前言
對于回圈依賴,我相信讀者無論只是聽過也好,還是有過了解也好,至少都有所接觸,但是我發現目前許多博客對于回圈依賴的講解并不清楚,都提到了Spring的回圈依賴解決方案是三級快取,但是三級快取每一級的作用是什么,為什么要這樣設計三級快取,很多博客都沒有提到,為了讓大家能夠更加清晰的理解Spring的回圈依賴,下面我便帶領大家從Spring原始碼的角度出發,講解Spring回圈依賴的整個流程以及其解決方案 —— 三級快取的作用,
提示
此文章建議讀者先閱讀一下Spring創建bean流程的代碼,這樣再讀這篇文章體會會明顯一些
若是讀者就想知道結論,建議直接從目錄四開始看
若是讀者已經知道Spring創建bean的流程,那也建議直接從目錄四開始看
文章瀏覽目錄
- 一、首先說明什么是回圈依賴
- 二、回圈依賴三級快取以及整個流程介紹
- 三、原始碼敘述Spring回圈依賴
- 四、重點說明getSingleton(String) 和 addSingletonFactory(String, ObjectFactory)
- 五、總結
一、首先說明什么是回圈依賴
比如,現在有兩個類,OrderService和UserService(下面文章中我們簡稱其為os和us,并且就以這兩個類作為演示),所謂的Spring回圈依賴就是在os中依賴了us,us中依賴了os,按照正常的流程來說:
- Spring根據字典序優先創建os的bean,但是容器中沒有os的bean,便創建os的bean
- 在創建os的程序中發現需要屬性注入us,然而容器中也沒有us的bean,這時便開始創建us
- 創建us的程序中其發現需要屬性注入os,容器中也沒有存放os的bean,就又開始創建os…
如此便進入了死回圈中,但是Spring中是否真是如此呢?我們來代碼演示一下:
這里是 os類,其中依賴了us
@Component
public class OrderService {
@Autowired
private UserService userService;
public OrderService(){
System.out.println("start orderService");
}
}
這里是 us類,其中依賴了os
@Component
public class UserService {
@Autowired
private OrderService orderService;
public UserService(){
System.out.println("start userService");
}
}
這里是測驗類
public class Test {
public static void main(String[] args) throws Exception {
AnnotationConfigApplicationContext ac =
new AnnotationConfigApplicationContext();
ac.register(Appconfig.class);
ac.refresh();
//關倍訓圈依賴
// ac.setAllowCircularReferences(false);
System.out.println(ac.getBean(OrderService.class));
System.out.println(ac.getBean(UserService.class));
}
}
運行結果如下:
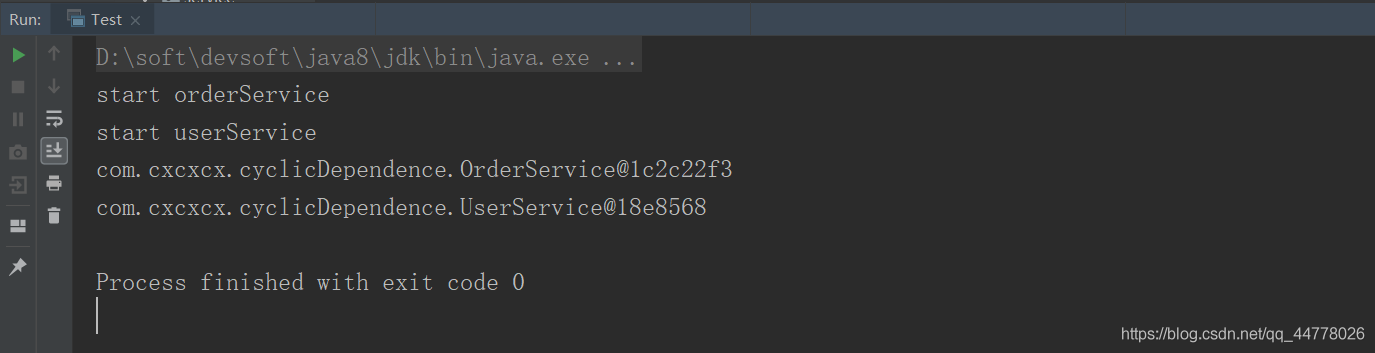
