文章目錄
- 哈希散串列
- 小故事
- 加載因子
- 哈希函式的安全
- 我的困惑
- 資料
哈希散串列
需要我說一下什么是哈希表嗎?上面那張圖可以先看一下,然后我搬一段官方話過來,
哈希表(Hash table,也叫散串列),是根據關鍵碼值(Key value)而直接進行訪問的資料結構,也就是說,它通過把關鍵碼值映射到表中一個位置來訪問記錄,以加快查找的速度,這個映射函式叫做散列函式,存放記錄的陣列叫做散串列,
哈希表hashtable(key,value) 就是把Key通過一個固定的演算法函式既所謂的哈希函式轉換成一個整型數字,然后就將該數字對陣列長度進行取余,取余結果就當作陣列的下標,將value存盤在以該數字為下標的陣列空間里,(或者:把任意長度的輸入(又叫做預映射, pre-image),通過散列演算法,變換成固定長度的輸出,該輸出就是散列值,這種轉換是一種壓縮映射,也就是,散列值的空間通常遠小于輸入的空間,不同的輸入可能會散列成相同的輸出,而不可能從散列值來唯一的確定輸入值,簡單的說就是一種將任意長度的訊息壓縮到某一固定長度的訊息摘要的函式,)
而當使用哈希表進行查詢的時候,就是再次使用哈希函式將key轉換為對應的陣列下標,并定位到該空間獲取value,如此一來,就可以充分利用到陣列的定位性能進行資料定位,
具體參考一下你的手機通訊錄,
Hash表在海量資料處理中有著廣泛應用,
我們之前的查找,都是這樣一種思路:集合中拿出來一個元素,看看是否與我們要找的相等,如果不等,縮小范圍,繼續查找,而哈希表是完全另外一種思路:當我知道key值以后,我就可以直接計算出這個元素在集合中的位置,根本不需要一次又一次的查找!
Hash Table的查詢速度非常的快,幾乎是O(1)的時間復雜度,
hash就是找到一種資料內容和資料存放地址之間的映射關系,
小故事
我在知乎上看到這么一個故事,覺得很不錯,跟大家分享一下,
你的車停在了萬達的停車場,你耍玩回來要找車,停車場太大了,不好找啊!!!
第一個辦法是:你對著停車場的車一輛一輛的找,運氣最差時,你搜遍樓下N輛車,發現你的車在末尾——拿術語說,這個復雜度是O(N),
假如所有車按車牌號順序排列,你直接往停車場中間走就行了;如果你的車牌號大于中間那輛車,那么你就往停車場后半部分的中間走,否則就往前半場走……依此類推,
這也是我們比較常用的方法了,二分查找,
那還有沒有更好一點的辦法呢?假設這個停車場非常非常大,大到可以給每個車牌號分配一個固定的停車位;那么只要你把自己的車牌號報給看門老頭,他拎著你的衣領子往后一丟,你就“吧唧”一下掉自己車頂上了——嗯,你看,一車一位,就是這么任性,
對于前面兩個方法的程式實作我就不說了吧,我們來看一下最后一個場景的程式實作:
要實作這么一個程式,需要使用一個陣列,但是這個陣列需要多大呢?
假設車牌號共8位,每位可以使用26個英文字母或10個阿拉伯數字,那么不同的車牌號共有36^8=2821109907456種,
用char陣列,大概要3T空間吧,
顯然,不太現實嘛,
那么,有沒有辦法在得到O(1)的查找效率的同時、又不付出太大的空間代價呢?
有,就是本篇講的哈希表了,
很簡單,我們把你的車牌號看作一個8位36進制的數字;為了方便,我們可以把它轉換成十進制,那么,你的車牌號就是一個不大于2821109907456的數字,現在,我們把你的車牌號除以一萬,只取余數——你看,你的車牌號是不是就和0~10000之間的數字對應起來了?
很好,你的車就停在這個數字對應的停車位上,過去開就是了——O(1)的查找效率!這個“把你的車牌號映射進0~10000之間”的操作,就是所謂的“哈希”或者(當然,實踐上,為了盡量減少沖突,哈希表的空間大小會盡量取質數),
但是,你發現你的車牌尾號和你的朋友的車牌尾號是一樣的啊,那是不是意味著,某一個車位,要停你的車,還要停你朋友的車?
