linux行程相關視頻決議:
初識Linux內核,行程通信能這么玩
linux內核,行程調度器的實作,完全公平調度器 CFS
Linux行程調度的目標
1.高效性:高效意味著在相同的時間下要完成更多的任務,調度程式會被頻繁的執行,所以調度程式要盡可能的高效;
2.加強互動性能:在系統相當的負載下,也要保證系統的回應時間;
3.保證公平和避免饑渴;
4.SMP調度:調度程式必須支持多處理系統;
5.軟實時調度:系統必須有效的呼叫實時行程,但不保證一定滿足其要求;
Linux行程優先級
行程提供了兩種優先級,一種是普通的行程優先級,第二個是實時優先級,前者適用SCHED_NORMAL調度策略,后者可選SCHED_FIFO或SCHED_RR調度策略,任何時候,實時行程的優先級都高于普通行程,實時行程只會被更高級的實時行程搶占,同級實時行程之間是按照FIFO(一次機會做完)或者RR(多次輪轉)規則調度的,
首先,說下實時行程的調度
實時行程,只有靜態優先級,因為內核不會再根據休眠等因素對其靜態優先級做調整,其范圍在0MAX_RT_PRIO-1間,默認MAX_RT_PRIO配置為100,也即,默認的實時優先級范圍是099,而nice值,影響的是優先級在MAX_RT_PRIO~MAX_RT_PRIO+40范圍內的行程,
不同與普通行程,系統調度時,實時優先級高的行程總是先于優先級低的行程執行,知道實時優先級高的實時行程無法執行,實時行程總是被認為處于活動狀態,如果有數個 優先級相同的實時行程,那么系統就會按照行程出現在佇列上的順序選擇行程,假設當前CPU運行的實時行程A的優先級為a,而此時有個優先級為b的實時行程B進入可運行狀態,那么只要b<a,系統將中斷A的執行,而優先執行B,直到B無法執行(無論A,B為何種實時行程),
不同調度策略的實時行程只有在相同優先級時才有可比性:
-
對于FIFO的行程,意味著只有當前行程執行完畢才會輪到其他行程執行,由此可見相當霸道,
-
對于RR的行程,一旦時間片消耗完畢,則會將該行程置于佇列的末尾,然后運行其他相同優先級的行程,如果沒有其他相同優先級的行程,則該行程會繼續執行,
總而言之,對于實時行程,高優先級的行程就是大爺,它執行到沒法執行了,才輪到低優先級的行程執行,等級制度相當森嚴啊,
重頭戲,說下非實時行程調度
引子
將當前目錄下的documents目錄打包,但不希望tar占用太多CPU:
nice -19 tar zcf pack.tar.gz documents
這個“-19”中的“-”僅表示引數前綴;所以,如果希望賦予tar行程最高的優先級,則執行:
nice --19 tar zcf pack.tar.gz documents
也可修改已經存在的行程的優先級:
將PID為1799的行程優先級設定為最低:
renice 19 1799
renice命令與nice命令的優先級引數的形式是相反的,直接以優先級值作為引數即可,無“-”前綴說法,
言歸正傳
Linux對普通的行程,根據動態優先級進行調度,而動態優先級是由靜態優先級(static_prio)調整而來,Linux下,靜態優先級是用戶不可見的,隱藏在內核中,而內核提供給用戶一個可以影響靜態優先級的介面,那就是nice值,兩者關系如下:
static_prio=MAX_RT_PRIO +nice+ 20
nice值的范圍是-2019,因而靜態優先級范圍在100139之間,nice數值越大就使得static_prio越大,最終行程優先級就越低,
ps -el 命令執行結果:NI列顯示的每個行程的nice值,PRI是行程的優先級(如果是實時行程就是靜態優先級,如果是非實時行程,就是動態優先級)
而行程的時間片就是完全依賴 static_prio 定制的,見下圖
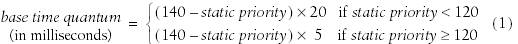