我們可以看見os和us都是正常列印,并沒有報錯,說明Spring是做了 某些處理 使其允許回圈依賴,其實Spring是提供了關倍訓圈依賴的api的,比如上面測驗類代碼中注釋掉的那句話,我們打開那個注釋,再運行一次,
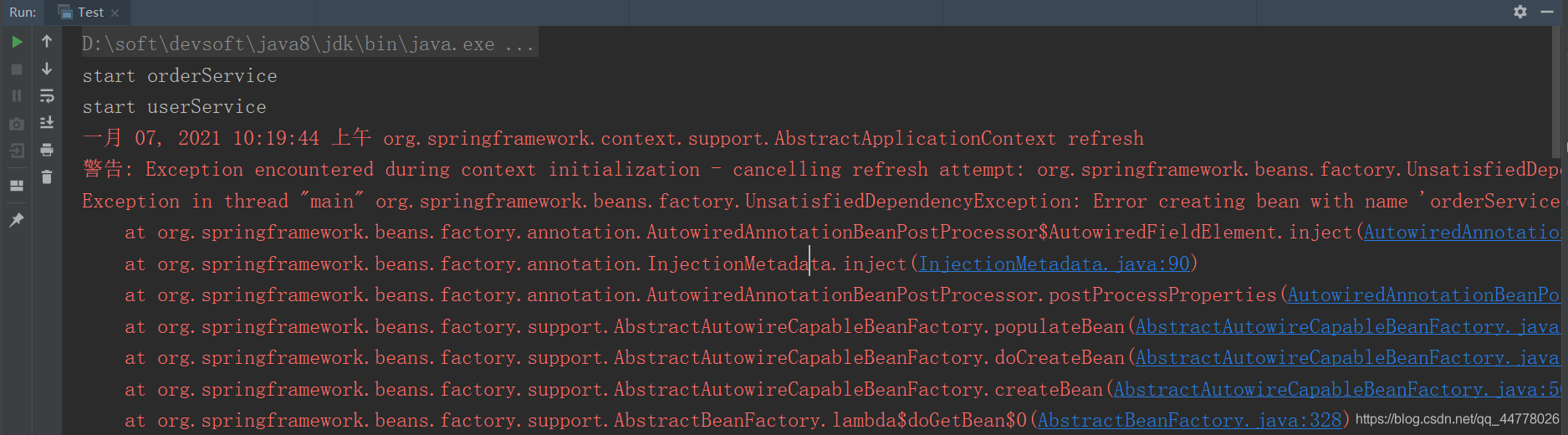
可以看見直接運行報錯,報錯資訊大家可以自己下去測驗看看,
這里再說明有兩種情況下Spring是不支持回圈依賴的,原因大家可以自行了解一下,
- 當bean的作用域是原型的時候
- 當以構造器的形式注入的時候
下面文章,我就來詳細講解 某些處理 到底是什么處理,
二、回圈依賴三級快取以及整個流程介紹
首先給三級快取在Spring中到底是哪三級,在 DefaultSingletonBeanRegistry 類中:
/** Cache of singleton objects: bean name to bean instance. */
// 一級快取,可稱為單例池,存放創建好的單例bean的map beanName - bean
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
/** Cache of singleton factories: bean name to ObjectFactory. */
// 三級快取,存放的結構是 beanName - ObjectFactory
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
/** Cache of early singleton objects: bean name to bean instance. */
// 二級快取,存放的結構是 beanName - bean
private final Map<String, Object> earlySingletonObjects = new ConcurrentHashMap<>(16);
因為Spring的回圈依賴解決只是bean的生命周期中的一個很小的部分,其歸屬的部分是屬性填充時期,意思就是回圈依賴是在屬性填充時期發生并解決的,bean生命周期大概如下:
- 推斷構造方法
- 實體化物件
- 屬性填充
- 生命周期回呼初始化方法
- …
為了讓大家能夠更加清晰的理解Spring的回圈依賴,這里先用文字描述一下,Spring創建bean解決回圈依賴的的大概流程(下面的原始碼敘述就圍繞這個流程展開)
- Spring優先創建os,在呼叫getSingleton 獲取os的bean的時候,發現單例池中沒有,所以會createBean,并將os放入正在創建的容器中;
- 進行os物件的實體化,然后將os放入三級快取中,接著對os進行屬性填充,執行某個后置處理器
方法完成屬性填充; - 屬性填充時發現os中的屬性是us,就會取getBean,但是拿不到us(還未創建),所以會createBean創建us的bean,并將us放入正在創建的容器中;
- 進行us物件的實體化,然后將us放入三級快取中,接著對us進行屬性填充;
- 屬性填充時,發現us中的屬性是os,但是得到os的bean為空,并且os現在是屬于在正在創建的,所以再次呼叫getSingleton 會從三級快取中得到os;
- 到此us屬性填充完畢,us這個bean存入單例池(一級快取),方法堆疊回傳,將us注入到os中,完成回圈依賴,
到這里我相信大家可能會有如下幾個疑問:
- 為什么要設定三級快取?各自作用是什么?
- 第三級快取的value值型別為什么和前兩級不一樣?
- 在上述流程中的步驟2說的某個后置處理器是哪個后置處理器?
- 在上述流程中的步驟5中,呼叫getSingleton 如何從三級快取中獲取bean?
