基于scattertext的“十二五和十三五規劃”文本分析
二〇二一年是十四五規劃的開篇之年,十二五和十三五規劃的對比研究對開展和實施十四五規劃有著非常重要的指導意義,
本文我將利用scattertext對十二五和十三五規劃進行文本可視化分析,
文本庫:
- 國民經濟和社會發展第十二個五年規劃綱要:全文共16篇,每篇又分多個章節
- 國民經濟和社會發展第十三個五年規劃綱要:全文共20篇,每篇又分多個章節
我將對以上篇章進行分詞和語料分析,最終呈現多角度分析的可視化效果,
本文所有代碼和運行得到的HTML檔案結果均已上傳至我的GitHub,需要的朋友可以自行下載,
1.資料處理
!pip install scattertext
!pip install spacy
!python -m spacy download zh_core_web_sm
import scattertext as st
import pandas as pd
import spacy
from scattertext import SampleCorpora, PhraseMachinePhrases, dense_rank, RankDifference, AssociationCompactor, produce_scattertext_explorer
from scattertext.CorpusFromPandas import CorpusFromPandas
讀入資料,需要提前將文本按照格式存入CSV檔案中,
df = pd.read_csv('plan.csv')
df.head()

欄位解釋
- speaker:每段文本的標題,
- text:每段文本的內容,
- party:所屬類別,因為最終的結果是呈現在x,y軸的一個坐標系上,所以類別只能為兩類,
df.tail()

2.繪制文字散布圖
import zh_core_web_sm
nlp = zh_core_web_sm.load()
corpus = st.CorpusFromPandas(df, category_col='party', text_col='text', nlp=nlp).build()
來看一下十二五規劃中提到的前100個高頻詞吧,
term_freq_df = corpus.get_term_freq_df()
term_freq_df['twelve score'] = corpus.get_scaled_f_scores('十二五')
