前言
演算法和資料結構是一個程式員的內功,所以經常在一些筆試中都會要求手寫一些簡單的排序演算法,以此考驗面試者的編程水平,下面我就簡單介紹八種常見的排序演算法,一起學習一下,
一、冒泡排序
思路:
- 比較相鄰的元素,如果第一個比第二個大,就交換它們兩個;
- 對每一對相鄰元素作同樣的作業,從開始第一對到結尾的最后一對,這樣在最后的元素就是最大的數;
- 排除最大的數,接著下一輪繼續相同的操作,確定第二大的數...
- 重復步驟1-3,直到排序完成,
影片演示:
實作代碼:
/**
* @author Ye Hongzhi 公眾號:java技術愛好者
* @name BubbleSort
* @date 2020-09-05 21:38
**/
public class BubbleSort extends BaseSort {
public static void main(String[] args) {
BubbleSort sort = new BubbleSort();
sort.printNums();
}
@Override
protected void sort(int[] nums) {
if (nums == null || nums.length < 2) {
return;
}
for (int i = 0; i < nums.length - 1; i++) {
for (int j = 0; j < nums.length - i - 1; j++) {
if (nums[j] > nums[j + 1]) {
int temp = nums[j];
nums[j] = nums[j + 1];
nums[j + 1] = temp;
}
}
}
}
}
//10萬個數的陣列,耗時:21554毫秒平均時間復雜度:O(n2)
空間復雜度:O(1)
演算法穩定性:穩定
二、插入排序
思路:
- 從第一個元素開始,該元素可以認為已經被排序;
- 取出下一個元素,在前面已排序的元素序列中,從后向前掃描;
- 如果該元素(已排序)大于新元素,將該元素移到下一位置;
- 重復步驟3,直到找到已排序的元素小于或者等于新元素的位置;
- 將新元素插入到該位置后;
- 重復步驟2~5,
影片演示:
實作代碼:
/**
* @author Ye Hongzhi 公眾號:java技術愛好者
* @name InsertSort
* @date 2020-09-05 22:34
**/
public class InsertSort extends BaseSort {
public static void main(String[] args) {
BaseSort sort = new InsertSort();
sort.printNums();
}
@Override
protected void sort(int[] nums) {
if (nums == null || nums.length < 2) {
return;
}
for (int i = 0; i < nums.length - 1; i++) {
//當前值
int curr = nums[i + 1];
//上一個數的指標
int preIndex = i;
//在陣列中找到一個比當前遍歷的數小的第一個數
while (preIndex >= 0 && curr < nums[preIndex]) {
//把比當前遍歷的數大的數字往后移動
nums[preIndex + 1] = nums[preIndex];
//需要插入的數的下標往前移動
preIndex--;
}
//插入到這個數的后面
nums[preIndex + 1] = curr;
}
}
}
//10萬個數的陣列,耗時:2051毫秒平均時間復雜度:O(n2)
空間復雜度:O(1)
演算法穩定性:穩定
三、選擇排序
思路:
第一輪,找到最小的元素,和陣列第一個數交換位置,
第二輪,找到第二小的元素,和陣列第二個數交換位置...