三、原始碼敘述Spring回圈依賴
將上面流程轉化為具體的原始碼呼叫,如下:
1、流程的第一步,
Spring優先創建os,在呼叫getSingleton 獲取os的bean的時候,發現單例池中沒有,所以會createBean,并將os放入正在創建的容器中,
(1)代碼呼叫如下:
ac.refresh();
//這個方法的功能之一就是完成類的實體化和屬性注入
finishBeanFactoryInitialization(beanFactory);
//實體化所有的非lazy的單例bean
beanFactory.preInstantiateSingletons();
(2)進入這個 preInstantiateSingletons() 方法中(一些不怎么必要的邏輯,我就直接省略了),在這個方法里面會得到所有的beanDefinition(這個東西就是用于描述一個bean的,大家可以自己去了解一下,這里不做展開)的名稱,判斷這個bean是否是FactoryBean或者是一個普通的bean,這里我們的os是一個普通的bean(一般來說都是一個普通的bean),進入else,呼叫getBean(String) 方法,
@Override
public void preInstantiateSingletons() throws BeansException {
//這里得到所有的 bd名字
List<String> beanNames = new ArrayList<>(this.beanDefinitionNames);
// Trigger initialization of all non-lazy singleton beans...
// 這里就遍歷所有的bd,然后進行所有非惰性單例的bean的初始化
for (String beanName : beanNames) {
// 根據bd名字看是否需要合并獲取其 bd
RootBeanDefinition bd = getMergedLocalBeanDefinition(beanName);
//如果這個bd不是抽象的,是單例的,不是lazy的,那就表示其現在可以進行初始化
if (!bd.isAbstract() && bd.isSingleton() && !bd.isLazyInit()) {
//如果這個bean是一個 FactoryBean
if (isFactoryBean(beanName)) {
Object bean = getBean(FACTORY_BEAN_PREFIX + beanName);
if (bean instanceof FactoryBean) {
...
}
}
// 否則是一個普通的bean
else {
// 根據beanName獲取一個bean,
getBean(beanName);
}
}
}
...
}
(3)進入 getBean(String) 方法,里面呼叫的的是doGetBean 方法
@Override
public Object getBean(String name) throws BeansException {
return doGetBean(name, null, null, false);
}
(4)進入 doGetBean 方法,在這個方法中會呼叫 getSingleton(String) 方法!!!!注意這個getSingleton(String) 方法,很重要,這個方法就是解決回圈依賴的根本方法,第一次呼叫 getSingleton(String) 得到os的bean為null,便會再次呼叫多載的 getSingleton(String, ObjectFactory) 方法,
protected <T> T doGetBean(
String name, @Nullable Class<T> requiredType, @Nullable Object[] args, boolean typeCheckOnly)
throws BeansException {
// 可以理解為驗證bean的名字是否合法,若是合法則將bd map中的key作為beanName
// 在獲取factoryBean的時候 若是加上 & 則是獲取FactoryBean物件本身的bean,不加 & 則是獲取回傳的物件的bean
String beanName = transformedBeanName(name);
Object bean;
// Eagerly check singleton cache for manually registered singletons.
// getSingleton !!!!! 重點方法!!!!
// 這里就從 singletonObjects(單例池) 容器中直接拿,下面代碼中還會呼叫其多載的 getSingleton
// 第一次獲取的肯定是null
Object sharedInstance = getSingleton(beanName);
if (sharedInstance != null && args == null) {
...
bean = getObjectForBeanInstance(sharedInstance, name, beanName, null);
}
else {
...
if (!typeCheckOnly) {
markBeanAsCreated(beanName);
}
try {
RootBeanDefinition mbd = getMergedLocalBeanDefinition(beanName);
checkMergedBeanDefinition(mbd, beanName, args);
// Guarantee initialization of beans that the current bean depends on.
String[] dependsOn = mbd.getDependsOn();
if (dependsOn != null) {
...
}
// Create bean instance.
if (mbd.isSingleton()) {
// 這里再次呼叫 getSingleton (多載的)
sharedInstance = getSingleton(beanName, () -> {
// 這個lambda運算式的邏輯就是為了創建一個單例bean
try {
return createBean(beanName, mbd, args);
}
catch (BeansException ex) {
destroySingleton(beanName);
throw ex;
}
});
bean = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
}
else if (mbd.isPrototype()) {
...
}
}
catch (BeansException ex) {
cleanupAfterBeanCreationFailure(beanName);
throw ex;
}
}
// Check if required type matches the type of the actual bean instance.
if (requiredType != null && !requiredType.isInstance(bean)) {
...
