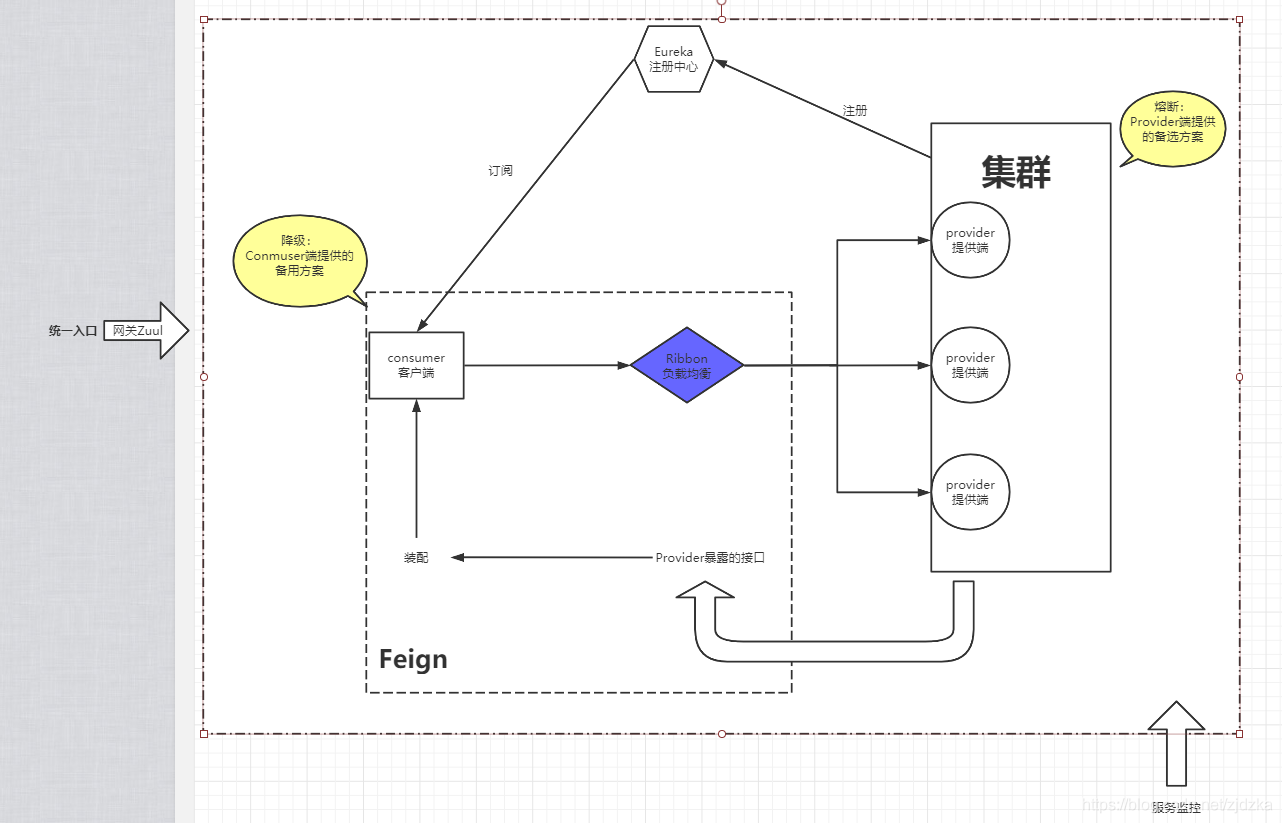
Spring Cloud 是一套完整的微服務解決方案,基于 Spring Boot 框架,準確的說,它不是一個框架,而是一個大的容器,它將市面上較好的微服務框架集成進來,從而簡化了開發者的代碼量,
SpringCloud框架
- 一、核心
- 二、組件介紹
- 三、Eureka注冊中心
- 3.1組態檔
- 3.2啟動類
- 3.3對比Zookeeper
- 四、Ribbon客戶端負載均衡
- 4.1Ribbon是什么?
- 4.2Ribbon能干嘛?