那也不太現實,那這么辦呢?沒錯,hash可能會把不同的資料映射到同一個點上,術語稱其為“碰撞”,
1、實在沒辦法,就在你的車上方再搭建一個車位,然后把你朋友的車放上去吧,
這就是開鏈法,
2、過去的散列函式是 (車牌號 模除 10000),發現碰撞了就換散列函式 (車牌號加1 模除 10000)試一試,
這叫“再散列法”,
3、再修個小車庫,碰撞了的停小車庫去(小車庫可以隨便停,也可以搞一套別的機制)
請注意,因為沖突的存在,哈希表雖然有著優異的平均訪問時間(常數訪問效率!);但它的“最大訪問時間”卻是沒有保證的——你可能一個微秒甚至幾個納秒就拿到了資料,也可能幾十個毫秒了還在鏈表上狂奔,因此實時性要求嚴格的場合,用它前需要謹慎考慮,
如果我們的“鍵值轉換陣列下標的函式(也就是哈希函式)”選擇不當(比如我前面提到的直接求余),就很容易使得“碰撞”頻繁出現,這就對哈希函式的選擇提出了要求,
但是哈希函式本身也不應該過于復雜,不然每次計算耗時太久——O(1)雖然是常數時間;但如果時間常數太長,它可能就不如O(lnN)查找演算法快,
要知道,在一百萬資料里面做二分法搜索,最差時也不過需要20次搜索而已;如果你的哈希函式本身需要的計算時間已經超過了這個限度,那么改用二分法顯然是個更為理智的選擇:不僅更快,還更省空間,
工程問題,向來是需要根據實際情況靈活選擇、做出合理折衷的,
作者:invalid s
鏈接:https://www.zhihu.com/question/330112288/answer/744362539 來源:知乎
著作權歸作者所有,商業轉載請聯系作者獲得授權,非商業轉載請注明出處,
加載因子
無論如何,哈希表中,碰撞無法絕對避免,
當碰撞發生時,就不得不使用開鏈表法或再散列法存盤沖突資料;而這必將影響哈希表的性能,
很容易想到,如果哈希表很大、里面卻沒存幾條資料,那么它出現沖突(碰撞)的幾率就會很小;反之,如果哈希表已經接近滿了,那么每條新加入的資料都會產生碰撞,
哈希表實際所存資料量和哈希表最大容量之間的比值,叫做哈希表的“加載因子”,
加載因子越小,沖突的概率就越低,但浪費大量空間;加載因子越高,沖突概率越大,但空間浪費就越少,這是一個需要根據工程實踐靈活選擇的折衷值,很多語言的hash函式庫允許你主動調節這個值,一般來說,一個較為平衡的加載因子大約是0.7~0.8左右,這樣既不會浪費太多空間,也不至于出現太多沖突,
哈希函式的安全
如果哈希表使用的哈希函式較為簡單,對惡意的攻擊者來說,他可以精心構造一大堆資料提交給你——所有這些資料散列后全都存在一個格子里,
我們前面提到過,當遇到這種沖突/碰撞時,為了避免彼此覆寫,這些資料就要存在鏈表中(或者再散列后存在同一個哈希表中),當這些資料被存進鏈表時,對它們的訪問效率將降到O(N)——因為鏈表搜索效率只有O(N),之前就發生過這種攻擊,包括Java在內的許多種語言全部落馬,
解決方案也很簡單:
1、提高哈希函式復雜度,想辦法加入隨機性(相當于每次使用一個不同的哈希函式),避免被人輕易捕捉到弱點
2、不要用開鏈表法存盤沖突資料,采用“再散列法”,并且使用不同的哈希函式再散列、還可以把沖突資料存入另一個表——要構造同時讓兩個以上不同的哈希函式沖突的攻擊資料,難度就大得多了,
我的困惑
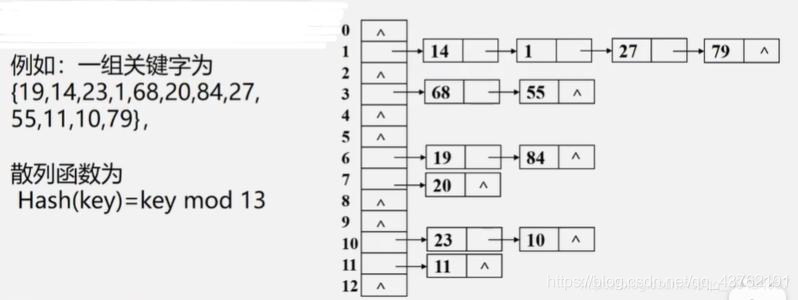
我一開始想到的也是開鏈法,所以開頭那張圖也就是開鏈法的,
但是,開鏈法真的好嗎?
散串列要有多少個初始位置?如果有一億個資料的存盤,二分查找一個資料要20次,哈希要比二分快,那開鏈法的鏈就不要太長了,那需要有多少個哈希節點呢?需要占用多大的存盤空間?
應該是我讀書少吧,
資料
看一下我之前寫好的兩篇,就不復制粘貼過來了,有點大,
那兩篇都是我在網上四處碰壁之后寫的,
【C++ STL】停下你到處找 hash_map 使用教程的手,看我的就好了
【C++】攻克哈希表(unordered_map)

轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/260107.html
標籤:其他
上一篇:情人節禮物 浪漫至死不渝
下一篇:記憶體耗盡后Redis會發生什么