我們前面也說了,系統調度時,還會考慮其他因素,因而會計算出一個叫行程動態優先級的東西,根據此來實施調度,因為,不僅要考慮靜態優先級,也要考慮行程的屬性,例如如果行程屬于互動式行程,那么可以適當的調高它的優先級,使得界面反應地更加迅速,從而使用戶得到更好的體驗,Linux2.6 在這方面有了較大的提高,Linux2.6認為,互動式行程可以從平均睡眠時間這樣一個measurement進行判斷,行程過去的睡眠時間越多,則越有可能屬于互動式行程,則系統調度時,會給該行程更多的獎勵(bonus),以便該行程有更多的機會能夠執行,獎勵(bonus)從0到10不等,
系統會嚴格按照動態優先級高低的順序安排行程執行,動態優先級高的行程進入非運行狀態,或者時間片消耗完畢才會輪到動態優先級較低的行程執行,動態優先級的計算主要考慮兩個因素:靜態優先級,行程的平均睡眠時間也即bonus,計算公式如下,
dynamic_prio = max (100, min (static_prio - bonus + 5, 139))
在調度時,Linux2.6 使用了一個小小的trick,就是演算法中經典的空間換時間的思想[還沒對照原始碼確認],使得計算最優行程能夠在O(1)的時間內完成,
為什么根據睡眠和運行時間確定獎懲分數是合理的
睡眠和CPU耗時反應了行程IO密集和CPU密集兩大瞬時特點,不同時期,一個行程可能即是CPU密集型也是IO密集型行程,對于表現為IO密集的行程,應該經常運行,但每次時間片不要太長,對于表現為CPU密集的行程,CPU不應該讓其經常運行,但每次運行時間片要長,互動行程為例,假如之前其其大部分時間在于等待CPU,這時為了調高相應速度,就需要增加獎勵分,另一方面,如果此行程總是耗盡每次分配給它的時間片,為了對其他行程公平,就要增加這個行程的懲罰分數,
【文章福利】需要C/C++ Linux服務器架構師學習資料加群812855908(資料包括C/C++,Linux,golang技術,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒體,CDN,P2P,K8S,Docker,TCP/IP,協程,DPDK,ffmpeg等)
現代方法CFS
不再單純依靠行程優先級絕對值,而是參考其絕對值,綜合考慮所有行程的時間,給出當前調度時間單位內其應有的權重,也就是,每個行程的權重X單位時間=應獲cpu時間,但是這個應得的cpu時間不應太小(假設閾值為1ms),否則會因為切換得不償失,但是,當行程足夠多時候,肯定有很多不同權重的行程獲得相同的時間——最低閾值1ms,所以,CFS只是近似完全公平,
Linux行程狀態機
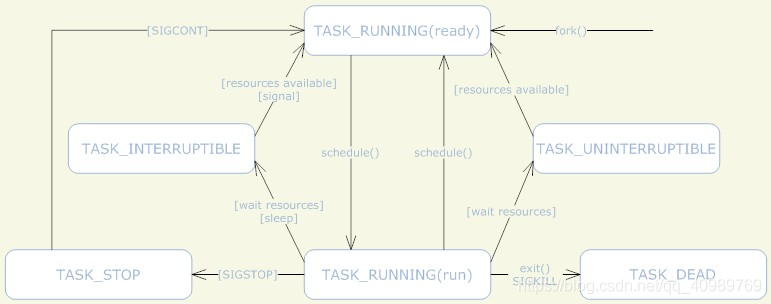
行程是通過fork系列的系統呼叫(fork、clone、vfork)來創建的,內核(或內核模塊)也可以通過kernel_thread函式創建內核行程,這些創建子行程的函式本質上都完成了相同的功能——將呼叫行程復制一份,得到子行程,(可以通過選項引數來決定各種資源是共享、還是私有,)
那么既然呼叫行程處于TASK_RUNNING狀態(否則,它若不是正在運行,又怎么進行呼叫?),則子行程默認也處于TASK_RUNNING狀態,
另外,在系統呼叫clone和內核函式kernel_thread也接受CLONE_STOPPED選項,從而將子行程的初始狀態置為 TASK_STOPPED,
行程創建后,狀態可能發生一系列的變化,直到行程退出,而盡管行程狀態有好幾種,但是行程狀態的變遷卻只有兩個方向——從TASK_RUNNING狀態變為非TASK_RUNNING狀態、或者從非TASK_RUNNING狀態變為TASK_RUNNING狀態,總之,TASK_RUNNING是必經之路,不可能兩個非RUN狀態直接轉換,
也就是說,如果給一個TASK_INTERRUPTIBLE狀態的行程發送SIGKILL信號,這個行程將先被喚醒(進入TASK_RUNNING狀態),然后再回應SIGKILL信號而退出(變為TASK_DEAD狀態),并不會從TASK_INTERRUPTIBLE狀態直接退出,