- 4.3集群的搭建
- 五、Feign負載均衡
- 5.1簡介
- 5.2feign能干嘛?
- 5.3對比之前的客戶端
- 六、服務熔斷Hystrix
- 6.1什么是Hystrix?
- 6.2服務熔斷
- 6.3服務降級
- 七、路由網關Zuul
- 7.1概述
- 7.2組態檔
- 7.3啟動類
一、核心
SpringCloud框架的核心其實就是基于Http協議,這也是它與Dubbo最本質的區別,
Dubbo:基于RPC
SpringCloud:基于Http
二、組件介紹
SpringCloud有幾個重要的組件:
- 注冊中心:Eureka
- 客戶端負載均衡:Ribbon
- 宣告式遠程方法呼叫:Feign
- 服務降級、熔斷:Hystrix
- 網關:Zuul
三、Eureka注冊中心
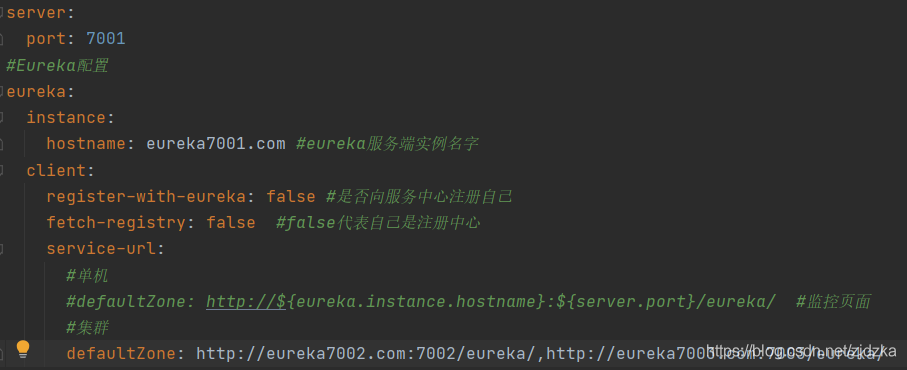
3.1組態檔
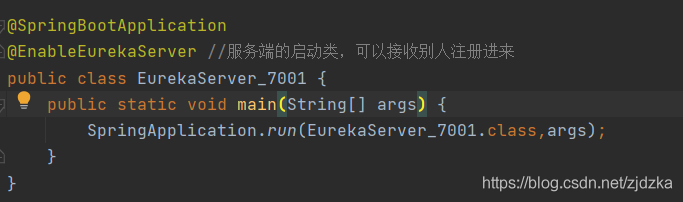
3.2啟動類
一定不能忘記了注解!!!
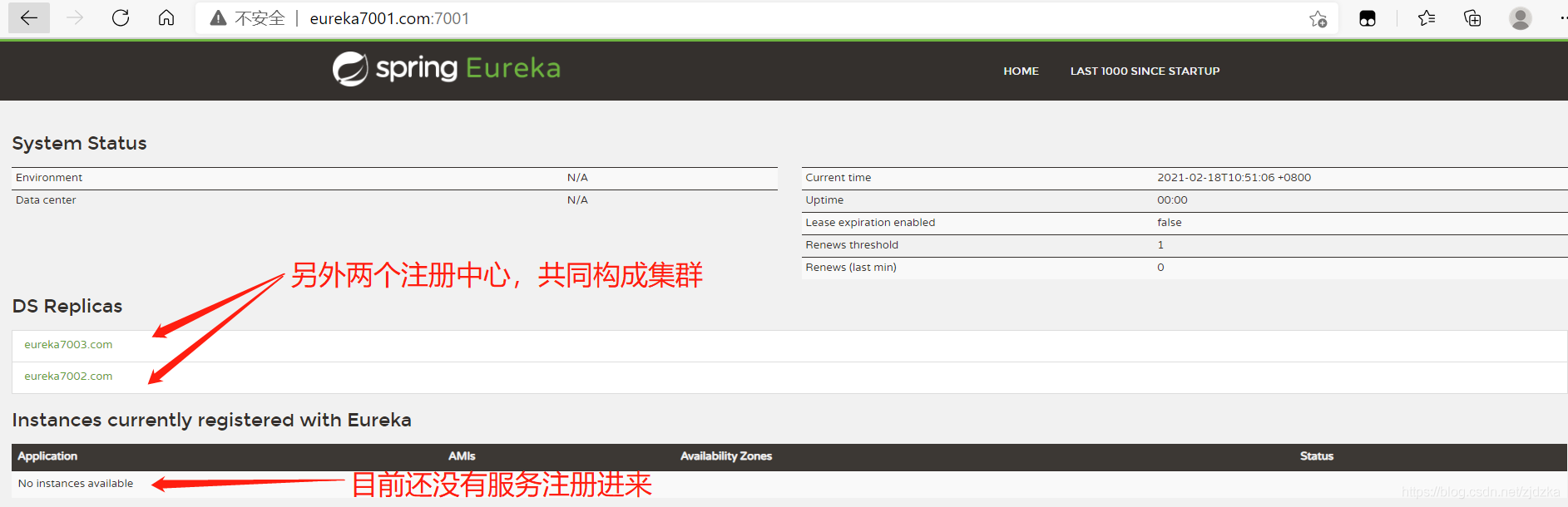
3.3對比Zookeeper
我們知道zookeeper也是注冊中心,那么它和Eureka又有什么區別呢?
回顧一下CAP原則:
- C(consistency) :強一致性
- A(availability) :可用性
- P(partition tolerance) :磁區容錯性
CAP原則遵循三選二:CA,CP,AP
| Zookeeper | Eureka | |
|---|---|---|
| 遵循的原則 | CP:一致性、容錯性 | AP:可用性、容錯性 |
