文章目錄
一、資料庫磁區、分表、分庫、分片
YesOk ,大家好 ,我是小劉,許久不見,甚是想念 ,小劉今天來帶大家學習 分庫分表的基礎知識

1.1 單機資料庫的瓶頸

- 單個表資料量越大,讀寫鎖,插入操作重新建立索引效率越低,
- 單個庫資料量太大(一個庫資料量到1T - 2T就是極限)
- 單個資料庫服務器壓力過大
- 讀寫速度遇到瓶頸(并發量幾百)
1.2 磁區
資料庫磁區是一種物理資料庫的設計技術,它的目的是為了在特定的 SQL操作中減少資料讀寫的總量以縮減回應時間,
磁區并不是生成新的資料庫表,而是將表的資料均勻分攤到不同的硬碟,系統或不同服務器存盤介子中,實際上還是一張表,另外,磁區可以做到將表的資料分攤到不同的地方,提高資料檢索的效率,降低資料庫頻繁 IO壓力值,磁區的優點如下:
- 相對于單個檔案系統或硬碟,磁區可以存盤更多的資料,
- 資料管理比較方便,如要清理或廢棄某年的資料,就可以直接洗掉該日期的磁區資料即可,
- 精準定位磁區查詢資料,不需要全表掃描查詢,大大提高檢索效率,
- 可跨多個磁區磁盤查詢,來提高查詢的吞吐量,
- 在涉及聚合函式時,很容易進行資料的合并,
1.2.1 什么時候考慮使用磁區?
- 一張表的查詢速度已經慢到影響使用的時候,
- sql經過優化
- 資料量大
- 表中的資料是分段的
- 對資料的操作往往只涉及一部分資料,而不是所有的資料
1.2.2 水平磁區
這種形式磁區是對表的行進行磁區,通過這種的方式不同分組里面的物理列分割的資料集得以組合,從而進行個體分體或集體分割,所有在表中定義的列在每個資料集中都能找到,所以表的特性得以保持,
舉例:一個包含十年發票記錄的表可以被磁區為10個不同的磁區,每個磁區包含的是其中一年的記錄,
1.2.3 垂直磁區
這種磁區方式一般來說是通過對表的垂直劃分來減少目標表的寬度,使某些特定的列被劃分到特定的磁區,每個磁區都包含了其中的列所對應的行,
舉例:一個包含了大 text和 blob列的表,這些 text和 blod列又不經常被訪問,這時候就要把這些不經常使用的 text和 blob了劃分到另一個磁區,在保證它們資料關聯性的同時還能提高訪問速度,
1.2.4 磁區實作的方式
mysql5開始支持磁區功能
創建表:
create table sales(
id int auto increment,
amount double not null,
order_day datetime not null,
primary key(id,order_day)
) engine=Innodb
設定磁區:
partition by range(year(order_day))(
partition p_2010 values less than (2000),
partition p_2011 values less than (2011),
partition p_2012 values less than (2012),
partition p_2012 values less than maxvalue
);
1.3 分表
1.3.1 什么時候考慮分表?

- 一張表的查詢速度已經慢到影響使用的時候
sql經過優化- 資料量大
- 當頻繁插入或者聯合查詢時,速度變慢
1.3.2 分表解決的問題
分表后,單表的并發能力提高了,磁盤的 IO性能也提供了,寫操作效率也提高了,
- 查詢一次的時間短了
- 資料分布在不同的檔案,磁盤
I/O性能提高 - 讀寫鎖影響的資料量變小
- 插入資料庫需要重新建立索引的資料減少
1.3.3 分表實作方式
要業務系統配合遷移升級,作業量較大
常用磁區分表的規則策略
Range(范圍)Hash(哈希)- 按照時間拆分
Hash之后按照分表個數取模- 在認證庫中保存資料庫配置,就是建立一個
DB,這個DB單獨保存user_id到DB的映射關系
1.4 分庫
1.4.1 什么時候考慮分庫?
