文章目錄
- 一、總覽
- 1.1 MySQL架構
- 1.2 SQL陳述句的執行流程
- 二、各組件的功能
- 2.1 連接器
- 2.2 分析器
- 2.3 優化器
- 2.4 執行器
- 三、陳述句分析(**)
- 先where還是先join?
- 總結
- 四、索引是如何起作用的
- 4.1 MySQL執行計劃決議
- 4.2 優化器是如何找到索引的?
- 4.3 優化器是如何選擇索引的?
- 五、索引的優化
一、總覽
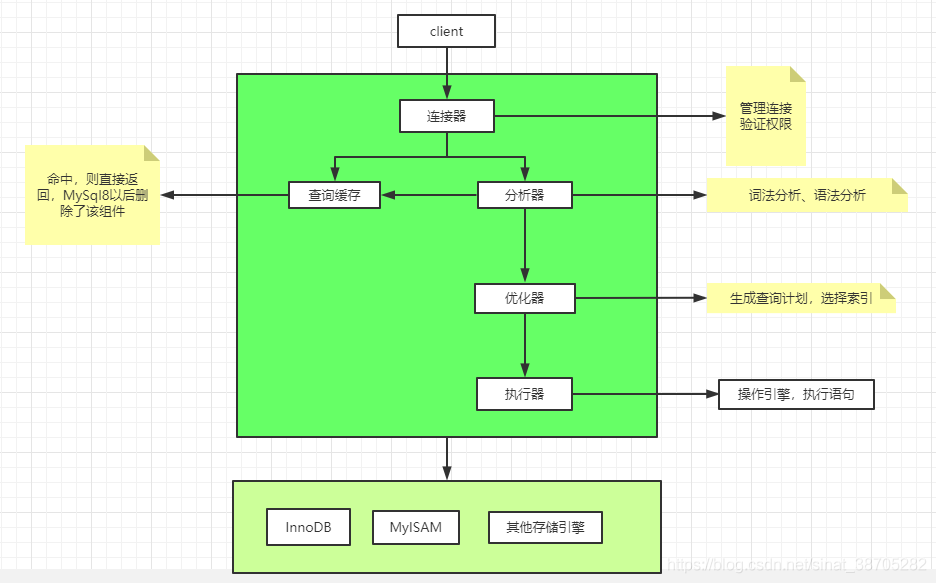
1.1 MySQL架構
1.2 SQL陳述句的執行流程
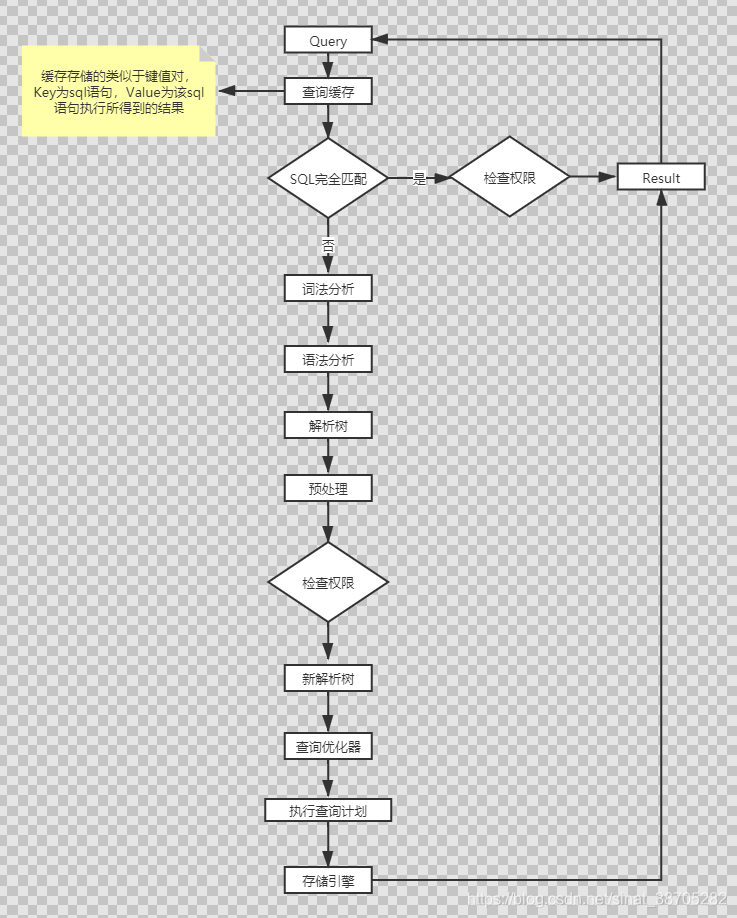
二、各組件的功能
2.1 連接器
連接器負責與客戶端建立連接、獲取權限、維持和管理連接,
用戶創建會話時,會檢查用戶的用戶名和密碼,驗證通過后會查詢權限表,得到該用戶的所有權限,
2.2 分析器
當用戶發送sql陳述句進行資料庫操作時,分析器負責對這條sql進行詞法分析、語法分析、語意分析,
- 詞法分析:將關鍵字識別出來,將查詢條件、欄位等都提取出來,
- 語法分析:判斷當前sql陳述句是否符合語法
- 語意分析:判斷查找的表是否存在、要操作的欄位是否存在等等
2.3 優化器
主要進行執行方案的選擇,會選擇用不用索引,用哪個索引等等,
2.4 執行器
呼叫資料庫引擎的介面,執行sql,
- 首先判斷用戶是否有對當前表的操作權限
- 然后呼叫引擎介面去執行sql
三、陳述句分析(**)
select * from a left join b on a.id = b.id
