本文借鑒了@平胸小仙女的知憾訓復 https://www.zhihu.com/question/36081767
寫在前面:
文章有點長,操作有點復雜,需要代碼的直接去文末即可,想要學習的需要有點耐心,當我理清所有邏輯后,我抑郁的(震驚的)發現,只需要改下歌曲ID就可以爬取其他任意歌曲的評論了!生成的TXT檔案在程式同一目錄,
有基礎的可能覺得我比較啰嗦,因為我寫博客一是為了記錄下知識點,在遺忘的時候可以查看回顧下,二是因為我學編程的時候,搜到的很多帖子都是半殘的,有些人是為了引流到自己的公眾號,有些人干脆是騙流量,有的帖子質量很好,但是對小白不太友好,沒有相關基礎很難復現,這樣就在搜索上浪費了很多時間,我寫博客盡量把每一步操作都記錄下來,這樣別人能復現我的成果,對著一個可以運行的程式,才會有學習的欲望,先學會操作,再去弄懂原理,然后就可以寫出自己的程式了!至于技術原理,網上的大牛太多了,想學的話很容易學到,我希望看到我的博客的小白,不至于在操作上浪費太多時間,能有時間用到學習技術原理上,
當然也有一部分是獵奇的,希望直接復制就能運行,這樣的呢,給我點個贊就行啦!畢竟誰不是從白嫖怪一步一步成長起來的呢,好奇心是最好的老師,
可能遇到的麻煩:
ModuleNotFoundError: No module named ‘Crypto‘ 踩坑
用到的工具:
手把手教你下載安裝配置Fiddler 和 Fiddler Everywhere
PyCharm中文指南2.0
詞云清洗用到的stopwords.txt:
Python文本分析之常用最全停用詞表(stopwords)
詞云清洗的分析參見:
Python爬取你好李煥英豆瓣短評并利用stylecloud制作更酷炫的詞云圖
F12大法開啟:
打開網易云網頁版,找到一首喜愛的音樂,我選擇的是柏松的《世間美好與你環環相扣》,然后開啟F12大法!