| 理解 | 當向注冊中心查詢服務串列時,我們可以容忍注冊中心回傳的是幾分鐘以前的注冊資訊,但不能接受服務直接down掉不可用,也就是說,服務注冊功能對可用性的要求要高于一致性,但是zk會出現這樣一種情況,當master節點因為網路故障與其他節點失去聯系時,剩下節點會重新進行leader選舉,問題在于,選舉leader的時間太長,30-120s且選舉期間整個zk集群都是不可用的,這就導致在選舉期間注冊服務癱癱,在云部署的環境下,因為網路問題使得zk集群失去掌握節點是較大概率會發生的事件,雖然服務最終能夠恢復,但是漫長的選舉時間導致的注冊長期不可用是不能容忍的. | Eureka各個節點都是平等的,幾個節點掛掉不會影響正常節點的作業,剩余的節點依然可以提供注冊和查詢服務,而Eureka的客戶端在向某個Eureka注冊時,如果發現連接失敗,則會自動切換至其他節點,只要有一臺Eureka還在,就能保住注冊服務的可用性,只不過查到的資訊可能不是最新的,除此之外,Eureka還有一種自我保護機制,如果在15分鐘內超過85%的節點都沒有正常的心跳,那么Eureka就認為客戶端與注冊中心出現了網路故障,此時會出現以下幾種情況: 1. Eureka不再從注冊串列中移除因為長時間沒收到心跳而應該過期的服務 2. Eureka仍然能夠接受新服務的注冊和查詢請求,但是不會被同步到其他節點上(即保證當前節點依然可用) 3.當網路穩定時,當前實體新的注冊資訊會被同步到其他節點中 |
Eureka可以很好的應對因為網路故障導致部分節點失去聯系的情況,而不會像zookeeper那樣,是整個注冊服務癱瘓
四、Ribbon客戶端負載均衡
4.1Ribbon是什么?
- Spring Cloud Ribbon是基于Netflix Ribbon實作的一套客戶端負載均衡的工具,
- 簡單的說,Ribbon是Netflix發布的開源專案,主要功能是提供客戶端的軟體負載均衡演算法,將NetFlix的中間層服務連接在一起,Ribbon的客戶端組件提供一系列完整的配置項如:連接超時、重試等等,簡單的說,就是在組態檔中列出LoadBalancer(簡稱LB:負載均衡)后面所有的機器,Ribbon會自動的幫助你基于某種規則(如簡單輪詢,隨機連接等等)去連接這些機器,我們也很容易使用Ribbon實作自定義的負載均衡演算法!
