一、背景
推薦和廣告領域已經大規模應用DNN模型,但大規模稀疏性仍然是該領域模型的本質特點,為了增強模型的擬合能力,模型稀疏引數會達到萬億規模,單模型的物理大小超過1TB,需要分布式的服務來承載;另外模型在線預估場景每秒的引數獲取量由每秒用戶請求量(大于1000),每個用戶請求計算的item數量(大于1000),每個item獲取的引數量(大于200)的三者乘積組成,其對應每秒的引數獲取量KPS(Keys Per Second)在2億的級別,即使用20個副本來分攤流量單機KPS也超過1000萬,行業內還沒有一個通用key-value存盤引擎(Redis/RocksDB/Pika[1])能滿足上述的兩個核心訴求,于是BIGO結合模型在線預估場景的特點進行了存盤引擎和分布式服務的定制設計,獲得了萬億引數規模下高性能引數服務的能力,取名Cyclone,
二、整體架構設計
1、核心目標
1、單機能夠支撐1000萬以上KPS且latency低于10ms
2、通過分布式集群支持萬億引數規模,TB級別的模型
3、支持多副本和多個shards的一致性增量更新
4、系統可用性達到99.99%
2、架構圖
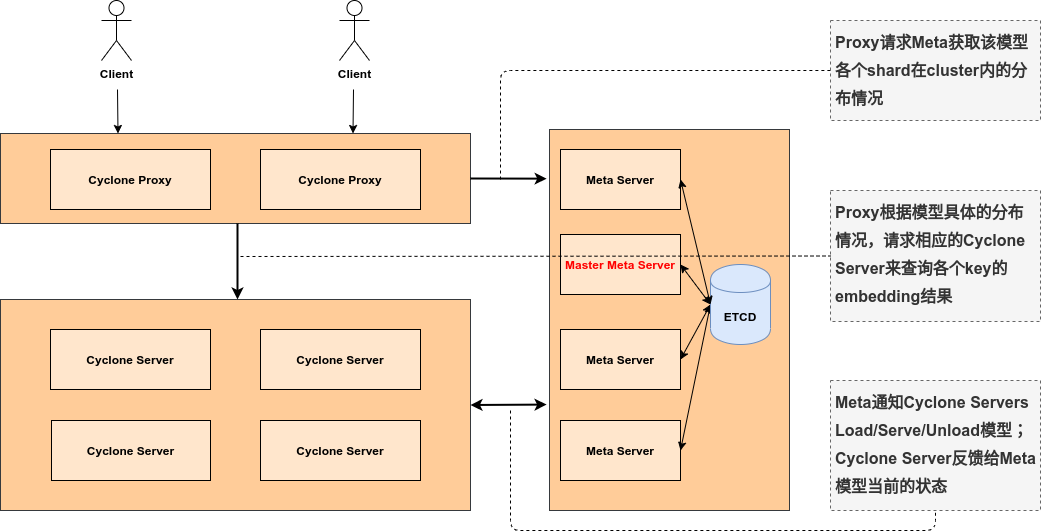
上圖為整體系統架構圖,在線服務部分包含cyclone proxy、cyclone meta、cyclone server三個核心服務,引數資料存盤在Cyclone Server中,
3、設計思路
(1)底層存盤引擎的核心目標是需要極致的查詢性能,同時考慮到模型在線預估場景不會實時做insert/update/erase操作,只需要整體更新模型版本,因此我們采用完美hash(cmph[2]),在離線階段build好索引結構,在線服務階段直接mmap資料即可提供查詢,類似于FlatBuffers[3]的“Access to serialized data without parsing/unpacking”;此外cmph可以最大限度的壓縮索引部分(平均每個key大約用3個bits來表示),同時又可以保證絕對O(1)的查詢效率,value部分整體單獨存放,通過offset來獲取value的值
(2)整個集群由一組cyclone meta服務來做模型管理,負責模型的發布、遷移、下線;meta服務采用單master多slave架構,且master一旦失效可以快速從slave中選擇出新的master承接服務;并由etcd集群存盤模型元資訊,保證元資料的可靠性
(3)cyclone server負責模型引數存盤和查詢,且通過heartbeat和master cyclone meta互動,一旦server失效,cyclone meta可以快速進行服務遷移保持各模型具有穩定的副本服務能力
(4)對外由cyclone proxy層提供統一訪問介面,其內部會負責模型的路由、keys的dispatch與merge、各cyclone server的load balance,同時該層使得模型副本變化以及分片遷移等內部情況對外透明
三、關鍵技術點接拆
1、模型拆分