行程從非TASK_RUNNING狀態變為TASK_RUNNING狀態,是由別的行程(也可能是中斷處理程式)執行喚醒操作來實作的,執行喚醒的行程設定被喚醒行程的狀態為TASK_RUNNING,然后將其task_struct結構加入到某個CPU的可執行佇列中,于是被喚醒的行程將有機會被調度執行,
而行程從TASK_RUNNING狀態變為非TASK_RUNNING狀態,則有兩種途徑:
1、回應信號而進入TASK_STOPED狀態、或TASK_DEAD狀態;
2、執行系統呼叫主動進入TASK_INTERRUPTIBLE狀態(如nanosleep系統呼叫)、或TASK_DEAD狀態(如exit系統呼叫);或由于執行系統呼叫需要的資源得不到滿 足,而進入TASK_INTERRUPTIBLE狀態或TASK_UNINTERRUPTIBLE狀態(如select系統呼叫),
顯然,這兩種情況都只能發生在行程正在CPU上執行的情況下,
通過ps命令我們能夠查看到系統中存在的行程,以及它們的狀態:
R(TASK_RUNNING),可執行狀態,
只有在該狀態的行程才可能在CPU上運行,而同一時刻可能有多個行程處于可執行狀態,這些行程的task_struct結構(行程控制塊)被放入對應CPU的可執行佇列中(一個行程最多只能出現在一個CPU的可執行佇列中),行程調度器的任務就是從各個CPU的可執行佇列中分別選擇一個行程在該CPU上運行,
只要可執行佇列不為空,其對應的CPU就不能偷懶,就要執行其中某個行程,一般稱此時的CPU“忙碌”,對應的,CPU“空閑”就是指其對應的可執行佇列為空,以致于CPU無事可做,
有人問,為什么死回圈程式會導致CPU占用高呢?因為死回圈程式基本上總是處于TASK_RUNNING狀態(行程處于可執行佇列中),除非一些非常極端情況(比如系統記憶體嚴重緊缺,導致行程的某些需要使用的頁面被換出,并且在頁面需要換入時又無法分配到記憶體……),否則這個行程不會睡眠,所以CPU的可執行佇列總是不為空(至少有這么個行程存在),CPU也就不會“空閑”,
很多作業系統教科書將正在CPU上執行的行程定義為RUNNING狀態、而將可執行但是尚未被調度執行的行程定義為READY狀態,這兩種狀態在linux下統一為 TASK_RUNNING狀態,
S(TASK_INTERRUPTIBLE),可中斷的睡眠狀態,
處于這個狀態的行程因為等待某某事件的發生(比如等待socket連接、等待信號量),而被掛起,這些行程的task_struct結構被放入對應事件的等待佇列中,當這些事件發生時(由外部中斷觸發、或由其他行程觸發),對應的等待佇列中的一個或多個行程將被喚醒,
通過ps命令我們會看到,一般情況下,行程串列中的絕大多數行程都處于TASK_INTERRUPTIBLE狀態(除非機器的負載很高),畢竟CPU就這么一兩個,行程動輒幾十上百個,如果不是絕大多數行程都在睡眠,CPU又怎么回應得過來,
D(TASK_UNINTERRUPTIBLE),不可中斷的睡眠狀態,
與TASK_INTERRUPTIBLE狀態類似,行程處于睡眠狀態,但是此刻行程是不可中斷的,不可中斷,指的并不是CPU不回應外部硬體的中斷,而是指行程不回應異步信號,
絕大多數情況下,行程處在睡眠狀態時,總是應該能夠回應異步信號的,否則你將驚奇的發現,kill -9竟然殺不死一個正在睡眠的行程了!于是我們也很好理解,為什么ps命令看到的行程幾乎不會出現TASK_UNINTERRUPTIBLE狀態,而總是TASK_INTERRUPTIBLE狀態,
而TASK_UNINTERRUPTIBLE狀態存在的意義就在于,內核的某些處理流程是不能被打斷的,如果回應異步信號,程式的執行流程中就會被插入一段用于處理異步信號的流程(這個插入的流程可能只存在于內核態,也可能延伸到用戶態),于是原有的流程就被中斷了(參見《linux異步信號handle淺析》),