4.2Ribbon能干嘛?
- LB,即負載均衡(Load Balance),在微服務或分布式集群中經常用的一種應用,
- 負載均衡簡單的說就是將用戶的請求平攤的分配到多個服務上,從而達到系統的HA(高可用),·常見的負載均衡軟體有 Nginx,Lvs等等
- dubbo、SpringCloud中均給我們提供了負載均衡,SpringCloud的負載均衡演算法可以自定義·
- 負載均衡簡單分類:
1.集中式LB
即在服務的消費方和提供方之間使用獨立的LB設施,如Nginx,由該設施負責把訪問請求通過某種策略轉發至服務的提供方!
2.行程式LB
將LB邏輯集成到消費方,消費方從服務注冊中心獲知有哪些地址可用,然后自己再從這些地址中選出一個合適的服務器,
Ribbon就屬于行程內LB,它只是一個類別庫,集成于消費方行程,消費方通過它來獲取到服務提供方的地址!
4.3集群的搭建
1.創建多個注冊中心:

2.組態檔系結:
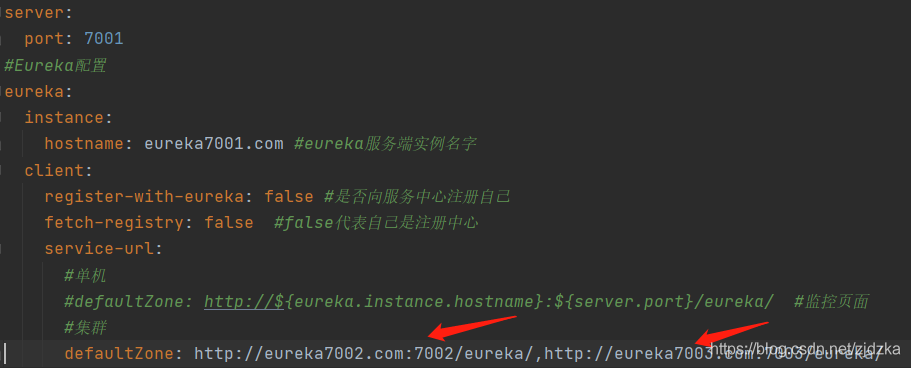
3.啟動集群:
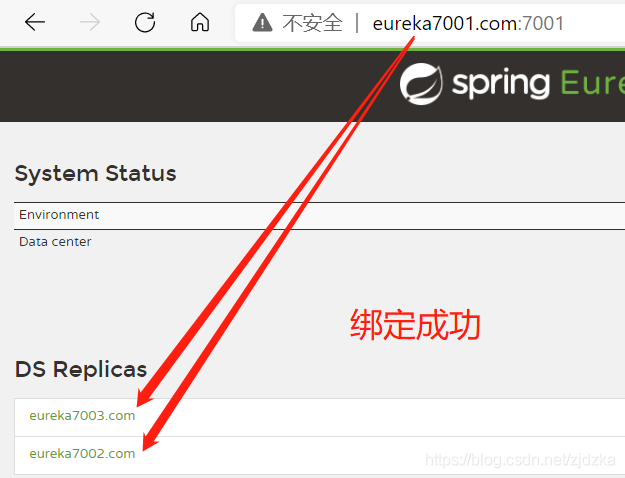
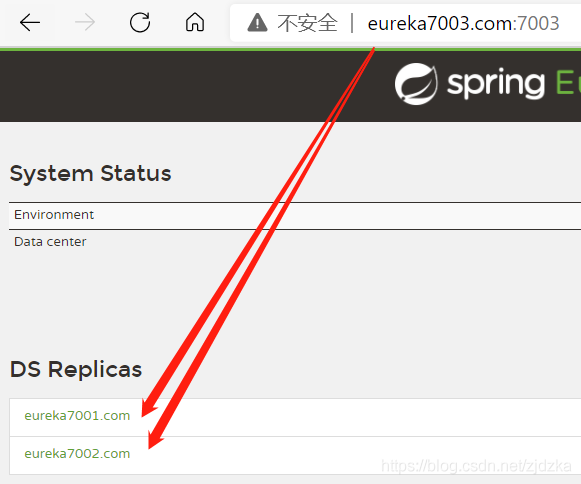
五、Feign負載均衡
5.1簡介
feign是宣告式的web service客戶端,它讓微服務之間的呼叫變得更簡單了,類似controller呼叫service,SprinCloud集成了Ribbon和Eureka,可在使用Feign時提供負載均衡的http客戶端,
只需要創建一個介面,然后添加注解即可!