- 單臺
DB的存盤空間不夠 - 隨著查詢量的增加單臺資料庫服務器已經沒辦法支撐
1.4.2 分庫解決的問題
其主要目的是為突破單節點資料庫服務器的 I/O 能力限制,解決資料庫擴展性問題,
1.4.3 分庫實作的方式
垂直拆分
把系統中不存在關聯關系或者需要 join的表可以放在不同的資料庫不同的服務器中, 按照業務垂直拆分,比如:可以按照業務分為資金、會員、訂單三個資料庫,
需要解決的問題:跨資料庫的事務、 join查詢等問題,
水平拆分
例如,大部分的站點,資料都是和用戶有關,那么可以根據用戶,將資料按照用戶水平拆分,
按照規則拆分,一般水平庫是在垂直分庫之后的,比如每天處理的訂單數量是海量的,可以按照一定的規則水平劃分,
需要解決的問題:資料路由、組裝,
讀寫分離
對于時效性不高的資料,可以通過讀寫分離緩解資料庫壓力,
需要解決的問題:在業務上區分哪些業務是允許一定時間延遲的,以及資料同步問題,
1.5 磁區、分表、分庫的對比
磁區就是把一張表的資料分成N個區塊,在邏輯上看最終只是一個表,但底層是由N個物理區塊組成的,分表就是把一張表按一定的規則分解成N個具有獨立存盤空間的物體表,系統讀寫時需要根據定義好的規則得到對應的字表名,然后操作它,分庫一旦分表,一個資料庫中的表會越來越多
優先級:垂直分庫–>水平分庫–>讀寫分離
1.6 拆分后面臨的新問題
- 事務的支持,分庫分表,就變成了分布式事務
join時跨庫,跨表的問題- 分庫分表,讀寫分離使用了分布式,分布式為了保證強一致性,必然帶來延遲,導致性能降低,系統的負責度降低,
解決方案:
對于不同的方式之間沒有嚴格的界限,特點不同,側重點不同,需要根據實際情況,結合每種方式的特點來進行處理,選用第三方的資料庫中間件( Atlas, Mycat, TDDL, DRDS),同時業務系統需要配合資料存盤的升級,
總結:優先考慮磁區,當磁區不能滿足需求時,開始考慮分表,合理的分表對效率的提升會優于磁區,
1.7 京東評論案例
現狀
- 商品的評論數量:數十億條
- 每天的服務呼叫:數十億次
- 每年成倍增長
整體的資料存盤:基礎資料存盤,文本存盤
基礎資料存盤
MySQL:只存盤非文本的基礎資訊,包括:評論狀態,用戶,時間等基礎資料,以及圖片,標簽,點贊等附加資訊,資料組織形式(不同的資料又可選擇不同的庫表拆分方案):
- 評論基礎資料按用戶
ID進行拆庫并拆表 - 圖片及標簽處于同一資料庫下,根據商品編號分別進行拆表
- 其它的擴展資訊資料,因資料量不大、訪問量不高,處理于同一庫下且不做分表即可
文本存盤
文本存盤(評論的內容)使用了 mongodb、 hbase
- 選擇
nosql而非mysql。 - 減輕了
mysql存盤壓力,釋放msyql,龐大的存盤也有了可靠的保障, nosql的高性能讀寫大大提升了系統的吞吐量并降低了延遲,
1.8 資料分片
在分布式存盤系統中,資料需要分散在多臺設備上,資料分片( Sharding)就是用來確定資料在多臺存盤設備上分布的技術,資料分片要達到三個目的:
- 分布均勻,即每臺設備上的資料量要盡可能相近
- 負載均衡,即每臺設備上的請求量要盡可能相近
- 擴縮容時產生的資料遷移盡可能少
資料分片方法
- 劃分號段
- 取模
- 檢索表
- 一致性哈希演算法(
Consistent Hashing)是在1997年由MIT提出的一種分布式哈希(DHT)實作演算法,設計目標是為了解決因特網的熱點(Hot Spot)問題,一致性哈希的演算法簡單而巧妙,很容易做到資料均分布,其單調性也保證了擴縮容的資料遷移是比較少的,