直到最后一個元素,排序完成,
影片演示:
實作代碼:
/**
* @author Ye Hongzhi 公眾號:java技術愛好者
* @name SelectSort
* @date 2020-09-06 22:27
**/
public class SelectSort extends BaseSort {
public static void main(String[] args) {
SelectSort sort = new SelectSort();
sort.printNums();
}
@Override
protected void sort(int[] nums) {
for (int i = 0; i < nums.length; i++) {
int minIndex = i;
for (int j = i + 1; j < nums.length; j++) {
if (nums[j] < nums[minIndex]) {
minIndex = j;
}
}
if (minIndex != i) {
int temp = nums[i];
nums[minIndex] = temp;
nums[i] = nums[minIndex];
}
}
}
}
//10萬個數的陣列,耗時:8492毫秒演算法復雜度:O(n2)
演算法空間復雜度:O(1)
演算法穩定性:不穩定
四、希爾排序
思路:
把陣列分割成若干(h)個小組(一般陣列長度length/2),然后對每一個小組分別進行插入排序,每一輪分割的陣列的個數逐步縮小,h/2->h/4->h/8,并且進行排序,保證有序,當h=1時,則陣列排序完成,
影片演示:
實作代碼:
/**
* @author Ye Hongzhi 公眾號:java技術愛好者
* @name SelectSort
* @date 2020-09-06 22:27
**/
public class ShellSort extends BaseSort {
public static void main(String[] args) {
ShellSort sort = new ShellSort();
sort.printNums();
}
@Override
protected void sort(int[] nums) {
if (nums == null || nums.length < 2) {
return;
}
int length = nums.length;
int temp;
//步長
int gap = length / 2;
while (gap > 0) {
for (int i = gap; i < length; i++) {
temp = nums[i];
int preIndex = i - gap;
while (preIndex >= 0 && nums[preIndex] > temp) {
nums[preIndex + gap] = nums[preIndex];
preIndex -= gap;
}
nums[preIndex + gap] = temp;
}
gap /= 2;
}
}
}
//10萬個數的陣列,耗時:261毫秒演算法復雜度:O(nlog2n)
演算法空間復雜度:O(1)
演算法穩定性:穩定
五、快速排序
快排,面試最喜歡問的排序演算法,這是運用分治法的一種排序演算法,
思路:
- 從陣列中選一個數做為基準值,一般選第一個數,或者最后一個數,
- 采用雙指標(頭尾兩端)遍歷,從左往右找到比基準值大的第一個數,從右往左找到比基準值小的第一個數,交換兩數位置,直到頭尾指標相等或頭指標大于尾指標,把基準值與頭指標的數交換,這樣一輪之后,左邊的數就比基準值小,右邊的數就比基準值大,
- 對左邊的數列,重復上面1,2步驟,對右邊重復1,2步驟,
- 左右兩邊數列遞回結束后,排序完成,
影片演示:
實作代碼:
/**
* @author Ye Hongzhi 公眾號:java技術愛好者
* @name SelectSort
* @date 2020-09-06 22:27
**/
public class QuickSort extends BaseSort {
public static void main(String[] args) {
QuickSort sort = new QuickSort();
sort.printNums();
}
@Override
protected void sort(int[] nums) {
if (nums == null || nums.length < 2) {
return;
}
quickSort(nums, 0, nums.length - 1);
}
private void quickSort(int[] nums, int star, int end) {
if (star > end) {
return;
}
int i = star;
int j = end;
int key = nums[star];
while (i < j) {
while (i < j && nums[j] > key) {
j--;
}
while (i < j && nums[i] <= key) {
i++;
}
if (i < j) {
int temp = nums[i];
nums[i] = nums[j];
nums[j] = temp;
}
}
nums[star] = nums[i];
nums[i] = key;
quickSort(nums, star, i - 1);
quickSort(nums, i + 1, end);
}
}
//10萬個數的陣列,耗時:50毫秒演算法復雜度:O(nlogn)
演算法空間復雜度:O(1)
演算法穩定性:不穩定
六、歸并排序
歸并排序是采用分治法的典型應用,而且是一種穩定的排序方式,不過需要使用到額外的空間,
思路:
- 把陣列不斷劃分成子序列,劃成長度只有2或者1的子序列,
- 然后利用臨時陣列,對子序列進行排序,合并,再把臨時陣列的值復制回原陣列,
- 反復操作1~2步驟,直到排序完成,
歸并排序的優點在于最好情況和最壞的情況的時間復雜度都是O(nlogn),所以是比較穩定的排序方式,
