本專案針對輿情食品安全領域進行物體關系的抽取,工程主要分為爬蟲、資料清洗、資料標注、模型的訓練、模型的預測,關系抽取采用的是TextCNN,下面介紹下工程的開發邏輯,
1、介紹下整體的工程架構
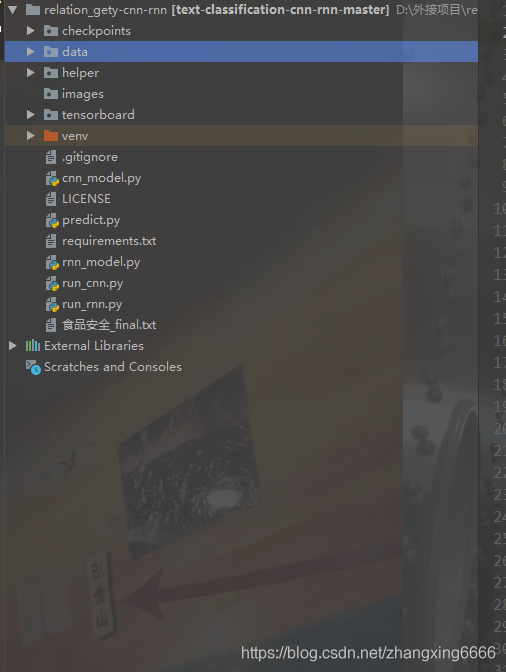
2、介紹下爬蟲和資料處理部分,都放在data目錄下面:
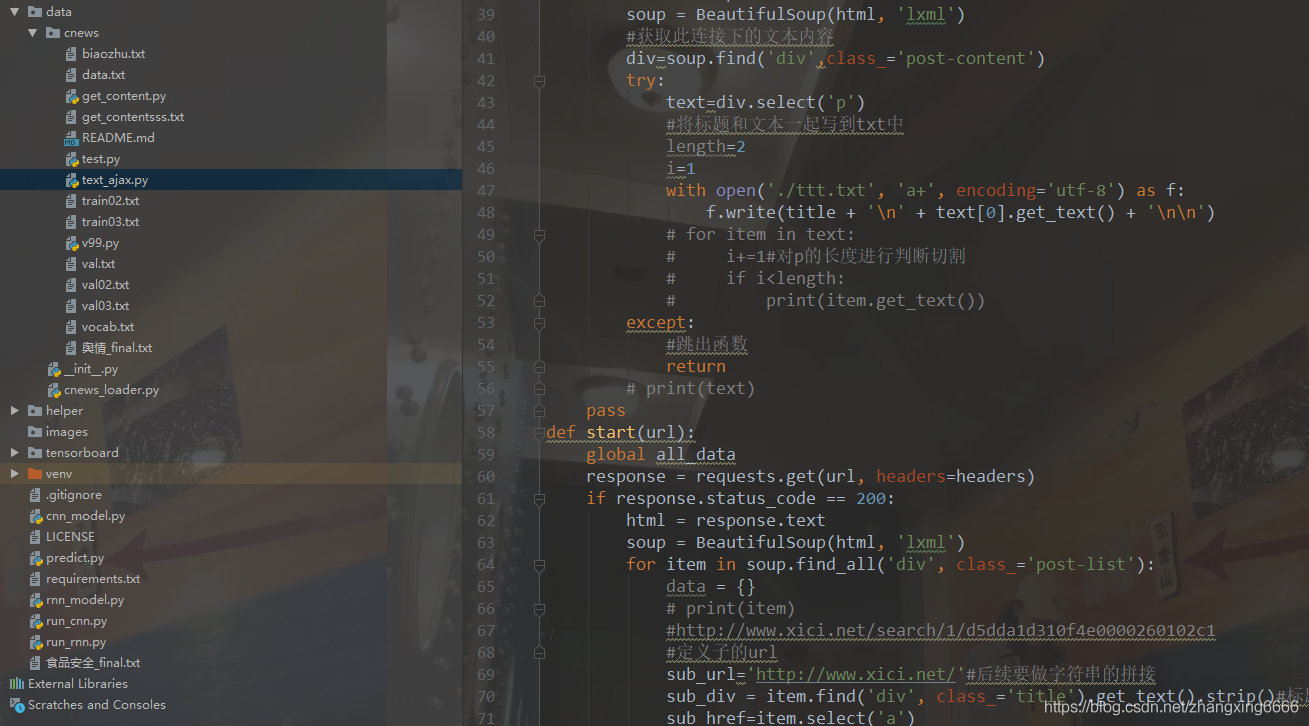
3、針對清洗后的資料,需要進行資料的標注,后面提供給深度學習模型訓練:

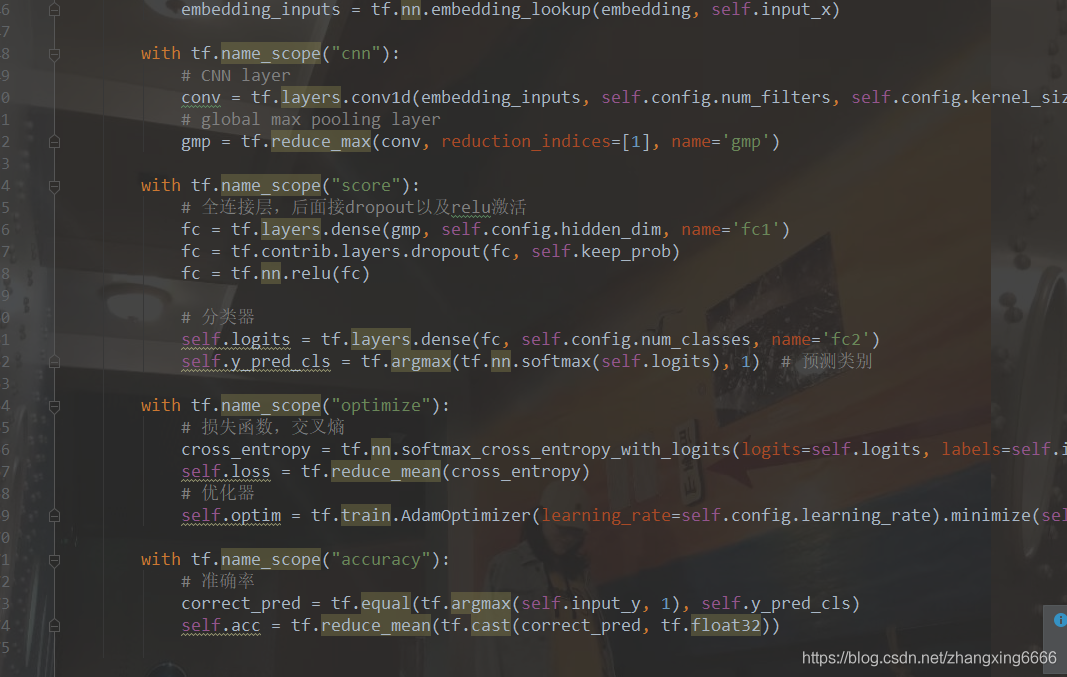
4、定義CNN模型網路結構:
5、進行模型的訓練,最終的準確率在訓練集和測驗集上達到75到80左右
