??Presto 是由 Facebook 開發的開源大資料分布式高性能 SQL 查詢引擎; 它被設計為用來專門進行高速、實時的資料分析,以彌補 Hive 在速度和對接多種資料源上的短板;專門為互動式查詢所設計,提供分鐘級乃至亞秒級低延時的查詢性能,
1.1 Presto 架構
??Presto 是典型的 MPP 架構,由一個 Coordinator 和多個 Worker 組成,其中 Coordinator 負責 SQL 的決議和調度,Worker 負責任務的具體執行,可配置多個不同型別的 Catalog,實作對多個資料源的訪問,
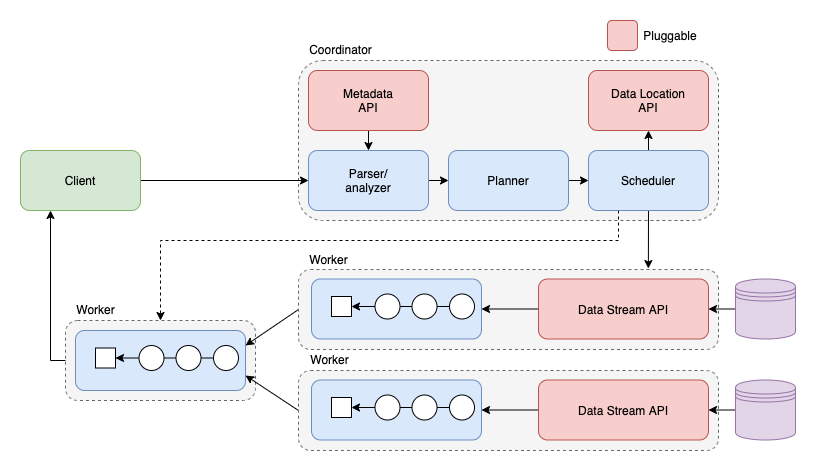
1.2 Presto 執行查詢程序
- Client 發送請求給 Coordinator,
- SQL 通過 ANTLR 進行決議生成 AST,
- AST 通過元資料進行語意決議,
- 語意決議后的資料生成邏輯執行計劃,并且通過規則進行優化,
- 切分邏輯執行計劃為不同 Stage,并調度 Worker 節點去生成 Task,
- Task 生成相應物理執行計劃,
- 調度完后根據調度結果 Coordinator 將 Stage 串聯起來,
- Worker 執行相應的物理執行計劃,
- Client 不斷地向 Coordinator 拉取查詢結果,Coordinator 從最侄訓聚輸出的 Worker 節點拉取查詢結果,
1.3 Presto 為何高性能
- Pipeline, 全記憶體計算,
- SQL 查詢計劃規則優化,
- 動態代碼生成技術,
- 資料調度本地化,注重記憶體開銷效率,優化資料結構,Cache,非精確查詢等其它技術,
1.4 Presto優化
-
Coordinator 節點不作為計算節點,只作為協調節點;
-
每臺物理機只部署一個 Presto 節點,無其他任何競爭服務;
-
JVM 配置為 G1 回收器、最大堆記憶體為物理記憶體的 75%;
-
設定堆外記憶體最大使用量 MaxDirectMemorySize;
-
設定 glibc 的引數 export MALLOC_ARENA_MAX=1 ;
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/240988.html
標籤:其他