影片演示:
實作代碼:
/**
* @author Ye Hongzhi 公眾號:java技術愛好者
* @name MergeSort
* @date 2020-09-08 23:30
**/
public class MergeSort extends BaseSort {
public static void main(String[] args) {
MergeSort sort = new MergeSort();
sort.printNums();
}
@Override
protected void sort(int[] nums) {
if (nums == null || nums.length < 2) {
return;
}
//歸并排序
mergeSort(0, nums.length - 1, nums, new int[nums.length]);
}
private void mergeSort(int star, int end, int[] nums, int[] temp) {
//遞回終止條件
if (star >= end) {
return;
}
int mid = star + (end - star) / 2;
//左邊進行歸并排序
mergeSort(star, mid, nums, temp);
//右邊進行歸并排序
mergeSort(mid + 1, end, nums, temp);
//合并左右
merge(star, end, mid, nums, temp);
}
private void merge(int star, int end, int mid, int[] nums, int[] temp) {
int index = 0;
int i = star;
int j = mid + 1;
while (i <= mid && j <= end) {
if (nums[i] > nums[j]) {
temp[index++] = nums[j++];
} else {
temp[index++] = nums[i++];
}
}
while (i <= mid) {
temp[index++] = nums[i++];
}
while (j <= end) {
temp[index++] = nums[j++];
}
//把臨時陣列中已排序的數復制到nums陣列中
if (index >= 0) System.arraycopy(temp, 0, nums, star, index);
}
}
//10萬個數的陣列,耗時:26毫秒演算法復雜度:O(nlogn)
演算法空間復雜度:O(n)
演算法穩定性:穩定
七、堆排序
大頂堆概念:每個節點的值都大于或者等于它的左右子節點的值,所以頂點的數就是最大值,
思路:
- 對原陣列構建成大頂堆,
- 交換頭尾值,尾指標索引減一,固定最大值,
- 重新構建大頂堆,
- 重復步驟2~3,直到最后一個元素,排序完成,
構建大頂堆的思路,可以看代碼注釋,
影片演示:
實作代碼:
/**
* @author Ye Hongzhi 公眾號:java技術愛好者
* @name HeapSort
* @date 2020-09-08 23:34
**/
public class HeapSort extends BaseSort {
public static void main(String[] args) {
HeapSort sort = new HeapSort();
sort.printNums();
}
@Override
protected void sort(int[] nums) {
if (nums == null || nums.length < 2) {
return;
}
heapSort(nums);
}
private void heapSort(int[] nums) {
if (nums == null || nums.length < 2) {
return;
}
//構建大根堆
createTopHeap(nums);
int size = nums.length;
while (size > 1) {
//大根堆的交換頭尾值,固定最大值在末尾
swap(nums, 0, size - 1);
//末尾的索引值往左減1
size--;
//重新構建大根堆
updateHeap(nums, size);
}
}
private void createTopHeap(int[] nums) {
for (int i = 0; i < nums.length; i++) {
//當前插入的索引
int currIndex = i;
//父節點的索引
int parentIndex = (currIndex - 1) / 2;
//如果當前遍歷的值比父節點大的話,就交換值,然后繼續往上層比較
while (nums[currIndex] > nums[parentIndex]) {
//交換當前遍歷的值與父節點的值
swap(nums, currIndex, parentIndex);
//把父節點的索引指向當前遍歷的索引
currIndex = parentIndex;
//往上計算父節點索引
parentIndex = (currIndex - 1) / 2;
}
}
}
private void updateHeap(int[] nums, int size) {
int index = 0;
//左節點索引
int left = 2 * index + 1;
//右節點索引
int right = 2 * index + 2;
while (left < size) {
//最大值的索引
int largestIndex;
//如果右節點大于左節點,則最大值索引指向右子節點索引
if (right < size && nums[left] < nums[right]) {
largestIndex = right;
} else {
largestIndex = left;
}
//如果父節點大于最大值,則把父節點索引指向最大值索引
if (nums[index] > nums[largestIndex]) {
largestIndex = index;
}
