前言
最近騰訊游戲學院發布了一些游戲行業內大佬們的分享視頻,觀看這些視頻,我們可以了解到行業內最新的一些技術知識等,以便提升自己的水平,之前也看到天刀手游是基于Unity制作的,同時自己也作為一名天刀游戲的玩家,碰見看見有關天刀手游的技術分享,因此必然要學習學習,了解大佬們的核心先進技術,
鏈接:https://www.bilibili.com/video/BV1EZ4y137db?p=6
本文目前基本僅僅只是對視頻的內容的抄錄,因為視頻大部分提到的知識都沒有接觸過(唉!),無法跟進一步的拓展來說,以后有時間一定好好研究一番,同時若后續專案需要,也可以以此作為一個研究方向的參考,
手游研發的三要素
畫質,幀率,功耗(pc可以不考慮),三者協調,例如當我們的幀率達到一個預估值后,我們可以再努力提升畫質,當畫質提升后,必然會造成幀率的下降以及功耗的提升,因此我們需要再優化幀率以及功耗,通過這種方式來達到三者平衡以及不斷的拔高,

利用各種技術堆疊來優化
在游戲開發中,我們往往需要各種優化來提升性能,這點是非常非常重要的,視頻中的大部分內容介紹的也就是如果通過各種技術堆疊,來獲得更好的優化效果,