}
return (T) bean;
}
(4.1)這里給出 getSingleton(String) 方法邏輯,可以看到引數2Spring直接給的true,在 getSingleton(String , boolean) 方法中,第一次呼叫會回傳null,
@Override
@Nullable
public Object getSingleton(String beanName) {
// 引數2直接給的true
return getSingleton(beanName, true);
}
@Nullable
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// Quick check for existing instance without full singleton lock
// 首先從一級快取 singletonObjects 單例池直接獲取,singletonObjects就是bean的單例池
Object singletonObject = this.singletonObjects.get(beanName);
// 如果從一級快取 單例池中獲取的bean為空,并且該bean正在被創建
// 第一次運行進來第二個條件肯定不滿足,不進入if,直接回傳 singletonObject
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
// 從二級快取中獲取
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
synchronized (this.singletonObjects) {
// Consistent creation of early reference within full singleton lock
// 再次從一級快取中獲取
singletonObject = this.singletonObjects.get(beanName);
// 若是一次快取中沒有
if (singletonObject == null) {
// 從二級快取中獲取
singletonObject = this.earlySingletonObjects.get(beanName);
// 若是二級快取中也沒有
if (singletonObject == null) {
// 那就從三級快取中獲取
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
// 若是三級快取中拿到了
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
}
}
return singletonObject;
}
(4.2)這里給出 getSingleton(String, ObjectFactory) 方法邏輯,里面的beforeSingletonCreation(String) 方法就將當前正在創建bean存入了表示正在創建的集合 singletonsCurrentlyInCreation 中,即將os存入其中,singletonObject = singletonFactory.getObject(); 這個這句話就得到創建好的bean,但是singletonFactory是哪里來的呢?他其實是由外部的lambda運算式實作的,在外部的lambda運算式中就呼叫了 createBean(…) 這個方法去創建了一個單例的bean,
public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(beanName, "Bean name must not be null");
synchronized (this.singletonObjects) {
// 這里仍然從容器當中拿一次
Object singletonObject = this.singletonObjects.get(beanName);
// 拿到了就回傳,沒有拿到就進入這個if
if (singletonObject == null) {
if (this.singletonsCurrentlyInDestruction) {
...
}
if (logger.isDebugEnabled()) {
...
}
// 將當前beanName存入正在創建bean的set集合中
beforeSingletonCreation(beanName);
boolean newSingleton = false;
boolean recordSuppressedExceptions = (this.suppressedExceptions == null);
if (recordSuppressedExceptions) {
this.suppressedExceptions = new LinkedHashSet<>();
}
try {
// 這個getObject() 的邏輯就是該方法外部的lambda 運算式
singletonObject = singletonFactory.getObject();
newSingleton = true;
}
catch (IllegalStateException ex) {
...
}
finally {
...
afterSingletonCreation(beanName);
}
// 將創建好的單例bean存入單例池中
if (newSingleton) {
addSingleton(beanName, singletonObject);
}
}
return singletonObject;
}
}
(4.2.1)這里給出beforeSingletonCreation(String)的邏輯
其作用就是將該beanName放入了這個表示正在創建的集合 singletonsCurrentlyInCreation中
protected void beforeSingletonCreation(String beanName) {
//這里完成的功能就是,判斷當前檢查中是否包含該bean,并且判斷該bean是否在正在創建,注意這里是add
if (!this.inCreationCheckExclusions.contains(beanName) && !this.singletonsCurrentlyInCreation.add(beanName)) {
throw new BeanCurrentlyInCreationException(beanName);
}
}
以上代碼就是流程的第一步:
Spring優先創建os,在呼叫getSingleton 獲取os的bean的時候,發現單例池中沒有,所以會createBean,并將os放入正在創建的容器中;
2、流程的第二步,
進行os物件的實體化,然后將os放入三級快取中,接著對os進行屬性填充,執行某個后置處理器方法完成屬性填充;
(4.3)這里給出getSingleton(String, ObjectFactory) 引數2的lambda運算式邏輯
在(4.2)中有這樣一句代碼getObject() ,由于lambda運算式的異步性,所以當呼叫getObject() 方法時才會執行lambda運算式,在lambda運算式中呼叫了一個方法 createBean(beanName, mbd, args) 而createBean 的回傳值就是 getObject()所得到的物件,在 createBean 中又繼續呼叫了doCreateBean 方法得到了一個完整的bean,
// 這個getObject() 的邏輯就是該方法外部的lambda 運算式
singletonObject = singletonFactory.getObject();
// lambda運算式如下
() -> {
// 這個lambda運算式的邏輯就是為了創建一個單例bean
try {
return createBean(beanName, mbd, args);
}
catch (BeansException ex) {
destroySingleton(beanName);
throw ex;
}
}
//其中 createBean(beanName, mbd, args) 方法邏輯如下
@Override
protected Object createBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args)
throws BeanCreationException {
if (logger.isTraceEnabled()) {
...
}
RootBeanDefinition mbdToUse = mbd;
// Make sure bean class is actually resolved at this point, and
// clone the bean definition in case of a dynamically resolved Class
// which cannot be stored in the shared merged bean definition.