where a.sex = "男"
group by a.age
having a.age > 16
order by a.age
//該sql的實際執行順序是:所以這也就是為什么要小表驅動大表
//(Mysql采用了嵌套回圈的方式),小表在前,可以減少兩張表的連接次數
from a
on a.id = b.id
left join b
where a.sex = "男"
group by a.age
having a.age > 16
select
order by a.age
a表:
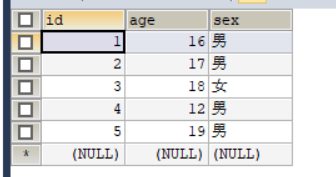
b表:
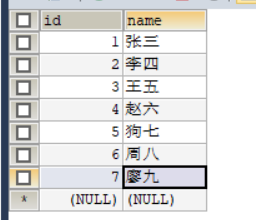
結果:
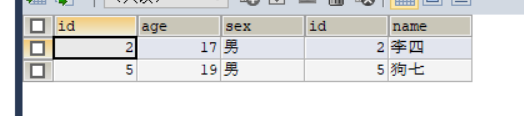
查詢計劃:

樹狀查詢計劃:
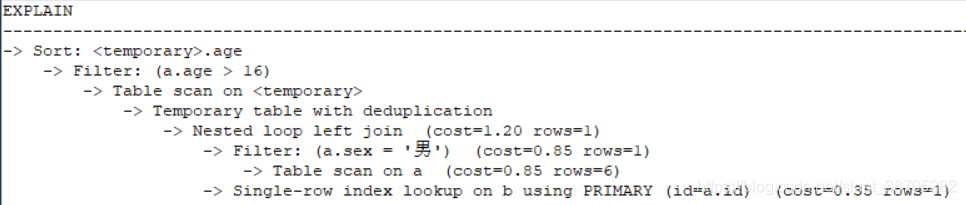
首先:(由于mysql采取了嵌套回圈的形式)
一般sql陳述句的大致執行流程:
//偽代碼形式(僅join部分)
遍歷左表的每一行{
Boolean b = false;
遍歷右表,尋找滿足條件的行{
如果滿足where條件{
合并結果并輸出
}
}
b = true;//說明有滿足的行
if(!b){
說明沒有和當前的左表行匹配的右表行
使用NULL填充
}
}
但是我們看查詢計劃,好像是先用where過濾掉了 a.sex = "女"的記錄,然后再和b表進行的join,這是為什么呢?到底是先where還是先join呢?