天刀手游主要用到了如下幾個技術點來進行優化:
- 對多執行緒渲染引擎,進行優化,把大部分可以并行的作業,比如影片、布料,放到其他的執行緒去運行,
- 使用ISPC,來自動生成NeonSIMD的代碼,這部分代碼可以更好地提升CPU的執行效率,
- 在GPU和CPU的遮擋剔除中,使用不同粒度的遮擋剔除演算法,首先啟用了Vulkan API,通過它來對GPU的記憶體進行更好的粒度上的管理,
- 實作了GPU Driven的渲染管線,用compute來輔助優化各項其他的渲染技術,
- 在畫面上使用了PBR的材質,使用了真實的物理單位的lighting,獲得更好的HDR的畫面效果,
在開發程序中,經歷了多執行緒的優化,發現了在做手機平臺上的一個優化甜區,即手機的多核要比我們在端游時代開發的時候更早的進入了多核時代,現在很多安卓手機都是4+4的多核架構(像更早時候在主機平臺上看到的,如xbox360,ps3),在這些架構下,都是以能讓開發者更多的使用這些輔助的計算單元,來提升計算效率,因此有兩個大方向:
- 盡可能剝離主執行緒上的計算,通過dispatch到小核上,dispatch到其他執行緒上,來提升它的計算效率,
- 把計算轉入GPU Compute,
做優化時,團隊要有一個非常好的基礎,這個基礎來源于我們在于從多執行緒開始,意識到整個計算體系,應該不同的去往compute方向,或者往其他執行緒方向去使用,通過減少主執行緒的開銷成本,來去提升整個游戲的性能效率,
多執行緒的框架改動
對Unity進行了多執行緒的框架改動,把渲染執行緒和提交執行緒從主執行緒中剝離出來,因為在手游的開發環境里,一個主執行緒的持續作業會帶來手機芯片的功率提升,這會帶來更多的發熱,
Vulkan API
官網:https://www.khronos.org/vulkan/
相關文獻:https://vkguide.dev/
Vulkan是數字圖形技術產業誕生的一個全新圖形介面專案,它類似于OpenGL和Direct3D,并且在某些領域上要優于這兩者,Vulkan針對高性能的實時3D應用,如跨平臺的各類3D游戲和互動軟體,并提供更好的性能和更低的CPU占用率,而且在多核CPU協同負載運行更加優秀,
天刀手游也引入了Vulkan API,它相對于OpenGLES來說的話,有著更好的,更輕量級的呼叫,進過他們的測驗,可以做到在提交執行緒上獲得30%的CPU的效率提升,
同時Vulkan API是更加自由的開發方式,可以在其中進行各種各樣的優化,例如對一些比較重的Vulkan API操作,像Descriptor Set的系結,Layout的系結,都可以采用一些Cache的方式來去做,Vulkan API的靈活性可以使得開發時獲得更好的解法,
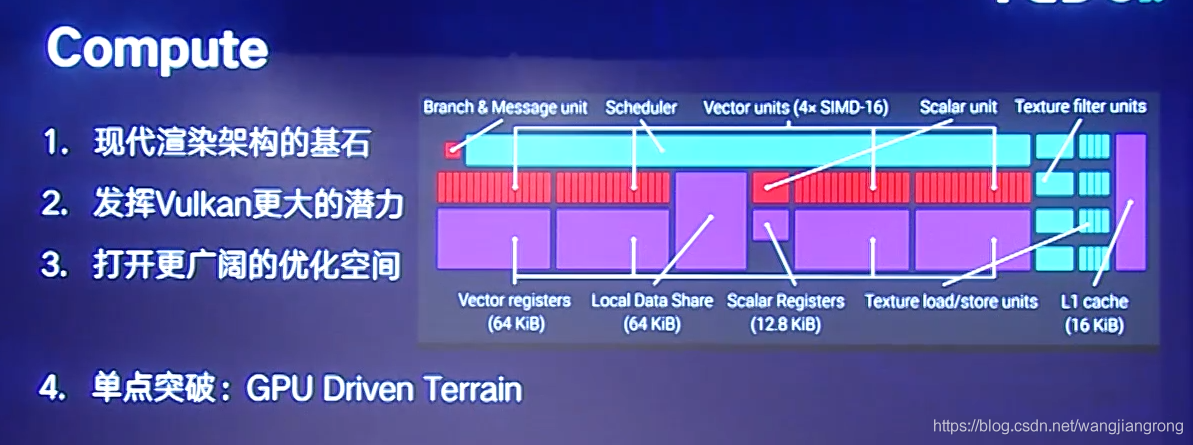
GPU Compute
GPU Compute即Compute Shader,在它的幫助下,程式員可直接將GPU作為并行處理器加以利用,GPU將不僅具有3D渲染能力,也具有其他的運算能力,在前面的Vulkan以及后面的GPU Driven的相關文獻中,都有所介紹,
視頻中的解讀如下:
- 它首先是一個現代渲染框架的一個基石,除了GPU進行光柵化處理的部分之外,compute能夠完成大量的GPU的渲染流程上的操作,包括計算光照,計算材質等等,另外值得注意的是,compute的渲染語言,其實是完全能和GPU本身的硬體對應起來,例如Local Data Storage機制,例如ThreadGroup和Thread利用率的概念,這兩個都能很好的在compute語言上表現出來,
- 使用compute能夠發揮Vulkan更大的潛力,因為我們可以使用Vulkan對GPU的同步行為做出非常好的控制,而compute作為一個獨立的單元,我們可以把compute的計算很好的和GPU的其他計算并行起來,例如compute可以和一個帶寬優先的(像shadow pass)進行并行,另外compute是一個單獨的Queue,我們可以對比vs和ps的整套pipeline來說,它是一個非常簡化的單元,非常容易到處去擺放的,
- 采用compute的話,可以給GPU Driven和Bindless打開更廣闊的優化空間,我們甚至可以使用Async compute的方式來更進一步的并行compute和GPU的單元,
- 對天刀手游而言,打開compute的關鍵突破點就是GPU Driven的地形系統,
GPU Driven
參考文獻:https://www.raywenderlich.com/books/metal-by-tutorials/v2.0/chapters/15-gpu-driven-rendering#toc-chapter-018-anchor-001
https://zhuanlan.zhihu.com/p/37084925
天刀手游同時也引入了GPU Driven的技術,通過它可以把大部分CPU上的作業轉移到GPU上去運行,不僅提升了GPU的效率,也減少了從GPU到CPU之間的各種傳遞的帶寬,這項技術可以運用在地形上,以及草和植被上,同時在家園里也運用了這些效果,
何為GPU Driven Pipeline?
首先是GPU掌握實際的渲染控制,可以提供更細致的渲染力度,例如我們在做渲染剔除的時候,CPU只能控制在object level,使用Object Bounding來去做剔除,我們在GPU這個層面上,可以做到更進一步的控制,我們可以在Mesh cluster級別上,通過切分Mesh來獲得更好的力度控制,
另外一個好處是,它不需要GPU和CPU之間的資料來回傳遞,在理想情況下,GPU Driven甚至可以使用一個drawcall來繪制完整個場景,當然了,這個需要compute shader的支持以及indirect drawing相關api的提供,在Vulkan1.0的情況下都可以拿到相關的支持,

行業發展
在最近幾年里,GPU Driven其實是一個相對來說比較熱門的研發方向,以下是歷年來的一些參考文獻:
- siggraph15 <GPU-Driven Rendering Pipelines> ubisoft:主要是講《刺客信條:大革命》的開發,
- gdc16 <Optimizing the Graphics Pipeline With Compute> EA frostbite:EA的寒霜引擎(Frostbite Engine)也提到了GPU Driven的pipeline,
- gdc18 <Terrain Rendering in "Far Cry 5"> ubisoft
- gdc19 <GPU Driven Rendering and Virtual Texturing in "Trials Rising"> ubisoft
但是在手機的領域上,目前還沒有一些技術能夠真正在在線的產品中體現出來,

