本文主要內容
1. 排序及其相關概念的介紹
2. 常見排序及其演算法實作
3. 排序演算法復雜度及穩定性分析
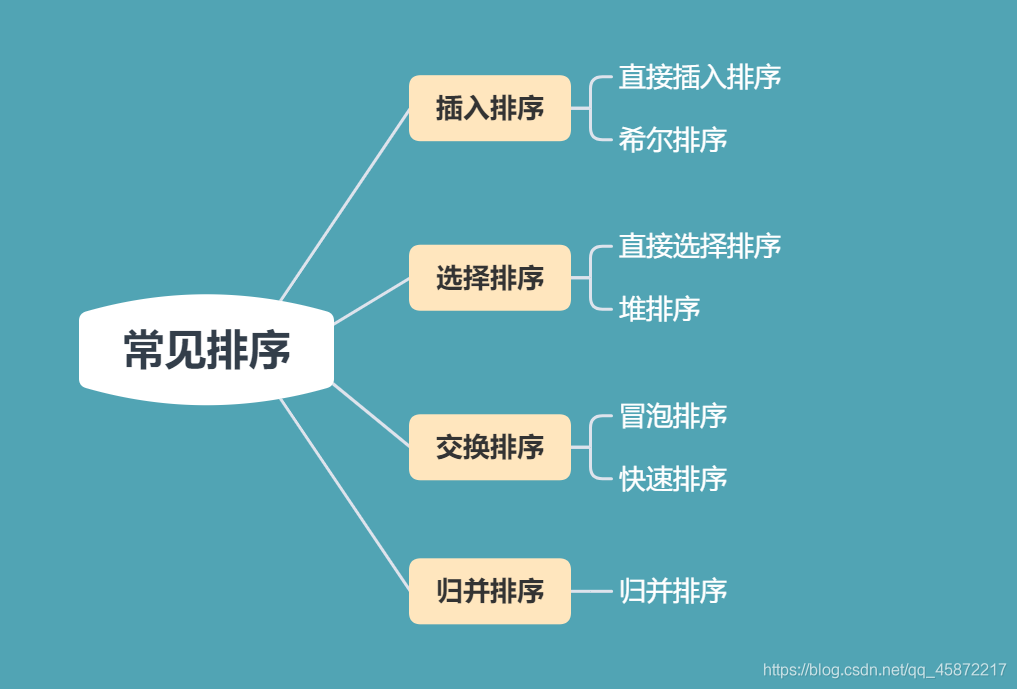
目錄
- 本文主要內容
- 一、排序及其相關概念的介紹
- 二、常見排序及其演算法實作
- 1.插入排序
- 1.1直接插入排序
- 1.2希爾排序(縮小增量排序)
- 2.選擇排序
- 2.1直接選擇排序
- 2.1堆排序
- 3.交換排序
- 3.1冒泡排序
- 3.2快速排序
- 3.2.1快速排序之左右指標法
- 3.2.2快速排序之挖坑法
- 3.2.3快速排序之前后指標法
- 3.2.4快速排序之非遞回實作
- 4.歸并排序
- 4.1歸并排序
- 4.2歸并排序(非遞回)
- 三、 排序演算法復雜度及穩定性分析
一、排序及其相關概念的介紹
- 排序:使一串記錄,按照其中的某個或某些關鍵字的大小,遞增或遞減的排列起來的操作,
- 穩定性:假定在待排序的記錄序列中,存在多個具有相同的關鍵字的記錄,若經過排序,這些記錄的相對次序保持不變,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,則稱這種排序演算法是穩定的;否則稱為不穩定的,(即在一個序列中,相同關鍵字的相對次序在排序前后不發生改變,就稱該排序穩定,反之不穩定,)
- 內部排序:資料元素全部放在記憶體中的排序,
- 外部排序:資料元素太多不能同時放在記憶體中,根據排序程序的要求不能在內外存之間移動資料的排序,
二、常見排序及其演算法實作
1.插入排序
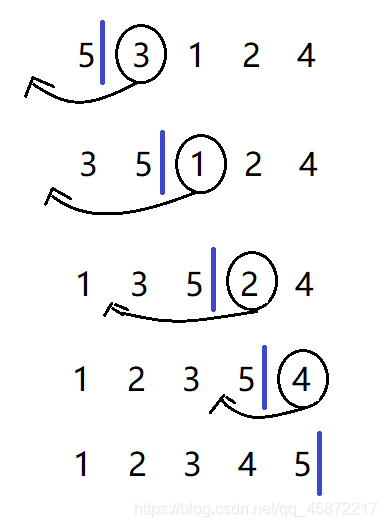
1.1直接插入排序
基本思想:當插入第i(i>=1)個元素時,前面的a[0],a[1],…,a[i-1]已經排好序,此時用a[i]的排序碼與a[i-1],a[i-2],…的排序碼順序進行比較,找到插入位置即將array[i]插入,原來位置上的元素順序后移,
void InsertSort(int* a, int n)
{
for (int i = 0; i < n - 1; i++)
{
//把end+1的資料插入到[0,end]的有序區間
int end = i;//end為已經排好的序列的最后的位置
int temp = a[end + 1];//待插入的資料
while (end >= 0)