虛擬服務器
為了讓系統有更好的擴展性,這里提出存盤層 VServer(虛擬服務器)的概念,一個 VServer是一個邏輯上的存盤服務器,是分布式存盤系統的一個存盤單元,一臺物理設備上可以部署多個 VServer,一個 VServer支持一個寫行程和多個讀行程,
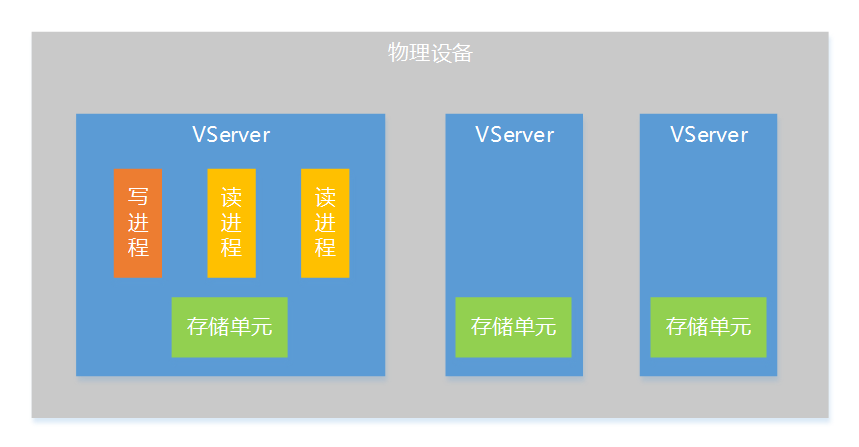
通過 VServer的方式,會有下面一些好處:
- 提高單機性能,為了不引入復雜的鎖機制,采用了單寫行程的設計,如果單機只有一個寫行程,寫并發能力會受到限制,通過
VServer方式把單機上的存盤資源(記憶體、硬碟)劃分為多個存盤單元,這樣就支持多個寫行程同時作業,大大提升單機寫并發能力, - 部署擴展性更好,
VServer的方式在部署上非常靈活,可以根據單機的資源情況來確定VServer的數量,針對不同的機型配置不同的VServer數量,這樣不同的機型都能充分利用機器上的資源,即使在一個系統中使用多種機型,也能做到機器的負載比較均衡,
二、事務的ACID和隔離級別
- 原子性(
Atomic):事務中各項操作,要么全做要么全不做,任何一項操作失敗都會導致整個事務的失敗 - 一致性(
Consistent):事務結束后系統的狀態是一致的 - 隔離性(
Isolated):并發操作的事務彼此看不到對方的中間狀態 - 持久性(
Durable):事務完成后所做的改動都會被持久化
資料庫事務并發導致的問題
- 臟讀: 事務
A讀到了事務B未提交的資料 - 可重復讀:事務
A查詢得到一行記錄row1,事務B提交修改后,事務A第二次查詢得到row1,但列內容發生了改變,側重于次數 - 幻讀:事務
A第一次查詢得到一行記錄row1,事務B提交修改后,事務A第二次查詢得到兩行記錄row1和row2,側重于insert
MySQL資料庫給我們提供的4中隔離級別
- 串行化(
Serializable):事務A多次從一張表中讀取到相同的行,禁止其他事務對這張表進行CRUD操作 - 不可重復讀(
Repeatable read):事務A可以讀取到相同的值,禁止其他事務對欄位進行更改 - 讀已提交(
Read committed):事務A只能讀取已提交的資料 - 讀未提交:(
Read uncomitted): 事務A可以讀取到未提交的資料
臟讀可重復讀幻讀串行化√√√不可重復讀√√×讀已提交√××讀未提交×××
Oracle提供3種隔離級別
讀已提交,串行化,只讀模式:只讀事務只能看到事務執行前就已經提交的資料,且事務中不能執行 insert、 update及 delete陳述句,
三、MySQL鎖機制
3.1 鎖的分類
- 從對資料操作的型別(讀/寫)分
- 讀鎖(共享鎖):針對同一份資料,多個讀操作可以同時進行而不會互相影響,
- 寫鎖(排它鎖):當前寫操作沒有完成前,它會阻斷其他寫鎖和讀鎖,
- *對資料操作的粒度分
為了盡可能資料庫的并發度,每次鎖定的資料范圍越小越好,理論上每次只鎖定當前操作的資料的方案會得到最大的并發度,但是管理鎖是很耗資源的事情(涉及獲取,檢查,釋放鎖等操作),因此資料庫系統需要在高并發回應和系統性能兩方面進行平衡,這樣就產生了"鎖粒度( Lock granularity)"的概率,