Twelve_most = list(term_freq_df.sort_values(by='twelve score',ascending=False).index[:100])
print(Twelve_most)

可以看到“社會 管理”、“加快”、“轉變”等詞是十二五規劃中重點強調的內容,
再來看一下十三五規劃提到的前100個高頻詞吧,
term_freq_df['thirteen score'] = corpus.get_scaled_f_scores('十三五')
Thirteen_most = list(term_freq_df.sort_values(by='thirteen score',ascending=False).index[:100])
print(Thirteen_most)

可以看到“資料”、“貧困”、“法治”等詞是十三五規劃重點強調的內容,
開始繪圖,生成可視化的HTML格式的檔案,
html = st.produce_scattertext_explorer(corpus, category='十二五', category_name='十二五', not_category_name='十三五',
width_in_pixels=1000, metadata=df['speaker'])
open("scattertext_01.html",'wb').write(html.encode('utf-8'))
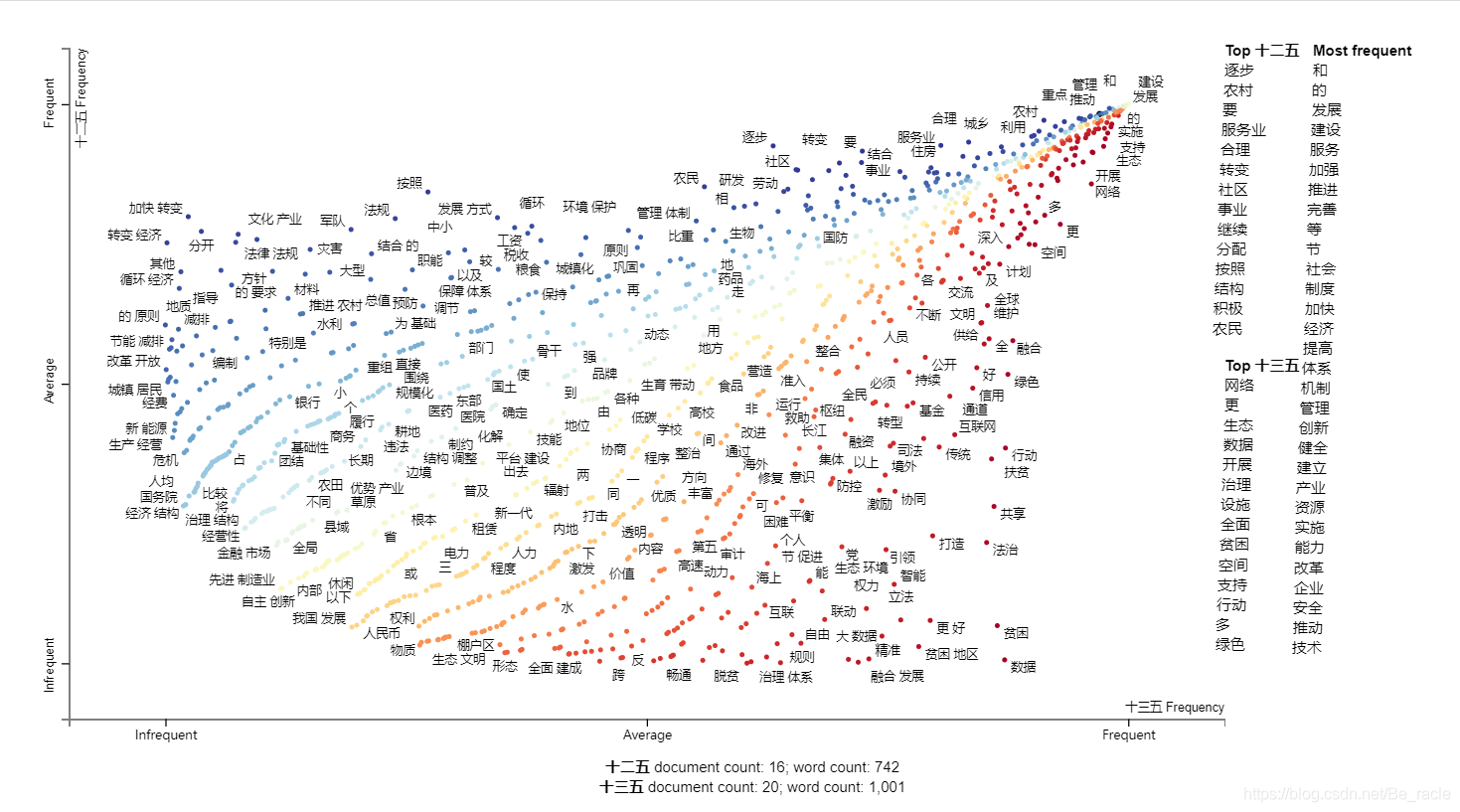
從上圖可以看到十二五規劃聚焦于轉變、回圈、節能等,十三五規劃聚焦于資料、脫貧、法治等,建設和發展則是二者共同的主題,
在圖中用滑鼠點擊“轉變 經濟”,

從上圖可以看到關于“轉變 經濟”一詞,十二五提到的頻率要高于十三五,
在圖中用滑鼠點擊“資料”,

顯然,“資料”這個概念是十三五規劃最新提出來的,
3.構建主題模型
接下來,我們構建主題模型,這里的主題是通過觀察上面的可視化結果進行選擇的,我一共選擇了文化、民生、脫貧、生態、改革、科技六大主題,
topic_model = { '文化':['文化','文明'],
'民生':['收入','社區','分配','管理'],
'脫貧':['脫貧','地區','農村','摘帽'],
'生態':['綠色','生態','環境','環保'],
'改革':['發展','轉變','深入','回圈','創新'],
'科技':['資料','互聯網','網路','現代化','科技']
}