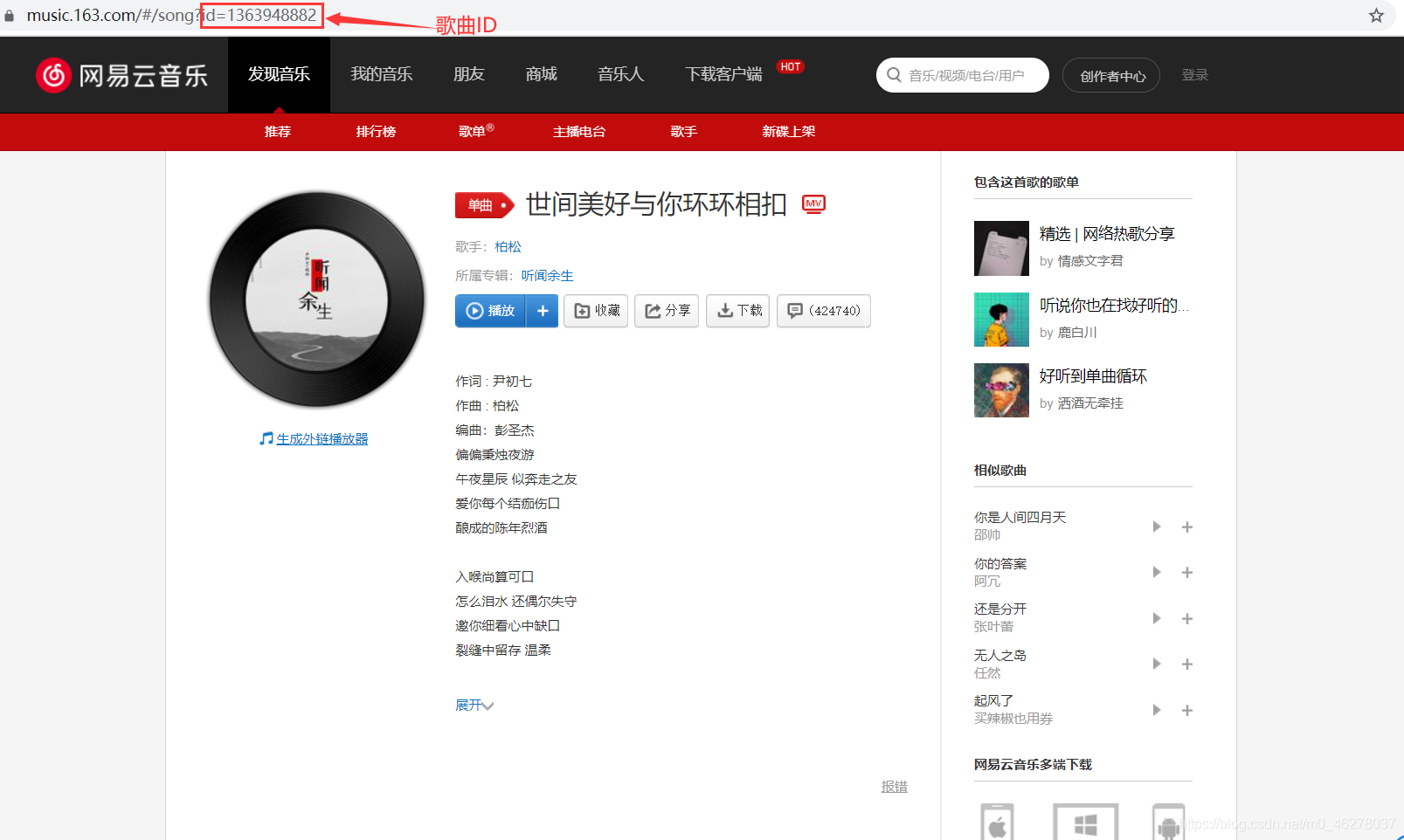
現在開始作法:按F12,選中network(也可以右鍵–>檢查–>network),然后F5重繪頁面,就可以看到network的活動:
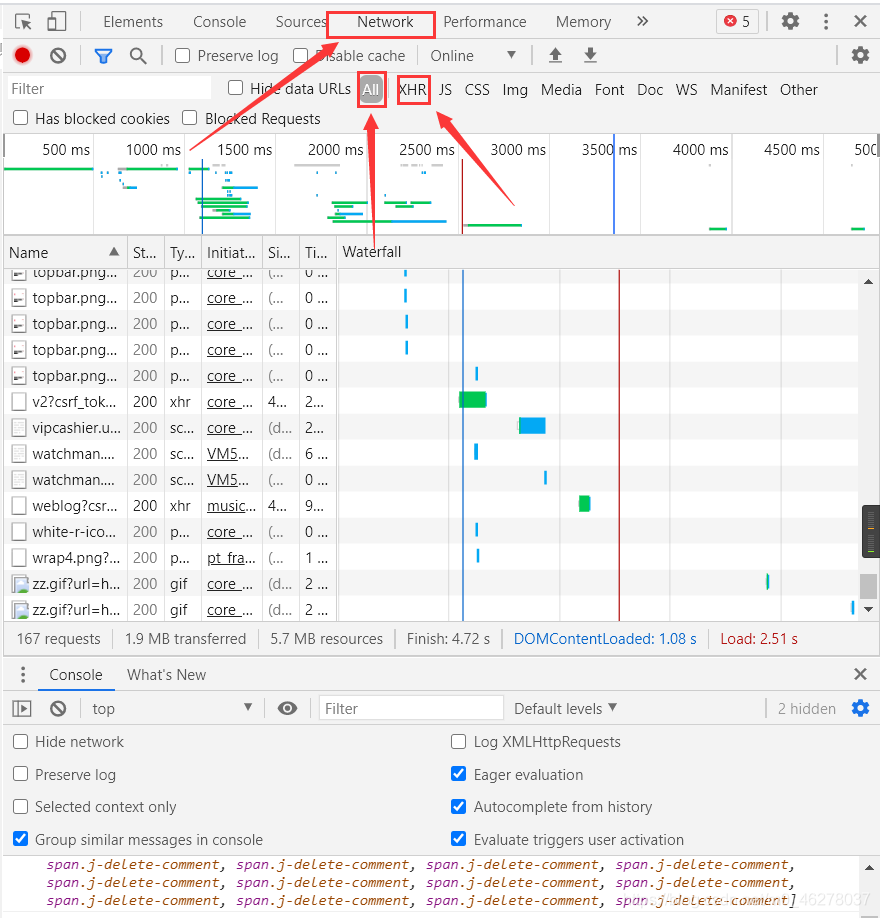
點擊評論的下一頁,發現只有評論會重繪成下一頁的評論,網頁的URL沒有變,說明向服務器發送的請求是XHR(XMLHttpRequest)物件,所有現代瀏覽器均支持 XMLHttpRequest 物件(IE5 和 IE6 使用 ActiveXObject),XMLHttpRequest 用于在后臺與服務器交換資料,這意味著可以在不重新加載整個網頁的情況下,對網頁的某部分進行更新,
完全不懂的小白可以學這個入下門:
https://www.w3cschool.cn/ajax/ajax-xmlhttprequest-create.html
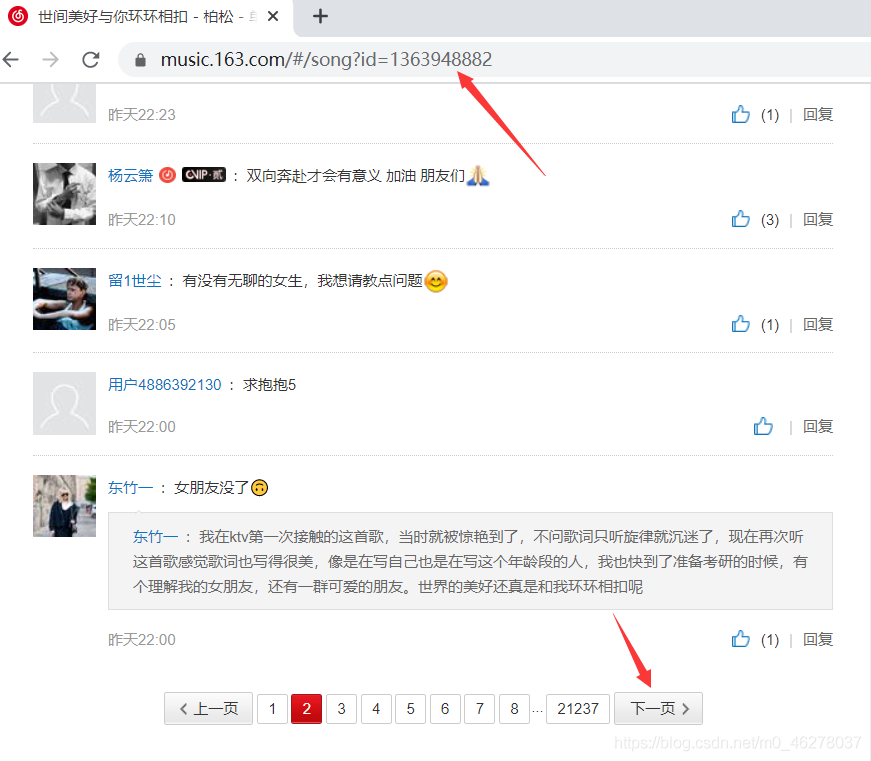
這樣就縮小了排查范圍,選中XHR,會發現少了很多,但是還有十多條,這就沒辦法了,可以自己瞎猜,我是一個一個點進去,然后選中Response,這樣一個個的找到包含評論的資料包的,當然你操作的時候頁面跟我的不太一樣,因為這些框框都是可以拖動的,需要看哪一部分的時候可以拖動使得需要的部分變大,突出的顯示出來,
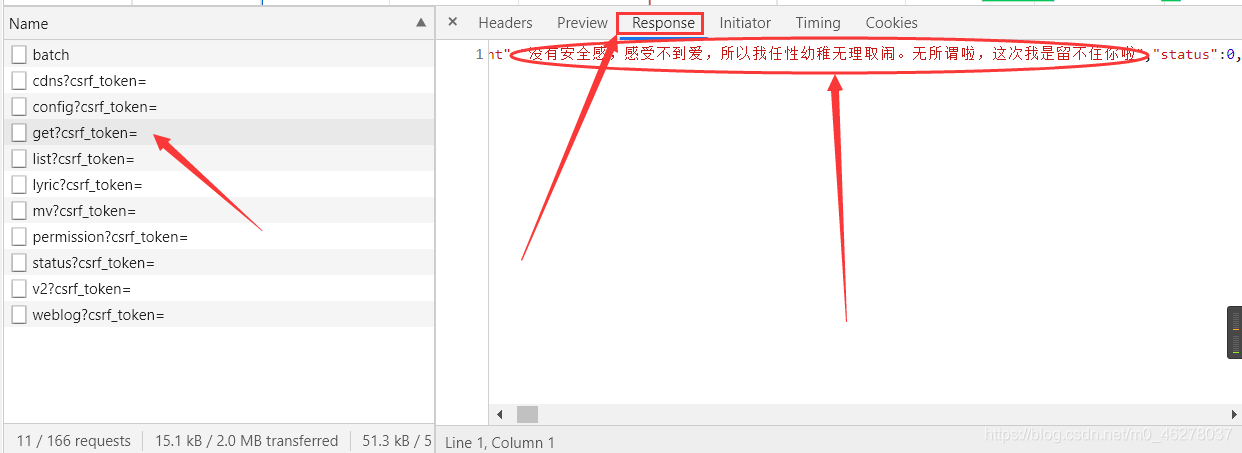
對比上圖,就是這個了:
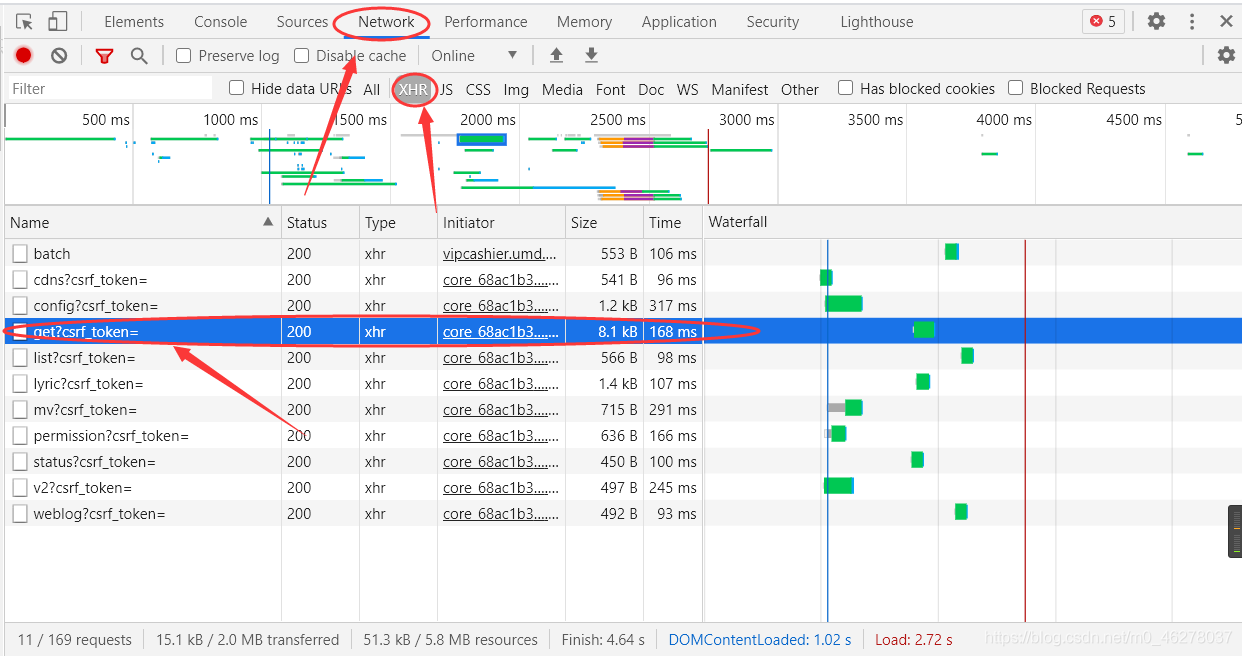
點進去,選中Headers,就可以看到Request Headers
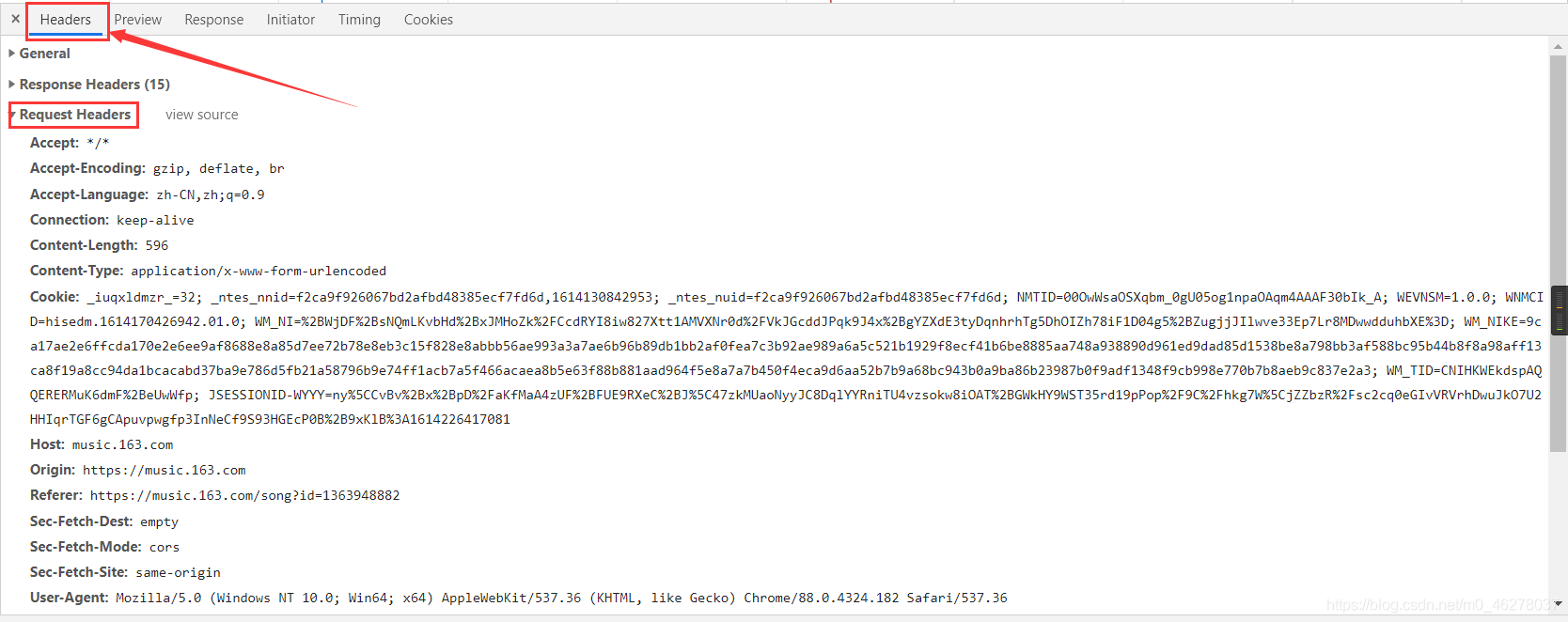
以及兩個引數params和encSecKey

