在平時做學的知識中我們直到char大小為1,short為2,int為4,
但是當在結構體中呢?
看下面一段代碼:
struct A {
int a;
char b;
short c;
};
正常結構體大小演算法不就應該是:4+1+2=7
但是實際運行結果為:8;
為什么會產生上面的結果,這個原因就是因為如果按照正常的大小存放,則系統大的效率會很低,
因為CPU從記憶體中讀取資料的時候是按照一個位元組一個自己讀取的如果按照正常大小存取的話則會出現下面的情況
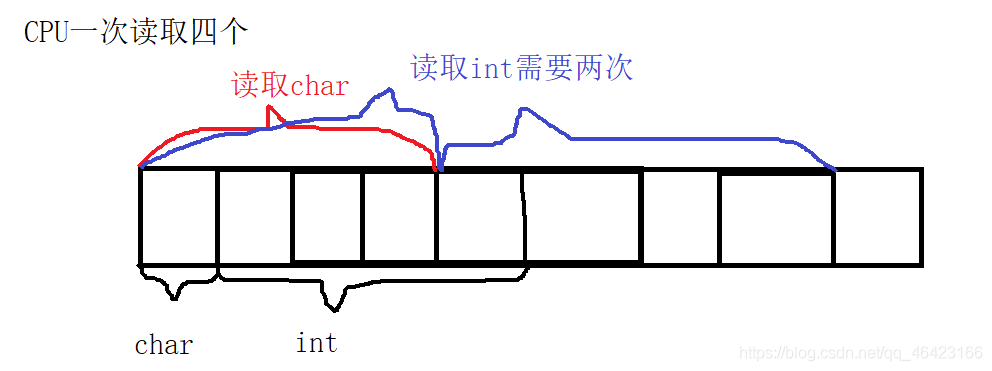
讀取第一個位元組char的時候,則會讀取前四個位元組,然后取第一個位元組,
當讀取第二個int的時候,就會先讀取前四個位元組,然后把第一位去掉,然后再讀取接下來四個位元組,
然后把加下來四個位元組的后三位去掉,再組合到一塊,資源利用率較低也很麻煩,
因此這種方法顯然缺點很多,因此就產生了記憶體對齊的情況,
記憶體對齊
就是把特定型別的變數放在特定的地址上,這就需要各個變數在空間上按一定的規則排列,而不是簡單地順序排列,這就是記憶體對齊,
記憶體對齊規則
首先我們要直到幾個概念:
- 資料型別自身的對齊值:就是上面交代的基本資料型別的自身對齊值,
對于char型資料,其自身對齊值為1,對于short型為2,對于int,float,double型別,其自身對齊值為4,單位位元組, -
指定對齊值:#pragma pack (value)時的指定對齊值value,
可以使用#pragma pack (show)來顯示系統自定義的值,或者這個value可以自己定義(系統默認為8,可以自己試一下) - 結構體或者類的自身對齊值:其成員中自身對齊值最大的那個值,
- 資料成員、結構體和類的有效對齊值:自身對齊值和指定對齊值中較小的那個值
這四個的第一條就是正常的自身對齊值,將這個值與指定對齊值比較,取小的就是資料的有效對齊值
然后后面三條主要是關于結構體的有效對齊值:首先找到結構體內的自身對其值最大的,然后和指定對齊值比較,兩個比較小的就是結構體的有效對齊值,
了解上面四個概念之后,我們記住存放地址就行了:
存放起始地址%有效對齊值=0
主要就是這兩條概念,然后我們分析一下上面的代碼,
struct A {
int a; 自身對齊值為4,系統默認為8,所以有效對齊值為4,需滿足存放地址%4=0,所以放到0的位置就可以了,所占位置為0,1,2,3
char b; 自身對齊值為1,系統默認為8,所以有效對齊值為1,需滿足存放地址%1=0,此時位置4即滿足,所占位置為4
short c; 自身對齊值為2,系統默認為8,所以有效對齊值為2,需滿足存放地址%2=0,此時位置5顯然不行,所以放到6的位置,所占位置6,7.
};總體占8個位置,此時結構體內最大為4,系統為8,所以結構體的有效值為4,此時8%4=0,滿足條件,所以大小即為8.
如果將結構體內資料位置換一下呢?此時還是8嗎?
struct B {
char b;
int a;
short c;
};
下面進行分析
struct B {
char b; 自身對齊值為1,系統默認為8,所以有效對齊值為1,需滿足存放地址%1=0,此時位置0即滿足,所占位置為0
int a; 自身對齊值為4,系統默認為8,所以有效對齊值為4,需滿足存放地址%4=0,但是位置1,2,3都不滿足,所以放在位置4,所占位置為4,5,6,7
short c; 自身對齊值為2,系統默認為8,所以有效對齊值為2,需滿足存放地址%2=0,所以放到8的位置即可,所占位置8,9
};總體占10個位置,此時結構體內最大為4,系統為8,所以結構體的有效值為4,此時10%4!=0,不滿足條件,所以需要調整,即取離10最近且滿足%4=0,即為12,所以此時大小就變成了12
第二段代碼的結構體大小12你是否看懂了呢?
主要掌握這個記憶體對齊規則就可以了,
記憶體對齊的優點
- 記憶體對齊是作業系統為了提高訪問記憶體的策略,作業系統在訪問記憶體的時候,每次讀取一定長度(這個長度是作業系統默認的對齊數,或者默認對齊數的整數倍),
如果沒有對齊,為了訪問一個變數可能產生二次訪問. - 提高存取資料的速度,比如有的平臺每次都是從偶地址處讀取資料,對于一個int型的變數,若從偶地址單元處存放,
則只需一個讀取周期即可讀取該變數;但是若從奇地址單元處存放,則需要2個讀取周期讀取該變數, - 某些平臺只能在特定的
目錄
記憶體對齊
記憶體對齊規則
記憶體對齊的優點
地址處訪問特定型別的資料,否則拋出硬體例外給作業系統
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/249103.html
標籤:其他
上一篇:[RTOS前期準備]以Systick作為時基源+基本定時器撰寫延時函式(基于STM32F407+CubeMX+HAL)