// 從beanDefinition物件中獲取出來bean的型別,因為實體化物件就需要類
Class<?> resolvedClass = resolveBeanClass(mbd, beanName);
if (resolvedClass != null && !mbd.hasBeanClass() && mbd.getBeanClassName() != null) {
mbdToUse = new RootBeanDefinition(mbd);
mbdToUse.setBeanClass(resolvedClass);
}
// Prepare method overrides.
try {
mbdToUse.prepareMethodOverrides();
}
catch (BeanDefinitionValidationException ex) {
throw new BeanDefinitionStoreException(mbdToUse.getResourceDescription(),
beanName, "Validation of method overrides failed", ex);
}
try {
// Give BeanPostProcessors a chance to return a proxy instead of the target bean instance.
// 第一次呼叫后置處理器 --- 與aop有關
Object bean = resolveBeforeInstantiation(beanName, mbdToUse);
// 90%的情況這里的bean就是為空,因為這里是做aop的屬性設定
if (bean != null) {
return bean;
}
}
catch (Throwable ex) {
throw new BeanCreationException(mbdToUse.getResourceDescription(), beanName,
"BeanPostProcessor before instantiation of bean failed", ex);
}
try {
// 這里就會來進行bean的創建 將beanName,bd,和一些引數傳入開始進行bean的創建
// beanInstance就是實體化好的一個完整的bean
Object beanInstance = doCreateBean(beanName, mbdToUse, args);
if (logger.isTraceEnabled()) {
logger.trace("Finished creating instance of bean '" + beanName + "'");
}
return beanInstance;
}
catch (BeanCreationException | ImplicitlyAppearedSingletonException ex) {
// A previously detected exception with proper bean creation context already,
// or illegal singleton state to be communicated up to DefaultSingletonBeanRegistry.
throw ex;
}
catch (Throwable ex) {
throw new BeanCreationException(
mbdToUse.getResourceDescription(), beanName, "Unexpected exception during bean creation", ex);
}
}
(5)這里給出 doCreateBean(beanName, mbdToUse, args) 方法的邏輯
在這個方法中,在執行 createBeanInstance(beanName, mbd, args) 方法的時候會進行實體化os物件,里面完成了推斷構造方法 和 實體化物件,但是此時并未注入屬性,后面初始化了一個 boolean型別的值 earlySingletonExposure,因為此時os是單例的,并且Spring是允許回圈依賴的,并且os也在正在創建的那個集合中,所以此時這個boolean值就為true,如此便會進入下面的那個if之中,呼叫addSingletonFactory() 方法(查看5.1)將os以ObjectFactory的形式存入了三級快取中,后面便呼叫了 populateBean(beanName, mbd, instanceWrapper) 方法完成了屬性注入,
protected Object doCreateBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args)
throws BeanCreationException {
// Instantiate the bean.
// 這里開始實體化bean
BeanWrapper instanceWrapper = null;
// 如果是單例的
if (mbd.isSingleton()) {
instanceWrapper = this.factoryBeanInstanceCache.remove(beanName);
}
if (instanceWrapper == null) {
// 實體化物件,里面第二次呼叫后置處理器 --- 這里面完成了推斷構造方法 和 實體化物件(還未注入屬性!!!!)
// 得到的 instanceWrapper 就是實體化好的物件的包裝類
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
// 這里就通過bean的包裝類得到了該bean的實體和型別
Object bean = instanceWrapper.getWrappedInstance();
Class<?> beanType = instanceWrapper.getWrappedClass();
if (beanType != NullBean.class) {
mbd.resolvedTargetType = beanType;
}
// Allow post-processors to modify the merged bean definition.
synchronized (mbd.postProcessingLock) {
if (!mbd.postProcessed) {
...
}
}
// Eagerly cache singletons to be able to resolve circular references
// even when triggered by lifecycle interfaces like BeanFactoryAware.
// 判斷是否允許進行回圈依賴并且提前暴露這個單例bean,注意這里很重要,
// 這個boolean值與 getSingleton(String, boolean) 方法是密切相關的
// 條件1:該bean是否單例
// 條件2:該類的 allowCircularReferences 屬性,這個屬性默認為true,那就是直接體現Spring是默認支持回圈依賴的
// 條件3:該bean是否是正在創建的(beanName是否在正在創建的容器之中)
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
...
// 第四次呼叫后置處理器,判斷是否需要進行 AOP
// 引數2是一個ObjectFactory --- 物件工廠,使用的是lambda運算式
// 這里提前暴露一個物件工廠,而不是一個bean物件!!!
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
// Initialize the bean instance.
Object exposedObject = bean;
try {
// 這里面進行屬性填充,即常說的自動注入
populateBean(beanName, mbd, instanceWrapper);
exposedObject = initializeBean(beanName, exposedObject, mbd);
}
catch (Throwable ex) {
...
}
if (earlySingletonExposure) {
...
}
// Register bean as disposable.
try {
registerDisposableBeanIfNecessary(beanName, bean, mbd);
}
catch (BeanDefinitionValidationException ex) {
...
