B-樹
B-樹的意義
B-樹是一種平衡的多路查找樹,它在檔案系統中很有用,常用作檔案的索引,用于提高在磁盤中的查找效率,
B-樹的性質
一棵M階的B樹T,滿足以下條件:
(1)每個節點至多擁有M棵子樹
(2)若根節點不是葉子節點,則根節點至少擁有2棵子樹
(3)除根節點外,其余每個分支節點至少擁有ceil(M/2)棵子樹{這也說明除根節點外的分支節點至少擁有ceil(M/2)-1個關鍵字}
(4)有k棵子樹的節點,則存在k-1個關鍵字
(5)所有葉子節點都在同一層,并且不帶資訊
常將M設定為一個偶數
B-樹的資料結構
typedef struct _btree_node
{
int *key;
btree_node **children;//子樹
int num;//關鍵字數目
int leaf;//是否為葉子節點
} btree_node;
typedef struct _btree
{
btree_node *root;
int t;//M階b樹,M = 2t,即最多只有M棵子樹
//+這樣可以保證M為偶數,M-1為奇數
} btree;
B-樹原子操作
B-樹有兩個非常重要的原子操作:分裂與合并
記住兩個關鍵的原子操作(這是從king老師那里學到的)就像記住九九乘法表一樣
(1)分裂
節點子樹數目到達M,可以分裂;中間的關鍵字上浮1,左右側的關鍵字成為該關鍵字左右子樹,
分裂分為兩種情況:
情況1:該節點為根節點
情況2:該節點非根節點
兩者區別在于根節點中間關鍵字上浮后會成為新的節點;而非根節點的中間關鍵字直接插入父節點即可
分裂如圖所示:


(2)合并
關鍵字和其左右子樹進行合并到其左子樹,對于關鍵字e來說,這是一個下沉2的操作,

B-樹的關鍵字插入
首先,需要記住的是:
同二叉搜索樹相同,B-樹關鍵字的插入一定會插入葉子節點
其次,插入關鍵字需要用到前面提到的原子操作——分裂,
這是因為,在插入關鍵字時,若關鍵字插入一個已經存在M棵子樹的節點,就會導致,該節點不滿足性質(3),因此,每次在當前節點查找之前,如果當前節點已經存在M-1個關鍵字,則需要進行分裂,此外也可以防止該節點的子樹分裂后,關鍵字上浮導致該節點不滿足性質(3).
最后,插入關鍵字的流程:
分為兩步:
step1:處理根節點(btree_insert)
step2:處理非根節點(btree_insert_nonfull)
btree_insert流程圖
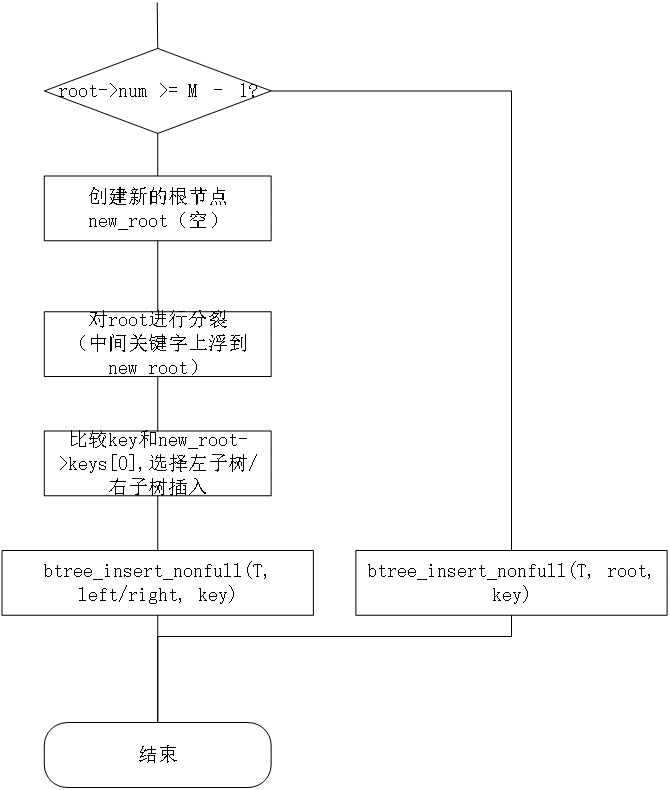
btree_insert_nonfull思路
這是一個遞回函式,函式的遞回結束條件是——到達葉子節點:找到對應的位置插入即可,
函式思路
當遇到葉子節點:直接找到位置插入,函式回傳
而當遇到非葉子節點時:
(1)查找到需要插入的子樹
(2)檢查需要插入的子樹的關鍵字數目,若已滿,則進行分裂
注意:正是由于這一步檢查,才保證了在葉子節點時,可以放心地插入,而不必擔心葉子節點數量已滿,也可以保證在分裂時,上浮的節點不會導致該節點關鍵字超出限制
代碼如下:
void btree_insert_nonfull(btree *T, btree_node *x, KEY_VALUE k)
{
int i = x->num - 1;
//two conditions:
//condition 1: 如果是葉子節點,直接插入即可
//condition 2: 如果不是葉子節點
//(1)檢查節點是否已滿,若已滿則需要分裂
//(2)查找插入的子樹
if (x->leaf == 1)
{
while (i >= 0 && x->key[i] > k)