{
if (temp < a[end])
{
a[end + 1] = a[end];
end--;
}
else
{
break;
}
}
a[end + 1] = temp;
}
}
直接插入排序的特性總結:
- 元素集合越接近有序,直接插入排序演算法的時間效率越高;反之,越接近逆序,越壞,
- 時間復雜度:O(N^2)
- 空間復雜度:O(1)
- 穩定性:穩定
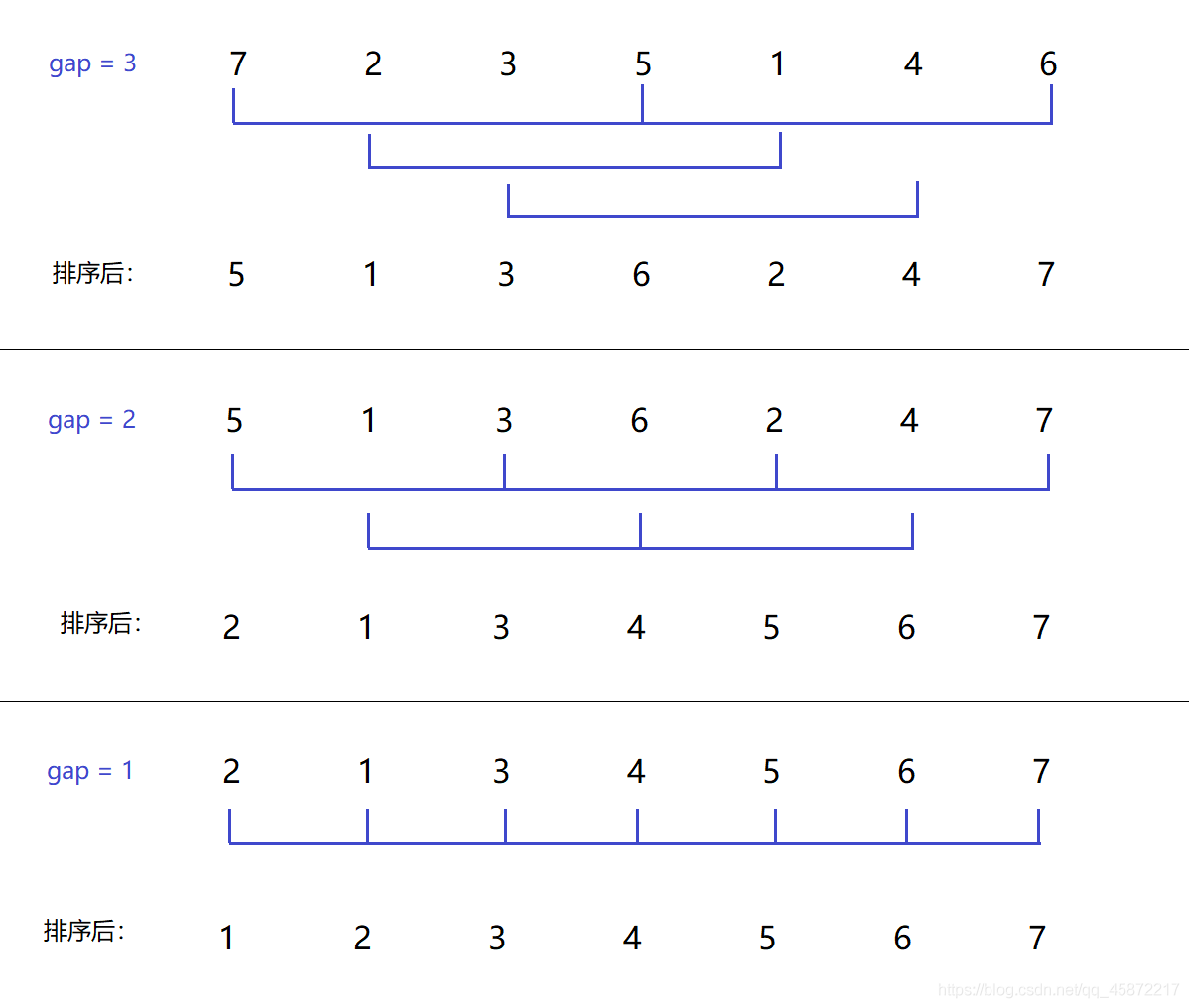
1.2希爾排序(縮小增量排序)
基本思想:先進行預排序,把間距為gap的值分為一組,對每組進行插入排序,再對gap進行遞減取值,重復上述分組和排序的作業,當gap=1時,所有記錄在統一組內排好序(此時也就是進行直接插入排序)
void ShellSort(int* a, int n)
{
//把gap設定的大一點,然后預排序,讓陣列接近有序
//最后gap==1,直接插入排序,保證有序
int gap = n;
while (gap > 1)
{
gap = gap / 3 + 1;//gap一直是遞減的形態;
//+1 :保證最后一次gap一定是1,才能實作完全排序
for (int i = 0; i < n - gap; i++) // i++實作多組并排
{
//for回圈內部是單組內部的排序
int end = i;
int temp = a[end + gap];
while (end >= 0)
{
if (temp < a[end])
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = temp;
}
}
}
希爾排序的特性總結:
- 希爾排序是對直接插入排序的優化,
- 當gap > 1時都是預排序,目的是讓陣列更接近于有序,當gap = 1時,陣列已經接近有序的了,這樣就會很快,整體而言,可以達到優化的效果,
- 希爾排序的時間復雜度不好計算,需要進行推導,推匯出來平均時間復雜度: O(N^1.3— N^2)
- 穩定性:不穩定
2.選擇排序
2.1直接選擇排序
基本思想:在元素集合a[i]–a[n-1]中選擇關鍵碼最大(小)的資料元素,若它不是這組元素中的最后一個(第一個)元素,則將它與這組元素中的最后一個(第一個)元素交換,在剩余的a[i]–a[n-2](a[i+1]–a[n-1])集合中,重復上述步驟,直到集合剩余1個元素,排序結束,