}
return exposedObject;
}
(5.1)這里給出 addSingletonFactory(String, ObjectFactory)的邏輯
此時就將os以ObjectFactory的形式存入了三級快取中,
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(singletonFactory, "Singleton factory must not be null");
synchronized (this.singletonObjects) {
// 若是一級快取中沒有這個bean,表示這個bean還沒有創建完畢
if (!this.singletonObjects.containsKey(beanName)) {
// 三級快取中添加該 物件工廠
this.singletonFactories.put(beanName, singletonFactory);
// 二級快取中移除該bean,這里為什么要移除
// 我認為這里移除的原因有兩點:
// 1、就是為了讓程式在呼叫 getSingleton(String, boolean) 方法的時候,進入第二個if,就是同步代碼塊中,
// 2、從二級快取中移除一個舊的bean,便于三級快取重新生產一個新(重新進行aop等操作)物件
this.earlySingletonObjects.remove(beanName);
// 將該beanName存放到表示保存已經注冊好的bean的集合中
this.registeredSingletons.add(beanName);
}
}
}
5.2、這里給出lambda運算式() -> getEarlyBeanReference(beanName, mbd, bean)中方法的邏輯
這個lambda的呼叫時機是在 getSingleton(String) 這個方法里面
其與aop相關,所以Spring其實是很早就進行了aop的,而不只是生命周期的那個時間段(請注意這句話),
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
return exposedObject;
}
6、這里給出populateBean(beanName, mbd, instanceWrapper) 方法的邏輯
在這個方法中首先會執行InstantiationAwareBeanPostProcessor介面的postProcessAfterInstantiation()方法,實際上我們可以自己實作InstantiationAwareBeanPostProcessor介面,然后重寫postProcessAfterInstantiation()方法,讓其回傳false,便可以對指定的bean設定其不允許回圈依賴,
后面代碼中最重要的便是 InstantiationAwareBeanPostProcessor這個后置處理器的 postProcessProperties() 方法呼叫,這個方法就完成了屬性注入,其實作類 AutowiredAnnotationBeanPostProcessor 便完成了了 @Autowired 注解的實作,另外一個實作類 CommonAnnotationBeanPostProcessor 完成了 @Resources 注解的實作,
protected void populateBean(String beanName, RootBeanDefinition mbd, @Nullable BeanWrapper bw) {
if (bw == null) {
if (mbd.hasPropertyValues()) {
...
}
else {
// Skip property population phase for null instance.
return;
}
}
// Give any InstantiationAwareBeanPostProcessors the opportunity to modify the
// state of the bean before properties are set. This can be used, for example,
// to support styles of field injection.
// 判斷要不要進行屬性注入,
// 我們自己可以實作 InstantiationAwareBeanPostProcessor 這個介面,
// 重寫其中 postProcessAfterInstantiation() 方法使其回傳false,則可以不再進行屬性注入
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof InstantiationAwareBeanPostProcessor) {
InstantiationAwareBeanPostProcessor ibp = (InstantiationAwareBeanPostProcessor) bp;
if (!ibp.postProcessAfterInstantiation(bw.getWrappedInstance(), beanName)) {
return;
}
}
}
}
// pvs是表示你有沒有給我的屬性傳入值
// 比如當使用xml的形式時,有ref指定該屬性需要傳入的值是什么,但是 @Autowired 沒法指定值所以會得到null
// 正因為是null 所以其開始進行屬性自動注入
PropertyValues pvs = (mbd.hasPropertyValues() ? mbd.getPropertyValues() : null);
// 得到該bean的自動注入模式,@Autowired 的自動注入模式為 0
int resolvedAutowireMode = mbd.getResolvedAutowireMode();
// 判斷該注入模式是byName還是byType,所以@Autowired 不會進入這個判斷
if (resolvedAutowireMode == AUTOWIRE_BY_NAME || resolvedAutowireMode == AUTOWIRE_BY_TYPE) {
...
}
boolean hasInstAwareBpps = hasInstantiationAwareBeanPostProcessors();
boolean needsDepCheck = (mbd.getDependencyCheck() != AbstractBeanDefinition.DEPENDENCY_CHECK_NONE);
PropertyDescriptor[] filteredPds = null;
if (hasInstAwareBpps) {
if (pvs == null) {
pvs = mbd.getPropertyValues();
}
// 在 getBeanPostProcessors() 中會得到6個 bean后置處理器
// 其中一個叫 CommonAnnotationBeanPostProcessor 這個bean后置處理器就是處理 @Resource 注解的
// 還有一個叫 AutowiredAnnotationBeanPostProcessor 這個bean后置處理器就是處理 @Autowired 注解的
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof InstantiationAwareBeanPostProcessor) {
InstantiationAwareBeanPostProcessor ibp = (InstantiationAwareBeanPostProcessor) bp;
// 這里就是執行 對應后置處理器的重寫方法
// @Autowired 注解便會執行 AutowiredAnnotationBeanPostProcessor 這個后置處理器的重寫方法
/** AutowiredAnnotationBeanPostProcessor后置處理器的這個方法就是完成屬性填充 */
PropertyValues pvsToUse = ibp.postProcessProperties(pvs, bw.getWrappedInstance(), beanName);
if (pvsToUse == null) {
...