在Response里可以看到當前頁的所有評論,但也只是當前頁的,其他頁的評論如何獲取呢?
點擊下一頁的時候只重繪評論,而不會重新加載頁面,那么既然這個行程是向服務器發起獲取評論的請求,我們點擊下一頁看看這個行程會有什么變化,
第一頁:
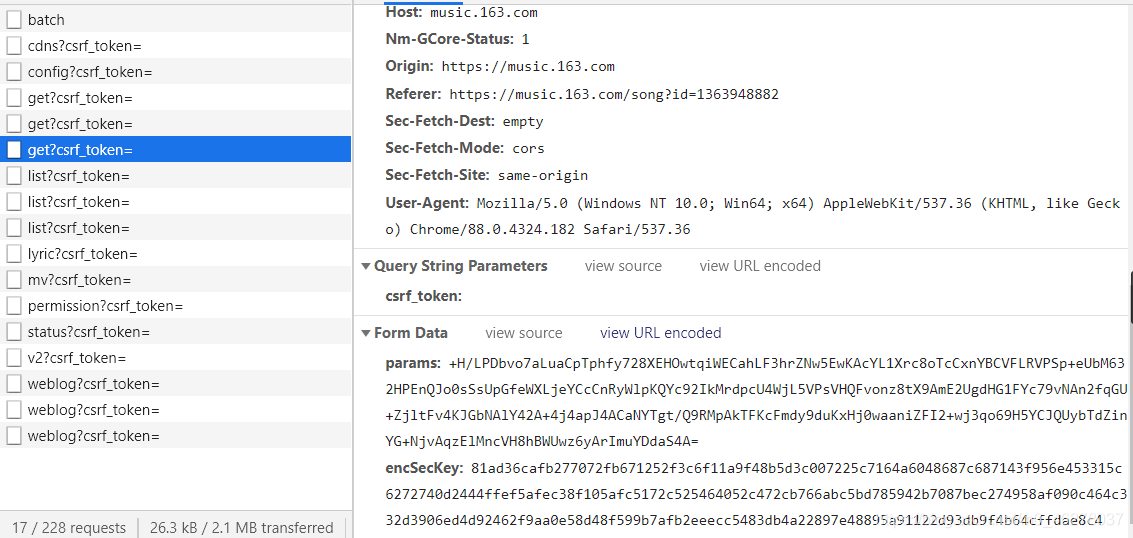
第二頁:
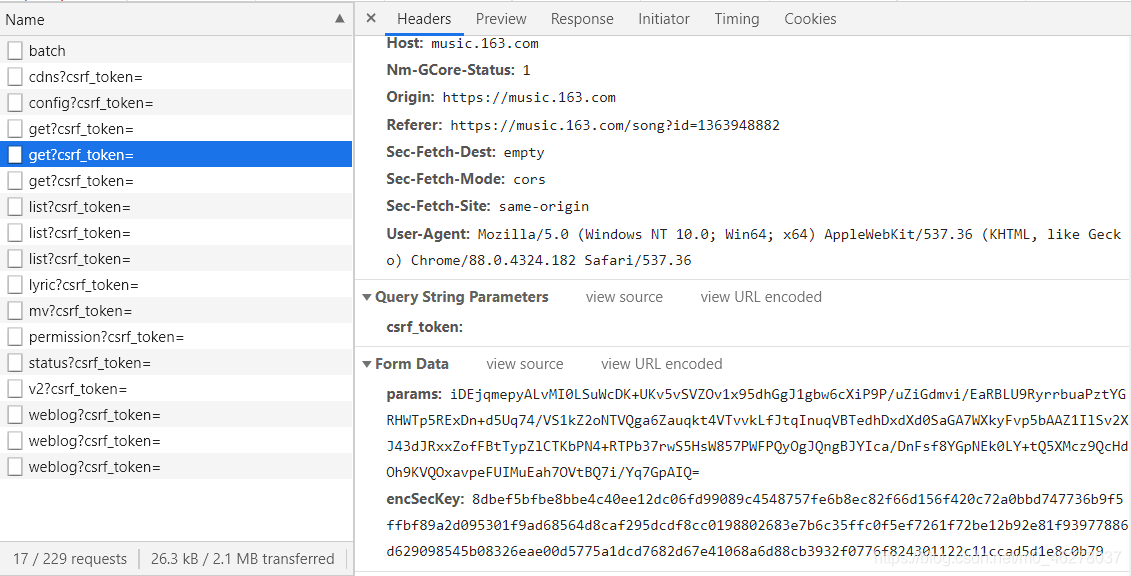
第三頁:
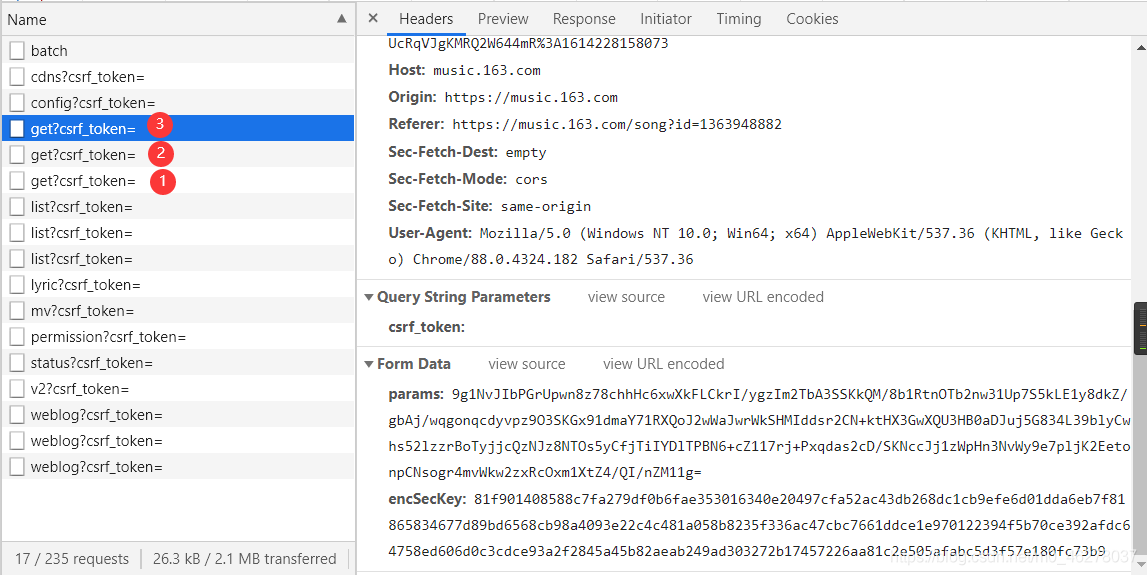
可以發現只有這兩個引數 params和encSecKey會隨之改變,進而Response也重繪成了下一頁的評論,由此得出結論:這是通過不同頁面的params以及encSecKey引數的不同來向服務器發起獲取相應評論的請求,
js線上除錯:
因此,下一步就是弄清楚不同頁面的params以及encSecKey引數是如何改變的,這樣我們就能在爬蟲程式中通過生成隨頁面變化的這兩個引數,發送至服務器獲取相應的Response,