void SelectSort(int* a, int n)
{
for(int i=1;i<=n-1;i++)//進行n-1趟選擇
{
int index=i;
for(int j=i+1;j<=n;j++)//從無序中選取最小,并記錄下標
{
if(a[index]>a[j])
index=j;
}
if(index!=i)
swap(a[i],a[index]);
}
}
直接選擇排序的特性總結:
- 直接選擇排序效率不佳,實際中很少使用,
- 時間復雜度:O(N^2)
- 空間復雜度:O(1)
- 穩定性:不穩定
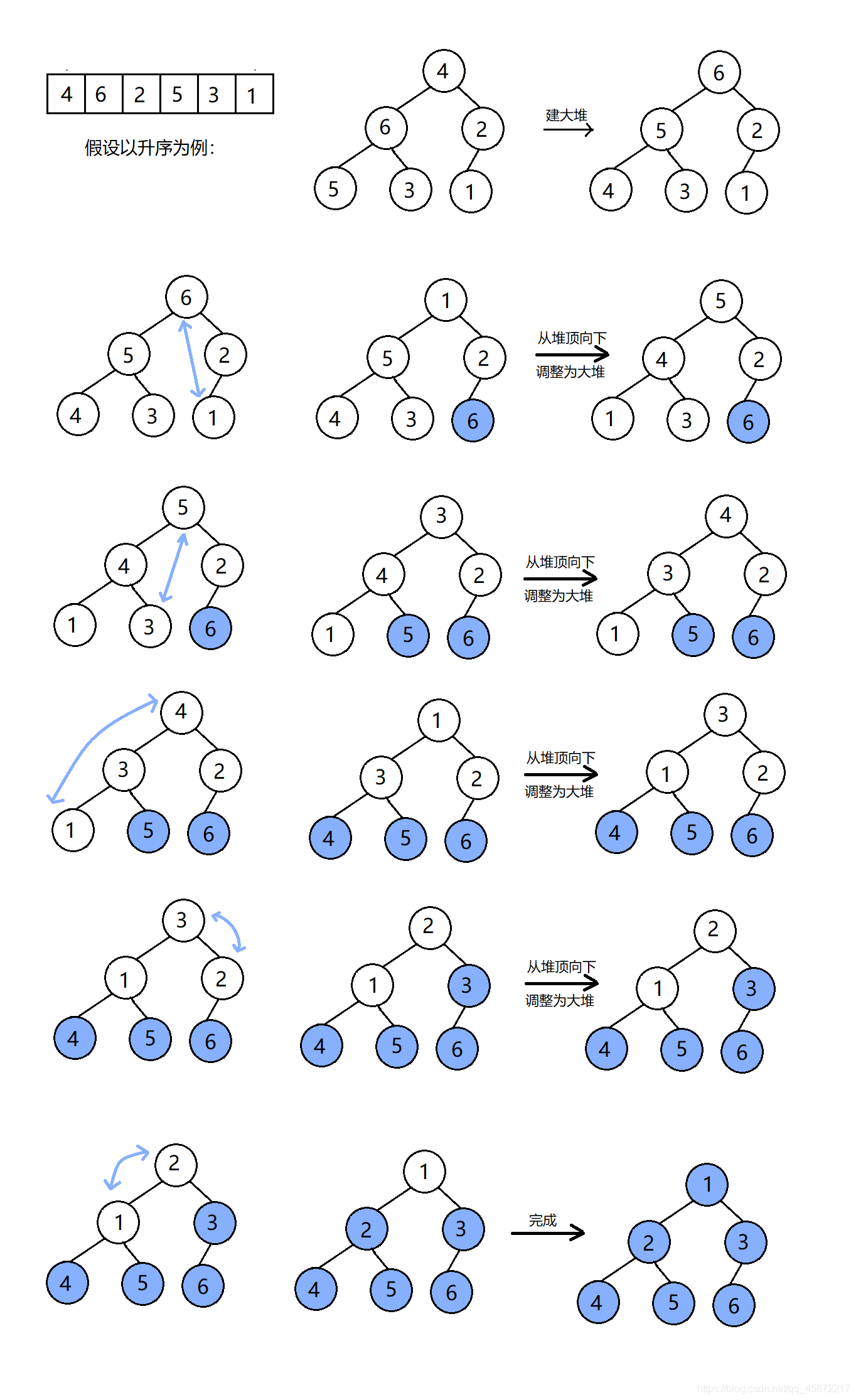
2.1堆排序
基本思想:利用堆積樹(堆)這種資料結構所設計的一種排序演算法,通過堆來進行選擇資料,需要注意的是排升序要建大堆,排降序建小堆,
void AdjustDown(int* a, int n, int root)
{
int parent = root;
int child = parent * 2 + 1;
while (child < n)
{
if (child + 1 < n&&a[child + 1] > a[child])
{
child++;
}
if (a[child]>a[parent])
{
Swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void HeapSort(int* a, int n)
{
//排升序,建大堆
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(a, n, i);
}
int end = n - 1;
while (end > 0)
{
Swap(&a[end], &a[0]);
AdjustDown(a, end, 0);
end--;
}
}
堆排序的特性總結:
- 堆排序使用堆來選數,效率高了很多,
- 時間復雜度:O(N*logN)
- 空間復雜度:O(1)
- 穩定性:不穩定
3.交換排序
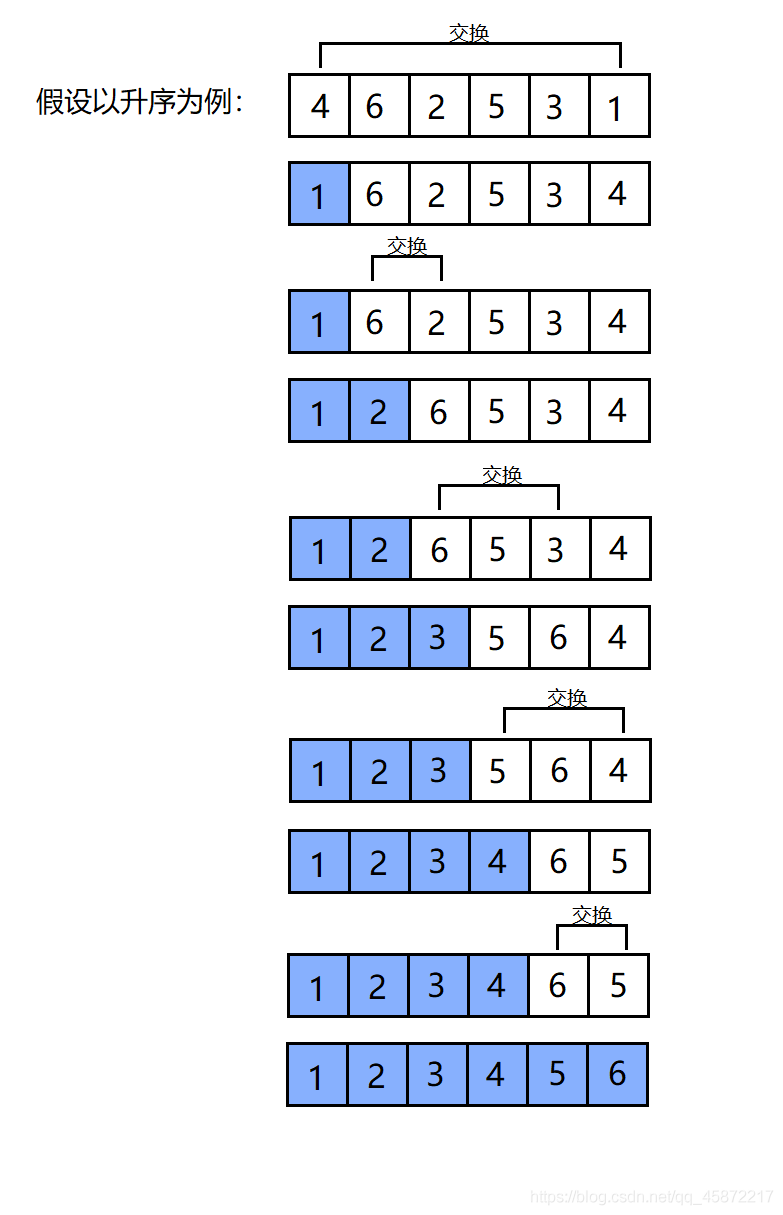
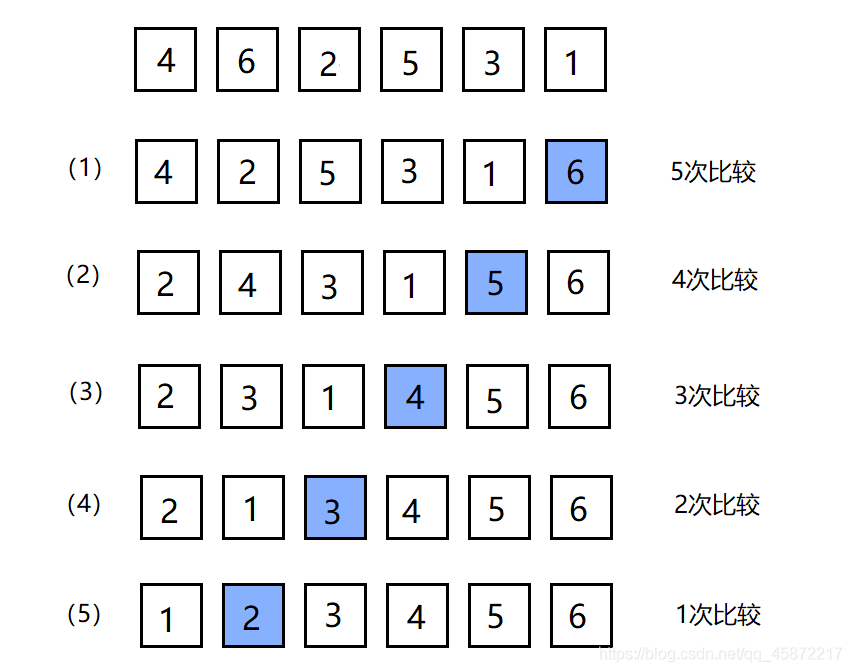
3.1冒泡排序
