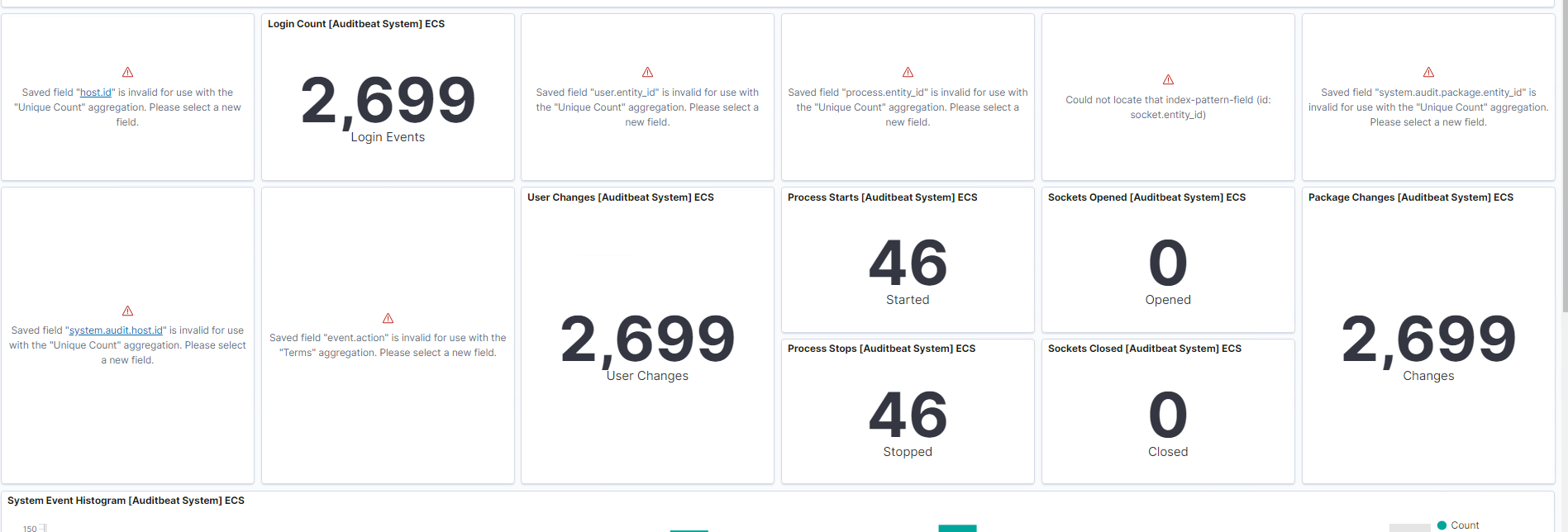
前一段時間有一個開發者私信我說自己的 Beats 連接到 Logstash,然后連接到 Elasticsearch,等資料在 Elasticsearch 中收集完后,發現 Kibana 中的 Dashboard 不能被使用,資料型別不匹配,這個到底是什么原因呢?
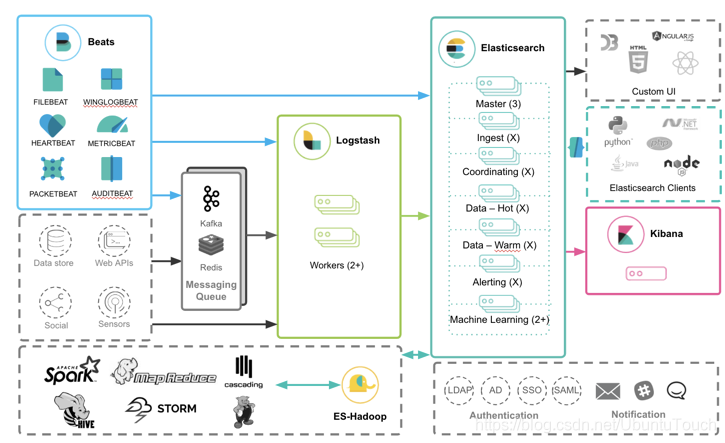
Beats 為我們的資料匯入帶來了極大的方便,目前在 Elastic Stack 的架構中:
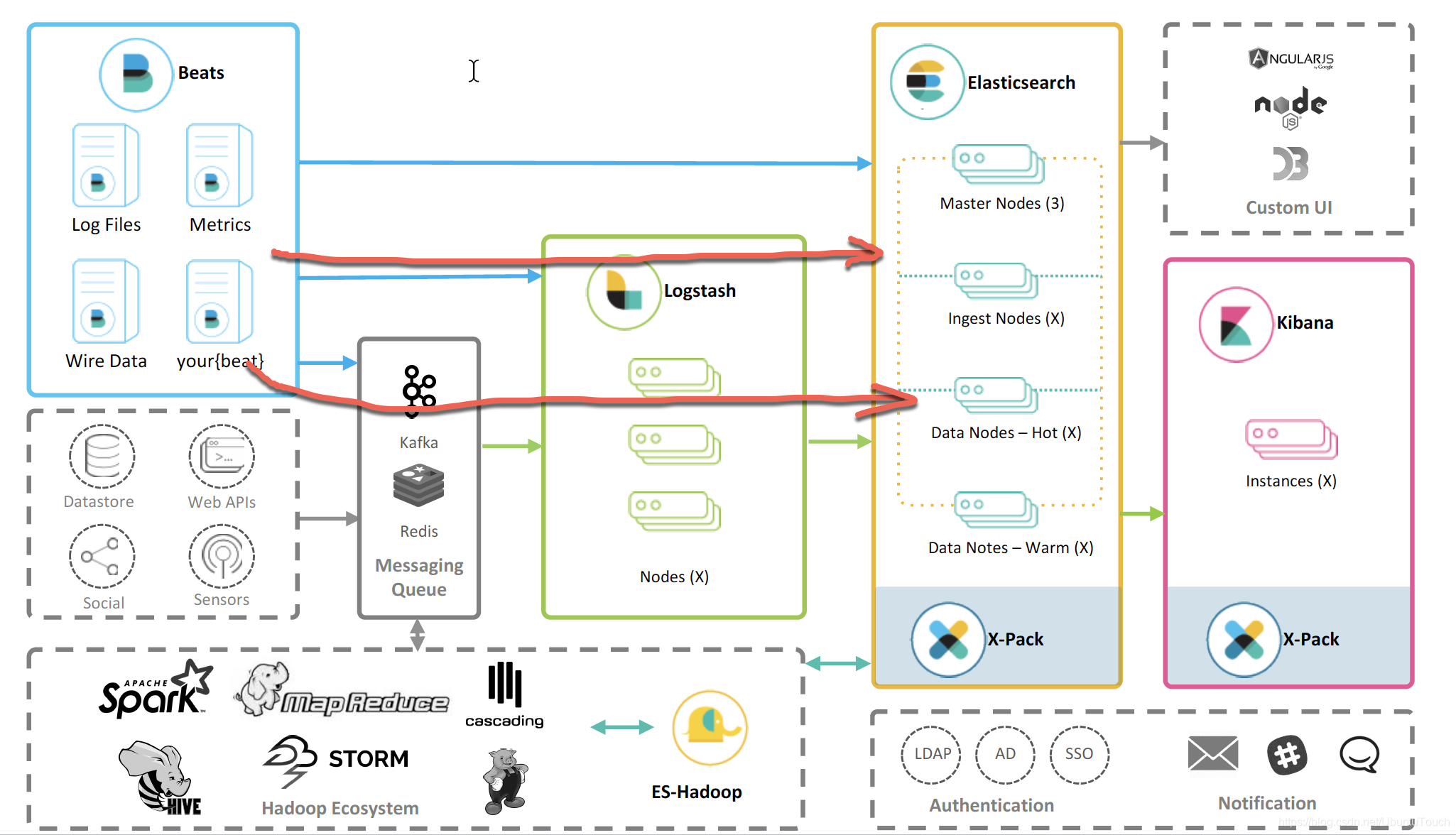
我們可以通過如下的三種路徑把資料匯入到 Elasticsearch 中:
- Beats ==> Elasticsearch
- Beats ==> Logstash ==> Elasticsearch
- Beats ==> Kafka ==> Logstash ==> Elasticsearch
如果你對這個架構還不是很了解的話,請參閱我之前的文章:
- Beats:Beats 入門教程 (一)
- Beats:Beats 入門教程 (二)
每個 Beats 含有各種模塊,它為我們常見的服務提供了很方便的資料采集方式,我們基本上可以開箱即用這些模塊,你可以詳細閱讀文章 Beats:Beats 入門教程 (二)來了解如何啟動這些模塊,
在 Beats 的模塊啟動中,我們通常采用 setup 來進行匯入 template, ingest pipeline,ILM policy 及 Dashboard,你可以詳細閱讀文章 “Beats:解密 Filebeat 中的 setup 命令”,在那篇文章中,我們非常需要注意的一點是:如果你沒有一個 template,那么等 Elasticsearch 收集第一個資料,它就會按照自己默認的方式為你的資料創建一個 mapping,這個也就是在 Elasticsearch 中常說的 schemaless,但是在很多的情況下這個并不是最優的 mapping,當我們使用 Beats 匯入的 Dashboard,它適合于使用 setup 命令而匯入的 index template 所定義的資料型別,你可以閱讀 “Elasticsearch: Index template” 以了解更多,
當我們使用 Beats 時,我們最重要的一點就是先執行 setup,而后再匯入資料,然而對于如下的兩種輸入方式:
- Beats ==> Logstash ==> Elasticsearch
- Beats ==> Kafka ==> Logstash ==> Elasticsearch
由于我們的 Beats 并不是直接連接到 Elasticsearch,在執行 setup 時,它并不能起到作用,那么我們該怎么辦呢?