}
pvs = pvsToUse;
}
}
}
if (needsDepCheck) {
...
}
if (pvs != null) {
...
}
}
以上代碼就是流程的第二步:
進行os物件的實體化,然后將os放入三級快取中,接著對os進行屬性填充,執行某個后置處理器
方法完成屬性填充;
上述流程中的第三,四,五步其實就是在回圈做上述任務,第六步時屬性已經填充完畢,回圈依賴早已解決
如果你仔細觀看了上述文章并且有結合Spring原始碼進行閱讀,你就會發現,getSingleton(String) 與 addSingletonFactory(String, ObjectFactory) 這兩個方法尤為重要,他們就是Spring解決回圈依賴的根本邏輯,
四、重點說明getSingleton(String) 和 addSingletonFactory(String, ObjectFactory)
在說明這兩個方法之前,再總結一下回圈依賴的流程:
- get os的bean,呼叫getSingleton(String) 但是為null;
- 將os放入表示正在創建的集合中;
- 實體化os的物件;
- 呼叫addSingletonFactory(String, ObjectFactory) 將os所對應的 ObjectFactory放入三級快取;
- os物件進行屬性填充;
- os屬性填充時發現屬性是us,呼叫 getSingleton(String) 獲取us的bean,但是為null;
- 將us放入表示正在創建的集合中;
- 實體化us的物件;
- 呼叫addSingletonFactory(String, ObjectFactory) 將us所對應的 ObjectFactory放入三級快取;
- us進行屬性填充;
- us進行屬性填充時,發現屬性是os,就呼叫 getSingleton(String) 獲取us的bean,這是能夠獲取到,us屬性填充完畢;
- us初始化完成,方法堆疊回傳,os屬性填充完畢,os初始化完成,
為了方便說明,下面再次給出 addSingletonFactory(String, ObjectFactory) 方法原始碼
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(singletonFactory, "Singleton factory must not be null");
synchronized (this.singletonObjects) {
// 若是一級快取中沒有這個bean,表示這個bean還沒有創建完畢
if (!this.singletonObjects.containsKey(beanName)) {
// 三級快取中添加該 物件工廠
// 這里提前暴露一個物件工廠,而不是一個bean物件
this.singletonFactories.put(beanName, singletonFactory);
// 二級快取中移除該bean,這里為什么要移除
// 我認為這里移除的原因有兩點:
// 1、就是為了讓程式在呼叫 getSingleton(String, boolean) 方法的時候,進入第二個if,就是同步代碼塊中,
// 2、從二級快取中移除一個舊的bean,便于三級快取重新生產一個新(重新進行aop等操作)物件
this.earlySingletonObjects.remove(beanName);
// 將該beanName存放到表示保存已經注冊好的bean的集合中
this.registeredSingletons.add(beanName);
}
}
}
其中引數2的ObjectFactory,是由一個lambda運算式傳入的,下面給出這個lambda運算式的原始碼
這個lambda運算式中的那個后置處理器完成的一個功能就是進行了aop!看到這,我相信有些讀者應該已經知道了第三級快取value值為什么是一個 ObjectFactory了,如果還不知道,也沒事,下面會解釋,
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
return exposedObject;
}
再說明 getSingleton(String) 方法,這里再次給出其方法原始碼
這個方法其實也沒有什么難懂的邏輯,看看注釋也就知道他在干嘛了,
@Override
@Nullable
public Object getSingleton(String beanName) {
return getSingleton(beanName, true);
}
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// Quick check for existing instance without full singleton lock
// 首先從一級快取 singletonObjects 單例池直接獲取,singletonObjects就是bean的單例池
Object singletonObject = this.singletonObjects.get(beanName);
// 如果從一級快取 單例池中獲取的bean為空,并且該bean正在被創建
// 第一次運行進來第二個條件肯定不滿足,不進入if,直接回傳 singletonObject
// 但是如果有回圈依賴的情況,這個條件就會滿足!!!!
// 如下代碼就是Spring解決回圈依賴的實作程序
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
// 從二級快取中獲取
singletonObject = this.earlySingletonObjects.get(beanName);
// 如果一級快取中為空,并且表示允許提前參考(這個條件從getBean的流程過來,Spring直接給的true)
// allowEarlyReference在這里直接默認為true,表示允許提前參考???
