Hello readers, this is an in-depth discusssion about a powerful classification algorithm called K-Nearest Neighbor(KNN). I have tried my best for collecting the information so that you can understand easily. So let’s begin…
The main contents are:
- Inroduction.
- What is KNN…?
- How does KNN works…?
- The Mathematics behind KNN.
- KNN code implementation.
Introduction
The KNN algorithm is one of the most fundamental, robust and versatile classifier that is often used as a benchmark for more complex classifiers such as Artificial Neural Networks (ANN) and Support Vector Machines (SVM). Despite its simplicity, KNN can outperform more powerful classifiers and is used in a variety of applications such as economic forecasting, data compression and genetics. For example, KNN was leveraged in a 2006 study of functional genomics for the assignment of genes based on their expression profiles.
What is KNN?
Let’s start with a simple example, in the picture bellow you can see, we have a set of 2 types of animals (Horse and Dog). If you want to know about a new data-point(animal)weather it is Horse or Dog the KNN algorithm will be able to tell you based on its features (Height and Weight)
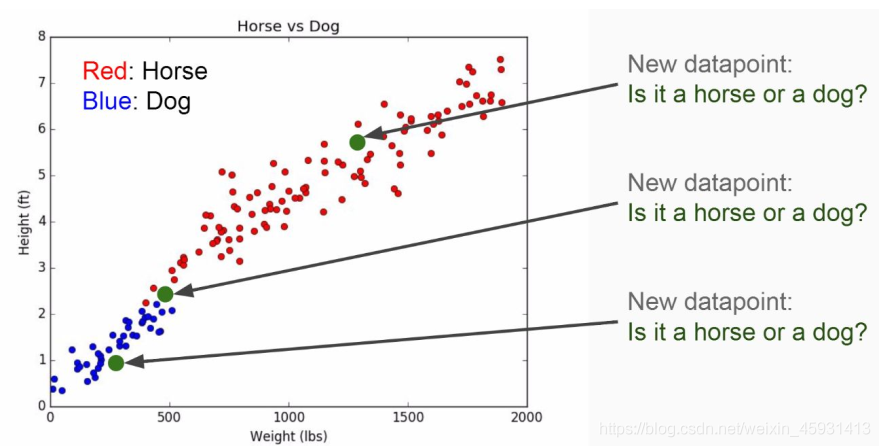
Beside that you can also think like this way, we will use x to denote a feature (aka. predictor, attribute) and y to denote the target (aka. label, class) we are trying to predict.
KNN falls in the supervised learning family of algorithms. Informally, this means we are given a labelled dataset consisting of training observations (x, y) and would like to capture the relationship between x and y. More formally, our goal is to learn a function h:X→Y, so that given an unseen observation x, h(x) can confidently predict the corresponding output y.
Some notation and defination:
The KNN classifier is also a supervised, non parametric, instance-based or lazy learning algorithm so the key notations are:
- Supervised learning is the machine learning task of learning a function that maps an input to an output based on example input-output pairs.
- Non-parametric means it makes no explicit assumptions about the functional form of h, avoiding the dangers of mismodeling the underlying distribution of the data. For example, suppose our data is highly non-Gaussian but the learning model we choose assumes a Gaussian form. In that case, our algorithm would make extremely poor predictions.
- Instance-based learning means that our algorithm doesn’t explicitly learn a model. Instead, it chooses to memorize the training instances which are subsequently used as “knowledge” for the prediction phase. Concretely, this means that only when a query to our database is made (i.e. when we ask it to predict a label given an input), will the algorithm use the training instances to spit out an answer.
- Lazy learning is a learning method in which generalization of the training data is, in theory, delayed until a query is made to the system, as opposed to eager learning, where the system tries to generalize the training data before receiving queries.
How does KNN work?