基本思想:對所有相鄰記錄的關鍵字值進行比效,如果是逆序,則將其交換,最終達到有序的程序,
void BubbleSort(int* a, int n)
{
int end = n;
while (end > 0)
{
int exchange = 0;
for (int i = 1; i < end; i++)
{
if (a[i - 1]>a[i])
{
Swap(&a[i - 1], &a[i]);
exchange = 1;
}
}
if (exchange == 0)
{
break;
}
end--;
}
}
冒泡排序的特性總結:
- 冒泡排序是一種非常容易理解的排序
- 時間復雜度:O(N^2)
- 空間復雜度:O(1)
- 穩定性:穩定
3.2快速排序
基本思想:任取待排序元素序列中的某元素作為基準值,按照該排序碼,將待排序集合分割成兩子序列:左子序列中所有元素均小于基準值,右子序列中所有元素均大于基準值,然后最左右子序列重復該程序,直到所有元素都排列在相應位置上為止,
將區間按斬訓準值劃分為左右兩半部分的常見方式有:
1. 左右指標法(hoare版本)
2. 挖坑法
3. 前后指標法
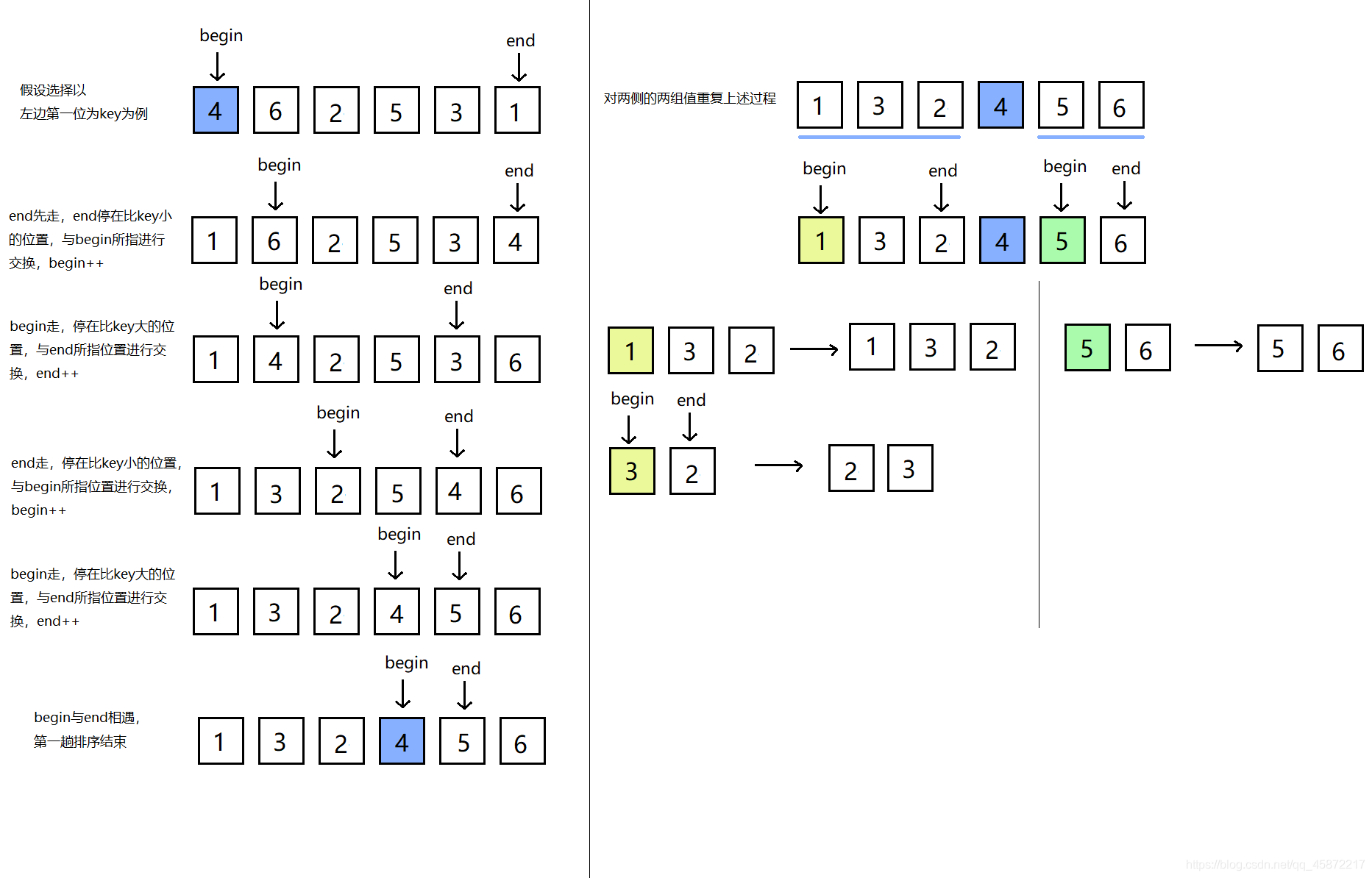
3.2.1快速排序之左右指標法
基本思想:選串列中的一個元素作為基準值,begin指標在第一位找比 它大的值,end指標在最后一位找比它小的值,最終通過一系列的交換,達到基準值的左側都比它小,右側都比它大,
注意:若基準值key選擇左邊第一位,那么要讓end先走,這樣能保證它們相遇的位置是比key小的位置;若選擇右邊第一位,那么讓begin先走,這樣能保證它們相遇的位置是比key大的位置(begin找到大的停下來,然后end去和它相遇),
int QuickSort(int* a, int begin, int end)
{
int key = a[end];
int keyindex = end;
while (begin < end)
{
//begin找大
while (begin < end && a[begin] <= key)
{
begin++;
}
//end找小
while (begin < end && a[end] >= key)
{
end--;
}
Swap(&a[begin], &a[end]);
}
Swap(&a[begin], &a[keyindex]);