在行程對某些硬體進行操作時(比如行程呼叫read系統呼叫對某個設備檔案進行讀操作,而read系統呼叫最終執行到對應設備驅動的代碼,并與對應的物理設備進行互動),可能需要使用TASK_UNINTERRUPTIBLE狀態對行程進行保護,以避免行程與設備互動的程序被打斷,造成設備陷入不可控的狀態,(比如read系統呼叫觸發了一次磁盤到用戶空間的記憶體的DMA,如果DMA進行程序中,行程由于回應信號而退出了,那么DMA正在訪問的記憶體可能就要被釋放了,)這種情況下的TASK_UNINTERRUPTIBLE狀態總是非常短暫的,通過ps命令基本上不可能捕捉到,
linux系統中也存在容易捕捉的TASK_UNINTERRUPTIBLE狀態,執行vfork系統呼叫后,父行程將進入TASK_UNINTERRUPTIBLE狀態,直到子行程呼叫exit或exec,
通過下面的代碼就能得到處于TASK_UNINTERRUPTIBLE狀態的行程:
#include <unistd.h>
void main() {
if (!vfork()) sleep(100);
}
編譯運行,然后ps一下:
kouu@kouu-one:~/test$ ps -ax | grep a\.out
4371 pts/0 D+ 0:00 ./a.out
4372 pts/0 S+ 0:00 ./a.out
4374 pts/1 S+ 0:00 grep a.out
然后我們可以試驗一下TASK_UNINTERRUPTIBLE狀態的威力,不管kill還是kill -9,這個TASK_UNINTERRUPTIBLE狀態的父行程依然屹立不倒,
T(TASK_STOPPED or TASK_TRACED),暫停狀態或跟蹤狀態,
向行程發送一個SIGSTOP信號,它就會因回應該信號而進入TASK_STOPPED狀態(除非該行程本身處于TASK_UNINTERRUPTIBLE狀態而不回應信號),(SIGSTOP與SIGKILL信號一樣,是非常強制的,不允許用戶行程通過signal系列的系統呼叫重新設定對應的信號處理函式,)
向行程發送一個SIGCONT信號,可以讓其從TASK_STOPPED狀態恢復到TASK_RUNNING狀態,
當行程正在被跟蹤時,它處于TASK_TRACED這個特殊的狀態,“正在被跟蹤”指的是行程暫停下來,等待跟蹤它的行程對它進行操作,比如在gdb中對被跟蹤的行程下一個斷點,行程在斷點處停下來的時候就處于TASK_TRACED狀態,而在其他時候,被跟蹤的行程還是處于前面提到的那些狀態,
對于行程本身來說,TASK_STOPPED和TASK_TRACED狀態很類似,都是表示行程暫停下來,
而TASK_TRACED狀態相當于在TASK_STOPPED之上多了一層保護,處于TASK_TRACED狀態的行程不能回應SIGCONT信號而被喚醒,只能等到除錯行程通過ptrace系統呼叫執行PTRACE_CONT、PTRACE_DETACH等操作(通過ptrace系統呼叫的引數指定操作),或除錯行程退出,被除錯的行程才能恢復TASK_RUNNING狀態,
Z(TASK_DEAD - EXIT_ZOMBIE),退出狀態,行程成為僵尸行程,
行程在退出的程序中,處于TASK_DEAD狀態,
在這個退出程序中,行程占有的所有資源將被回收,除了task_struct結構(以及少數資源)以外,于是行程就只剩下task_struct這么個空殼,故稱為僵尸,
之所以保留task_struct,是因為task_struct里面保存了行程的退出碼、以及一些統計資訊,而其父行程很可能會關心這些資訊,比如在shell中,$?變數就保存了最后一個退出的前臺行程的退出碼,而這個退出碼往往被作為if陳述句的判斷條件,
