租房資訊爬蟲實戰
- 摘要
- 1.技術選型
- 1.1 Selenium
- 1.2 MySql
- 2 程式思路
- 3 程式實作(python selenium)
- 3.1 引入需要的包
- 3.2 初始化驅動和資料庫連接
- 3.3 建表
- 3.4 具體資料爬取
- 4 爬取效果
- 5 小結
摘要
爬蟲有風險,謹慎防入獄,你我皆是遵紀守法的好公民,怎么會爬蟲這種面向監獄編程的技巧呢?這次就發幾個簡單的請求抓兩條資料吧,筆者以前曾經也專門做過爬蟲的作業(人稱爬哥),后來見各位同行入獄筆者見事不妙跑路了,首先爬蟲只是一種工具,望諸君堅守本心,在允許的情況下抓抓資料還是莫得問題的,這次筆者將使用python大法,再配合自動化神器selenium來爬個正經網站,
1.技術選型
1.1 Selenium
Selenium 是一個用于Web應用程式測驗的工具,Selenium測驗直接運行在瀏覽器中,就像真正的用戶在操作一樣,支持的瀏覽器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera,Edge等,這個工具的主要功能包括:測驗與瀏覽器的兼容性——測驗你的應用程式看是否能夠很好得作業在不同瀏覽器和作業系統之上,測驗系統功能——創建回歸測驗檢驗軟體功能和用戶需求,支持自動錄制動作和自動生成 .Net、Java、Perl等不同語言的測驗腳本,1
筆者本次爬取主要是使用Selenium的webDriver,這就是一個瀏覽器驅動,通過它來可以實作瀏覽器的一系列自動化操作,就是和我們瀏覽使用瀏覽器是一摸一樣的,只是現在我們是通過代碼來操作,
If you want to create robust, browser-based regression automation suites and tests, scale and distribute scripts across many environments, then you want to use Selenium WebDriver, a collection of language specific bindings to drive a browser - the way it is meant to be driven,2
使用webDriver來實作瀏覽器自動化操作,
1.2 MySql
Mysq想必不用再多廢話了,免費開源大法就是好,總所周知的關系型資料庫,本次實戰用來存盤爬取的資料,
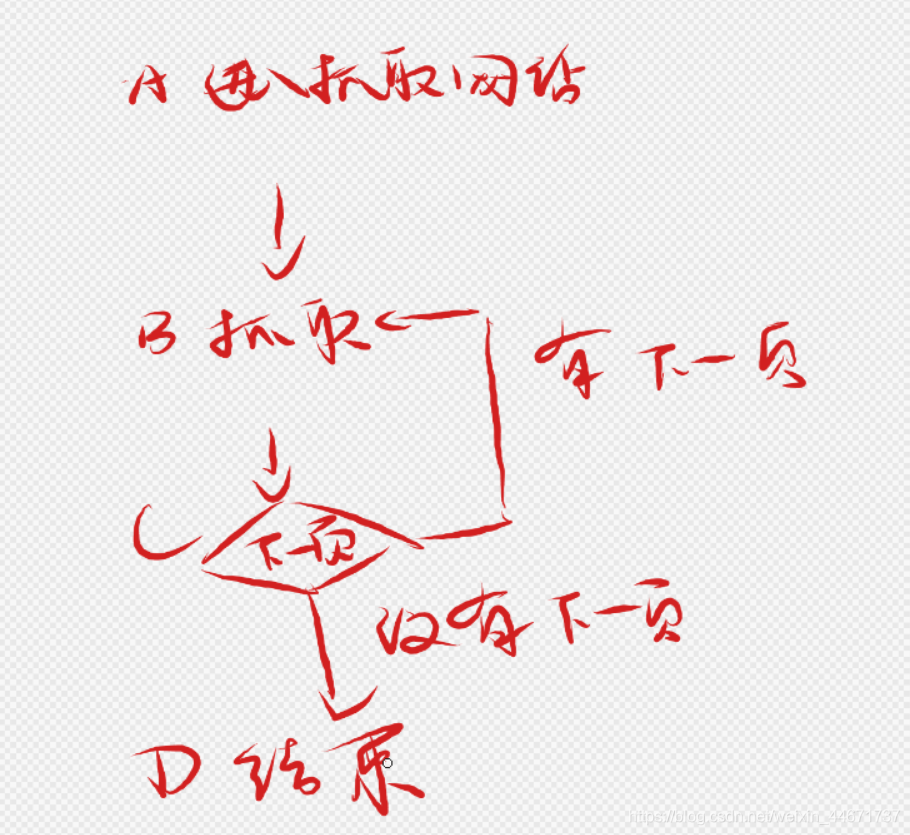
2 程式思路
整個爬蟲的資料抓取思路非常簡單,
- 進入要抓取資料的網站頁面,
- 開始抓取資料,
- 查看下一頁資料,如果成功進入下一頁則重復第2步,
- 第3步失敗沒有下一頁資料則結束,
3 程式實作(python selenium)
3.1 引入需要的包
使用selenium的webdriver來控制瀏覽器,使用pymysql操作資料庫用于保存資料,使用time來設定爬取速率,間隔時間設定,
from selenium import webdriver
import pymysql
import time
3.2 初始化驅動和資料庫連接
獲取mysql連接,
def get_conn():
conn = pymysql.connect(host="localhost",
port=你的埠,
user="你的用戶",
passwd="你的密碼",
db="你的db",
charset='utf8')
return conn
初始化webdriver,
driver_path = r"你的驅動位置\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path)
# 獲取一個連接
conn = get_conn()
cursor = conn.cursor()
3.3 建表
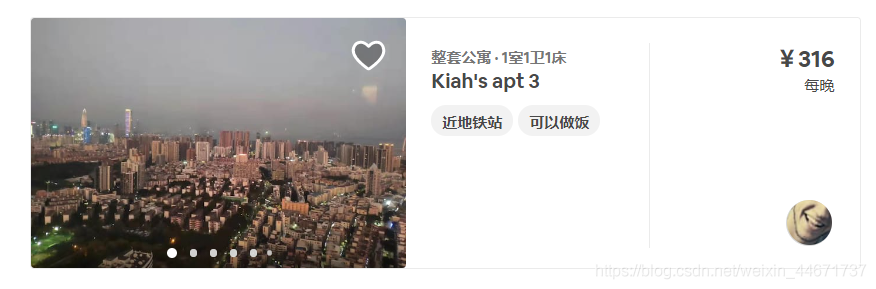
建表前需要根據要獲取的網站資訊的結構進行建表,筆者根據租房網站的資訊完成了下表構建,這個主要看網站上瀏覽到的資料的關系來,筆者要爬取的資料條目頁面上如下,所以就選取了能看到的價格戶型圖片等主要資訊作為建表屬性,
CREATE TABLE `sz` (
`image_url` varchar(255) DEFAULT NULL,
`house_type` varchar(255) DEFAULT NULL,
`apart_name` varchar(255) DEFAULT NULL,
`price` varchar(20) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
3.4 具體資料爬取