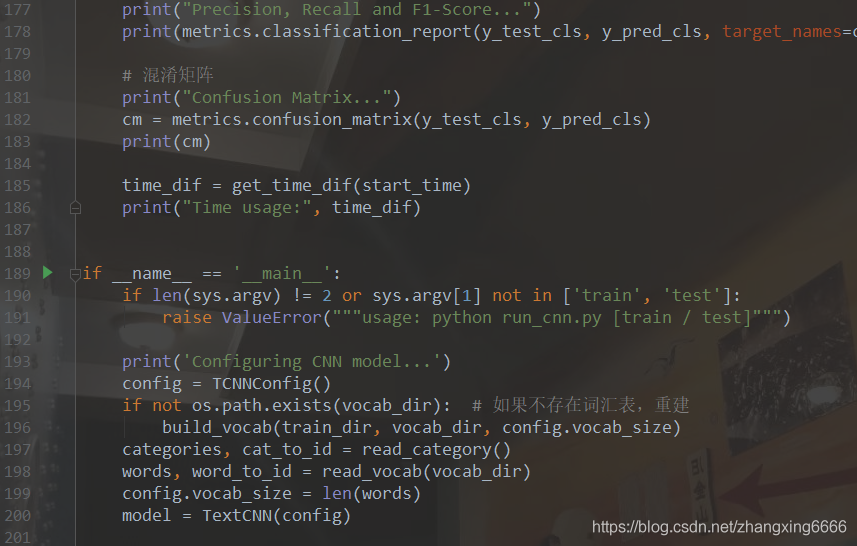
6、模型的預測結果如下所示:
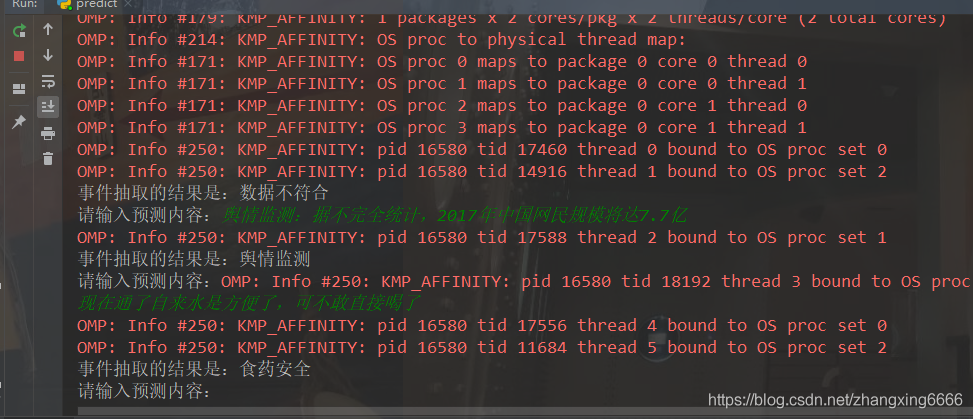
總結:從從抽取結果看,效果是可以的,需要資料集的可以郵我:sessioncookies@163.com,歡迎三連呀!后面會有更多落地的NLP實戰,歡迎關注公眾號(微信搜索公眾號即可,不定期推送干貨喔):知識圖譜NLP
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/271553.html
標籤:其他
下一篇:Beats:為 Beats => Logstash => Elasticsearch 架構創建 template 及 Dashboard