首先,把模型整體拆分成若干shards,這部分需要充分考慮feature keys的特點,我們希望sharding后每個分片里的keys數量盡可能近似相等,一般來說shard_idx = hash(key) & mask, mask=2^N–1,至于hash函式,考慮到這里的feature key已經是uint64_t,如果本身不夠均勻,可以嘗試用一些mixer[4],
其次,每個shard內部,為了避免單個cmph資料量太大(1000萬key的build時長大約為15s)導致build時間太久,可以進一步拆分成多個sections,每個section都是一個獨立的cmph模型,建議控制在1000萬左右的keys,這里的拆分也需要用到hash函式,建議與sharding程序用的一致,
2、模型更新一致性
在模型更新期間,我們希望模型的所有shards、所有副本能夠同時完成版本切換,避免步調不一致帶來的預估效果損失,因此采用兩個階段來完成版本切換:第一階段是cyclone meta控制多個cyclone server完成模型shards的download與load/init;第二階段是cyclone meta通知各個cyclone server開始serving,同時在元資訊里完成模型的版本切換,在模型升級期間會有兩個版本的資料同時存在于cluster內,
3、水平擴展
cyclone proxy是無狀態的對等節點,因此可以任意水平擴展;cyclone server被cyclone meta調度,新加入的cyclone server節點會被逐步的把模型調度上來,同時由于模型是多副本,因此即便某臺cyclone server失效也并不會導致某模型資料不可訪問,cyclone meta會把失效的cyclone server上的模型分攤到其他cyclone server來補齊各模型應有的副本數;cyclone meta將模型的元資料(例如已經發布成功的模型、正在發布的模型、正在遷移/卸載的模型資訊)持久化到etcd中存盤,同時基于etcd的分布式鎖,所有cyclone meta競爭鎖,獲得鎖的meta自動成為master,提升為master的節點會從etcd獲取所有模型的元資料,繼續負責整個cyclone cluster的模型管理,
4、自適應調整模型副本數
cyclone meta會統計單個模型最近一段歷史版本的訪問情況,根據查詢量來動態調整新版模型的副本數;同時,如果當前版本在serving期間查詢量增加太快,cyclone meta也會實時的增加副本來應對;此外,如果某個模型長期沒有被查詢,超過一定時長后會被判定為zombie模型,進而將其副本數逐步調小至0(即自動下線該模型),
5、增量發布
為了更好的解決增量問題,我們需要索引內核可以支持在線批量insert/erase,為此我們在cyclone二期替換掉了cmph索引內核,改用自研的zmap內核(基于parallel flat hash map[5]改進的一種hashtable),zmap支持多讀單寫,可以在線更新增量資料,雖然索引部分相比于cmph會增大一些,但該索引格式支持在線更新,且查詢效率要優于cmph,離線build比cmph更快,