int div = begin;//相遇的位置
QuickSort(a, left, div - 1);
QuickSort(a, div + 1, right);
}
3.2.2快速排序之挖坑法
基本思想:選取序列中第一個元素為坑,保存在key中,坑的意思是,這個位置的值被拿走了,可以覆寫,填新的值,那么end先走,找比key的值小的數,填到坑中,end為新的坑,然后begin再走,找比key大的值填入新坑中,直至begin與end相遇結束該趟回圈,
挖坑法與左右指標很類似,因此,參照上圖即可,
int QuickSort(int* a, int begin, int end)
{
int key = a[end];//坑 (這個位置的值被拿走了,可以覆寫,填新的值)
while (begin < end)
{
while (begin < end&&a[begin] <= key)
{
begin++;
}
//左邊找到比key大的填到右邊的坑,然后begin位置就形成了新的坑
a[end] = a[begin];
while (begin < end&&a[end] >= key)
{
end--;
}
//右邊找到比key小的值填到左邊的坑,然后end的位置形成新的坑
a[begin] = a[end];
}
//填一下坑 也就是end和begin相遇的位置
a[begin] = key;
int div = begin;//相遇的位置
QuickSort(a, left, div - 1);
QuickSort(a, div + 1, right);
}
3.2.3快速排序之前后指標法
基本思想:設定兩個指標,分別為prev與cur,prev在cur的前面,選取最后一個元素為基準值,保存至key中, cur找到比key小的值停下,然后prev++,cur和prev位置的值進行交換,
int PartSort3(int* a, int begin, int end)
{
//cur找到比key小的停下,然后prev++;
//然后cur和prev位置的值交換
int prev = begin - 1;
int cur = begin;
int keyIndex = end;
while (cur < end)
{
if (a[cur] < a[keyIndex] && ++prev != cur)
{