topic_feature_builder = st.FeatsFromTopicModel(topic_model)
topic_corpus = st.CorpusFromParsedDocuments(df,category_col='party',parsed_col='text',feats_from_spacy_doc=topic_feature_builder).build()
html = st.produce_scattertext_explorer(
topic_corpus,
category='十二五',
category_name='十二五',
not_category_name='十三五',
width_in_pixels=1000,
metadata=df['speaker'],
use_non_text_features=True,
use_full_doc=True,
pmi_threshold_coefficient=0,
topic_model_term_lists=topic_feature_builder.get_top_model_term_lists()
)
open('scattertext_02.html','wb').write(html.encode('utf-8'))

點擊“科技”主題

可以看到“科技”這一主題在十二五和十三五中的提及情況,
4.利用SVD降維重繪圖形
利用SVD降維,字詞的向量表示,
from sklearn.feature_extraction.text import TfidfTransformer
from scipy.sparse.linalg import svds
df['parse'] = df['text'].apply(st.whitespace_nlp_with_sentences)
corpus = (st.CorpusFromParsedDocuments(df,category_col='party',parsed_col='parse').build()
.get_stoplisted_unigram_corpus()
.remove_infrequent_words(minimum_term_count=1,term_ranker=st.OncePerDocFrequencyRanker))
embeddings = TfidfTransformer().fit_transform(corpus.get_term_doc_mat())
corpus.get_num_docs()
