原文作者:逖靖寒的世界
原文地址:分布式實時統計系統--RAINBIRD
最近Twitter開發了一款分布式實時統計系統Rainbird,Rainbird可以用于實時資料的統計:
- 統計網站中每一個頁面,域名的點擊次數
- 內部系統的運行監控(統計被監控服務器的運行狀態)
- 記錄最大值和最小值
性能要求
作為大型網站的分布式應用,需要具備以下性能:
- 極高的寫入性能,可以達到100,000的WPS
- 非常高的讀取性能,可以達到10,000s的RPS
- 高度的可擴展性,包括讀取和存盤等等,能夠擴展到100+ TB的量級
- 讀取速度回應間隔短,絕大多數的讀取速度應該不超過100ms
系統組件
Rainbird一款基于Zookeeper, Cassandra, Scribe, Thrift的分布式實時統計系統,這些基礎組件的基本功能如下:
- Zookeeper:Hadoop子專案中的一款分布式協調系統,用于控制分布式系統中各個組件中的一致性,
- Cassandra:NoSQL中一款非常出色的產品,集合了Dynamo和Bigtable特性的分布式存盤系統,用于存盤需要進行統計的資料,并且提供客戶端進行統計資料的查詢,(需要使用分布式Counter補丁CASSANDRA-1072)
- Scribe:Facebook開源的一款分布式日志收集系統,用于在系統中將各個需要統計的資料源收集到Cassandra中,
- Thrift:Facebook開源的一款跨語言C/S網路通信框架,開發人員基于這個框架可以輕易地開發C/S應用,
整體設計
Rainbird的設計架構圖如下:
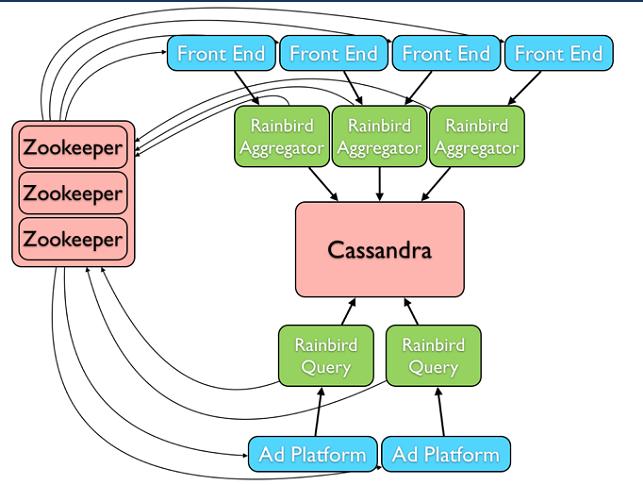
整個Rainbird系統中各個組件之間的協調和容災處理由ZooKeeper負責,Cassandra負責整個資料的存盤和統計,Front End中部署了Scribe,收集需要統計的資料,然后將收集到資料實時地發生到Rainbird Aggregator中,Rainbird Aggregator將快取收集的資料(1M),并將快取的資料進行一次預處理,然后再將資料一次性批量寫入到Cassandra中,這里預處理的作用類似于MapReduce框架中的combiner的作用,在Maper端做Reduce,Rainbird Query接受用戶的查詢請求,直接到Cassandra中查詢已經統計好的資料回傳給客戶端,
頁面URL統計示例
假設我們需要統計網站的頁面點擊的情況,那么如何使用Rainbird來進行統計呢?在統計的程序中,本博客中一篇文章的URL為:http://www.cnblogs.com/gpcuster/tag/Cassandra/,我們可以將這個URL分拆為以下四個部分com、cnblogs、www、http://www.cnblogs.com/gpcuster/tag/Cassandra/ 然后以分拆后的這四個部分組合為以下Key:
- com,cnblogs,www,http://www.cnblogs.com/gpcuster/tag/Cassandra/
- com,cnblogs,www
- com,cnblogs
- com
最后將這些Key的資料寫入Cassandra中,這樣就完成了整個統計的程序,如果需要查詢頁面http://www.cnblogs.com/gpcuster/tag/Cassandra/被訪問了多少次,只要在Cassandra中查詢Key為com,cnblogs,www,http://www.cnblogs.com/gpcuster/tag/Cassandra/的值即可,如果需要查詢頁面http://www.cnblogs.com被訪問了多少次,只要在Cassandra中查詢Key為com,cnblogs,www的值即可,如果要查詢頁面http://*cnblogs.com被訪問了多少次,也可以進行類似的查詢即可,
更多參考
- 如果希望了解更詳細的資訊,可以參考:http://www.slideshare.net/kevinweil/rainbird-realtime-analytics-at-twitter-strata-2011
- 另外,想了解更多關于Cassandra的資訊,可以參考:http://www.cnblogs.com/gpcuster/tag/Cassandra/
- 想了解更多關于ZooKeeper的資訊,可以參考:http://www.cnblogs.com/gpcuster/tag/ZooKeeper/
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/261000.html
標籤:其他
上一篇:寫在2021年上班的第一天