- 進入爬取頁面
def goto_url():
url = "https://www.airbnb.cn/s/Shenzhen--China/homes?screen_size=medium&refinement_paths%5B%5D=%2Fhomes&place_id=ChIJkVLh0Aj0AzQRyYCStw1V7v0&click_referer=t%3ASEE_ALL%7Csid%3A342ab702-9117-480e-aee0-4983237764f0%7Cst%3AMAGAZINE_HOMES&title_type=MAGAZINE_HOMES&last_search_session_id=342ab702-9117-480e-aee0-4983237764f0"
driver.get(url)
- 決議爬取資訊
def get_detail_info():
elements = driver.find_elements_by_class_name("_8ssblpx")
print(elements)
for element in elements:
try:
image_url = str(element.find_element_by_css_selector("._e296pg > div > div > div > a > div > img").get_attribute("src"))
house_type = str(element.find_element_by_css_selector("._10ejfg4u > div > div > a > div._1dir9an > div:nth-child(1) > div > div > span > span").text)
apart_name = str(element.find_element_by_css_selector("._10ejfg4u > div > div > a > div._1dir9an > div:nth-child(2) > div > div").text)
price = str(element.find_element_by_css_selector("._10ejfg4u > div > div > a > div._1uomq46 > div._qg0ydb > div._1orel7j7 > div > span:nth-child(2)").text)
print(sql % (image_url, house_type, apart_name, price))
cursor.execute(sql % (image_url, house_type, apart_name, price))
except Exception as e:
print(e)
conn.commit()
- 跳轉到下一頁
def goto_next():
driver.find_element_by_css_selector("#site-content > div > div > div > div._1kss53yu > div > div > div > div._99vlue > div._jro6t0 > a._za9j7e").click()
# driver.execute('document.querySelector("#site-content > div > div > div > div._1kss53yu > div > div > div > div._99vlue > div._jro6t0 > a._za9j7e").click()')
- 執行
goto_url()
while True:
time.sleep(2)
get_detail_info()
time.sleep(2)
goto_next()
4 爬取效果
需要爬取的資料全部保存到資料庫了,是不是so easy!

5 小結
新年期間擼代碼真是痛快,一直寫代碼一直爽,擼完代碼寫博客,這個程式還是很簡單的,筆者寫這個的時候一會兒就寫完了,不過這也得益于筆者很久以前專門做過爬蟲相關作業,對于Http,Tcp之類協議也比較熟悉,對于什么網路爬蟲這不是灑灑水手到擒來,在做爬蟲時應該掌味訓本的html標簽,http協議等相關知識,有了一定的基礎后爬蟲是很簡單的,不過現在的反爬技術也越來越強了,還是得不斷精進才能與時俱進呀!感謝諸君垂閱,

百度百科Selenium詞條 ??
百度百科Selenium 官網WebDriver介紹, ??
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/260636.html
標籤:其他
上一篇:簡單健康打卡爬蟲腳本
下一篇:文藝平衡樹演算法