Swap(&a[cur], &a[prev]);
}
++cur;
}
Swap(&a[++prev], &a[keyIndex]);
int div = prev;
QuickSort(a, left, div - 1);
QuickSort(a, div + 1, right);
}
快速排序的特性總結:
- 整體的綜合性能和使用場景都比較好
- 時間復雜度分析:
最好的情況:恰巧每次都選到了中位數作為key,那么時間復雜度為O(N*logN)
最壞的情況:key為陣列中最大或最小的那個數,時間復雜度O(N^2) 有序的情況下,
*做出“三數取中”改進,所以不會出現最壞的情況,所以時間復雜度不考慮最壞,因此為O(N logN), - 空間復雜度:O(logN)
- 穩定性:不穩定
快速排序遞回方式的優化:
(1)三數取中法選key:不要選到最大或最小的那個數
int getMidIndex(int *a, int begin, int end)
{
int mid = (begin + end) / 2;
if (a[begin] < a[mid])
{
if (a[mid] < a[end])
{
return mid;
}
else if (a[begin] < a[end])
{
return end;
}
else return begin;
}
else //a[begin] > a[mid]
{
if (a[mid]>a[end])
{
return mid;
}
else if (a[begin] > a[end])
{
return end;
}
else return begin;
}
}
(2) 小區間優化:遞回到小的子區間(如10個元素以下)時,可以考慮使用插入排序,可以減少整體的遞回次數,
3.2.4快速排序之非遞回實作
基本思想:將區間劃分成若干個子區間,利用堆疊的性質,來實作每個區間的有序,
void QuickSortNonR(int* a, int left, int right)
{
//用堆疊來實作
stack st;
stackInit(&st);
stackPush(&st, right);
stackPush(&st, left);
while (!stackEmpty(&st))
{
int begin = stackTop(&st);
stackPop(&st);
