要想用活Redis,Lua腳本是繞不過去的坎
- 前言
- 記憶體回收
- 過期策略
- 8 種淘汰策略
- LRU 演算法
- Redis 改進后的 LRU 演算法
- Redis 如何管理熱度資料
- LFU 演算法
- 訪問頻次遞增
- 訪問頻次遞減
- 總結
前言
作為一臺服務器來說,記憶體并不是無限的,所以總會存在記憶體耗盡的情況,那么當 Redis 服務器的記憶體耗盡后,如果繼續執行請求命令,Redis 會如何處理呢?
記憶體回收
使用Redis 服務時,很多情況下某些鍵值對只會在特定的時間內有效,為了防止這種型別的資料一直占有記憶體,我們可以給鍵值對設定有效期,Redis 中可以通過 4 個獨立的命令來給一個鍵設定過期時間:
expire key ttl:將key值的過期時間設定為ttl秒,pexpire key ttl:將key值的過期時間設定為ttl毫秒,expireat key timestamp:將key值的過期時間設定為指定的timestamp秒數,pexpireat key timestamp:將key值的過期時間設定為指定的timestamp毫秒數,
PS:不管使用哪一個命令,最終 Redis 底層都是使用 pexpireat 命令來實作的,另外,set 等命令也可以設定 key 的同時加上過期時間,這樣可以保證設值和設過期時間的原子性,
設定了有效期后,可以通過 ttl 和 pttl 兩個命令來查詢剩余過期時間(如果未設定過期時間則下面兩個命令回傳 -1,如果設定了一個非法的過期時間,則都回傳 -2):
ttl key回傳key剩余過期秒數,pttl key回傳key剩余過期的毫秒數,
過期策略
如果將一個過期的鍵洗掉,我們一般都會有三種策略:
- 定時洗掉:為每個鍵設定一個定時器,一旦過期時間到了,則將鍵洗掉,這種策略對記憶體很友好,但是對
CPU不友好,因為每個定時器都會占用一定的CPU資源, - 惰性洗掉:不管鍵有沒有過期都不主動洗掉,等到每次去獲取鍵時再判斷是否過期,如果過期就洗掉該鍵,否則回傳鍵對應的值,這種策略對記憶體不夠友好,可能會浪費很多記憶體,
- 定期掃描:系統每隔一段時間就定期掃描一次,發現過期的鍵就進行洗掉,這種策略相對來說是上面兩種策略的折中方案,需要注意的是這個定期的頻率要結合實際情況掌控好,使用這種方案有一個缺陷就是可能會出現已經過期的鍵也被回傳,
在 Redis 當中,其選擇的是策略 2 和策略 3 的綜合使用,不過 Redis 的定期掃描只會掃描設定了過期時間的鍵,因為設定了過期時間的鍵 Redis 會單獨存盤,所以不會出現掃描所有鍵的情況:
typedef struct redisDb {
dict *dict; //所有的鍵值對
dict *expires; //設定了過期時間的鍵值對
dict *blocking_keys; //被阻塞的key,如客戶端執行BLPOP等阻塞指令時
dict *watched_keys; //WATCHED keys
int id; //Database ID
//... 省略了其他屬性
} redisDb;
8 種淘汰策略
假如 Redis 當中所有的鍵都沒有過期,而且此時記憶體滿了,那么客戶端繼續執行 set 等命令時 Redis 會怎么處理呢?Redis 當中提供了不同的淘汰策略來處理這種場景,
首先 Redis 提供了一個引數 maxmemory 來配置 Redis 最大使用記憶體:
maxmemory <bytes>
或者也可以通過命令 config set maxmemory 1GB 來動態修改,
如果沒有設定該引數,那么在 32 位的作業系統中 Redis 最多使用 3GB 記憶體,而在 64 位的作業系統中則不作限制,
Redis 中提供了 8 種淘汰策略,可以通過引數 maxmemory-policy 進行配置:
| 淘汰策略 | 說明 |
|---|---|