正對上面的兩種情況,我們需要首先按照如下的方式配置 Beats:
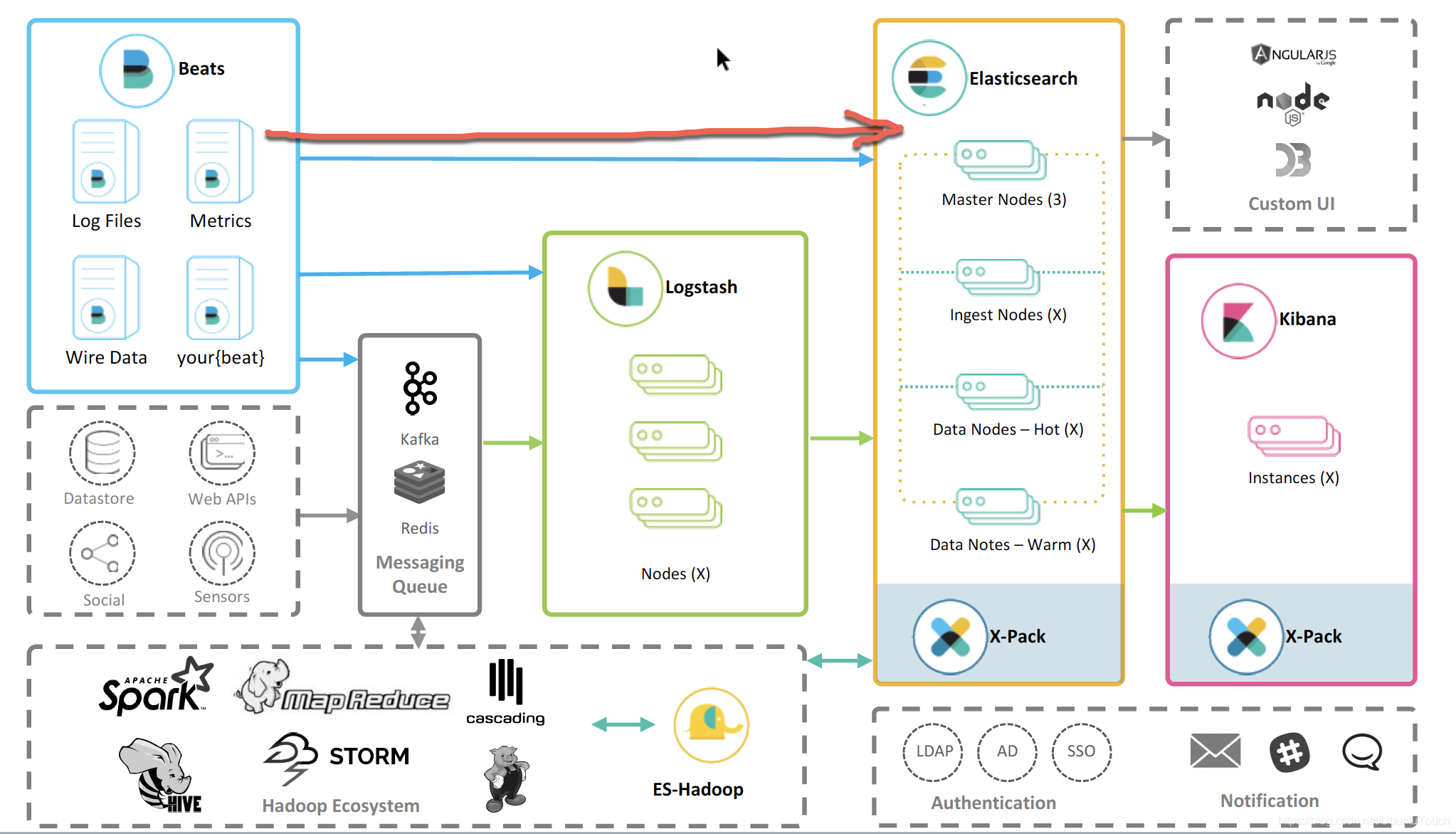
也就是:
- Beats ==> Elasticsearch
當我們執行完 setup 命令之后,我們就創建好了相應的 index template,index pattern, ILM policy 以及 Dashboard 等,這個程序我們可以稱之為 Bootstrap,然后,當我們匯入資料的時候,我們按照之前的連接方式匯入資料,也就是:
- Beats ==> Logstash ==> Elasticsearch
- Beats ==> Kafka ==> Logstash ==> Elasticsearch
值得注意的是:setup 針對任何的 Beats,只需要運行一次就可以了,這樣匯入的資料,它完全可以使用之前的 Dashboard 進行展示,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/271554.html
標籤:其他
上一篇:基于深度學習的物體關系抽取
下一篇:Spring框架