int end = stackTop(&st);
stackPop(&st);
//取出堆疊中的區間[begin,end],開始分
int div = QuickSort(a, begin, end);
//[begin, div-1] div [div+1, end]
if (div + 1 < end) //說明該區間中至少有兩個值
{
stackPush(&st, end);
stackPush(&st, div + 1);
}
if (begin < div - 1)
{
stackPush(&st, div - 1);
stackPush(&st, begin);
}
}
stackDestory(&st);
}
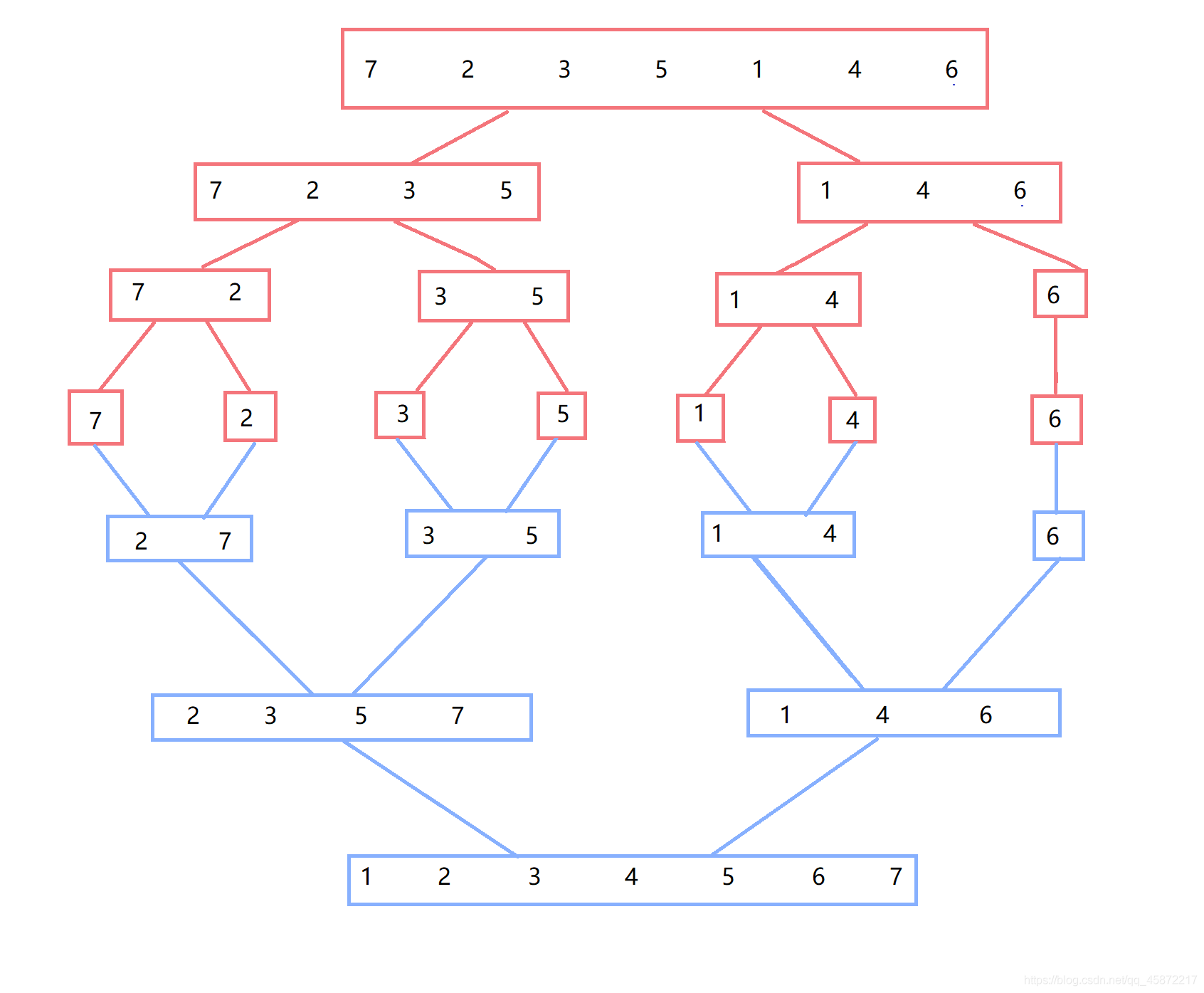
4.歸并排序
4.1歸并排序
基本思想:采用分治法,將已有序的子序列合并,得到完全有序的序列;即先使每個子序列有序,再使子序列段間有序,若將兩個有序表合并成一個有序表,稱為二路歸并,
void MergeArr(int* a, int begin1, int end1, int begin2, int end2, int* temp)
{
int left = begin1, right = end2;
int index = begin1;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
temp[index++] = a[begin1++];
else
temp[index++] = a[begin2++];
}
while (begin1 <= end1)
temp[index++] = a[begin1++];
while (begin2 <= end2)
temp[index++] = a[begin2++];
// 把歸并好的再tmp的資料在拷貝回到原陣列
for (int i = left; i <= right; ++i)
a[i] = temp[i];
}
void _MergeSort(int* a, int left, int right, int* temp)
{
if (left>=right)
{
return;
}
int mid = (left + right) / 2;
//[left,mid] [mid+1,right] 有序,則可以合并,現在它們沒有序,子問題解決