一種提高共享資源并發性的方式是讓鎖定物件更有選擇性,盡量只鎖定需要修改的部分資料,而不是所有的資源,更理想的方式是,只對會修改的資料片進行精確的鎖定,任何時候,在給定的資源上,鎖定的資料量越少,則系統的并發度越高,只要相互之間不發生沖突即可,
- 表鎖
- *行鎖
3.2 表鎖
特點:偏向 MyISAM存盤引擎,開銷小,加鎖快;無死鎖;鎖定粒度大,發生鎖沖突的概率最高,并發度最低,
案例1【加讀鎖】:
[session1]
lock table user read;
這里只能執行查詢當前表,不能查詢其他表,插入或更新當前表都會提示錯誤
unlock tables;
[session2]
在session1鎖定表后,session2能查詢或更新未鎖定的表,能查詢鎖定表,插入或者更新鎖定表會一直等待鎖被釋放,
案例1【加寫鎖】:
[session1]
lock tables user write;
這里可以對鎖定表做查詢、更新、插入操作
unlock tables;
[session2]
在session1鎖定表后,查詢、更新、插入操作均需要等到鎖被釋放,
結論:
- 對
MyISAM表的讀操作(加讀鎖),不會阻塞其他行程對同一表的讀請求,但會堵塞同一表的寫請求,只要當讀鎖釋放后,才會執行其他行程的寫操作, - 對
MyISAM表的寫操作(加寫鎖),會阻塞其他行程的對同一表的讀和寫操作,只有當寫鎖釋放后,才會執行其它行程的讀寫操作,
查看哪些表被加鎖: show open tables;
分析表鎖定: show status like 'table%';
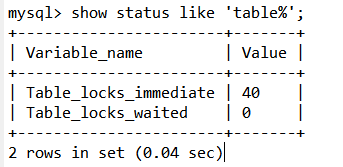
Table_locks_immediate:產生表級鎖定的次數,表示可以立即獲取鎖的查詢次數,每立即獲取鎖值加1 ;
Table_locks_waited:出現表級鎖定爭用而發生等待的次數(不能立即獲取鎖的次數,每等待一次鎖值加1),此值高則說明存在著較嚴重的表級鎖爭用情況;
Myisam的讀寫鎖調度是讀優先,這也是myisam不適合做寫為主表的引擎,因為寫鎖后,其他執行緒不能做任何操作,大量的更新會使查詢很難得到鎖,從而造成永遠阻塞
3.3 行鎖
特點:
- 偏向
InnoDB存盤引擎,開銷大,加鎖慢;鎖定粒度最小,發生鎖沖突的概率最低,并發度也最高, InnoDB和MyISAM的最大不同有兩點:一是支持事務;二是采用了行級鎖,
案例【加行鎖】
[session1]
set autocommit=0;
這里可以對鎖定表做更新操作
commit;
[session2]
在session2鎖定表后不commit時,這里對鎖定表進行update操作,會等待鎖釋放,
無索引行鎖升級為表鎖
當某個索引列沒有正常使用,如賦錯誤的型別的值,會導致行鎖變表鎖,
間隙鎖危害
間隙鎖:當我們用范圍條件而不是相等條件檢索資料,并請求共享或拍他鎖時, InnoDB會給符合條件的已有資料記錄的索引項加鎖;對于鍵值在條件范圍內但不存在的記錄,叫做"間隙( GAP)", InnoDB也會對這個"間隙"進行加鎖,這種鎖機制就是所謂的間隙鎖( Next-Key),
危害:當鎖定一個范圍鍵值之后,即使某些不存在的鍵值也會被無辜的鎖定,而造成在鎖定的時候無法插入鎖定鍵值范圍內的任何資料,在某些場景下這可能會對性能造成很大的危害,
【面試題】 如何鎖定一行
select * from user for update;