這兩個引數一看就是js加密的,而這個行程的initiator是core_68ac1b3aadf40a20caba599a0ab2365d.js
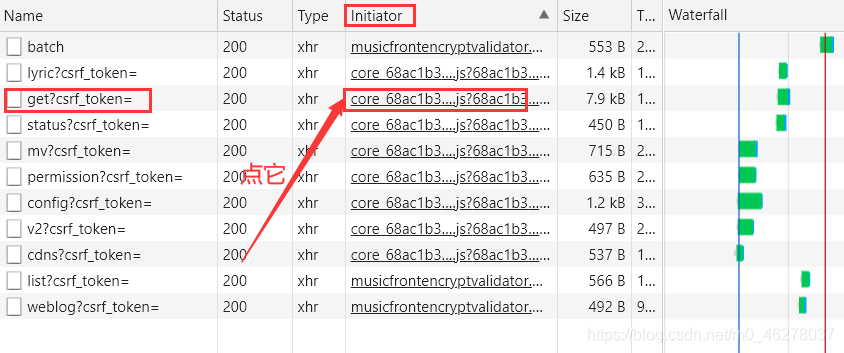
一般這樣的js都是沒法看的,因此就點進去并save as將core_68ac1b3aadf40a20caba599a0ab2365d.js下載到本地查看,以下簡稱core.js,
切記切記!!!一定要先點這個美化按鈕!!!然后再保存!!!沒有一個教程帖子告訴我這點,然后我就傻不拉嘰的直接保存了!!!!當然你也可以不點不美化,畢竟我第一次沒有美化也做出來了,
右鍵,Save as 就可以保存了,選個自己知道的路徑,等下有用!
打開core.js,我用的是Sublime Text,
這就是你不點美化的后果!!!找不同吧!!!
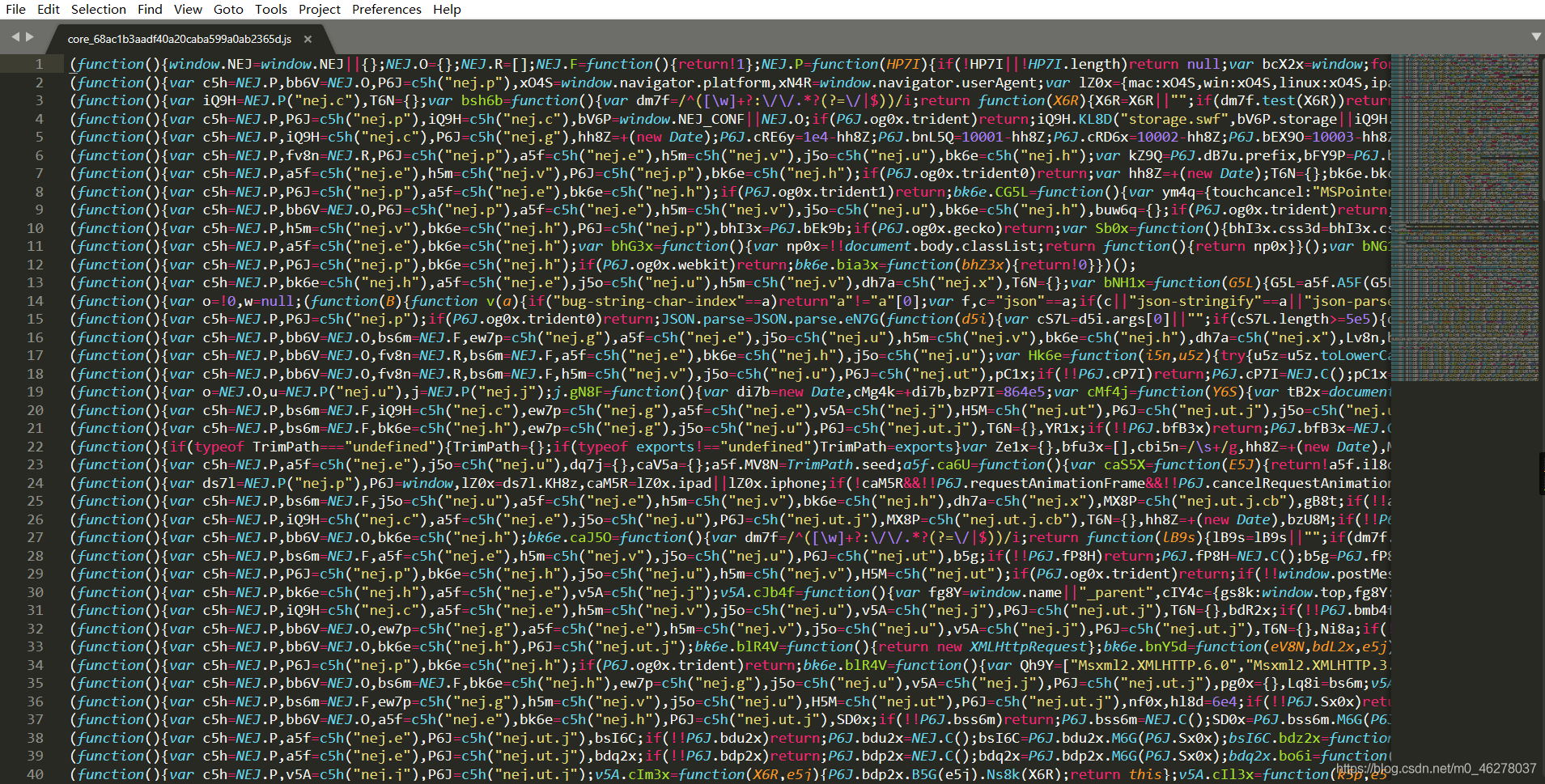
這是美化后的:
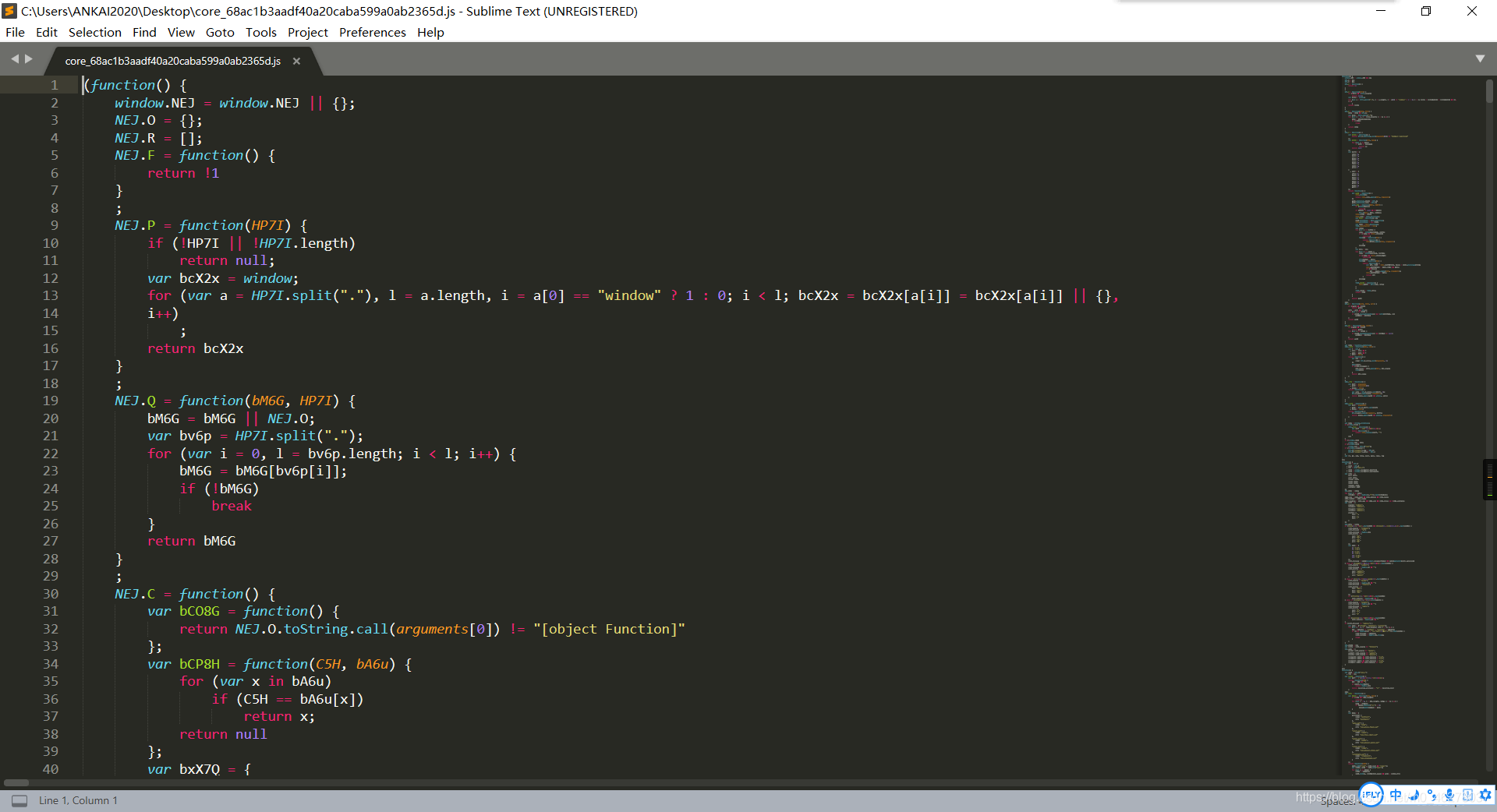
搜索params和encSecKey,查找這兩個引數:

可以看到這兩個引數都是bWv4z函式中的變數,(PS:細心的讀者會注意到后面的截圖不再是bWv4z,其他引數也有微小變化,是因為我出去吃了個飯,回來后core.js已經失效,網易云更新了這個,所以我重新下載編輯了,不影響學習,)而這個函式也就是window.asrea這個函式,暫且不管window.asrea這個函式是如何實作的,可以看到它有四個引數,先不管這四個引數是哪來的,可以先把它們輸出到console看一下,這時候就需要線上除錯js,首先將本地的core.js檔案添加幾行代碼,以便使這四個引數顯示出來:

把第2、3、4個引數先注釋掉,因為要一個一個的獲取,
接著要用到Fiddle Everywhere了,下載安置配置見本文開頭鏈接,
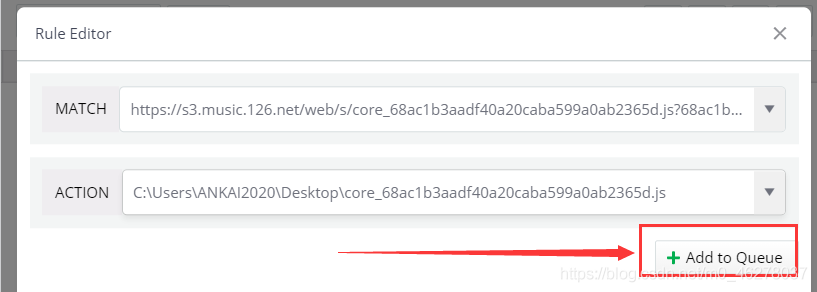
點擊打開AutoResponder,然后點Add New Rule
彈出
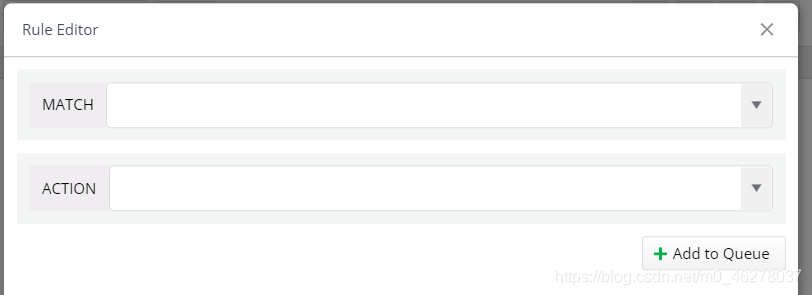
先看MATCH:
回到這里,這次點Open in new tab
在彈出的頁面復制URL,注意不是美化后的,是美化前的,可以點叉把美化后的關了,再右鍵Open in new tab
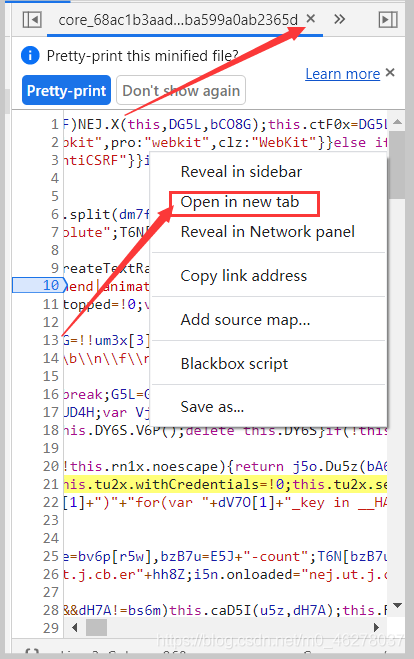
復制URL