當然,內核也可以將這些資訊保存在別的地方,而將task_struct結構釋放掉,以節省一些空間,但是使用task_struct結構更為方便,因為在內核中已經建立了從pid到task_struct查找關系,還有行程間的父子關系,釋放掉task_struct,則需要建立一些新的資料結構,以便讓父行程找到它的子行程的退出資訊,
父行程可以通過wait系列的系統呼叫(如wait4、waitid)來等待某個或某些子行程的退出,并獲取它的退出資訊,然后wait系列的系統呼叫會順便將子行程的尸體(task_struct)也釋放掉,
子行程在退出的程序中,內核會給其父行程發送一個信號,通知父行程來“收尸”,這個信號默認是SIGCHLD,但是在通過clone系統呼叫創建子行程時,可以設定這個信號,
通過下面的代碼能夠制造一個EXIT_ZOMBIE狀態的行程:
#include <unistd.h>
void main() {
if (fork())
while(1) sleep(100);
}
編譯運行,然后ps一下:
kouu@kouu-one:~/test$ ps -ax | grep a\.out
10410 pts/0 S+ 0:00 ./a.out
10411 pts/0 Z+ 0:00 [a.out] <defunct>
10413 pts/1 S+ 0:00 grep a.out
只要父行程不退出,這個僵尸狀態的子行程就一直存在,那么如果父行程退出了呢,誰又來給子行程“收尸”?
當行程退出的時候,會將它的所有子行程都托管給別的行程(使之成為別的行程的子行程),托管給誰呢?可能是退出行程所在行程組的下一個行程(如果存在的話),或者是1號行程,所以每個行程、每時每刻都有父行程存在,除非它是1號行程,
1號行程,pid為1的行程,又稱init行程,
linux系統啟動后,第一個被創建的用戶態行程就是init行程,它有兩項使命:
1、執行系統初始化腳本,創建一系列的行程(它們都是init行程的子孫);
2、在一個死回圈中等待其子行程的退出事件,并呼叫waitid系統呼叫來完成“收尸”作業;
init行程不會被暫停、也不會被殺死(這是由內核來保證的),它在等待子行程退出的程序中處于TASK_INTERRUPTIBLE狀態,“收尸”程序中則處于TASK_RUNNING狀態,
X(TASK_DEAD - EXIT_DEAD),退出狀態,行程即將被銷毀,
而行程在退出程序中也可能不會保留它的task_struct,比如這個行程是多執行緒程式中被detach過的行程(行程?執行緒?參見《linux執行緒淺析》),或者父行程通過設定SIGCHLD信號的handler為SIG_IGN,顯式的忽略了SIGCHLD信號,(這是posix的規定,盡管子行程的退出信號可以被設定為SIGCHLD以外的其他信號,)
此時,行程將被置于EXIT_DEAD退出狀態,這意味著接下來的代碼立即就會將該行程徹底釋放,所以EXIT_DEAD狀態是非常短暫的,幾乎不可能通過ps命令捕捉到,
一些重要的雜項
調度程式的效率
“優先級”明確了哪個行程應該被調度執行,而調度程式還必須要關心效率問題,調度程式跟內核中的很多程序一樣會頻繁被執行,如果效率不濟就會浪費很多CPU時間,導致系統性能下降,
在linux 2.4時,可執行狀態的行程被掛在一個鏈表中,每次調度,調度程式需要掃描整個鏈表,以找出最優的那個行程來運行,復雜度為O(n);
在linux 2.6早期,可執行狀態的行程被掛在N(N=140)個鏈表中,每一個鏈表代表一個優先級,系統中支持多少個優先級就有多少個鏈表,每次調度,調度程式只需要從第一個不為空的鏈表中取出位于鏈表頭的行程即可,這樣就大大提高了調度程式的效率,復雜度為O(1);
在linux 2.6近期的版本中,可執行狀態的行程按照優先級順序被掛在一個紅黑樹(可以想象成平衡二叉樹)中,每次調度,調度程式需要從樹中找出優先級最高的行程,復雜度為O(logN),
那么,為什么從linux 2.6早期到近期linux 2.6版本,調度程式選擇行程時的復雜度反而增加了呢?