{
x->keys[i + 1] = x->keys[i];
i --;
}
x->keys[i + 1] = k;
}
else
{
//首先,找到要插入的子樹
while (i >= 0 && x->keys[i] > k)
{
i--;
}
//其次,查看該子樹是否已滿節點,因為,該子樹可能就是葉子節點
if (x->children[i + 1]->num == (2 * (T->t) - 1))
{
btree_split_child(T, x, i + 1);
if (k > x->keys[i + 1])
{
i++;
}
}
//最后,繼續插入關鍵值
btree_insert_nonfull(T, x->children[i+1], k);
}
}
B-樹的關鍵字洗掉
注意:當M為偶數時,ceil(M/2) = M/2,下文不作區分
btree_delete_key是一個遞回函式:
遞回j結束條件——當該關鍵字存在于葉子節點
1. 思路
當關鍵字存在于該節點:進行洗掉操作
(1)若為葉子節點:直接洗掉即可,若洗掉后,葉子節點為空,則需要釋放記憶體(這是什么情況呢?當M為2時)
(2)若為非葉子節點:則需要進行填補,
首先洗掉當前關鍵字
a)若左孩子節點的關鍵字數量 >= M, 則從左孩子子樹最大關鍵字填補,并從左子樹中洗掉該關鍵字,直接回傳
b)若右孩子節點的關鍵字數量 >= M, 則從右孩子子樹最小關鍵字填補,并從左子樹中洗掉該關鍵字,直接回傳
c)若兩側均不可填補上來,則進行合并left + key + right -> left,再從left中洗掉關鍵字key
當關鍵字不存在于該節點:繼續查找關鍵字所在的樹child,并檢查該樹的根節點是否滿足數量 >= M/2
(1)若子樹child為空,則說明B樹不存在該關鍵字,直接回傳
(2)若子樹child不為空,則說明關鍵字若存在,只可能存在于該子樹,檢查子樹數量是否 >= M/2
a)若關鍵字數量 >= M/2 – 1, 則直接btree_delete_key(T,child, key)
b)若關鍵字數量 < M/2 – 1,需要進行借位,并從借位的子樹洗掉該關鍵字
(則若關鍵字在該節點,則洗掉可能導致不滿足性質——除了根節點外的節點,至少擁有 ceil(M/2) 棵子樹)
左兄弟樹:left = node->child[idx - 1]
右兄弟樹:right = node->child[idx + 1]
兩者至少存在一個
i)從關鍵字較多且關鍵字數量 >= M/2 的子樹借位
ii)若不可借位,則進行合并
2.代碼
//B樹的key洗掉
/* @node : 從node節點開始找,
* 若node節點為葉子節點,則直接洗掉該關鍵值即可;
* 若node節點非葉子節點,則需要
*/
void btree_delete_key(btree *T, btree_node *node, KEY_VALUE k)
{
if (node == NULL)
{
return;
}
int idx = 0;
int i = 0;
int prev = 0;
int nxt = 0;
//找到第一個大于等于key的關鍵字
while (idx < node->num && key > node->keys[idx])
{
idx++;
}
//若該關鍵字等于key,key位于該節點
if (idx < node->num && key == node->keys[idx])
{
//若該節點為葉子節點,則直接洗掉該關鍵字
if (node->leaf)
{
...