corpus.get_num_terms()
embeddings = embeddings.T
U, S, VT = svds(embeddings, k=3, maxiter=20000, which='LM')
print(U.shape, S.shape, VT.shape)
x_dim=0
y_dim=1
projection = pd.DataFrame({'term':corpus.get_terms(),'x':U.T[x_dim],'y':U.T[y_dim]}).set_index('term')
print(len(projection))
projection
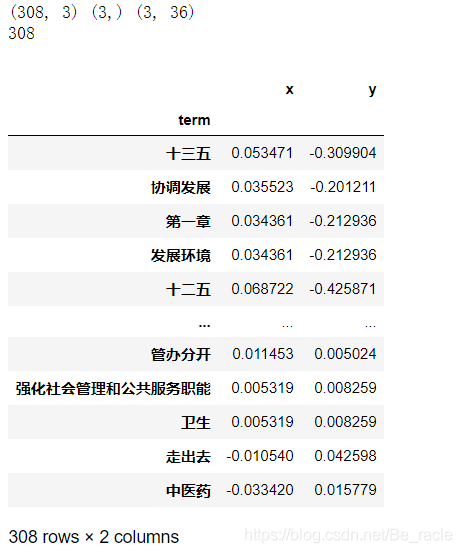
html = st.produce_pca_explorer(corpus,
category='十二五',
category_name='十二五',
not_category_name='十三五',
projection=projection,
metadata=df['speaker'],
width_in_pixels=1000,
scaler = st.scale_neg_1_to_1_with_zero_mean,
x_dim=x_dim,
y_dim=y_dim)
open('scattertext_03.html','wb').write(html.encode('utf-8'))
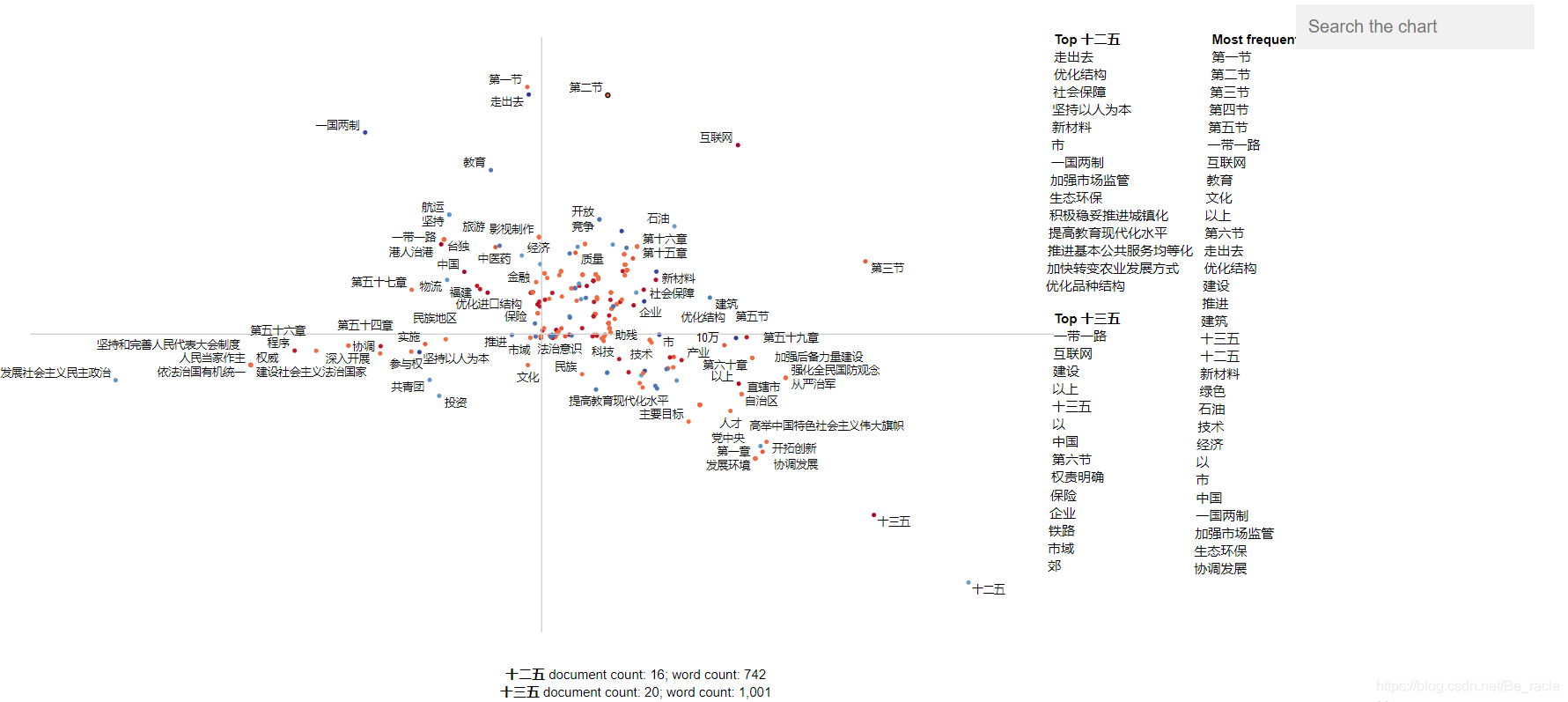
5.以文章為單位繪圖
#用句子斷開文章
df['parse'] = df['text'].apply(st.whitespace_nlp_with_sentences)
corpus = (st.CorpusFromParsedDocuments(df,category_col='party',parsed_col='parse').build()
.get_stoplisted_unigram_corpus())
corpus = corpus.add_doc_names_as_metadata(corpus.get_df()['speaker'])
embeddings = TfidfTransformer().fit_transform(corpus.get_term_doc_mat())
#SVD降維
u, s, vt = svds(embeddings, k=3, maxiter=20000, which='LM')