//如果父節點索引指向最大值索引,證明已經是大根堆,退出回圈
if (largestIndex == index) {
break;
}
//如果不是大根堆,則交換父節點的值
swap(nums, largestIndex, index);
//把最大值的索引變成父節點索引
index = largestIndex;
//重新計算左節點索引
left = 2 * index + 1;
//重新計算右節點索引
right = 2 * index + 2;
}
}
private void swap(int[] nums, int i, int j) {
int temp = nums[i];
nums[i] = nums[j];
nums[j] = temp;
}
}
//10萬個數的陣列,耗時:38毫秒演算法復雜度:O(nlogn)
演算法空間復雜度:O(1)
演算法穩定性:不穩定
八、桶排序
思路:
- 找出最大值,最小值,
- 根據陣列的長度,創建出若干個桶,
- 遍歷陣列的元素,根據元素的值放入到對應的桶中,
- 對每個桶的元素進行排序(可使用快排,插入排序等),
- 按順序合并每個桶的元素,排序完成,
對于陣列中的元素分布均勻的情況,排序效率較高,相反的,如果分布不均勻,則會導致大部分的數落入到同一個桶中,使效率降低,
影片演示(來源于五分鐘學演算法,侵刪):
實作代碼:
/**
* @author Ye Hongzhi 公眾號:java技術愛好者
* @name BucketSort
* @date 2020-09-08 23:37
**/
public class BucketSort extends BaseSort {
public static void main(String[] args) {
BucketSort sort = new BucketSort();
sort.printNums();
}
@Override
protected void sort(int[] nums) {
if (nums == null || nums.length < 2) {
return;
}
bucketSort(nums);
}
public void bucketSort(int[] nums) {
if (nums == null || nums.length < 2) {
return;
}
//找出最大值,最小值
int max = Integer.MIN_VALUE;
int min = Integer.MAX_VALUE;
for (int num : nums) {
min = Math.min(min, num);
max = Math.max(max, num);
}
int length = nums.length;
//桶的數量
int bucketCount = (max - min) / length + 1;
int[][] bucketArrays = new int[bucketCount][];
//遍歷陣列,放入桶內
for (int i = 0; i < length; i++) {
//找到桶的下標
int index = (nums[i] - min) / length;
//添加到指定下標的桶里,并且使用插入排序排序
bucketArrays[index] = insertSortArrays(bucketArrays[index], nums[i]);
}
int k = 0;
//合并全部桶的
for (int[] bucketArray : bucketArrays) {
if (bucketArray == null || bucketArray.length == 0) {
continue;
}
for (int i : bucketArray) {
//把值放回到nums陣列中
nums[k++] = i;
}
}
}
//每個桶使用插入排序進行排序
private int[] insertSortArrays(int[] arr, int num) {
if (arr == null || arr.length == 0) {
return new int[]{num};
}
//創建一個temp陣列,長度是arr陣列的長度+1
int[] temp = new int[arr.length + 1];
//把傳進來的arr陣列,復制到temp陣列
for (int i = 0; i < arr.length; i++) {
temp[i] = arr[i];
}
//找到一個位置,插入,形成新的有序的陣列
int i;
for (i = temp.length - 2; i >= 0 && temp[i] > num; i--) {
temp[i + 1] = temp[i];
}
//插入需要添加的值
temp[i + 1] = num;
//回傳
return temp;
}
}
//10萬個數的陣列,耗時:8750毫秒演算法復雜度:O(M+N)
演算法空間復雜度:O(M+N)
演算法穩定性:穩定(取決于桶內的排序演算法,這里使用的是插入排序所以是穩定的),
總結
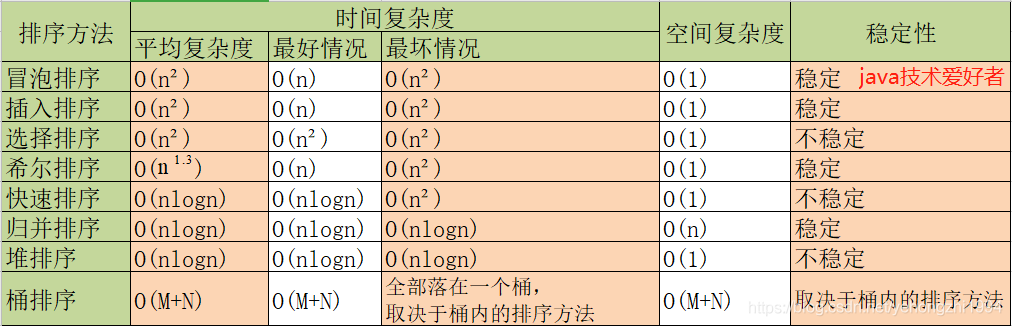
影片演示來源于演算法學習網站:https://visualgo.net
講完這些排序演算法后,可能有人會問學這些排序演算法有什么用呢,難道就為了應付筆試面試?平時開發也沒用得上這些,
我覺得我們應該換個角度來看,比如高中時我們學物理,化學,數學,那么多公式定理,現在也沒怎么用得上,但是高中課本為什么要教這些呢?
我的理解是:第一,普及一些常識性的問題,第二,鍛煉思維,提高解決問題的能力,第三,為了區分人才,
回到學排序演算法有什么用的問題上,實際上也一樣,這些最基本的排序演算法就是一些常識性的問題,作為開發者應該了解掌握,同時也鍛煉了編程思維,其中包含有雙指標,分治,遞回等等的思想,最后在面試中體現出來的就是人才的劃分,懂得這些基本的排序演算法當然要比不懂的人要更有競爭力,
原文鏈接
本文為阿里云原創內容,未經允許不得轉載,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/90599.html
標籤:其他