結論:
Innodb存盤引擎由于實作了行級鎖定,雖然在鎖定機制的實作方面所帶來的的性能損耗可能比表級鎖定會要更高一些,但是整體并發處理能力方面要遠遠優于 MyISAM的表級鎖定,當系統并發量較高的時候, InnoDB的整體性能和 MyISAM相比就有比較明顯的優勢了,
但是 Innodb的行級鎖定同樣也有脆弱的一面,當我們使用不當的時候,可能會讓 Innodb的整體性能表現不僅不能比 MyISAM高,甚至可能會更差,
分析行鎖定:
通過檢查 InnoDB_row_lock狀態變數來分析系統上的行鎖的爭奪情況
命令: mysql> show status like 'innodb_row_lock%';
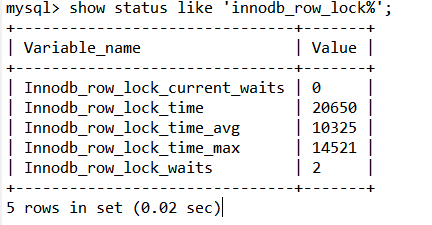
Innodb_row_lock_current_waits:當前正在等待鎖定的數量;
Innodb_row_lock_time:從系統啟動到現在鎖定總時間長度;
Innodb_row_lock_time_avg:每次等待所花平均時間;
Innodb_row_lock_time_max:從系統啟動到現在等待最常的一次所花的時間;
Innodb_row_lock_waits:系統啟動后到現在總共等待的次數;
優化建議
- 盡可能讓所有資料檢索都通過索引來完成,避免無索引行鎖升級為表鎖,
- 合理設計索引,盡量縮小鎖的范圍
- 盡可能較少檢索條件,避免間隙鎖
- 盡量控制事務大小,減少鎖定資源量和時間長度
- 盡可能低級別事務隔離
3.4 頁鎖
開銷和加鎖時間界于表鎖和行鎖之間;會出現死鎖;鎖定粒度界于表鎖和行鎖之間,并發度一般,
四、MySQL實戰問題
4.1 重復資料問題
select p1.Email from person p1 where p1.Email in (select p2.Email from person p2 where p1.Id!=p2.Id);
[優]SELECT email FROM `person` group by email HAVING count(email)>1;
[拓展]洗掉重復資料
[思路]根據重復資料進行分組,然后查出最小的id,洗掉其他之外的id行,這里得創建一個臨時表,
在mysql中,不能在一條Sql陳述句中,即查詢這些資料,同時修改這些資料
DELETE from person where id not in( select temp.id from (SELECT min(id) id FROM person group by email)as temp);
注意:這里在mysql5.7以上版本會報錯,因為不支持select那些group by和聚合函式之外的欄位
4.2 索引創建和查看
創建: create index idx_a_b on table(col_a,col_b);
查看: show index from table;
4.3 where 1=1和where 1=0的意義
where 1=1用于拼接多條件陳述句時,這樣就不用管條件是否存在,拼 where還是拼 and,
where1=0不回傳資料,僅回傳結構,用于快熟建表,
微信搜一搜 : 全堆疊小劉 ,獲取文章 pdf 版本
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/204537.html
標籤:架構設計