天刀手游中的運用
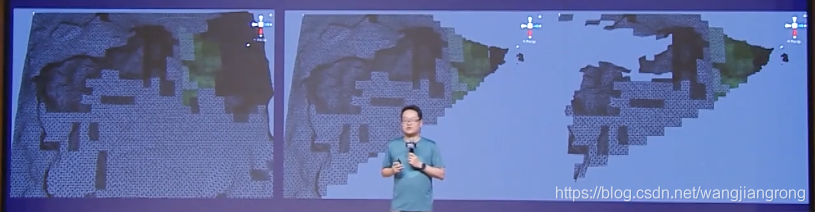
首先介紹下CPU地形常用的演算法,在天刀手游上個版本里的地形演算法是CPU端的Geometry Clipmap演算法,它采用的裁剪剔除方式是視錐的裁剪剔除方式,對比GPU Driven來說的話,它少了depth剔除,并且它的計算LOD的方式是根據距離計算的,而GPU Driven可以根據距離和地形塊的復雜度來計算,送入clipmap方式的頂點處,因為有兩個pass,其中一個要通過Virtual Texture來使用,這樣的話它是需要21萬*2的頂點數,而GPU Driven情況下,因為獲得比較好的剔除效果,它只需要8萬6的頂點數,
此外,在GPU Driven情況下在iphone8p上可以獲得2.9ms的時間開銷,這比通過CPU的方式下,節省了近四分之一的成本,而在CPU端獲得的收益更大,我們提交執行緒和渲染執行緒,每個都可以獲得5ms以上的收益,
下圖即是兩者的對比:

使用流程
它主要包含GPU Driven和Virtual Texture兩個演算法,它們的實作有著互相的交叉,出于簡化,視頻只介紹一下GPU Driven相關流程上的一些演算法,
- 首先是一個深度的mips生成,這部分演算法是在compute里面實作的,
- 其次我們在compute里面實作GPU遮擋剔除,使用上一步制作的深度緩沖buffer,GPU的遮擋剔除主要是通過計算你送入的patche的尺寸,看它處在哪一級的深度緩沖上,然后來對比這一級深度緩沖的深度和你的深度,來決定是否被depth剔除掉,
- 通過這個流程我們可以獲得可視的patches數目,然后根據這些可視的patches數目,仍然通過compute用來做indirect的Arguments的buffer來生成出來,
- 將這些準備好的indirect buffer給繪制出去,

Hiz Buffer(Hierarchical Z-Buffer)Occlusion Culling 優化
有一個非常重要的優化,也是在compute上可以達成的,該優化主要是利用compute里面的一個Thread shared memory的方式來做,這個優化它減少了對于CPU和GPU之間的多次的dispatch,減少了binding memory pingpong操作,它能應用的范圍主要在于對你的buffer做filter,例如我們經常在渲染管線中提到的bloom,高斯模糊以及自動曝光等,這些對于區域進行filter的操作都可以獲得優化,
應用
首先會做第一次的dispatch,這個dispatch會產生16*16的執行緒組,每組128條執行緒,我們這128條執行緒讀入深度放入mips里,
第二步通過同步的方式,再把上一級的mips相鄰的四個點取出來,合并選擇最深的單位,寫到第二級的mips里,然后以此類推,完成四級的寫出,
在第二個dispatch里,用同樣的方法,dispatch一個執行緒組,128條執行緒,同樣的把后面的32*16的mips寫入完成,

LOD優化
在Farcry的實作里面,它主要采用的是CPU四叉樹的方式來組織LOD的patches,根據距離更新四叉樹上的節點,然后根據相機的距離選擇這些節點,送入GPU進行indirect buffer和GPU Culling,
對于天刀手游來說,我們把這些patch資訊先通過offline的方式bake出來,我們在每個相機發生位置變化的時候,會去更新這些bake出來的資訊,根據這些資訊,我們會去對改變的patch做過濾,然后生成新的indirect buffer,

應用
第一步,讀到了所有的patches的屬性,
第二步,根據視錐裁剪,獲得視錐裁剪之后的結果,
第三步,再用HiZ產生的depth,產生一次depth裁剪,
這三步完成后,我們就可以生成Indirect Draw Arguments的buffer,將其dispatch出去,
GPU Driven的其他應用
除了地形以外,GPU Driven還可以應用在草地以及家園等系統中,
應用 Grass(場景的植被管理)
有經驗的渲染程式可能直接會意識到這一點,草的geometry和地形的patch或者是sector的管理是一個非常類似的概念,他們都有LOD,都有不同的geometry的表現,繪制這些geometry LOD的時候,最好的方法是通過Multi Draw Instanced Indirect的方案來做,
另外一點這些草的Texture,每種草的Texture它其實對應在地形上更像是一個地形的Virtual Texture機制,我們也可以用bindless的方式去做系結,可是在Vulkan 1.0 的平臺情況下,我們這兩個API,Multi Draw Instanced Indirect或者是bindless,都沒辦法獲得更好的支持,因此在天刀手游的實作里,我們只能采用將草的每種型別完成一次GPU Driven的culling和Draw Indirect Buffer的生成,