// 我覺得這個提前參考的意思就是(注意這個if的位置):因為回圈參考的原因,導致這個時候的bean還是一個不完整的,
// 但是一個不完整的bean怎么能夠給別人使用呢,所以這里需要進行一個判斷,是否允許一個不完整的bean提供給別人
// 當一個不完整的bean給被別人使用的時候,最后還是得讓其變得完整,所以這里使用了ObjectFactory,
// 由于回圈依賴的特殊性,所以這里為true,這里也可以作為Spring允許回圈依賴的原始碼級別證據之一,
if (singletonObject == null && allowEarlyReference) {
synchronized (this.singletonObjects) {
// Consistent creation of early reference within full singleton lock
// 再次從一級快取中獲取
singletonObject = this.singletonObjects.get(beanName);
// 若是一次快取中沒有
if (singletonObject == null) {
// 從二級快取中獲取
singletonObject = this.earlySingletonObjects.get(beanName);
// 若是二級快取中也沒有
if (singletonObject == null) {
// 那就從三級快取中獲取
// 三級快取存放物件工廠的時機是在屬性注入之前,并且earlySingletonExposure為true
// 所以當有回圈依賴的時候,Spring就會從三級快取中拿到這個不完整的bean,進行屬性注入
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
// 若是三級快取中拿到了
if (singletonFactory != null) {
// 得到 bean實體,注意這個 singletonFactory.getObject()得到bean 是使用lambda運算式完成的,
// 而lambda是異步進行的,即呼叫方法時才會執行,
// 而在這個運算式方法中完成了一個后置處理器的呼叫才回傳了這個bean
// 這個后置處理器所完成的任務就是對回圈依賴時的aop的解決,
singletonObject = singletonFactory.getObject();
// 將解決好aop問題的bean實體放入二級快取中!!!!!
this.earlySingletonObjects.put(beanName, singletonObject);
// 將該物件工廠從三級快取中移除,因為解決好aop問題的bean實體已經存放入二級快取中
this.singletonFactories.remove(beanName);
}
}
}
}
}
}
return singletonObject;
}
這里說明第三級快取為什么是一個ObjectFactory?
我們通過一個問題來說明
一個普通bean進行aop的程序:
new A -> 執行屬性注入 -> 生命周期回呼 -> 判斷aop代理 -> put 一級快取
當回圈依賴時有aop的執行程序:比如這里有A B兩類的回圈依賴,A進行了aop:
A實體化物件(A還是一個簡單物件沒有aop) -> 屬性注入B -> get B -> new B
-> 注入A(此時A還是一個簡單物件,沒有進行aop),A注入到B -> B put到容器 -> B注入到A
-> 生命周期回呼 -> aop -> A put到容器
-------> 可以看到此時的問題就是A是進行了aop的,但是B中的A卻是一個沒有進行aop的簡單物件
所以這里三級快取使用ObjectFactory的原因就在這里:
ObjectFactory 可以對物件進行任意修改,而這里的使用就是完成了回圈依賴情況下的aop的代理的實作,singletonFactory.getObject() 所得到的物件就是上述lambda 運算式中方法getEarlyBeanReference(beanName, mbd, bean) 的回傳物件,而這個方法中會呼叫后置處理器完成aop,這樣便解決了上面所說的問題,
到這里,我相信很多讀者應該已經知道了三級快取各自的作用了吧,可能你會問二級快取不是沒有說嗎?但是這二級快取的作用和存在的意義讀者可以思考一下,不過也沒關系,下面總結也會提到,
五、總結
這里的總結也就是回答上面提到的四個問題:
問題1:為什么要設定三級快取,各自的作用是什么?
Spring設計這三級快取的原因,很大程度上就是為了解決回圈依賴所帶來的一系列問題
其各自的作用:
一級快取:單例池,就是為了存放實體化好的bean
二級快取:我認為設定二級快取的目的是為了填補空白期,當三級快取創建好了解決aop問題的bean到這個bean存入一級快取(單例池)的這個空白期使用,當在多執行緒情況下,若是沒有這個二級快取,此時三級快取已經移除,而一級快取又沒有存入,就會出現問題,可能有人會問為什么不直接使用三級快取,而要設計一個二級快取,我認為是因為一個效率問題,工廠創建bean還是需要時間,不如先直接把這個解決好aop問題的bean拿出來,
三級快取:使用ObjectFactory完成了回圈依賴情況下的aop的代理問題解決
問題2:第三級快取的value值為什么和前兩級不一樣?
答案已經在問題1的回答里面了
問題3:在上述流程中的步驟2說的某個后置處理器是哪個后置處理器?
一個叫 CommonAnnotationBeanPostProcessor 這個bean后置處理器就是處理 @Resource 注解的
還有一個叫 AutowiredAnnotationBeanPostProcessor 這個bean后置處理器就是處理 @Autowired 注解的
問題4:在上述流程中的步驟5中,呼叫getSingleton 如何從三級快取中獲取bean?
這個問題的答案就在 getSingleton(String) 方法中
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/246589.html
標籤:其他
上一篇:統一網易云音樂、QQ音樂,采用自定義注解+反射+lombok+RestTemplate+FastJson 構造云博音樂服務框架
下一篇:Zstack私有云平臺運行實踐