先where還是先join?
我的理解是:這是因為當前a是驅動表,也就是左表,而where條件又是左表的過濾條件,此時先join后where得到的結果和先where后join得到的結果是一樣的,此時優化器會先把左表的where條件對左表進行過濾,減少和右表join的次數,此時如果先join,那么得到所有記錄,a.sex = "女"的依然還是要過濾掉,但這樣會白白進行幾次記錄的合并(做了無用功),所以當where條件是驅動表的過濾條件時,會先對驅動表進行where,然后再進行join (邏輯上還是可以認為是先join,后where)
但如果where條件是右表的,那么就需要先join,后where了,因為如果先where的話,會導致邏輯錯誤,因為只有滿足a.id = b.id的記錄才會進行合并,如果先用where把一部分記錄給過濾掉,那么和a進行合并的時候就會導致很多原本a.id和b.id相等的記錄沒法合并(b.id對應的那條記錄被where過濾掉了),所以要先join,再通過where條件對b進行過濾
EG:
我們改變a,b兩張表:
a表:
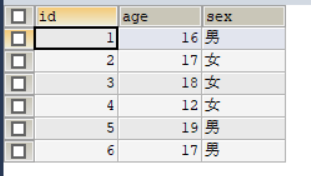
b表:
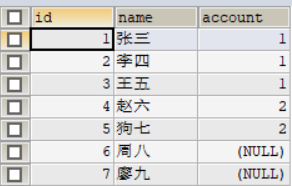
sql陳述句:
SELECT * FROM a LEFT JOIN b ON a.id = b.id AND a.sex = "男"
WHERE b.name IS NOT NULL
結果:

查詢計劃:

我們可以看到先掃描a表,然后通過join on 里的a.sex 過濾掉了性別為"女"的記錄,然后通過id查找對應b記錄,最后才通過where條件的 b.name is not null進行過濾,
如果先執行where 會怎么樣呢? 因為b表里面沒有任何一條記錄的name欄位是NULL,這樣在join的時候相當于where不起作用,
總結
對于任何一條sql,如果存在join,其執行邏輯都是先進行join,再用where過濾,只是當where條件為過濾驅動表(左表)記錄的條件時,mysql會進行優化,使得where先于join執行以提升效率,如果where的條件是被驅動表(右表),那么此時where必須要在join后執行,此外,mysql使用的嵌套查詢,還會優化使用index嵌套查詢,即與被驅動表連接的時候,會先訪問被驅動表對應的索引以提高效率,
所以最開始的那條SQL陳述句結合執行計劃的流程為:
sql陳述句:
select * from a left join b on a.id = b.id
where a.sex = "男"
group by a.age
having a.age > 16
order by a.age
- 全表掃描a(因為sex欄位沒有索引),得到所有性別為男的記錄,然后根據這些記錄的a.id去b表查找滿足a.id = b.id 條件的列 (b是根據id找的,使用聚簇索引,所以為eq_ref,表示根據a的每一行資料,回傳b的一條資料),進行合并
- 然后進行group by
- 再通過having條件過濾
- 再進行sort排序(這里sort 排序是起作用的,下面的sql陳述句 sort排序不起作用)
- 如果有limit引數,則從排序好的結果中取limit限制地數目回傳,
如果我們在age上添加一個索引,然后改變sql陳述句為
EXPLAIN
SELECT * FROM a LEFT JOIN b ON a.id = b.id
WHERE a.age > 16
GROUP BY a.age
HAVING a.sex = "男"
order by a.age
查詢結果是一樣的:

但是執行計劃卻不同,這里會使用到索引:

添加 format = tree查看樹狀的執行計劃:

這里的執行程序為:
- 先掃描a表通過age這個索引查詢出age>16的所有a表的記錄
- 再根據這些記錄的id去b表中查詢id相等的記錄進行合并
- 完成left join
- 再group by
- 再執行having過濾
- 這里order by不起作用,因為group by已經對age進行分組并排序了,所以優化器會將無用的order by陳述句給去掉,
四、索引是如何起作用的
4.1 MySQL執行計劃決議
這部分的博客太多太多了,這篇我覺得很詳細:
你確定你讀懂了 MySQL 執行計劃嗎?