Zmap的高性能主要得益于基于AVX2指令集能夠單次掃描hash table索引部分32個bytes,進而可以讓hash table的load factor提升到0.9以上,并通過精心設計資料結構使得在多讀單寫情況下基本達到無鎖,有關zmap我們后續會在另外的文章里進一步詳細討論它,
現階段cyclone二期已經上線,單模型可以在10分鐘的粒度增量更新,大大提升了時效性,
6、cyclone性能
由于cyclone集群可以任意水平擴展,模型也可以通過更多的副本和shards來提升單模型的查詢效率,因此我們重點來看下cyclone單機服務能力,選用一臺線上服務器,1T物理記憶體,CPU為44 core,2.1G Hz,加載1000億模型引數,單次mget查詢的keys數量從1k遞增到20k,分別觀察其QPS和Latency,
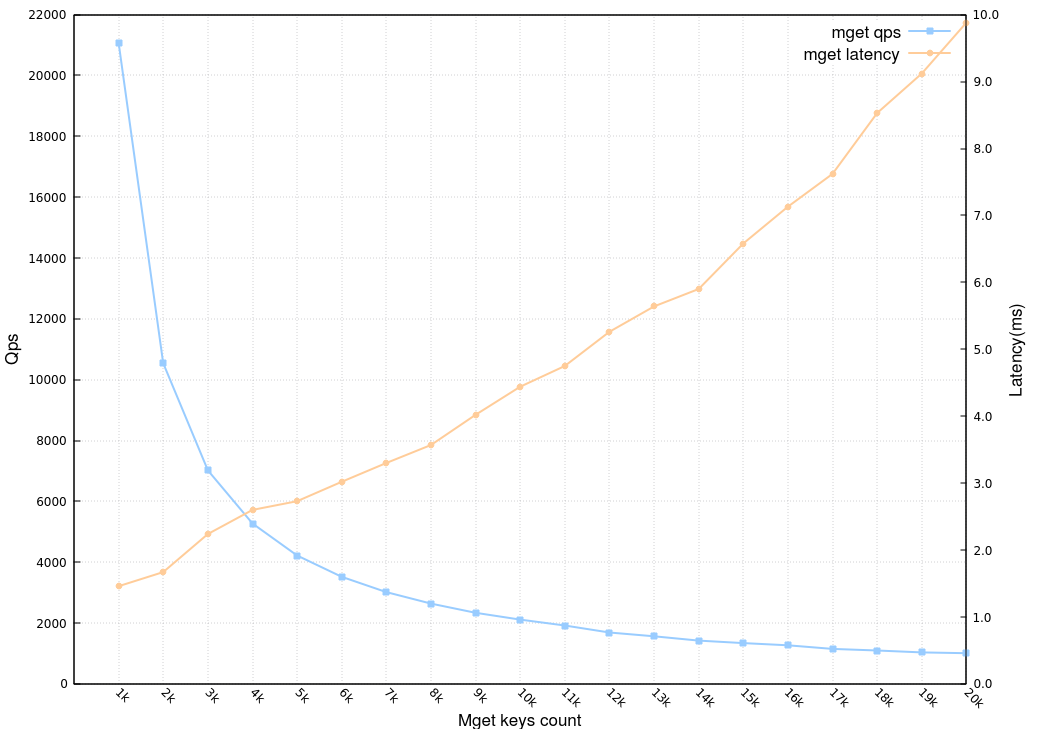
可以看到,mget 1k單機可以達到2.1萬的QPS,即單機2100萬的KPS,隨著單次mget的keys數量增加,QPS相應下降,但總的KPS基本是穩定在2000萬以上;Latency方面,即便是單次mget 2萬keys,客戶端也能夠在10ms內拿到結果,Cyclone server側的cpu使用率為1100%左右,還遠沒有達到cpu資源瓶頸,之所以KPS無法繼續提高是因為網卡吞吐量已經達到極限,
從性能測驗看Cyclone完全可以達到萬億引數規模的模型預估的性能要求,
四、總結與展望
cyclone除了為DNN提供配套的模型引數查詢,其實也可以給任何service提供高吞吐的key-value查詢,因此cyclone已經被廣泛用在了user-cf、item-cf、ad service等各種場景的服務中,
在深度學習日益普及的今天,相信很多公司都有類似的場景需要類似cyclone這樣一套支持水平擴展的、高可用的分布式服務來提供高性能模型引數查詢,后續我們會進一步持續打磨cyclone,等到更加成熟的時候BIGO將對外開源,
References:
[1] https://github.com/pika/pika
[2] http://cmph.sourceforge.net/
[3] https://google.github.io/flatbuffers/
[4] http://zimbry.blogspot.com/2011/09/better-bit-mixing-improving-on.html
[5] https://github.com/greg7mdp/parallel-hashmap
著作權宣告
轉載本網站原創文章需要注明來源出處,因互聯網客觀情況,原創文章中可能會存在不當使用的情況,如文章部分圖片或者部分參考內容未能及時與相關權利人取得聯系,非惡意侵犯相關權利人的權益,敬請相關權利人諒解并聯系我們及時處理,
關于本文
本文首發于公眾號【BIGO技術】,感興趣的同學可以移步至公眾號,獲取最新文章~

轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/246814.html
標籤:其他
上一篇:來吧,展示。互聯網術語
下一篇:面試經驗