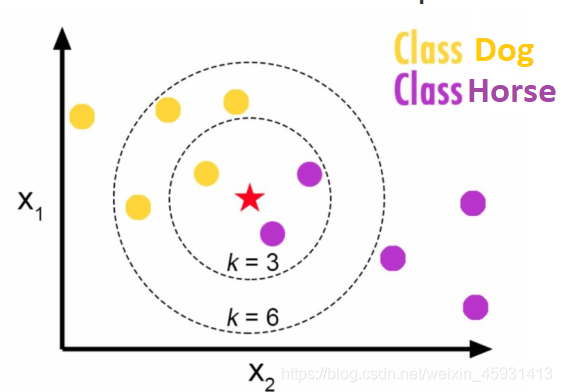
The principle behind K-Nearest Neighbor is to calculate the distance between a data-point X and all the point in the data and predict the majority label of the k closest points.
In the picture below, the red star is an animal. If we take the 3 closest points (k=3), our animal is more likely to be a horse (the probability of being a horse is 2/3). But with k=6 the new animal is more likely to be a dog (with a probability of 4/6).
The Mathematics Behind KNN
KNN works because of the deeply rooted mathematical theories it uses, when implementing KNN, the first step is transform data points into feature vectors, or their mathematical value. The algorithm then works by finding the distance between the mathematical values of their points. The most common way to find this distance is the Euclidean distance, as shown below:
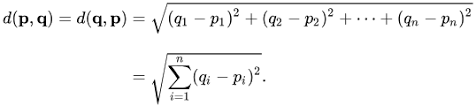
KNN runs this formula to complete the distance between each data point and the test data. It then find the probability of these points being similar to the test data and classifies it based on which points share the highest probabilities.
There are also some other algorithm like Manhattan Distance, Minkowski algorithm we can use:
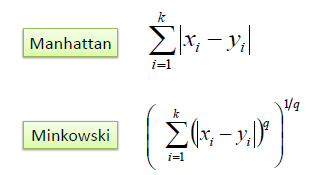
Let’s see one Example:
Consider the following data concerning credit default. Age and Loan are two numerical variables (predictors) and Default is the target.
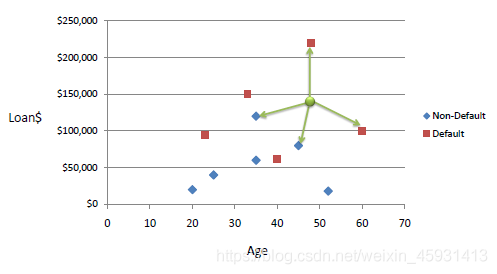
We can now use the training set to classify an unknown case (Age=48 and Loan=$142,000) using Euclidean distance. If K=1 then the nearest neighbor is the last case in the training set with Default=Y.
D = Sqrt[(48-33)^2 + (142000-150000)^2] = 8000.01 >> Default=Y
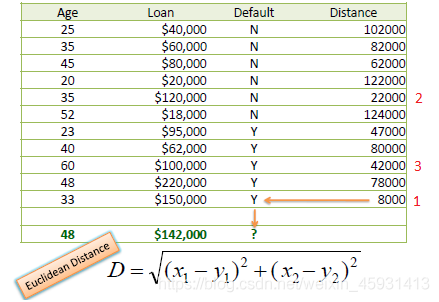
With K=3, there are two Default=Y and one Default=N out of three closest neighbors. The prediction for the unknown case is again Default=Y.
Code Implementation:
Here we are going to use the famous iris data set for our KNN example. The dataset consists of four attributes: sepal-width, sepal-length, petal-width and petal-length.These are the attributes of specific types of iris plant. The task is to predict the class to which these plants belong. There are three classes in the dataset: Iris-setosa, Iris-versicolor and Iris-virginica. Further details of the dataset are available here.
Importing Libraries:
First we need to import this librarise.