4.2 優化器是如何找到索引的?
InnoDB引擎會有一個xxx.ibd檔案,資料和索引都在該檔案中,所以查詢某個表時,就可以根據這個檔案得到與該表有關的所有索引,
4.3 優化器是如何選擇索引的?
MySQL 優化器原來是這樣作業的
五、索引的優化
索引創建的情形:
- 經常出現在where或者order by中的欄位
- 多表連接查詢的關聯欄位或者外鍵涉及的欄位
- group by的欄位
注意:有時候使用索引沒有全表掃描高,這是因為當使用的是輔助索引時,需要回表,當表中資料很少時,輔助索引的回表操作導致IO次數變多,
索引的優化原則:
-
對區分度比較大的欄位創建索引,即不怎么重復的,如果是重復性比較高的欄位,例如性別,只有男和女,給這樣的欄位加索引,效果不大,
-
最左前綴:當我們創建復合索引時,要使用索引,必須從定義的第一個索引列開始才能匹配索引,即對表a創建復合索引(name,age),那么要讓索引生效,我們在查詢時,要name在age前才可以應用到索引,這是因為B+樹的節點存盤的資料形式為(name,age),即(name,age)是有序的,單獨看name也是有序的,但是age不一定有序,只有當name相同時,age才有序,所以只有當name在age前面時索引才有效,如果想單獨age也可以使用索引,那么需要單獨為age創建一個索引,這樣的話索引數目變多,當更新或者插入時,維護索引的成本就增加了,
//在a表上創建復合索引 (name,age) //會用到索引 select * from a where name = xxx and age = xxx select * from a where name = xxx //索引不生效 select * from a where age = xxx -
索引列上不要做任何操作(計算、函式、型別轉換),會導致索引失效
//索引依然為name和age select * from a where lower(name) = "aaa" //因為對name使用了函式lower,而索引中沒有lower(name)相關的資料 //如果我們創建一個函式索引,那么該查詢可以使用索引 //eg:create unique index lower_name on a(lower(name)) -
范圍查詢盡量放到最右邊,即最后,因為范圍查詢后面的欄位,即便有索引也不會生效
//假設在a表上創建復合索引(name,age,account) //name和age會應用到索引,account不會應用索引 select * from a where name = xxx and age > 16 and account = xxx //應用到三個索引 select * from a where name = xxx and account = xx and age >16 -
盡量使用覆寫索引:即要查詢的列是索引列,這樣可以不用回表,例如表a,我在name和age兩列加了索引,當進行select name,age from a where age > 16這類陳述句,只查詢name、age兩個輔助索引就可以得到結果,不需要再回表,效率提升,
//即要查詢的資訊在輔助索引中即可以找到 //雖然用到了索引,但需要回表,因為還有一些別的資訊,輔助索引找不到, //例如sex等 select * from a where name = xxx and age > 16 //不需要回表 //因為輔助索引中含有name和age資訊 select name,age from a where name = xxx and age >16 -
可以使用索引來避免排序,可以將排序欄位也加入到索引中,group by同理
-
like以通配符開頭也會使得索引失效,所以最好通配符放在右邊,但如果查詢欄位剛好覆寫索引,那么會進行索引上的全表掃描,即型別為index,
-
盡量少使用or,or連接的欄位,只要有一個沒有索引,那么就不會走索引,只有當or連接的欄位都單獨建立了索引,才會走索引,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/236566.html
標籤:其他
上一篇:48v磁吸燈芯片調光調色無頻閃易過3C認證方案設計分析
下一篇:關于redis