這是因為,與此同時,調度程式對公平性的實作從上面提到的第一種思路改變為第二種思路(通過動態調整優先級實作),而O(1)的演算法是基于一組數目不大的鏈表來實作的,按我的理解,這使得優先級的取值范圍很小(區分度很低),不能滿足公平性的需求,而使用紅黑樹則對優先級的取值沒有限制(可以用32位、64位、或更多位來表示優先級的值),并且O(logN)的復雜度也還是很高效的,
調度觸發的時機
調度的觸發主要有如下幾種情況:
1、當前行程(正在CPU上運行的行程)狀態變為非可執行狀態,
行程執行系統呼叫主動變為非可執行狀態,比如執行nanosleep進入睡眠、執行exit退出、等等;
行程請求的資源得不到滿足而被迫進入睡眠狀態,比如執行read系統呼叫時,磁盤高速快取里沒有所需要的資料,從而睡眠等待磁盤IO;
行程回應信號而變為非可執行狀態,比如回應SIGSTOP進入暫停狀態、回應SIGKILL退出、等等;
2、搶占,行程運行時,非預期地被剝奪CPU的使用權,這又分兩種情況:行程用完了時間片、或出現了優先級更高的行程,
優先級更高的行程受正在CPU上運行的行程的影響而被喚醒,如發送信號主動喚醒,或因為釋放互斥物件(如釋放鎖)而被喚醒;
內核在回應時鐘中斷的程序中,發現當前行程的時間片用完;
內核在回應中斷的程序中,發現優先級更高的行程所等待的外部資源的變為可用,從而將其喚醒,比如CPU收到網卡中斷,內核處理該中斷,發現某個socket可讀,于是喚醒正在等待讀這個socket的行程;再比如內核在處理時鐘中斷的程序中,觸發了定時器,從而喚醒對應的正在nanosleep系統呼叫中睡眠的行程;
內核搶占
理想情況下,只要滿足“出現了優先級更高的行程”這個條件,當前行程就應該被立刻搶占,但是,就像多執行緒程式需要用鎖來保護臨界區資源一樣,內核中也存在很多這樣的臨界區,不大可能隨時隨地都能接收搶占,
linux 2.4時的設計就非常簡單,內核不支持搶占,行程運行在內核態時(比如正在執行系統呼叫、正處于例外處理函式中),是不允許搶占的,必須等到回傳用戶態時才會觸發調度(確切的說,是在回傳用戶態之前,內核會專門檢查一下是否需要調度);
linux 2.6則實作了內核搶占,但是在很多地方還是為了保護臨界區資源而需要臨時性的禁用內核搶占,
也有一些地方是出于效率考慮而禁用搶占,比較典型的是spin_lock,spin_lock是這樣一種鎖,如果請求加鎖得不到滿足(鎖已被別的行程占有),則當前行程在一個死回圈中不斷檢測鎖的狀態,直到鎖被釋放,
為什么要這樣忙等待呢?因為臨界區很小,比如只保護“i+=j++;”這么一句,如果因為加鎖失敗而形成“睡眠-喚醒”這么個程序,就有些得不償失了,
那么既然當前行程忙等待(不睡眠),誰又來釋放鎖呢?其實已得到鎖的行程是運行在另一個CPU上的,并且是禁用了內核搶占的,這個行程不會被其他行程搶占,所以等待鎖的行程只有可能運行在別的CPU上,(如果只有一個CPU呢?那么就不可能存在等待鎖的行程了,)
而如果不禁用內核搶占呢?那么得到鎖的行程將可能被搶占,于是可能很久都不會釋放鎖,于是,等待鎖的行程可能就不知何年何月得償所望了,
對于一些實時性要求更高的系統,則不能容忍spin_lock這樣的東西,寧可改用更費勁的“睡眠-喚醒”程序,也不能因為禁用搶占而讓更高優先級的行程等待,比如,嵌入式實時linux montavista就是這么干的,
由此可見,實時并不代表高效,很多時候為了實作“實時”,還是需要對性能做一定讓步的,
多處理器下的負載均衡
前面我們并沒有專門討論多處理器對調度程式的影響,其實也沒有什么特別的,就是在同一時刻能有多個行程并行地運行而已,那么,為什么會有“多處理器負載均衡”這個事情呢?