注意不是這個:

把復制的URL粘貼到MATCH
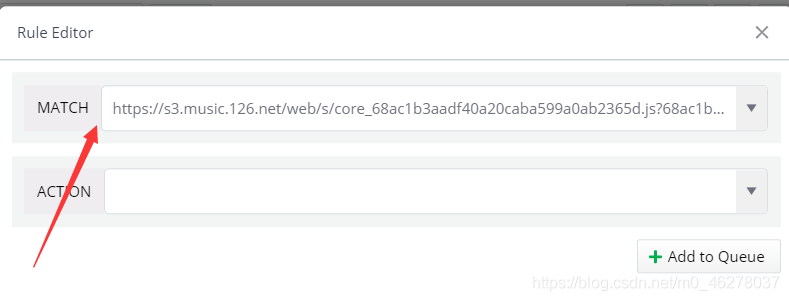
然后看ACTION
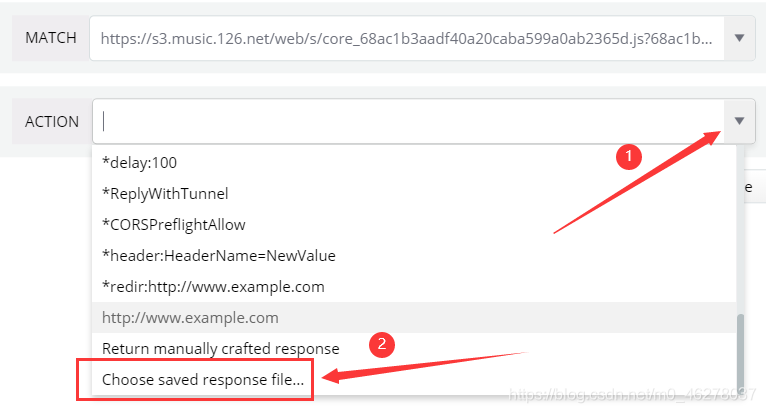
選中之前保存的core.js,就是core_68ac1b3aadf40a20caba599a0ab2365d.js
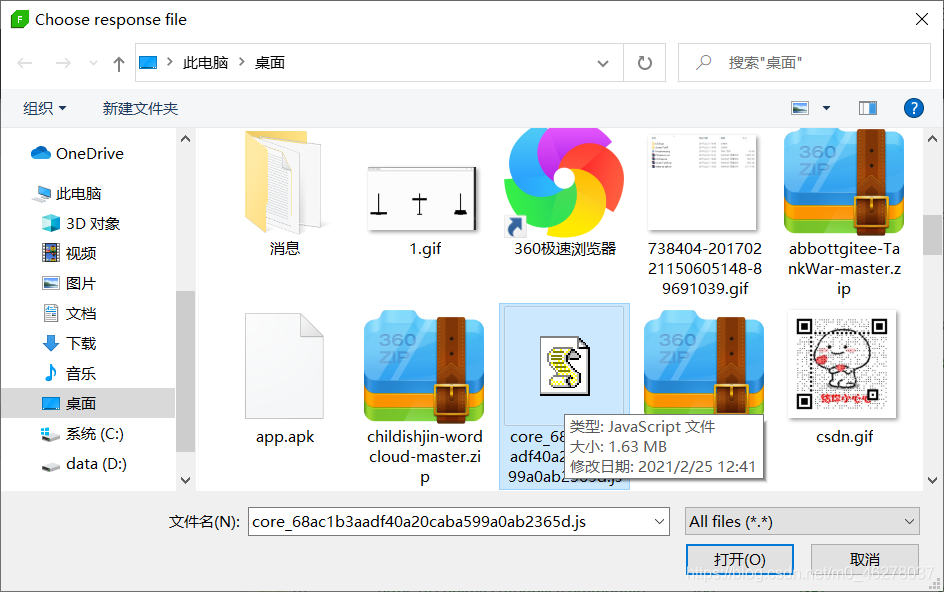
最后點Add to Queue
這樣就完成了:
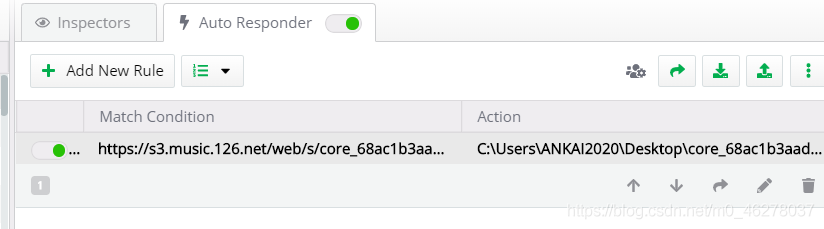
這步實際就是用本地修改過得core.js檔案替換服務器的core.js對請求作出回應,
這些設定完之后,清除瀏覽器快取,重繪頁面,就可以在console里面看到輸出的引數了,
什么?沒看到?清除瀏覽器快取啊,重啟瀏覽器啊,重啟Fiddle Everywhere啊,還看不到?
看不到就對了,因為在Sublime Text 中編輯完后沒有保存啊!
保存下,再重繪:
如圖,分別是第一頁和第二頁的第一個引數值
第一頁:
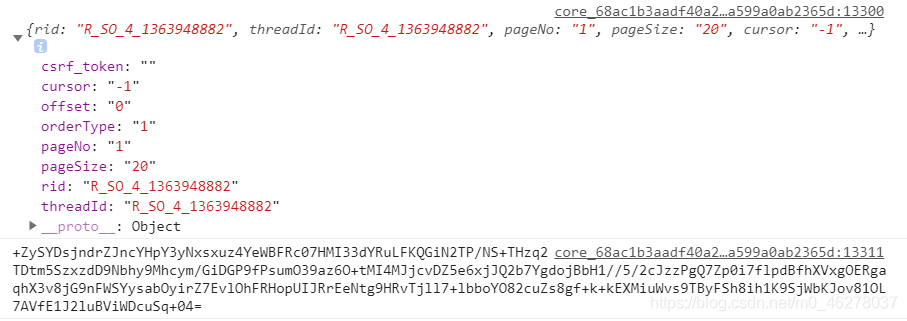
第二頁:
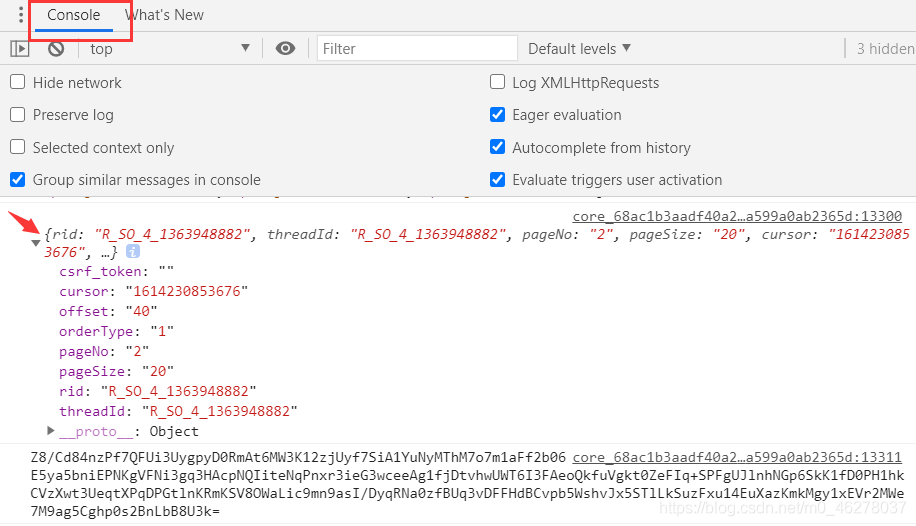
在這里,我遇到了最大的難題,至今未解決,
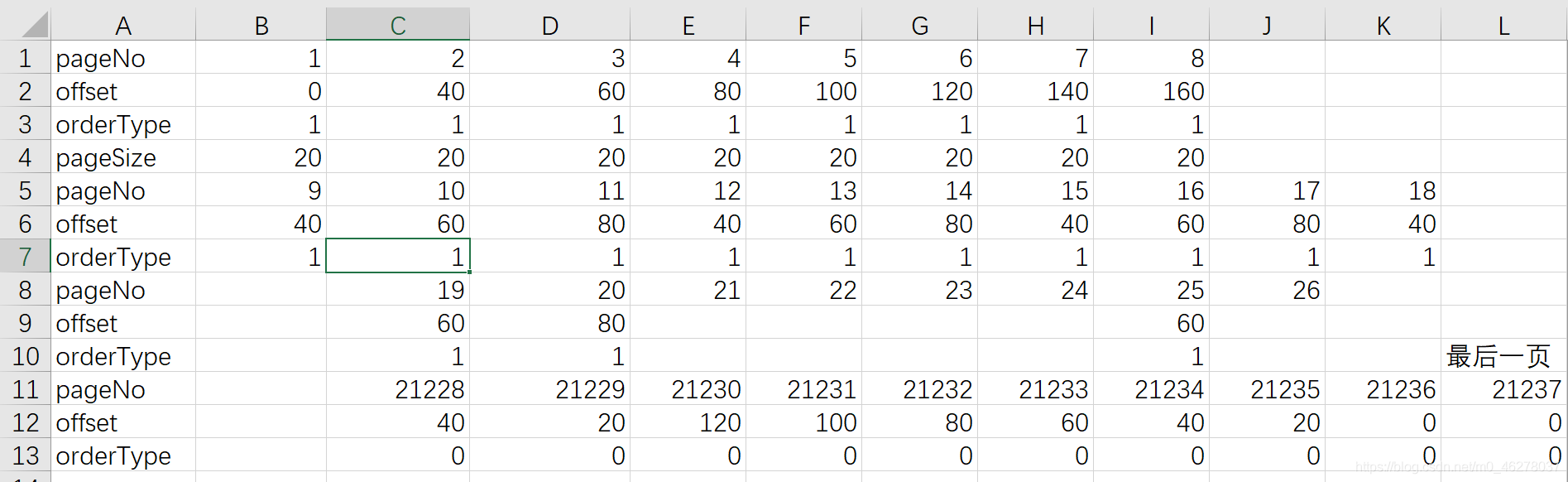
這是我試了N久得到的一些資料,至今沒有找到規律用數學公式寫出來,可能是網抑云的新的反爬方法吧,有人要試的話,記得每次都要F5重繪,有時候重繪一次還不行,比如在獲取2萬多頁后的資料時,每次顯示還不一樣,我又清空瀏覽器快取重繪幾次,資料不變了才記錄下來,因為頁碼是不能選的,只能這么一下下點擊,
資料:
都做到這了,總不能半途而廢吧,我就參考了其他人的資料:
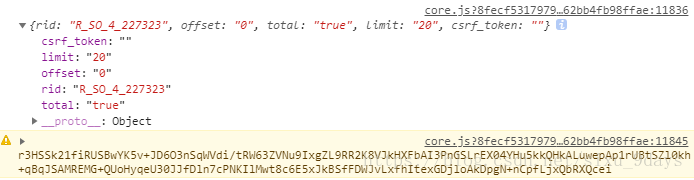
我發現網上所有的教程截圖全是這樣的資料,偏偏我的不一樣?????應該是網易云反爬的措施吧,
這樣的資料好處理:rid就是R_SO_4_加上歌曲的id,offset就是(評論頁數-1) * 20,total在第一頁是true,其余是false,
百思不得其解怪來了!!!后面的代碼用的就是這幾個以前的引數,程式竟然跑起來了!!!
不管了,繼續學原理!
按這樣的方式可以得到其余三個引數:
這樣,別忘了保存,然后清空瀏覽器快取,再重繪:
第二個引數值:

010001

第三個引數值:
00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7

第四個引數值:
0CoJUm6Qyw8W8jud

再次警告:
下載到本地的core.js檔案要趕快使用,我中午出去吃了個飯,回來接著寫的時候發現已經失效了


你看,引數已經發生了變化,快使用!噢應該著急的是我,我應該快截圖,不然前面的步驟又要再演示一次了,
分析加密函式:
可以發現,只有第一個引數隨頁面變化,其余三個引數都是不變的常量,至此 ,這四個引數我們都能夠在程式中通過代碼生成了,
那么,現在我們只要知道函式window.asrsea如何處理的就可以了,定位到這個函式:
我是在Sublime Text這么find來定位的,console中也可以,但是我用不太好,就在這find了:

這是結果:
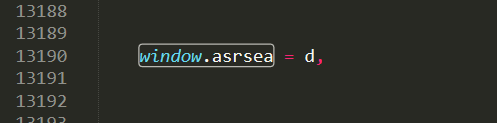
納尼?d? 什么鬼?函式?
再find:

然后搜到了好多好多的d,比找物件還難找!這誰受得了啊!
去隔壁控制臺搜下:
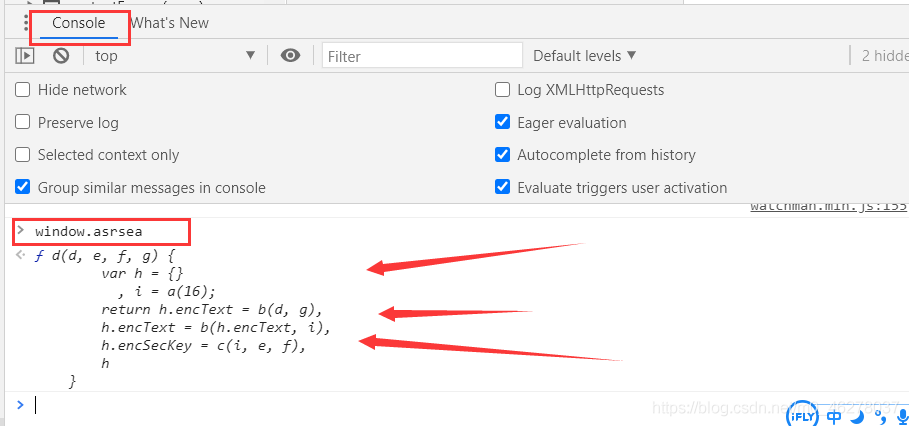
回車!啪!應聲而出,原來是你啊!