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
Importing the Dataset:
First you need to download the isirs dataset and use it like bellow:
iris =".\\iris.data.txt"
# Assign colum names to the dataset
names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'Class']
# Read dataset to pandas dataframe
dataset = pd.read_csv(iris, names=names)
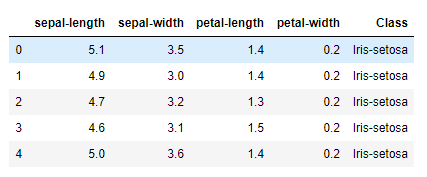
Execute the following code to see the data:
dataset.head()
Executing the above script will display the first five rows of our dataset as shown below:
Preprocessing:
X = dataset.iloc[:, :-1].values
y = dataset.iloc[:, 4].values
Train Test Split:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20)
Feature Scaling:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
Training and Predictions:
from sklearn.neighbors import KNeighborsClassifier
classifier = KNeighborsClassifier(n_neighbors=5)
classifier.fit(X_train, y_train)
Out put would be like this:
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=None, n_neighbors=5, p=2,
weights='uniform')
y_pred = classifier.predict(X_test)
Evaluating the Algorithm:
from sklearn.metrics import classification_report, confusion_matrix
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
The out put would look like this:
[[10 0 0]
[ 0 11 0]
[ 0 0 9]]
precision recall f1-score support
Iris-setosa 1.00 1.00 1.00 10
Iris-versicolor 1.00 1.00 1.00 11
Iris-virginica 1.00 1.00 1.00 9
accuracy 1.00 30
macro avg 1.00 1.00 1.00 30
weighted avg 1.00 1.00 1.00 30
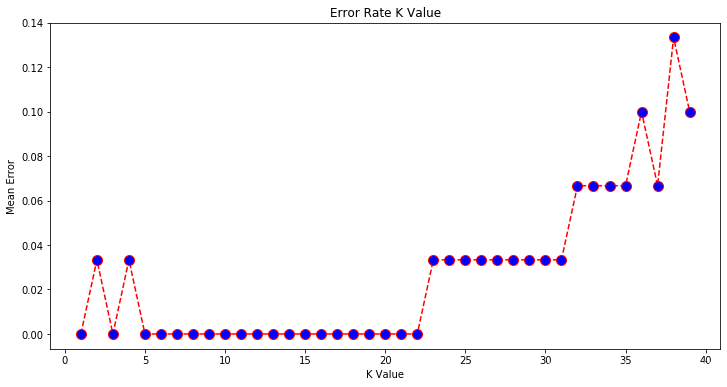
Comparing Error Rate with the K Value:
error = []
# Calculating error for K values between 1 and 40
for i in range(1, 40):
knn = KNeighborsClassifier(n_neighbors=i)
knn.fit(X_train, y_train)
pred_i = knn.predict(X_test)
error.append(np.mean(pred_i != y_test))
plt.figure(figsize=(12, 6))
plt.plot(range(1, 40), error, color='red', linestyle='dashed', marker='o',
markerfacecolor='blue', markersize=10)
plt.title('Error Rate K Value')
plt.xlabel('K Value')
plt.ylabel('Mean Error')
The out put would look like this:
Text(0, 0.5, ‘Mean Error’)
I hope you guys have understood. Thank you for reading. If I made any mistake let me know…Happy Learning…!!!
References:
I have taken help, Information, Images from the following websites you can visit these for further learning.
[1]:https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
[2]:https://www.unite.ai/what-is-k-nearest-neighbors/
[3]: https://kevinzakka.github.io/2016/07/13/k-nearest-neighbor/
[4]:https://stackabuse.com/k-nearest-neighbors-algorithm-in-python-and-scikit-learn/
[5]:https://medium.com/@kristian.roopnarine/building-a-k-nearest-neighbor-algorithm-with-the-iris-dataset-b7e76867f5d9
[6]:https://www.saedsayad.com/k_nearest_neighbors.htm
[7]:https://www.kaggle.com/canzca/k-nearest-neighbor/comments
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/121595.html
標籤:其他
上一篇:演算法競賽入門 — 素數篩