系列文章目錄
Flink/Blink 原理漫談(零)運行時的組件
Flink/Blink 原理漫談(一)時間,watermark詳解
Flink/Blink 原理漫談(二)流表對偶性和distinct詳解
Flink/Blink 原理漫談(三)state 有狀態計算機制 詳解
Flink/Blink 原理漫談(四)window機制詳解
Flink/Blink 原理漫談(五)流式計算的持續查詢實作 詳解
Flink/Blink 原理漫談(六)容錯機制(fault tolerance)詳解
文章目錄
- 系列文章目錄
- 前言 談談blink和flink
- Blink原理漫談
- 零、 Flink運行時的組件
- JobManager
- TaskManager
- ResourceManager
- Dispatcher
- 任務提交流程
前言 談談blink和flink
在實習時候接觸到了flink,這玩意實作了大促期間的實時大資料更新,這對我們這種只寫過python,c++啥玩意的來說聞所未聞,所以了解了一下flink的原理,并且嘗試使用了公司的blink,在學習時間之余,整理了所有的學習筆記,目的也是分享學習,
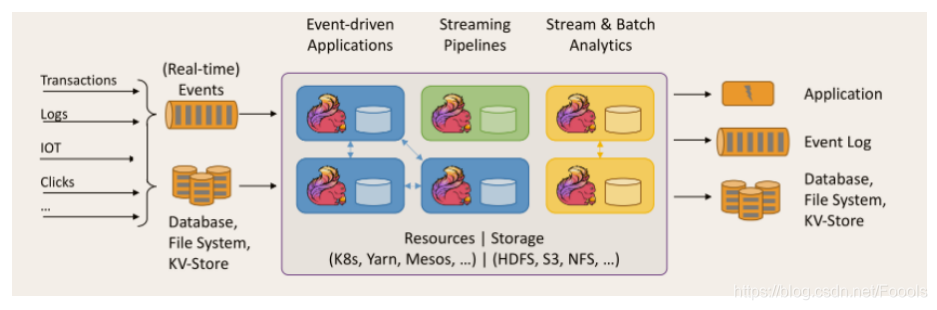
Apache Flink 是一個框架和分布式處理引擎,用于對無界和有界資料流進行有 狀態計算,Flink 被設計在所有常見的集群環境中運行,以記憶體執行速度和任意規模 來執行計算,
Blink是阿里巴巴實時計算部通過改進開源Apache Flink專案而創建的阿里內部產品,簡單的說Blink就是阿里巴巴開發的Flink 企業版,
這倆東西最大的不同其實我感覺,就是blink在公司應用起來是一個十分上層的api,語法基本都是sql,只需要加上with后面的引數就可以實作很多流式計算的功能,使用起來十分方便,即使有些復雜功能不好用sql直接實作也可以使用udf補充實作;而flink使用更多的是datastream api,還是要用java寫的,一些函式的使用需要去一步一步熟悉,相對來說,還是復雜了很多,其實flink也有sql api,但是功能不完善,很離譜,我竟然在完全開發完成之前就已經在學習了,總之,blink雖好,但是是人家內部用,flink也好,但是使用也是略微門檻要高一丟丟,我看到阿里云好像有flink,那個版本的應該也可以使用最上層的api,這個就不是特別了解了,
Blink原理漫談
這部分內容來自blink漫談系列ata,以及網路中關于flink原理的講解和一些知識分享視頻,我認為想要理解flink原理,可以先嘗試從頭到尾閱讀一下《blink漫談》,大概是有十篇左右,這部分其實講的很好,但是如果有點糊涂,那還是和我一樣……拿著一本書先啃吧,看完一本介紹flink的書,再看這一部分,就感覺很好理解了,話不多說,我嘗試用簡單的語言講一下blink/flink的比較重要的實作原理,
零、 Flink運行時的組件
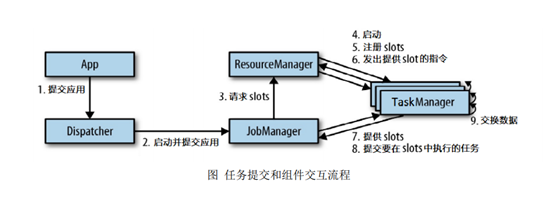
Flink 運行時架構主要包括四個不同的組件,它們會在運行流處理應用程式時協同作業: 作業管理器(JobManager)、資源管理器(ResourceManager)、任務管理器(TaskManager), 以及分發器(Dispatcher),因為 Flink 是用 Java 和 Scala 實作的,所以所有組件都會運行在 Java 虛擬機上,
下圖是整個flink的架構
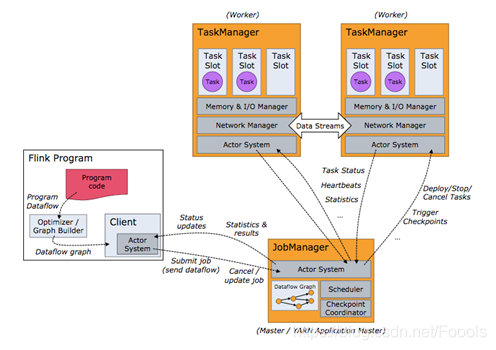
JobManager
控制一個應用程式的主行程