feign,主要是社區,大家都習慣面向介面編程,這個是很多開發人員的規范,呼叫微服務訪問兩種方法
1.微服務名字【ribbon】
2.介面和注解【feign】
5.2feign能干嘛?
- Feign旨在使撰寫Java Http客戶端變得更容易
- 前面在使用Ribbon + RestTemplate時,利用RestTemplate對Http請求的封裝處理,形成了一套模板化的呼叫方法,但是在實際開發中,由于對服務依賴的呼叫可能不止一處,往往一個介面會被多處呼叫,所以通常都會針對每個微服務自行封裝一些客戶端類來包裝這些依賴服務的呼叫,所以,Feign在此基礎上做了進一步封裝,由他 來幫助我們定義和實作依賴服務介面的定義,在Feign的實作下,我們只需要創建一個介面并使用注解的方式來配置它(類似于以前Dao介面上標注Mapper注解,現在是一個微服務介面上面標注一個Feign注解即可,完成對服務提供方的介面系結,簡化了使用Spring Cloud Ribbon時,自動封裝服務呼叫客戶端的開發量
5.3對比之前的客戶端
之前的客戶端controller:
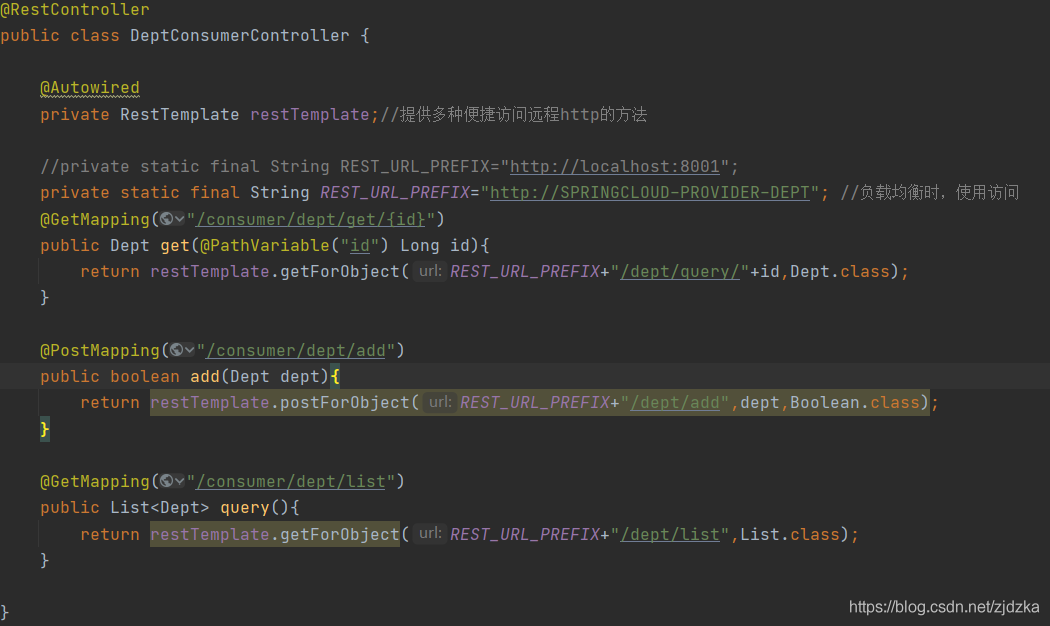
