Hystrix解決的問題
在復雜的分布式系統中,存在多個服務相互依賴的情況,如果某個服務因為某些原因不可用,例如機房的不可靠性、網路服務商的不可靠性等,系統對外界提供的整個功能都將不可用,
在高并發的情況下,單個服務的延遲會導致整個請求都處于延遲狀態,可能在幾秒內就使得整個服務處于執行緒負載飽和的狀態;
雪崩效應:某個服務的單點故障,導致用戶的請求處于阻塞狀態,最終結果是整個服務的執行緒資源消耗殆盡,由于服務的依賴性,會導致依賴于該故障服務的其他服務也處于執行緒阻塞狀態,最終導致這些服務的執行緒資源消耗,服務不可用,從而導致整個微服務系統都不可用,
Hystrix的設計原則
- 防止單個服務的故障耗盡整個服務的Servlet容器的執行緒資源;
- 快速失敗機制;
- 提供回退方案;
- 使用熔斷機制,防止故障擴散到其他服務;
- 提供熔斷器的監控組件HyStrix Dashboard,實時監控熔斷器的狀態
服務集成hystrix
添加jar包依賴
| <dependency> |
啟動類添加注解@EnableHystrix 開啟熔斷器功能
如果已經集成feign的話,只需要配置介面實作類和系結fallback操作


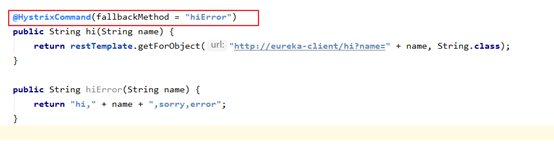
如果集成的是ribbon,則需要在方法上注解@HystrixCommand并指定fallback方法
集成hystrix dashboard
熔斷器監控使用hystrix dashboar監控
添加jar包依賴
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-hystrix-dashboard</artifactId> </dependency> |
啟動類添加注解@EnableHystrixDashboard
通過http://localhost:8764/hystrix進行訪問
集成turbine
每個服務都集成Hystrix DashBoard不利于統一管理,使用turbine收集資訊能夠更好的管理服務的熔斷器
引入jar包依賴
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-turbine</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-hystrix</artifactId> </dependency>
|
啟動類添加注解@EnableTurbine
配置監控內容
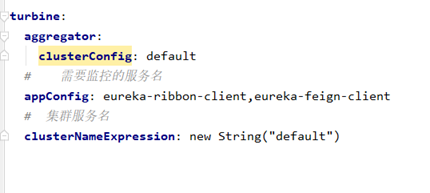
啟動服務后訪問任意服務的hystrix dashboard 監控turbine.stream流

《深入理解ng cloud與微服務構建》
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/262174.html
標籤:其他
上一篇:Android 12 預覽版發布,64g 手機用戶哭了
下一篇:專案架構設計參考資料