文章目錄
- 一、分塊查找演算法
- 二、實體:實作分塊查找演算法
本系列文章通過 1000(一篇文章表示 1 個實體) 個實體 ,為讀者提供較為詳細的練習題目,以便讀者舉一反三,深度學習,本系列的文章涉及到 Python 知識點包括:Python 語言基礎、運算子和運算式、陳述句和程式結構、串列和元組、字典和集合、字串、正則運算式、函式、面向物件編程、模塊和包、例外處理和程式除錯、檔案和目錄操作、資料庫編程、界面編程、網路編程、WEB 編程、行程和執行緒、網路爬蟲、游戲編程等知識點,由易到難,由淺入深,一步步打下堅實的編程基礎,
本系列文章涉及的演算法包括搜索、回溯、遞回、排序、迭代、貪心、分治和動態規劃等,涉及的資料結構包括字串、串列、指標、區間、佇列、矩陣、堆疊、鏈表、哈希表、線段樹、二叉樹、二叉搜索樹和圖結構等,
本系列文章是筆者為適應當前教育改革的創新要求,更好地踐行語言類課程,滿足實踐教學與創新能力培養的需要,閱讀大量書籍、各大互聯網公司的面試演算法、LintCode、LeetCode、九章演算法和結合筆者近幾年專案經驗撰寫的系列文章,精選了 1000 個趣味性、實用性強的應用實體,從不同難度、不同演算法、不同型別和不同資料結構等方面,將實際演算法進行總結,希望為 Python 編程人員拋磚引玉,由于筆者經驗與水平有限,博文中疏漏及不妥之處在所難免,衷心地希望各位讀者在評論區多提寶貴意見及具體的修改建議,以便筆者進一步修改和完善,
一、分塊查找演算法
分塊查找是二分法查找和順序查找的改進方法,分塊查找要求索引表是有序的,對塊內結點沒有排序要求,塊內結點可以是有序的也可以是無序的,
分塊查找就是把一個大的線性表分解成若干塊,每塊中的節點可以任意存放,但塊與塊之間必須排序,與此同時,還要建立一個索引表,把每塊中的最大值作為索引表的索引值,此索引表需要按塊的順序存放到一個輔助陣列中,查找時,首先在索引表中進行查找,確定要找的結點所在的塊,由于索引表是排序的,因此,對索引表的查找可以采用順序查找或二分查找;然后,在相應的塊中采用順序查找,即可找到對應的結點,
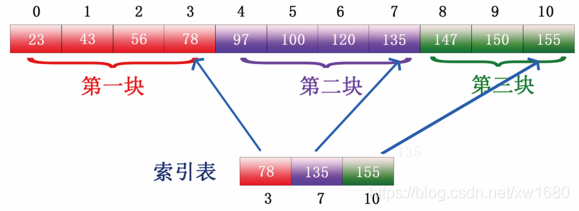
例如,有這樣一列資料:23、43、56、78、97、100、120、135、147、150,如下圖所示:

想要查找的資料是 150,使用分塊查找法步驟如下:
步驟1:將上圖所示的資料進行分塊,按照每塊長度為 4 進行分塊,分塊情況如下圖所示:

說明:每塊的長度是任意指定的,博主在這里用的長度為4,讀者可以根據自己的需要指定每塊長度,
步驟2:選取各塊中的最大關鍵字構成一個索引表,即選取上圖所示的各塊的最大值,第一塊最大的值是 78,第二塊最大的值是 135,第三塊最大值是 155,形成的索引表如下圖所示:
步驟3:用順序查找或者二分查找判斷想要查找資料 150 在上圖所示的索引表中的哪塊內容中,這里博主用的是二分查找法,即先取中間值 135 與 150 比較,如下圖所示:
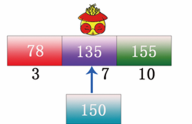
步驟4:結果是中間位置的資料 135 比目標資料 150 小,因此目標資料在 135 的下一塊內,將資料定位在第 3 塊內,此時將第 3 塊內的資料取出,進行順序比較,如下圖所示:

步驟5:通過順序查找第 3 塊的內容,終于在第 9 個位置找到目標數,此時分塊查找結束,
總結:至此,分塊查找演算法已經講解完畢,通過和二分查找法和順序查找法對比來看,分塊查找的速度雖然不如二分查找演算法,但比順序查找演算法快得多,當資料很多且塊數很大時,對索引表可以采用二分查找,這樣能夠進一步提高查找的速度,
二、實體:實作分塊查找演算法
具體代碼如下:
def search(data, key): # 用二分查找 想要查找的資料在哪塊內
length = len(data) # 資料串列長度
first = 0 # 第一位數位置
last = length - 1 # 最后一個資料位置
print(f"長度:{length} 分塊的資料是:{data}") # 輸出分塊情況
while first <= last:
mid = (last + first) // 2 # 取中間位置
if data[mid] > key: # 中間資料大于想要查的資料
last = mid - 1 # 將last的位置移到中間位置的前一位
elif data[mid] < key: # 中間資料小于想要查的資料
first = mid + 1 # 將first的位置移到中間位置的后一位
else:
return mid # 回傳中間位置
return False
# 分塊查找
def block(data, count, key): # 分塊查找資料,data是串列,count是每塊的長度,key是想要查找的資料
length = len(data) # 表示資料串列的長度
block_length = length // count # 一共分的幾塊
if count * block_length != length: # 每塊長度乘以分塊總數不等于資料總長度
block_length += 1 # 塊數加1
print("一共分", block_length, "塊") # 塊的多少
print("分塊情況如下:")
for block_i in range(block_length): # 遍歷每塊資料
block_data = [] # 每塊資料初始化
for i in range(count): # 遍歷每塊資料的位置
if block_i * count + i >= length: # 每塊長度要與資料長度比較,一旦大于資料長度
break # 就退出回圈
block_data.append(data[block_i * count + i]) # 每塊長度要累加上一塊的長度
result = search(block_data, key) # 呼叫二分查找的值
if result != False: # 查找的結果不為False
return block_i * count + result # 就回傳塊中的索引位置
return False
data = [23, 43, 56, 78, 97, 100, 120, 135, 147, 150, 155] # 資料串列
result = block(data, 4, 150) # 第二個引數是塊的長度,最后一個引數是要查找的元素
print("查找的值得索引位置是:", result) # 輸出結果
運行結果如下圖所示:
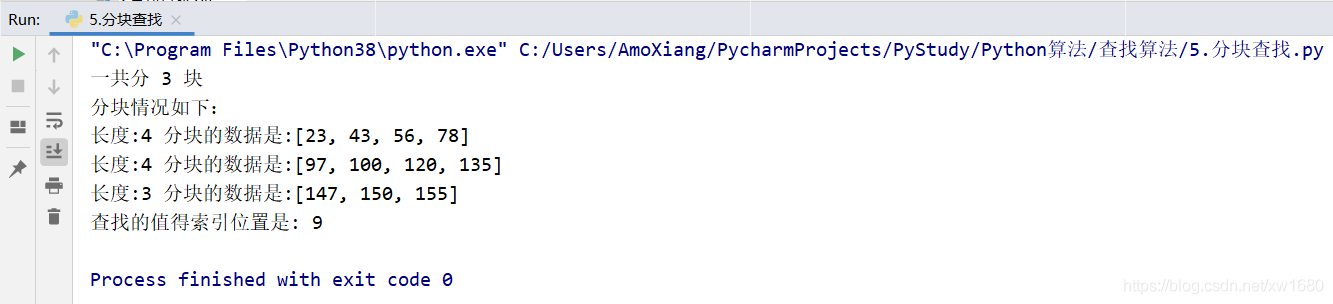
從上面的運行結果看到,當查找 150 時,查找結果完全符合上述描述的步驟,
感謝您閱讀本篇博文,希望本文能成為您編程路上的領航者,祝您閱讀愉快!

好書不厭讀百回,熟讀課思子自知,而我想要成為全場最靚的仔,就必須堅持通過學習來獲取更多知識,用知識改變命運,用博客見證成長,用行動證明我在努力,
如果我的博客對你有幫助、如果你喜歡我的博客內容,請點贊、評論、收藏一鍵三連哦!聽說點贊的人運氣不會太差,每一天都會元氣滿滿呦!如果實在要白嫖的話,那祝你開心每一天,歡迎常來我博客看看,
?編碼不易,大家的支持就是我堅持下去的動力,點贊后不要忘了關注我哦!
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/272526.html
標籤:其他