feign的controller:
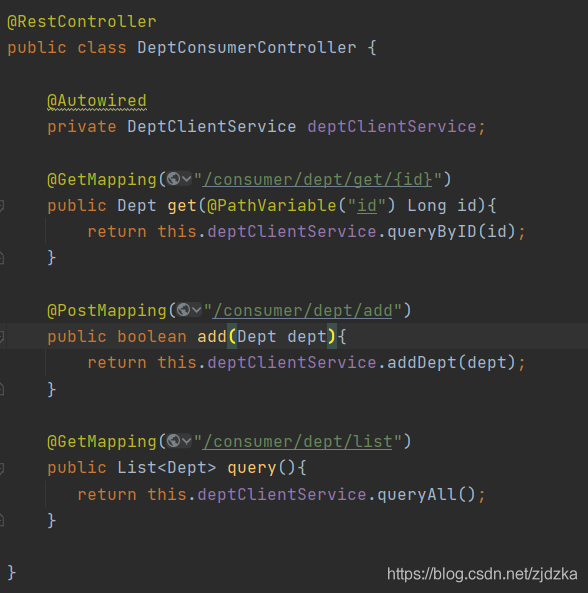
啟動類:
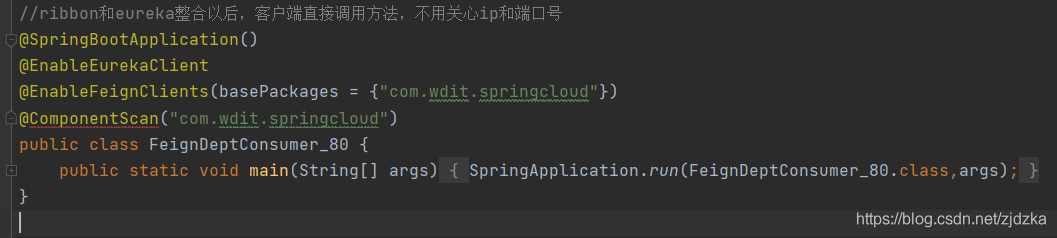
六、服務熔斷Hystrix
6.1什么是Hystrix?
Hystrix是一個用于處理分布式系統的延遲和容錯的開源庫,在分布式系統里,許多依賴不可避免的會呼叫失敗,比如超時,例外等,Hystrix能夠保證在一個依賴出問題的情況下,不會導致整體服務失敗,避免級聯故障,以提高分布式系統的彈性,
“斷路器”本身是一種開關裝置,當某個服務單元發生故障之后,通過斷路器的故障監控(類似熔斷保險絲),向呼叫方回傳一個服務預期的,可處理的備選回應(FallBack),而不是長時間的等待或者拋出呼叫方法無法處理的例外,這樣就可以保證了服務呼叫方的執行緒不會被長時間,不必要的占用,從而避免了故障在分布式系統中的蔓延,乃至雪崩
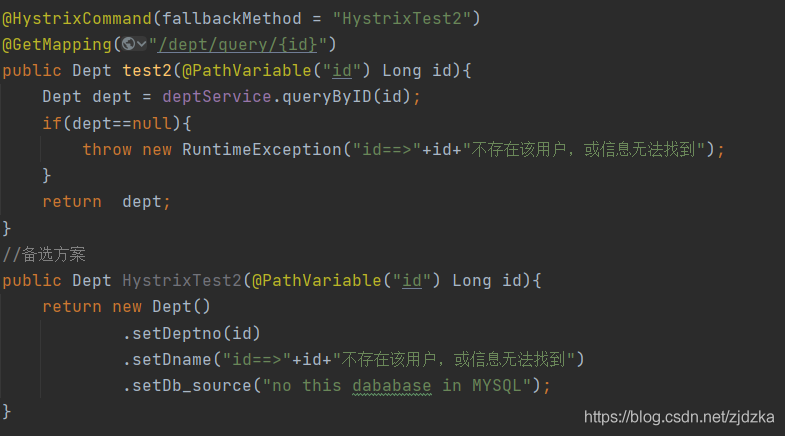
6.2服務熔斷
說簡單了就是:提供給客戶端一個備選方案,如果用戶在查詢時,出現了例外,不會讓用戶向之前一樣一直等待回應,而是跳轉備選方案,提示用戶