接受要制定的應用程式:作業圖(JobGraph),邏輯資料流圖(Logic dataflow graph),打包了的jar包
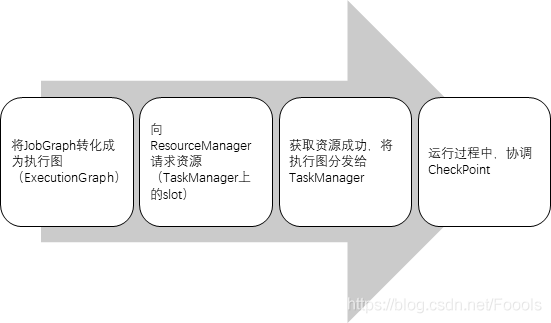
JobManager將JobGraph轉換成一個物理層面的資料流圖(執行圖execution Graph),包含所有可并發執行的任務,
TaskManager
Flink中的作業行程,通常會有多個TaskManager運行,
每個TaskManager中含一定量slot
TaskManger會向ResourceManager中注冊它的插槽
TaskManager收到ResourceManager的指令后,會將slot供JobManager呼叫(JobManager流程圖的第二步的后續)
JobManager可向slot分配任務來執行
運行同一任務的TaskManager可相互交換資料
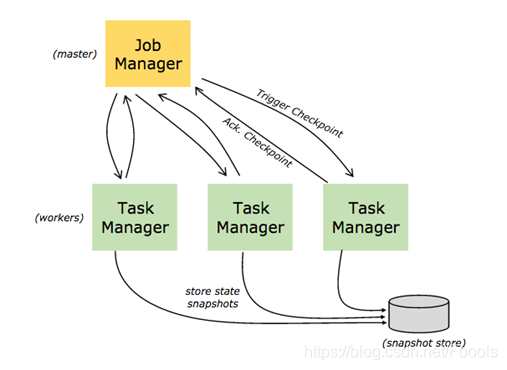
TaskManager與JobManager的關系如圖
ResourceManager
負責管理TaskManager的slot
不同環境有不同的ResourceManager
Dispatcher
為應用提供了REST介面,啟動web,ui,展示監控作業的執行資訊
應用被提交執行->Dispatcher啟動->將應用移交給一個JobManager
任務提交流程
TaskManger和slot
Flink 中每一個 worker(TaskManager)都是一個 JVM 行程,它可能會在獨立的線 程上執行一個或多個 subtask,為了控制一個 worker 能接收多少個 task,worker 通 過 task slot 來進行控制(一個 worker 至少有一個 task slot), 每個 task slot 表示 TaskManager 擁有資源的一個固定大小的子集,假如一個 TaskManager 有三個 slot,那么它會將其管理的記憶體分成三份給各個slot,
通過調整 task slot 的數量,允許用戶定義 subtask 之間如何互相隔離,如果一個 TaskManager 一個 slot,那將意味著每個 task group 運行在獨立的 JVM 中(該 JVM 可能是通過一個特定的容器啟動的),而一個 TaskManager 多個 slot 意味著更多的 subtask 可以共享同一個 JVM,而在同一個 JVM 行程中的 task 將共享 TCP 連接(基 于多路復用)和心跳訊息,它們也可能共享資料集和資料結構,因此這減少了每個 task 的負載,
Task Slot 是靜態的概念,是指 TaskManager 具有的并發執行能力,可以通過 引數 taskmanager.numberOfTaskSlots 進行配置;而并行度 parallelism 是動態概念, 即 TaskManager 運行程式時實際使用的并發能力,可以通過引數 parallelism.default 進行配置, 也就是說,假設一共有 3個 TaskManager,每一個 TaskManager 中的分配 3個 TaskSlot,也就是每個 TaskManager 可以接收 3個 task,一共 9個 TaskSlot,如果我 們設定 parallelism.default=1,即運行程式默認的并行度為 1,9個 TaskSlot 只用了 1個,有 8個空閑,因此,設定合適的并行度才能提高效率
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/255884.html
標籤:其他
上一篇:分布式秒殺系統的設計
下一篇:前端之H5與App互動總結