return;
}
/*若該節點非葉子節點,則進行填補式洗掉
*(1)先試從左側的子樹填補
*(2)若左側子樹無法填補,則試從右側子樹填補
*(3)若兩側均無法填補,則進行合并后再洗掉
*/
//若該節點非葉子節點,
//+且該節點 的 左側的子樹的關鍵字數量大于 t - 1(洗掉一個關鍵字仍滿足性質)
else if (node->children[idx]->num >= T->t)
{
//直接將 前序關鍵字填補上來,然后從左子樹中洗掉該關鍵字
//為什么要求left節點的關鍵字數目要 >= t 呢,因為可能該關鍵字就在這個節點中
btree_node *left = node->children[idx];
prev = get_max_key(left);
node->keys[idx] = prev;
btree_delete_key(T, left, prev);
}
//若該節點非葉子節點
//+且該節點 的 右側的子樹的關鍵字數量大于 t - 1
else if (node->children[idx + 1]->num >= T->t)
{
//直接將 后續 關鍵字填補上來,然后將其從右側子樹中洗掉
btree_node *right = node->children[idx + 1];
nxt = get_min_key(right);
node->keys[idx] = nxt;
btree_node_key(T, right, nxt);
}
//若該節點葉子節點
//+ 且兩側的子樹均無法填補上來(即兩側子樹的關鍵字數量均為t-1),則直接進行合并
//+ 合并是指,將left, node[idx], right 進行合并
//合并后,從left中洗掉關鍵字key
else
{
//合并
btree_merge(T, node, idx);
//從left中洗掉關鍵字key
btree_delete_key(T, node->children[idx], key);
}
}
else
//key大于該節點上所有關鍵字(此時idx == node->num)
//+ 這說明該關鍵字應位于子樹children[idx + 1],需要繼續進行查找
{
//若該子樹為空,說明本節點已經是葉子節點了且該關鍵字并不存在,說明子樹可以為空啊
//因為只有葉子節點,
btree_node *child = node->children[idx];
if (child == NULL)
{
printf("Cannot del key = %d\n", key);
return;
}
//若該子樹不為空,繼續尋找關鍵字,此處就解決上面的,洗掉節點后,可能導致節點
//+不滿足性質6)關鍵字的數目 >= t-1(孩子數目num >= t - 1)
//(1)若該子樹不為空,且其關鍵字的數量為 t - 1,說明再洗掉一個關鍵字,就不符合性質6)了
//+ 因此,需要進行借位,以防止key存在于該節點的情況
//+ 先 從左邊借位(需要左邊的子樹節點的num >= t)
//+ 然后 從右邊借位(需要右邊的子樹節點的num >= t)
//+ 如果,兩邊均不可借位,則進行合并
if (child->num == T->t - 1)
{
btree_node *left = NULL;
btree_node *right = NULL;
if (idx - 1 >= 0)
{
left = node->children[idx - 1];
}
if (idx + 1 <= node->num)
{
right = node->children[idx + 1];
}
//若兄弟樹存在且可以借位
//疑問:left可能為空嗎?
if ((left && left->num >= T->t) || (right && right->num >= T->t)
{
int richR = 0;
//確定關鍵字較多的兄弟樹
if (right) richR = 1;
if (left && right) richR = (right->num > left->num) ? 1 : 0;
//borrow from next
if (right && right->num >= T->t && richR)
{
//該子樹添加關鍵字和子樹
child->keys[child->num] = node->keys[idx];
child->children[child->num + 1] = right->children[0];
child->num++;
//右兄弟子樹洗掉關鍵字和子樹
node->keys[idx] = right->keys[0];
for (i = 0; i < right->num - 1; i++)
{
right->keys[i] = right->keys[i + 1];
right->children[i] = right->children[i + 1];
}
right->children[i] = right->children[i + 1];
right->keys[right->num - 1] = 0;
right->children[right->];
right->num--;
}
else
//borrow from prev
{
for (i = child->num; i > 0; i--)
{
child->keys[i] = child->keys[i - 1];
child->children[i + 1] = child->children[i];
}
child->children[1] = child->children[0];
child->children[0] = left->children[left->num];
child->keys[0] = node->keys[idx - 1];
child->num++;
node->keys[idx - 1] = left->keys[left->num - 1];
//left tree
left->children[left->num] = NULL;
left->num--;
}
}
//若查找洗掉節點的關鍵字數目 == t - 1,且左右兄弟子樹均不可借位
//+ 則進行merge
else if ((!left || (left->num == T->t - 1)) && (!right || (right->num == T->t - 1)))
{
//左兄弟樹 node->keys[idx - 1],和child進行合并
if (left && left->num == T->t - 1)
{
btree_merge(T, node, idx - 1);
child = left;
}
//右兄弟樹,node->keys[idx],和child進行合并
else if (right && right->num == T->t - 1)
{
btree_merge(T, node, idx);
}
}
}
//好了,現在即使,這個key位于該節點,也可以放心地洗掉了
btree_delete_key(T, child, key);
}
}
//需要合并,說明 其左右子樹的關鍵字數量均小于 t - 1 (則合并后,最大關鍵字數量為 2t)
void btree_merge(btree* T, btree_node *node, int idx)
{
//難道 非葉子節點,其關鍵字的左右子樹就一定存在?