如果系統中只有一個可執行佇列,哪個CPU空閑了就去佇列中找一個最合適的行程來執行,這樣不是很好很均衡嗎?
的確如此,但是多處理器共用一個可執行佇列會有一些問題,顯然,每個CPU在執行調度程式時都需要把佇列鎖起來,這會使得調度程式難以并行,可能導致系統性能下降,而如果每個CPU對應一個可執行佇列則不存在這樣的問題,
另外,多個可執行佇列還有一個好處,這使得一個行程在一段時間內總是在同一個CPU上執行,那么很可能這個CPU的各級cache中都快取著這個行程的資料,很有利于系統性能的提升,
所以,在linux下,每個CPU都有著對應的可執行佇列,而一個可執行狀態的行程在同一時刻只能處于一個可執行佇列中,
于是,“多處理器負載均衡”這個麻煩事情就來了,內核需要關注各個CPU可執行佇列中的行程數目,在數目不均衡時做出適當調整,什么時候需要調整,以多大力度行程調整,這些都是內核需要關心的,當然,盡量不要調整最好,畢竟調整起來又要耗CPU、又要鎖可執行佇列,代價還是不小的,
另外,內核還得關心各個CPU的關系,兩個CPU之間,可能是相互獨立的、可能是共享cache的、甚至可能是由同一個物理CPU通過超執行緒技術虛擬出來的……CPU之間的關系也是實作負載均衡的重要依據,關系越緊密,行程在它們之間遷移的代價就越小,參見《linux內核SMP負載均衡淺析》,
優先級繼承
由于互斥,一個行程(設為A)可能因為等待進入臨界區而睡眠,直到正在占有相應資源的行程(設為B)退出臨界區,行程A才被喚醒,
可能存在這樣的情況:A的優先級非常高,B的優先級非常低,B進入了臨界區,但是卻被其他優先級較高的行程(設為C)搶占了,而得不到運行,也就無法退出臨界區,于是A也就無法被喚醒,
A有著很高的優先級,但是現在卻淪落到跟B一起,被優先級并不太高的C搶占,導致執行被推遲,這種現象就叫做優先級反轉,
出現這種現象是很不合理的,較好的應對措施是:當A開始等待B退出臨界區時,B臨時得到A的優先級(還是假設A的優先級高于B),以便順利完成處理程序,退出臨界區,之后B的優先級恢復,這就是優先級繼承的方法,
中斷處理執行緒化
在linux下,中斷處理程式運行于一個不可調度的背景關系中,從CPU回應硬體中斷自動跳轉到內核設定的中斷處理程式去執行,到中斷處理程式退出,整個程序是不能被搶占的,
一個行程如果被搶占了,可以通過保存在它的行程控制塊(task_struct)中的資訊,在之后的某個時間恢復它的運行,而中斷背景關系則沒有task_struct,被搶占了就沒法恢復了,
中斷處理程式不能被搶占,也就意味著中斷處理程式的“優先級”比任何行程都高(必須等中斷處理程式完成了,行程才能被執行),但是在實際的應用場景中,可能某些實時行程應該得到比中斷處理程式更高的優先級,
于是,一些實時性要求更高的系統就給中斷處理程式賦予了task_struct以及優先級,使得它們在必要的時候能夠被高優先級的行程搶占,但是顯然,做這些作業是會給系統造成一定開銷的,這也是為了實作“實時”而對性能做出的一種讓步,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/256411.html
標籤:其他