_MergeSort(a, left, mid, temp);
_MergeSort(a, mid + 1, right, temp);
//歸并[left,mid][mid+1,right]有序
MergeArr(a, left, mid, mid + 1, right, temp);
}
// 歸并排序遞回實作
void MergeSort(int* a, int n)
{
int* temp = (int*)malloc(sizeof(int)*n);
_MergeSort(a, 0, n - 1, temp);
free(temp);
}
歸并排序的特性總結:
- 它思考更多的是,解決在磁盤中的外排序問題,
- 時間復雜度:O(N*logN)
- 空間復雜度:O(N) (缺點)
- 穩定性:穩定
4.2歸并排序(非遞回)
void MergeSortNonR(int* a, int n)
{
int* temp = (int*)malloc(sizeof(int)*n);
int gap = 1;//間隔
while (gap < n)
{
for (int i = 0; i < n; i += 2 * gap)
{
//[i,i+gap)[i+gap,i+2*gap)
//[i,i+gap-1][i+gap,i+2*gap-1]
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
//會有越界的情況
//1、合并時只有第一組,第二組不存在,就不需要合并
if (begin2 >= n)
{
break;
}
//2、合并時第二組只有部分資料,需要修正end2邊界
if (end2 >= n)
{
end2 = n - 1;
}
MergeArr(a, begin1, end1, begin2, end2, temp);
}
gap *= 2;
}
free(temp);
}
三、 排序演算法復雜度及穩定性分析
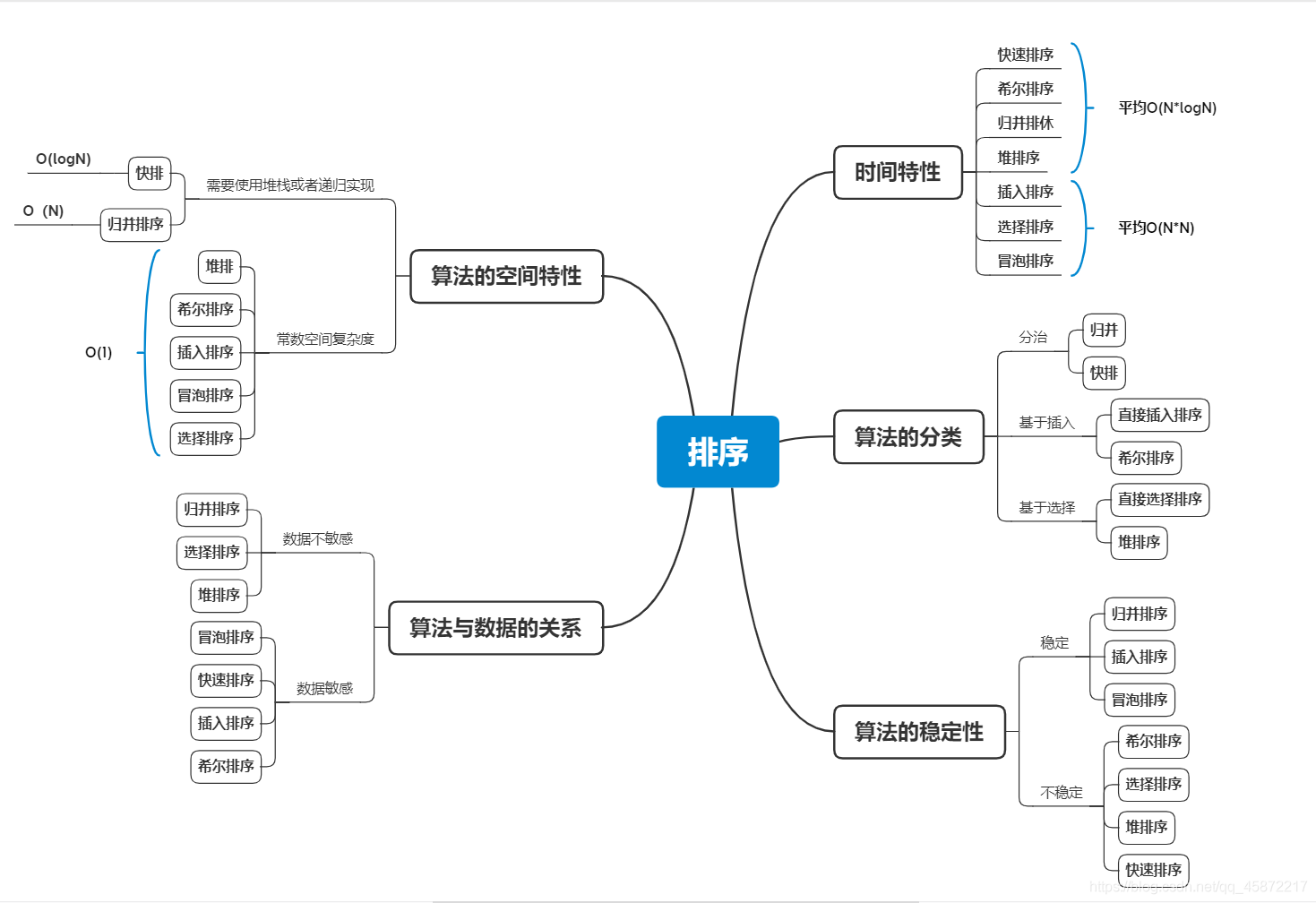
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/256410.html
標籤:其他
上一篇:程式員經常去的6大編程刷題網站,面筆試、復習、挑戰必備!建議收藏
下一篇:一文搞懂Linux行程調度原理