例如:
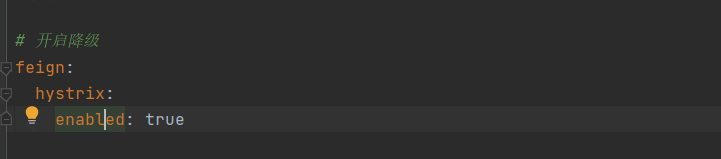
6.3服務降級
客戶端的備選方案:降級處理,只需要在組態檔中添加即可
七、路由網關Zuul
7.1概述
Zuul包含了對請求的路由和過濾兩個最主要的功能:
其中路由功能負責將外部請求轉發到具體的微服務實體上,是實作外部訪問統一入口的基礎,而過濾器功能則負責對請求的處理程序進行干預,是實作請求校驗,服務聚合等功能的基礎,Zuul和Eureka進行整合,將Zuul自身注冊為Eureka服務治理下的應用,同時從Eureka中獲得其他微服務的訊息,也即以后的訪問微服務都是通過Zuul跳轉后獲得,
注意:Zuul服務最侄訓是會注冊進Eureka
提供:代理+路由+過濾三大功能!
7.2組態檔
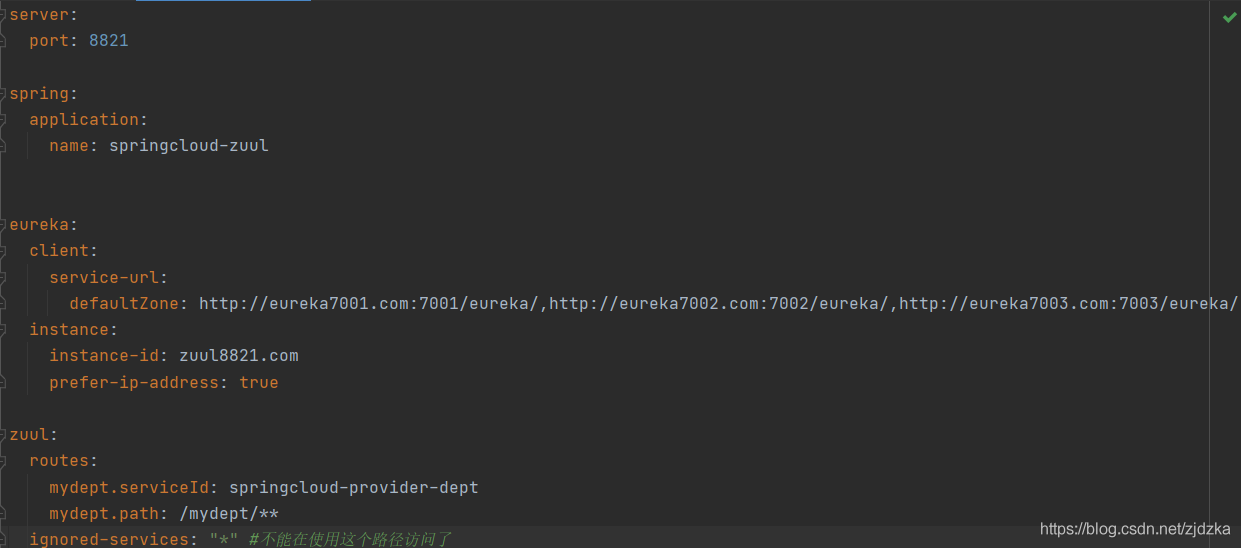
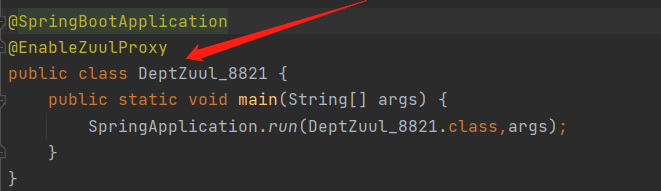
7.3啟動類
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/261001.html
標籤:其他