應用家園渲染
在家園的玩法里頭,主要是可以讓玩家盡可能多的定制我們整個家園的地形,地表,墻壁,物件,地板等等,在這個層面上,我們知道,它其實是需求非常多的geometry型別,第二它的區域相對來說比較小,只有128m*128m的自定義空間,而在這種小的自定義空間的情況下,遮擋剔除必須要做的非常好的一種技術,這兩點來看,GPU Driven非常非常的適合應用在家園渲染的情況下,
問題在于家園里的這些物件其實和草的型別一樣,都非常依賴于Multi Draw Instanced Indirect和bindless這兩種api的實作,對天刀手游來說只能退而求其次,利用地形步驟算出來的HiZ buffer做遮擋剔除,我們送入一套做遮擋剔除buffer的內容,然后通過CPU從readback的方案來獲得這些buffer的遮擋剔除結果,然后在CPU端組織盡量多的instance物件,即使采用這樣的方式,在家園渲染情況下,也獲得了比較好的渲染效率,

光照的優化
修改和提升了整體的光照表達,引入了自動曝光,提升了Tone mapping(把HDR變成LDR的程序)的效果,解決了由于真實物理單位引入之后,在不同的光斬訓境下lighting體現的一些細節的顏色丟失的問題,并且重新對sky lighting進行了定義,使得整個場景的室外表現更加豐富和具有對比度,
Compute的嘗試
在完成了compute的基礎機制上,進行了其他的嘗試,其中一條是,完成了在ASTC和PVRTC的GPU實時壓縮,這個也是通過GPU compute來實作的,這個功能可以用在角色的妝容系統上,
妝容系統
在天刀手游中,整個角色他的妝容系統是需要完成多個Feature的繪制,如果不能很好的baking到一張貼圖上,在實時渲染的情況下,它會產生更多的一些開銷,在實時baking到貼圖上,我們還希望它能夠盡量去做壓縮,來減少記憶體的使用,測驗了一些compute compression的效果,在PSNR和效率上都能獲得比較好的表現

嘗試Virtual Texture Compression
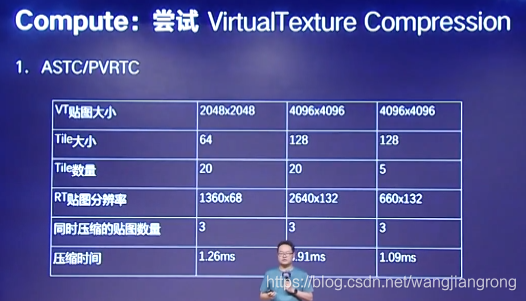
嘗試了對于Virtual Texture的壓縮,前面提到地形的Virtual Texture技術,是需要更新大量的地形塊資料,越多的地形塊資料,才能使你更新的頻率變低,
在天刀手游中,我們使用2048*2048,三張不經壓縮的材質,我們通過調整貼圖的尺寸,大小,數量以及壓縮方式,基本上能夠把大張貼圖的壓縮時間控制在4ms以下,可以達到使用的效果,

遠處來看,地表材質很難觀察到差異性,這種演算法對比了一下它的細節表現,我們仍然可以看到壓縮后是有一些Blocking的瑕疵(如下圖),這樣的瑕疵在天刀手游的畫面品質下是不能接受的,因此該方案被放棄,

嘗試Cluster deferred
嘗試了Cluster deferred,它主要應用于家園室內場景,該場景,它首先是一個封閉的空間,有大量的動態的物體,動態的光照效果,下圖中的圖片中大概有55盞燈,從左上角的一張藍色背景圖來看這個區域被多少光源照亮的情況,最多的話可能是8盞燈以上的照亮,
在這個技術方案實作之后,發現仍然解決不了幾個問題
第一個問題就是deferred本身帶有的問題,即它的帶寬問題,需要更好的設計GBuffer擱置,也需要去應用一些API,例如subpass,或者一些更好的pass combine的操作,
第二個問題在于它材質的復雜度,一個deferred的材質和forward的材質,在整個大世界的使用,是很難做兼容融合的,這個也增大了shader的復雜度以及作業量,
這個方向對未來也許是一個比較好的技術點,但是在現有的架構下還是不夠成熟,該方案也被放棄,

轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/246151.html
標籤:其他
上一篇:Kafka檔案存盤機制
下一篇:小說網站搭建與采集詳解