projection = pd.DataFrame({'term':corpus.get_metadata(), 'x':u.T[0], 'y':u.T[1]}).set_index('term')
category='十二五'
scores = (corpus.get_category_ids() == corpus.get_categories().index(category)).astype(int)
html = st.produce_pca_explorer(corpus,
category=category,
category_name='十二五',
not_category_name='十三五',
metadata=df['speaker'],
width_in_pixels=1000,
scaler = st.scale_neg_1_to_1_with_zero_mean,
show_axes=False,
use_non_text_features=True,
use_full_doc=True,
projection=projection,
scores=scores,
show_top_terms=True)
open('scattertext_04.html','wb').write(html.encode('utf-8'))
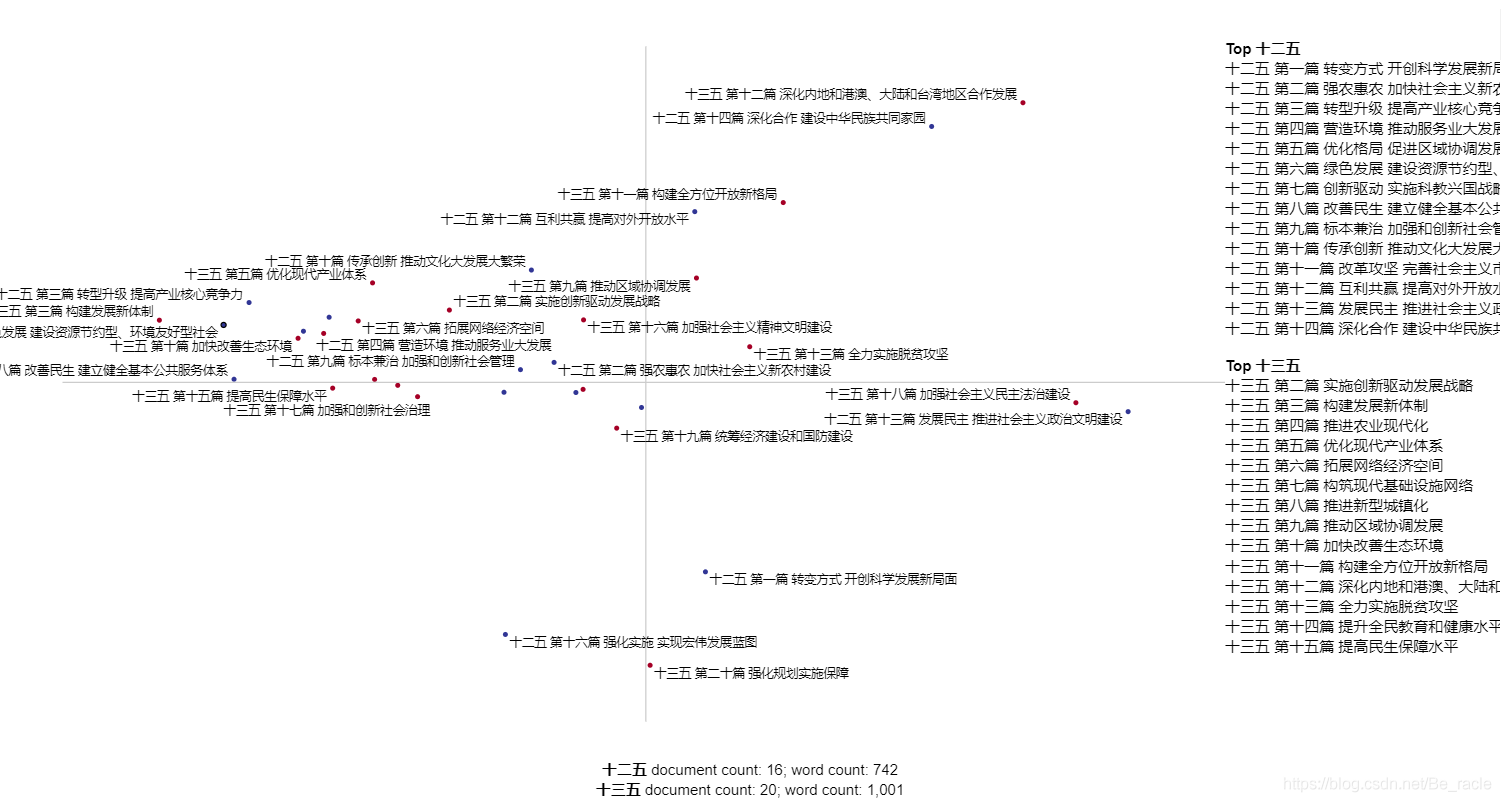
6.總結
從前面的可視化分析可以看出,也會出現一些“和”、“的”、“等”、“第一節”、“第二節”等不在我們期望范圍內的詞,原因在于我匯入的是未經處理的文本資訊,也就是沒有經過分詞的完整篇章,而scattertext會自動進行分詞,且不會做出任何篩選,
為了保留語料的完整性,我保留下來了這些詞,當然我們可以通過技術手段篩選掉這些詞,從而達到更好的可視化分析效果,
接下來,我希望可以利用streamlit或者是dash基于本文的基礎上構建一個文本可視化分析小系統,用戶只需上傳自己需要分析的文本就可以自動地得到分析結果,
本文所有的代碼和運行得到的HTML檔案結果均已上傳至我的GitHub,需要的朋友可以自行下載,
https://github.com/Beracle/05-Scattertext-Twelve-and-Thirteen-Plan
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/260633.html
標籤:其他