讀代碼,里面還有個b函式,console一下:

不行,沒辦法了,find吧,還好已經知道b有兩個引數了,而且還是個小寫的 b :

同樣的辦法揪出來c函式:
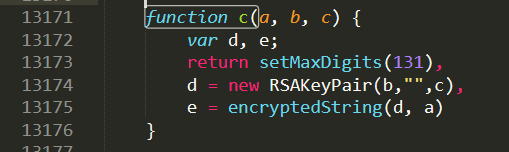
好了,bcd函式都就出來的啊,開始讀吧!
得,變數也是abcdef,果然網抑云啊!我抑郁了!!!
首先d函式:
function d(d, e, f, g) {
var h = {}
, i = a(16);
return h.encText = b(d, g),
h.encText = b(h.encText, i),
h.encSecKey = c(i, e, f),
h
}
研究過后,你就會發現:i 就是一個長度為16的隨機字串,既然是隨機的,就直接讓他等于16個F了,這個encText明顯就是params,encSecKey明顯就是encSecKey,而b函式就是一個AES加密,encText的獲得經過了兩次加密,第一次對 d 也就是第一個引數加密,key是第四個引數,第二次對第一次加密結果進行加密,key是 i ,在b函式中我們可以看到:
- 小注解:高級加密標準(AES,Advanced Encryption
Standard)為最常見的對稱加密演算法(微信小程式加密傳輸就是用這個加密演算法的),對稱加密演算法也就是加密和解密用相同的密鑰,
function b(a, b) {
var c = CryptoJS.enc.Utf8.parse(b)
, d = CryptoJS.enc.Utf8.parse("0102030405060708")
, e = CryptoJS.enc.Utf8.parse(a)
, f = CryptoJS.AES.encrypt(e, c, {
iv: d,
mode: CryptoJS.mode.CBC
});
return f.toString()
}
密鑰偏移量iv是0102030405060708,模式是CBC,那么就不難寫出對于第一個引數的加密了,
接下來是第二個引數encSecKey,你會發現c函式是一個RSA加密:
function c(a, b, c) {
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
- RSA加密是一種非對稱加密,可以在不直接傳遞密鑰的情況下,完成解密,這能夠確保資訊的安全性,避免了直接傳遞密鑰所造成的被破解的風險,是由一對密鑰來進行加解密的程序,分別稱為公鑰和私鑰,兩者之間有數學相關,該加密演算法的原理就是對一極大整數做因數分解的困難性來保證安全性,通常個人保存私鑰,公鑰是公開的(可能同時多人持有),
這里傳入 c 的三個引數 i 是16個F,e 是第二個引數,f 是第三個引數,全部是固定的值,那么無論歌曲id或評論頁數如何變化,這個encSecKey都不隨之發生變化,所以這個encSecKey對我們來說就是個常量,抄一個下來就是可以使用的,
至此,我們就能在程式中通過代碼獲取params和encSecKey這兩個引數了,
完整代碼:
# -*- coding:utf-8 -*-
import urllib.request
import http.cookiejar
import urllib.parse
import json
import time
import codecs
from Crypto.Cipher import AES
import base64
import os
class music:
#初始化
def __init__(self):
#設定代理,以防止本地IP被封
self.proxyUrl = "http://202.106.16.36:3128"
#request headers,這些資訊可以在ntesdoor日志request header中找到,copy過來就行
self.Headers = {
'Accept': "*/*",
'Accept-Language': "zh-CN,zh;q=0.9",
'Connection': "keep-alive",
'Host': "music.163.com",
'User-Agent':"Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.79 Safari/537.36"
}
# 使用http.cookiejar.CookieJar()創建CookieJar物件
self.cjar = http.cookiejar.CookieJar()
# 使用HTTPCookieProcessor創建cookie處理器,并以其為引數構建opener物件
self.cookie = urllib.request.HTTPCookieProcessor(self.cjar)
self.opener = urllib.request.build_opener(self.cookie)
# 將opener安裝為全域
urllib.request.install_opener(self.opener)
#第二個引數
self.second_param = "010001"
#第三個引數
self.third_param = "00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7"
#第四個引數
self.forth_param = "0CoJUm6Qyw8W8jud"
def get_params(self, page):
#獲取encText,也就是params
iv = "0102030405060708"
first_key = self.forth_param
second_key = 'F' * 16
if page == 0:
first_param = '{rid:"", offset:"0", total:"true", limit:"20", csrf_token:""}'
else:
offset = str((page - 1) * 20)
first_param = '{rid:"", offset:"%s", total:"%s", limit:"20", csrf_token:""}' % (offset, 'false')
self.encText = self.AES_encrypt(first_param, first_key, iv)
self.encText = self.AES_encrypt(self.encText.decode('utf-8'), second_key, iv)
return self.encText
def AES_encrypt(self, text, key, iv):
#AES加密
pad = 16 - len(text) % 16
text = text + pad * chr(pad)
encryptor = AES.new(key.encode('utf-8'), AES.MODE_CBC, iv.encode('utf-8'))
encrypt_text = encryptor.encrypt(text.encode('utf-8'))
encrypt_text = base64.b64encode(encrypt_text)
return encrypt_text
def get_encSecKey(self):
#獲取encSecKey
encSecKey = "257348aecb5e556c066de214e531faadd1c55d814f9be95fd06d6bff9f4c7a41f831f6394d5a3fd2e3881736d94a02ca919d952872e7d0a50ebfa1769a7a62d512f5f1ca21aec60bc3819a9c3ffca5eca9a0dba6d6f7249b06f5965ecfff3695b54e1c28f3f624750ed39e7de08fc8493242e26dbc4484a01c76f739e135637c"
return encSecKey
def get_json(self, url, params, encSecKey):
# post所包含的引數
self.post = {
'params': params,
'encSecKey': encSecKey,
}
# 對post編碼轉換
self.postData = urllib.parse.urlencode(self.post).encode('utf8')
try:
#發出一個請求
self.request = urllib.request.Request(url,self.postData,self.Headers)
except urllib.error.HTTPError as e:
print(e.code)
print(e.read().decode("utf8"))
#得到回應
self.response = urllib.request.urlopen(self.request)
#需要將回應中的內容用read讀取出來獲得網頁代碼,網頁編碼為utf-8
self.content = self.response.read().decode("utf8")
#回傳獲得的網頁內容
return self.content
def get_hotcomments(self, url):
#獲取熱門評論
params = self.get_params(1)
encSecKey = self.get_encSecKey()
content = self.get_json(url, params, encSecKey)
json_dict = json.loads(content)
hot_comment = json_dict['hotComments']
f = open('HotComments.txt', 'w', encoding='utf-8')
for i in hot_comment:
#將評論輸出至txt檔案中
time_local = time.localtime(int(i['time'] / 1000)) # 將毫秒級時間轉換為日期
dt = time.strftime("%Y-%m-%d %H:%M:%S", time_local)
f.write('用戶: ' + i['user']['nickname'] + '\n')
f.write('點贊數: ' + str(i['likedCount']) + '\n')
f.write('發表時間: ' + dt + '\n')
f.write('評論: ' + i['content'] + '\n')
f.write('-' * 40 + '\n')
f.close()
def get_allcomments(self, url):
#獲取全部評論
params = self.get_params(1)
encSecKey = self.get_encSecKey()
content = self.get_json(url, params, encSecKey)
json_dict = json.loads(content)
comments_num = int(json_dict['total'])
f = open('AllComments.txt', 'w', encoding='utf-8')
present_page = 0
if (comments_num % 20 == 0):
page = comments_num / 20
else:
page = int(comments_num / 20) + 1
print("共有%d頁評論" % page)
print("共有%d條評論" % comments_num)
# 逐頁抓取
for i in range(page):
params = self.get_params(i + 1)
encSecKey = self.get_encSecKey()
json_text = self.get_json(url, params, encSecKey)
json_dict = json.loads(json_text)
present_page = present_page + 1
for i in json_dict['comments']:
# 將評論輸出至txt檔案中
time_local = time.localtime(int(i['time'] / 1000))# 將毫秒級時間轉換為日期
dt = time.strftime("%Y-%m-%d %H:%M:%S", time_local)
f.write('用戶: ' + i['user']['nickname'] + '\n')
f.write('點贊數: ' + str(i['likedCount']) + '\n')
f.write('發表時間: ' + dt + '\n')
f.write('評論: ' + i['content'] + '\n')
f.write('-' * 40 + '\n')
print("第%d頁抓取完畢" % present_page)
f.close()
mail = music()
mail.get_hotcomments("https://music.163.com/weapi/v1/resource/comments/R_SO_4_1363948882?csrf_token")
mail.get_allcomments("https://music.163.com/weapi/v1/resource/comments/R_SO_4_1363948882?csrf_token")
執行:
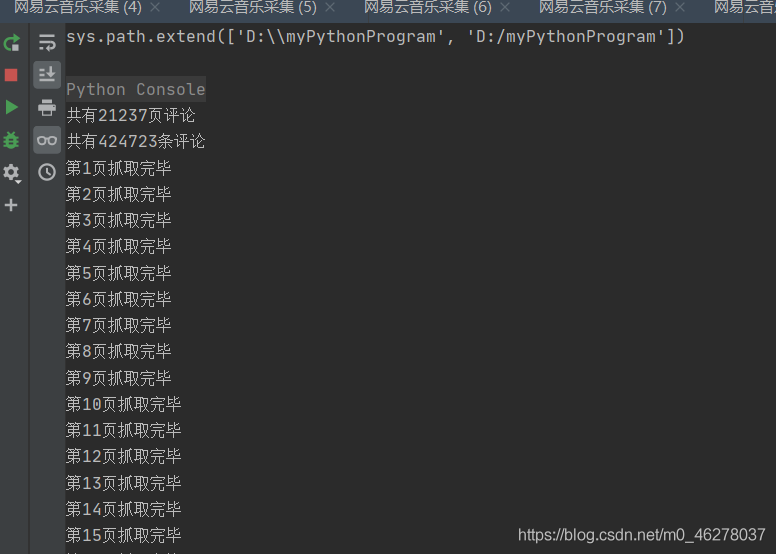
2萬頁!!!當然是我去睡覺讓Python慢慢的爬啦!
早上起來看到:

打開看看: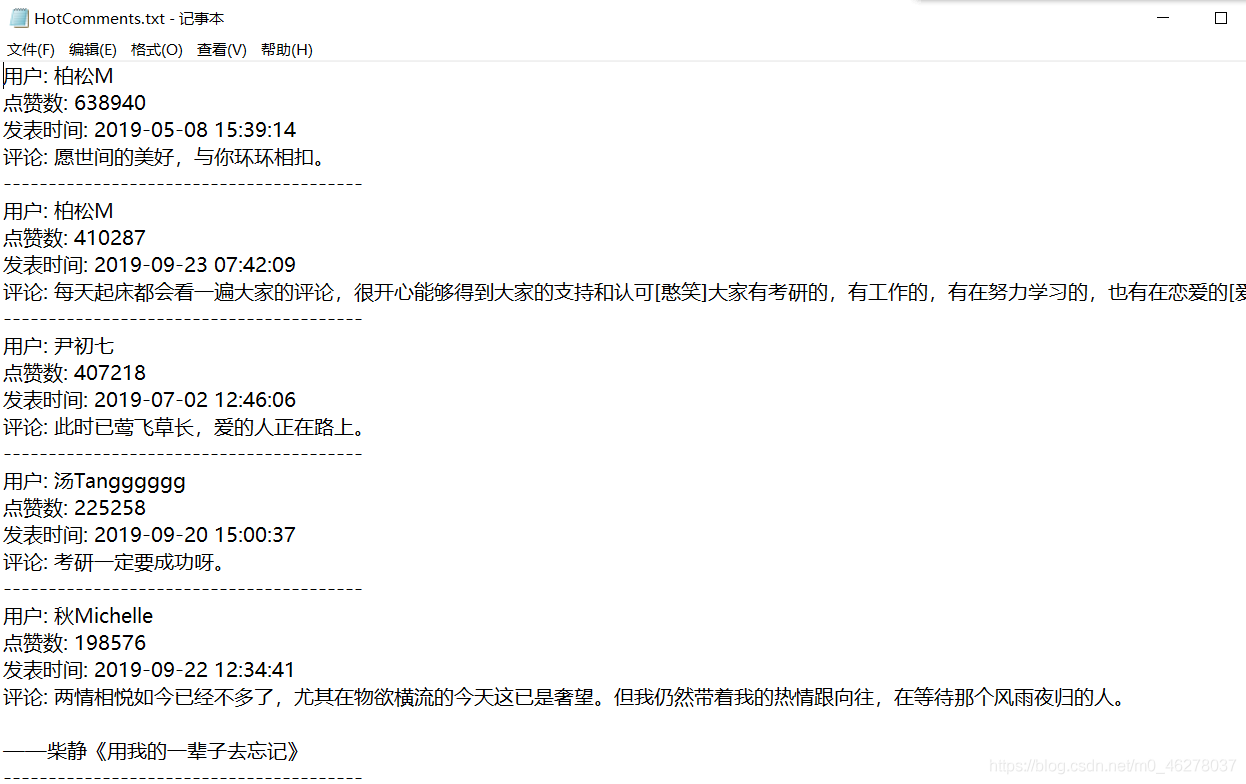
對比下:
最后一頁:
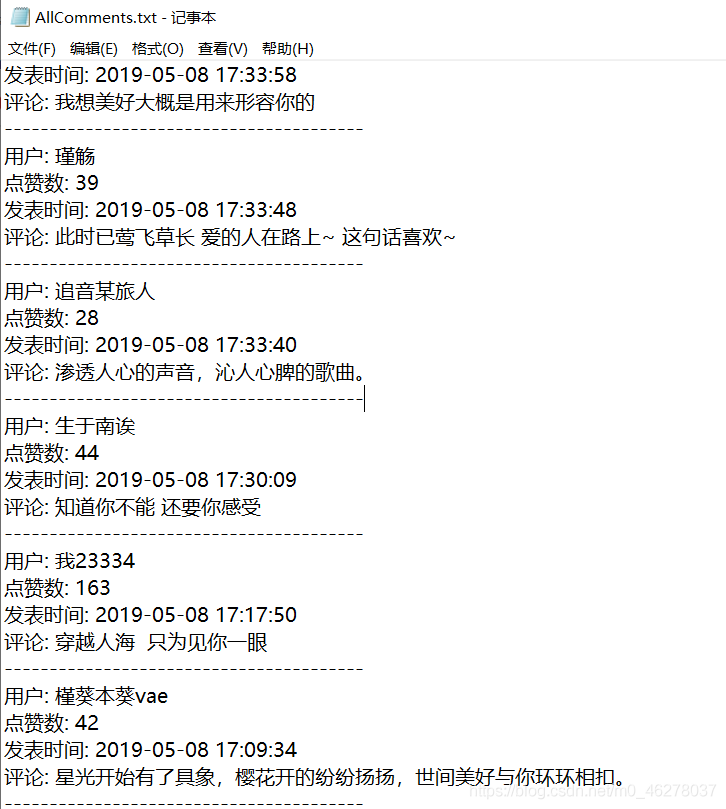
對比:
21239,哎呀,過了一夜又多了兩頁評論,
好了,到此結束!改下ID就可以爬其他人的啦!
情感分析:
接下來用stylecloud來進行情感分析,簡單的把爬取的評論用詞云展示出來不是分析,必須要經過詞云清洗才行,所用的stopwords.txt是本文開頭提到的,可以根據需要修改stopwords.txt,
由于評論過多的話爬取會消耗很多時間,所以情感分析另外建了個檔案,
完整代碼:
from stylecloud import gen_stylecloud
import jieba
def jieba_cloud(file_name, icon):
with open(file_name, 'r', encoding='utf8') as f:
word_list = jieba.cut(f.read())
result = " ".join(word_list) # 分詞用 隔開
# 設定停用詞
stopwords_file = open('stopwords.txt', 'r', encoding='utf-8')
stopwords = [words.strip() for words in stopwords_file.readlines()]
# 制作中文詞云
icon_name = " "
if icon == "1":
icon_name = "fas fa-grin-hearts"
elif icon == "2":
icon_name = "fas fa-space-shuttle"
elif icon == "3":
icon_name = "fas fa-heartbeat"
elif icon == "4":
icon_name = "fas fa-bug"
elif icon == "5":
icon_name = "fas fa-thumbs-up"
elif icon == "6":
icon_name = "fab fa-qq"
pic = str(icon) + '.png'
if icon_name is not None and len(icon_name) > 0:
gen_stylecloud(text=result,
size=1024, # stylecloud 的大小(長度和寬度)
icon_name=icon_name,
font_path='simsun.ttc',
max_font_size=250, # stylecloud 中的最大字號
max_words=5000, # stylecloud 可包含的最大單詞數
# stopwords=TRUE, # 布林值,用于篩除常見禁用詞
custom_stopwords=stopwords, # 定制停用詞串列
output_name=pic)
else:
gen_stylecloud(text=result, font_path='simsun.ttc', output_name=pic)
return pic
# 主函式
if __name__ == '__main__':
jieba_cloud("AllComments.txt", "1")
jieba_cloud("AllComments.txt", "2")
jieba_cloud("AllComments.txt", "3")
jieba_cloud("AllComments.txt", "4")
jieba_cloud("AllComments.txt", "5")
jieba_cloud("AllComments.txt", "6")
效果:







轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/264194.html
標籤:其他