| volatile-lru | 根據 LRU 演算法洗掉設定了過期時間的鍵,直到騰出可用空間,如果沒有可洗掉的鍵物件,且記憶體還是不夠用時,則報錯 |
| allkeys-lru | 根據 LRU 演算法洗掉所有的鍵,直到騰出可用空間,如果沒有可洗掉的鍵物件,且記憶體還是不夠用時,則報錯 |
| volatile-lfu | 根據 LFU 演算法洗掉設定了過期時間的鍵,直到騰出可用空間,如果沒有可洗掉的鍵物件,且記憶體還是不夠用時,則報錯 |
| allkeys-lfu | 根據 LFU 演算法洗掉所有的鍵,直到騰出可用空間,如果沒有可洗掉的鍵物件,且記憶體還是不夠用時,則報錯 |
| volatile-random | 隨機洗掉設定了過期時間的鍵,直到騰出可用空間,如果沒有可洗掉的鍵物件,且記憶體還是不夠用時,則報錯 |
| allkeys-random | 隨機洗掉所有鍵,直到騰出可用空間,如果沒有可洗掉的鍵物件,且記憶體還是不夠用時,則報錯 |
| volatile-ttl | 根據鍵值物件的 ttl 屬性, 洗掉最近將要過期資料, 如果沒有,則直接報錯 |
| noeviction | 默認策略,不作任何處理,直接報錯 |
PS:淘汰策略也可以直接使用命令 config set maxmemory-policy <策略> 來進行動態配置,
LRU 演算法
LRU 全稱為:Least Recently Used,即:最近最長時間未被使用,這個主要針對的是使用時間,
Redis 改進后的 LRU 演算法
在 Redis 當中,并沒有采用傳統的 LRU 演算法,因為傳統的 LRU 演算法存在 2 個問題:
- 需要額外的空間進行存盤,
- 可能存在某些
key值使用很頻繁,但是最近沒被使用,從而被LRU演算法洗掉,
為了避免以上 2 個問題,Redis 當中對傳統的 LRU 演算法進行了改造,通過抽樣的方式進行洗掉,
組態檔中提供了一個屬性 maxmemory_samples 5,默認值就是 5,表示隨機抽取 5 個 key 值,然后對這 5 個 key 值按照 LRU 演算法進行洗掉,所以很明顯,key 值越大,洗掉的準確度越高,
對抽樣 LRU 演算法和傳統的 LRU 演算法,Redis 官網當中有一個對比圖:
-
淺灰色帶是被洗掉的物件,
-
灰色帶是未被洗掉的物件,
-
綠色是添加的物件,
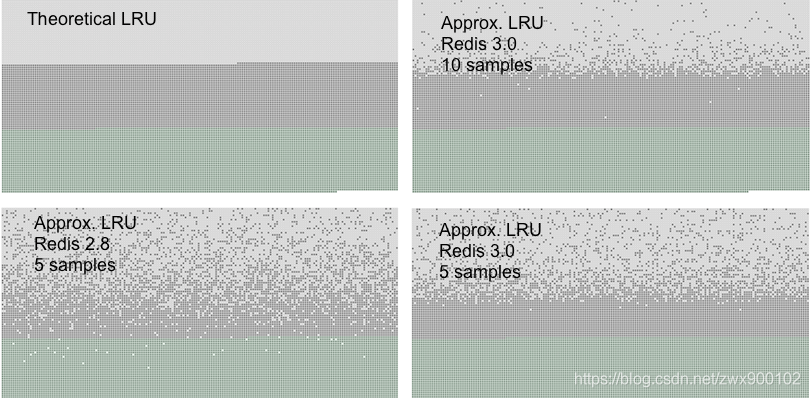
左上角第一幅圖代表的是傳統 LRU 演算法,可以看到,當抽樣數達到 10 個(右上角),已經和傳統的 LRU 演算法非常接近了,
Redis 如何管理熱度資料
前面我們講述字串物件時,提到了 redisObject 物件中存在一個 lru 屬性:
typedef struct redisObject {
unsigned type:4;//物件型別(4位=0.5位元組)
unsigned encoding:4;//編碼(4位=0.5位元組)
unsigned lru:LRU_BITS;//記錄物件最后一次被應用程式訪問的時間(24位=3位元組)
int refcount;//參考計數,等于0時表示可以被垃圾回收(32位=4位元組)
void *ptr;//指向底層實際的資料存盤結構,如:SDS等(8位元組)
} robj;
lru 屬性是創建物件的時候寫入,物件被訪問到時也會進行更新,正常人的思路就是最后決定要不要洗掉某一個鍵肯定是用當前時間戳減去 lru,差值最大的就優先被洗掉,但是 Redis 里面并不是這么做的,Redis 中維護了一個全域屬性 lru_clock,這個屬性是通過一個全域函式 serverCron 每隔 100 毫秒執行一次來更新的,記錄的是當前 unix 時間戳,
最后決定洗掉的資料是通過 lru_clock 減去物件的 lru 屬性而得出的,那么為什么 Redis 要這么做呢?直接取全域時間不是更準確嗎?
