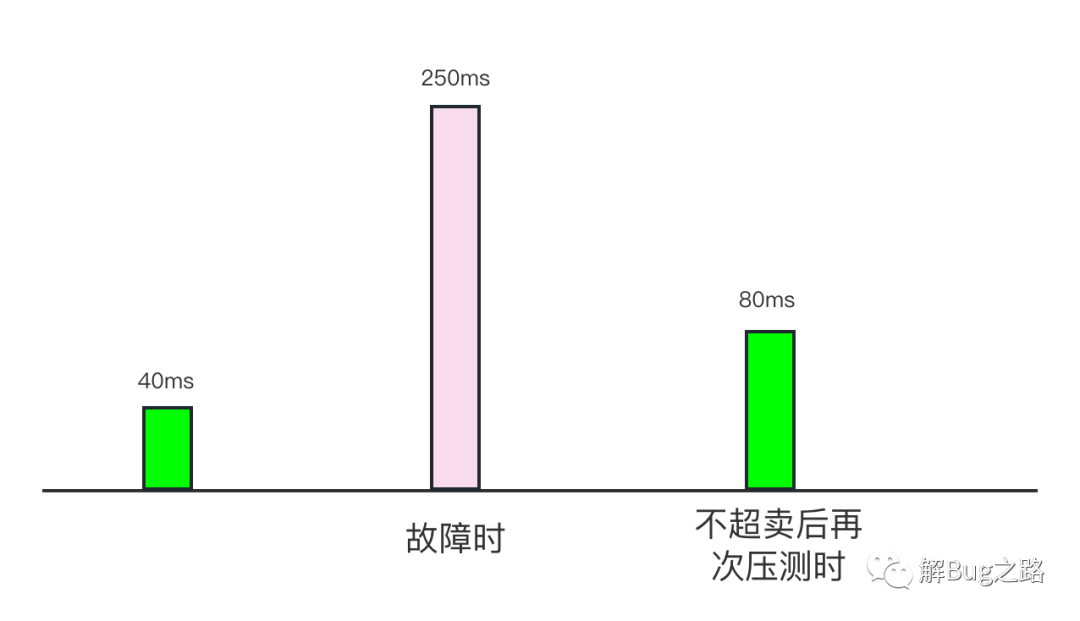
很明顯的,宿主機超賣是主因!而且宿主機超賣后的宿主機CPU負載過高還加重了這個Bug的觸發,
關于Cgroup的核數分配
線上的Cgroup(容器)的核數分配實際上是按照(核數=cfs_quota_us/cfs_period_us)這個模型去分配的,同時并不會在cpuset進行綁核,也就是說一個48核的容器,應用的各個執行緒可以跑在任何一個核上,只不過只分配了8核的時間片額度,這就利用了Cgroup的帶寬控制機制CFS_BANDWITH,
改進措施
很明顯的改進措施可以是下面幾種:
針對超賣:
1) 宿主機不超賣,但不是一個好的選擇,因為資源利用率上不去,存在大量CPU利用率很低的應用
2) 根據應用的CPU利用率情況進行高低錯配放到宿主機上,在利用資源利用率的同時又不至于互相影響
針對內核的Bug
1) 可以打Patch或者升級到5.4
為什么Young GC會變慢
回過頭來看看young gc為什么會慢就很明顯了,因為在young gc時候,被shedule出去了,而且沒有其它的空閑CPU讓jvm可以schedule回來,白白浪費了很長時間,
因為object copy在這個應用的young gc中是最耗費CPU以及時間的操作,所以自然在object copy階段出現變慢的現象,
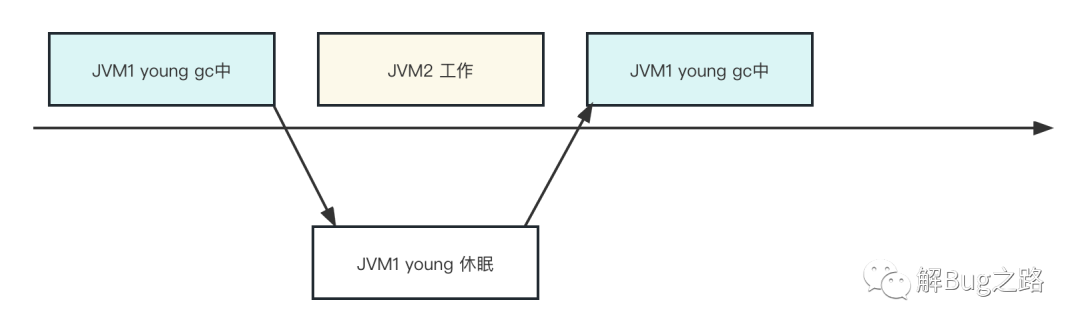
當然,行程schedule可以處在各種時間點,所以并不僅僅是Young GC變慢了,在請求處理階段也可能變慢,
總結
指標雖然能夠比較準確且客觀的反映兩個時間點的變化,但指標的定義和對指標的解讀確實比較主觀的,沒有理解清楚指標所能表達的極限以及使用場景,往往會讓我們排查問題進入誤區!
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/549788.html
標籤:其他
上一篇:行為型:迭代器模式
下一篇:行為型:發布訂閱模式