//是的!性質3)除根節點外,其余每個節點至少擁有M/2棵子樹
btree_node *left = node->children[idx];
btree_node *right = node->children[idx+1];
int i = 0;
//data merge
left->keys[T->t - 1] = node->keys[idx];
for (i = 0; i < T->t - 1; i++)
{
left->keys[T->t + i] = right->keys[i];
}
//children merge
if (!left->leaf)
{
for (i = 0; i < t; i++)
{
left->children[T->t + 1 + i] = right->children[i];
}
}
left->num += T->t;
//destroy right
btree_destroy_node(right);
//node
for (i = idx + 1; i < node->num; i++)
{
node->keys[i - 1] = node->keys[i];
node->children[i] = node->children->[i+1]
}
node->children[node->num - 1] = NULL;
node->num -= 1;
//若node的數目為1,則說明該節點為根節點,直接洗掉,并將left作為根節點
if (node->num == 0)
{
T->root = left;
btree_destroy_node(node);
}
}
B-樹的其它操作
相比較于插入和洗掉較為簡單,不在此贅述
(1)搜索關鍵字
(2)遍歷B-樹
(3)列印二叉樹
疑惑與解答
1.插入時,到達葉子節點一定可以插入嗎,會不會出現葉子節點為空的情況?
一定可以插入,
不會出現葉子節點為空,因為根據b樹性質:每個節點的關至少有ceil(M/2)棵子樹,也即至少擁有ceil(M/2) – 1個關鍵字,
2.每個節點至少有ceil(M/2)棵子樹是如何保證的?
在插入和洗掉關鍵字才會改變B樹的結構,因此提問等價于在插入/洗掉關鍵字時,如何保證B樹的性質,
(1)插入:只有當子樹數量到達M時,才會進行分裂
若M為偶數:此時左右的子樹數量均為ceil(M/2),可以保證至少有ceil(M/2)棵子樹,
若M為奇數:此時一棵子樹數量為(M/2)+1,另一棵為(M/2)-1,只要將新插入的節點放入子樹數量較少的一棵即可
(2)洗掉:在洗掉關鍵字時,需要提前檢查子樹節點的數量是否已經等于ciel(M/2),若等于,則需要進行借位,保證即使洗掉關鍵字,也可以滿足該性質
3.B-樹高度是什么時候減少的?
可能大家會疑惑,從來沒有更改過一個節點的是否為葉子的屬性,為什么B-樹的高度就開始減少了…這是因為B-樹高度的減少并不是從底部洗掉節點的,每次洗掉的節點都是根節點!是的,當發生合并時,你會發現,節點的關鍵字數目開始減少,而非根節點的關鍵字數目被限制在ceil(M/2)-1及以上,只有根節點的關鍵字數目可以為1,當在合并程序中,根節點的最后一個關鍵字下沉,于是根節點被洗掉,新的根節點"上位",此時B-樹的高度減1.
總結
本文首先介紹了B-樹的意義和性質,其次給出B-樹的資料結構,然后介紹了原子操作分裂和合并,重點介紹了B樹的關鍵字插入和洗掉,最后歸納了一些疑問點,歡迎大家批評與指正,
上浮:指節點C的關鍵字key成為父節點的關鍵字 ??
下沉:指節點P的關鍵字key成為其子節點的關鍵字 ??
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/262083.html
標籤:其他