這是因為這么做可以避免每次更新物件的 lru 屬性的時候可以直接取全域屬性,而不需要去呼叫系統函式來獲取系統時間,從而提升效率(Redis 當中有很多這種細節考慮來提升性能,可以說是對性能盡可能的優化到極致),
不過這里還有一個問題,我們看到,redisObject 物件中的 lru 屬性只有 24 位,24 位只能存盤 194 天的時間戳大小,一旦超過 194 天之后就會重新從 0 開始計算,所以這時候就可能會出現 redisObject 物件中的 lru 屬性大于全域的 lru_clock 屬性的情況,
正因為如此,所以計算的時候也需要分為 2 種情況:
- 當全域
lruclock>lru,則使用lruclock-lru得到空閑時間, - 當全域
lruclock<lru,則使用lruclock_max(即194天) -lru+lruclock得到空閑時間,
需要注意的是,這種計算方式并不能保證抽樣的資料中一定能洗掉空閑時間最長的,這是因為首先超過 194 天還不被使用的情況很少,再次只有 lruclock 第 2 輪繼續超過 lru 屬性時,計算才會出問題,
比如物件 A 記錄的 lru 是 1 天,而 lruclock 第二輪都到 10 天了,這時候就會導致計算結果只有 10-1=9 天,實際上應該是 194+10-1=203 天,但是這種情況可以說又是更少發生,所以說這種處理方式是可能存在洗掉不準確的情況,但是本身這種演算法就是一種近似的演算法,所以并不會有太大影響,
LFU 演算法
LFU 全稱為:Least Frequently Used,即:最近最少頻率使用,這個主要針對的是使用頻率,這個屬性也是記錄在redisObject 中的 lru 屬性內,
當我們采用 LFU 回收策略時,lru 屬性的高 16 位用來記錄訪問時間(last decrement time:ldt,單位為分鐘),低 8 位用來記錄訪問頻率(logistic counter:logc),簡稱 counter,
訪問頻次遞增
LFU 計數器每個鍵只有 8 位,它能表示的最大值是 255,所以 Redis 使用的是一種基于概率的對數器來實作 counter 的遞增,r
給定一個舊的訪問頻次,當一個鍵被訪問時,counter 按以下方式遞增:
- 提取
0和1之間的亂數R, counter- 初始值(默認為5),得到一個基礎差值,如果這個差值小于0,則直接取0,為了方便計算,把這個差值記為baseval,- 概率
P計算公式為:1/(baseval * lfu_log_factor + 1), - 如果
R < P時,頻次進行遞增(counter++),
公式中的 lfu_log_factor 稱之為對數因子,默認是 10 ,可以通過引數來進行控制:
lfu_log_factor 10
下圖就是對數因子 lfu_log_factor 和頻次 counter 增長的關系圖:
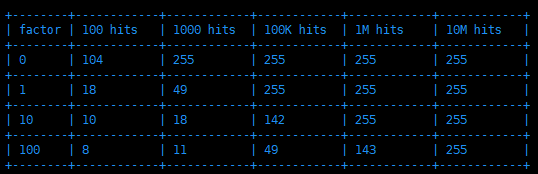
可以看到,當對數因子 lfu_log_factor 為 100 時,大概是 10M(1000萬) 次訪問才會將訪問 counter 增長到 255,而默認的 10 也能支持到 1M(100萬) 次訪問 counter 才能達到 255 上限,這在大部分場景都是足夠滿足需求的,
訪問頻次遞減
如果訪問頻次 counter 只是一直在遞增,那么遲早會全部都到 255,也就是說 counter 一直遞增不能完全反應一個 key 的熱度的,所以當某一個 key 一段時間不被訪問之后,counter 也需要對應減少,
counter 的減少速度由引數 lfu-decay-time 進行控制,默認是 1,單位是分鐘,默認值 1 表示:N 分鐘內沒有訪問,counter 就要減 N,
lfu-decay-time 1
具體演算法如下:
- 獲取當前時間戳,轉化為分鐘后取低
16位(為了方便后續計算,這個值記為now), - 取出物件內的
lru屬性中的高16位(為了方便后續計算,這個值記為ldt), - 當
lru>now時,默認為過了一個周期(16位,最大65535),則取差值65535-ldt+now:當lru<=now時,取差值now-ldt(為了方便后續計算,這個差值記為idle_time), - 取出組態檔中的
lfu_decay_time值,然后計算:idle_time / lfu_decay_time(為了方便后續計算,這個值記為num_periods), - 最后將
counter減少:counter - num_periods,
看起來這么復雜,其實計算公式就是一句話:取出當前的時間戳和物件中的 lru 屬性進行對比,計算出當前多久沒有被訪問到,比如計算得到的結果是 100 分鐘沒有被訪問,然后再去除配置引數 lfu_decay_time,如果這個配置默認為 1也即是 100/1=100,代表 100 分鐘沒訪問,所以 counter 就減少 100,
總結
本文主要介紹了 Redis 過期鍵的處理策略,以及當服務器記憶體不夠時 Redis 的 8 種淘汰策略,最后介紹了 Redis 中的兩種主要的淘汰演算法 LRU 和 LFU,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/260108.html
標籤:其他