目錄
- 前言
- 一、buffer pool
- 二、redo log
- 三、binlog
- 四、兩階段提交
- 五、undo log
前言
在MySQL架構組件中簡單介紹了MySQL的一些基本組件,本節以InnoDB為背景介紹幾個核心日志模塊
??由于磁盤隨機讀寫的效率很低,MySQL為了提供性能,讀寫不是直接操作的磁盤檔案,而是在記憶體中開辟了一個叫做buffer pool的快取區域,更新資料的時候會優先更新到buffer pool,之后再由I/O執行緒寫入磁盤,同時為了InnoDB為了保證宕機不丟失buffer pool中的資料,實作crash safe,還引入了一個叫做redo log的日志模塊,另外還有處于MySQL Server層的用于備份磁盤資料的bin log,用于事務回滾和MVCC的undo log等,
一、buffer pool
??buffer pool作為一個快取池,以頁為單位,用于快取資料和索引等資料,對應表空間中的頁,回到MySQL組件圖,一條SQL經過服務層各個組件的處理之后,最終通過執行器呼叫存盤引擎提供的介面執行,如果是要更新一條資料,那么會先找到資料所在頁,將該頁加載到buffer pool中,在buffer pool中對資料進行修改,最侄訓通過IO執行緒再以頁為單位將快取中的資料刷入磁盤,
二、redo log
??由于引入了buffer pool,資料不是實時寫入磁盤的,如果資料還沒有寫入磁盤的時候MySQL宕機了,那么快取中的資料不就丟失了嗎?使用redo log來記錄這些操作,即使MySQL宕機,那么在重新啟動后也能根據這些記錄來恢復還沒有來得及寫入磁盤的資料,進而保證了事務的持久性,redo log是物理日志,記錄了某個資料頁上做了什么修改,屬于InnoDB引擎,MyISAM等不具備,下文會提到的binlog則屬于服務層,底層存盤引擎都共享,
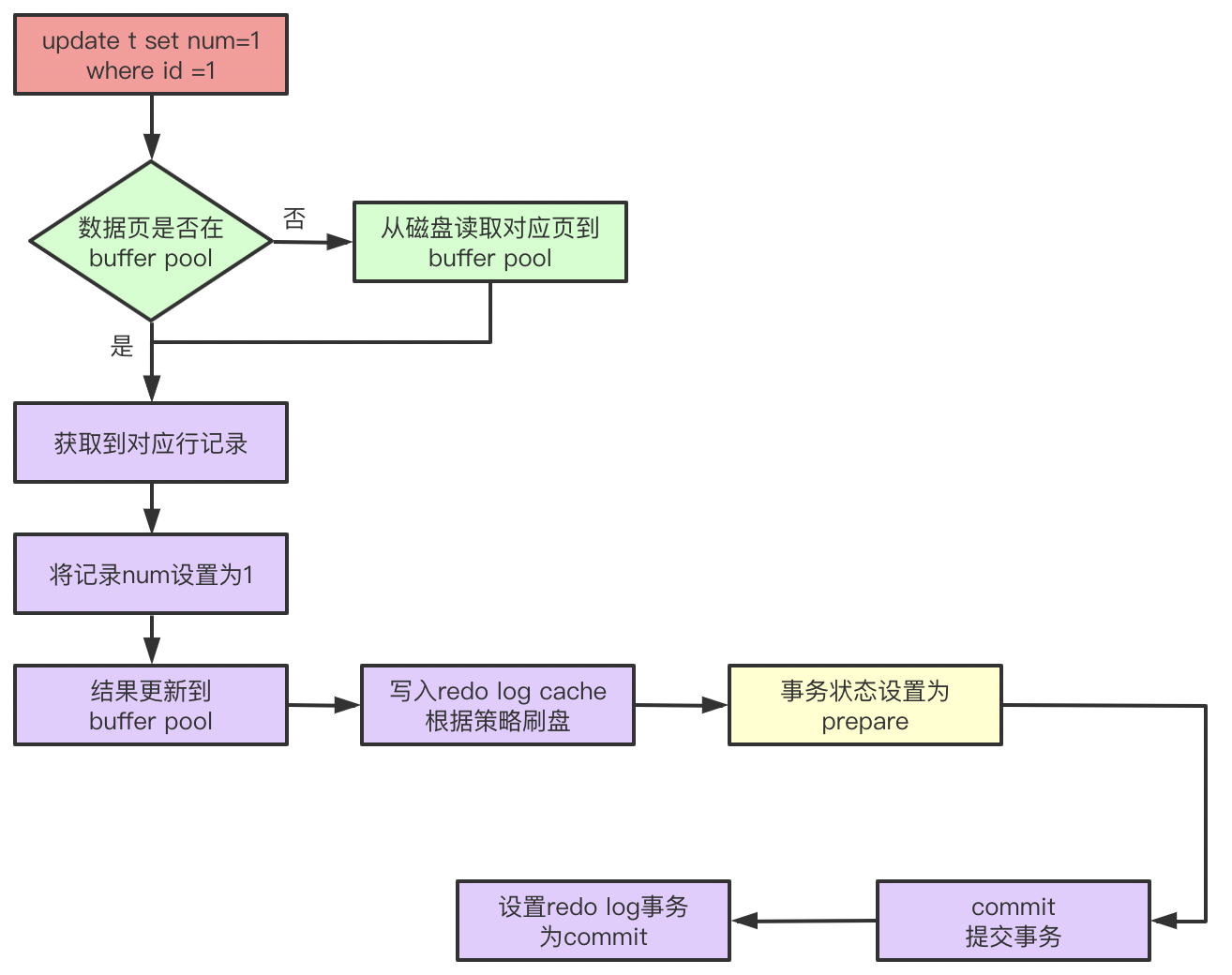
??有了buffer pool的介紹,我們知道記錄會先在buffer pool中更新,當pool中更新之后會在redo log buffer中添加對應的記錄,記錄某個資料頁上做了什么修改,事務會被設定為prepare狀態,這個時候就可以開始根據策略刷盤了,然后等待Server層處理(比如binlog寫入),在事務提交之后,標識redo log為已提交,
??redo log buffer中的資料也不是直接入盤,中間還會經過作業系統內核空間的緩沖區,也就是前文圖中的os buffer,然后才到磁盤上的redo log file,innodb_flush_log_at_trx_commit引數可以控制redo log buffer何時寫入redo log file,該引數有三個可選值,分別如下:
- 0:延遲寫,不會在事務提交時立即將redo log buffer寫入到os buffer,而是每秒寫入os buffer,然后立即寫入到redo log file,也就是每秒刷盤
- 1:實時寫,實時刷,每次事務提交都會將redo log buffer寫入os buffer,然后立即寫入redo log file,資料能夠及時入盤,但是每次事務提交都會刷盤,效率較低
- 2:實時寫,延時刷,每次事務提交都將redo log buffer寫入os buffer,然后每秒將os buffer寫入redo log file
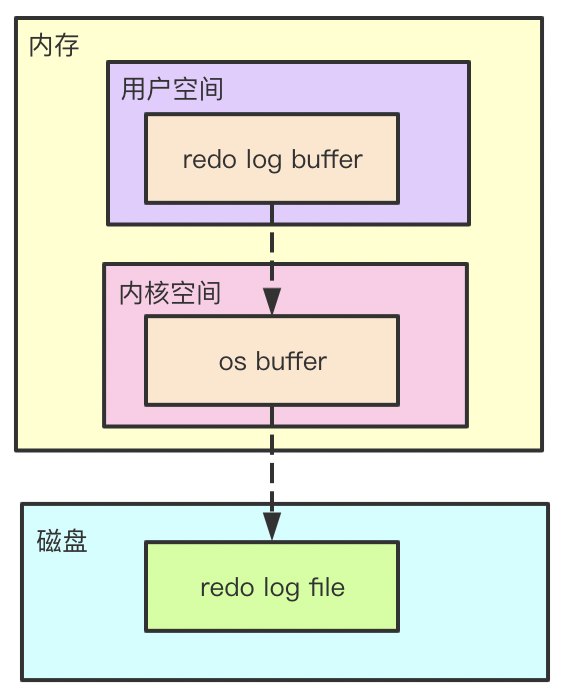
??redo log在記憶體中是由首位相連的四個檔案組成的,如下圖(網圖):
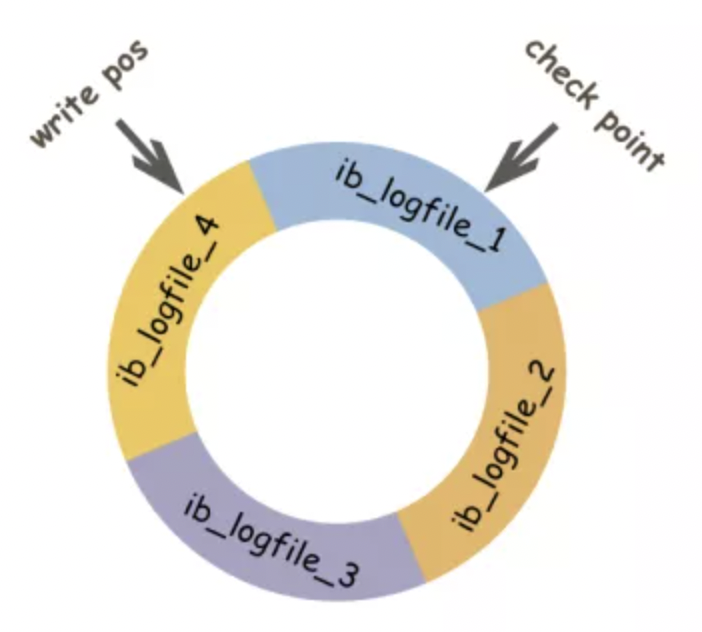
??寫入的時候從檔案頭部開始寫,每當要增加一條資料,就依次往尾部添加,所有檔案寫滿之后又會從頭開始寫,之前位置的資料會被覆寫,刷盤時也是從檔案頭部開始讀取,所以需要兩個引數分別表示刷盤后的位置和寫入位置,上圖中,write pos表示當前寫入位置,check point表示刷盤后的位置,假設redo log buffer的資料是順時針讀寫,那么check point順時針到write pos之間的資料是待刷盤資料,如果不刷盤資料則會被覆寫,write pos順時針到check point之間則是可用的空間,
??buffer pool中的資料需要刷盤,redo log buffer中的資料頁也需要刷盤,如果事務提交成功之后buffer pool中的資料還沒有刷盤,這時MySQL宕機了,那么在重啟的時通過比對redo log file和資料頁,可以從redo log file中恢復資料,redo log file根據innodb_flush_log_at_trx_commit引數配置,通常最多丟失一秒的資料,
??引入redo log后,一條更新SQL的流程是這樣的(二階段提交后文說明):
三、binlog
??redo log buffer主要可以在buffer pool資料還未刷盤宕機時保證事務的持久性,而binlog主要用于主從復制和資料恢復,可以通過引數max_binlog_size設定每個binlog檔案的大小,新增binlog資料時直接向檔案末尾添加,如果檔案大小達到了引數配置值,那么資料會記錄到新檔案中,這個和redo log的環形日志有鮮明的對比,binlog日志有三種級別,可以通過binlog-format指定,分別是:
- statement:基于SQL陳述句的賦值,只記錄SQL,不記錄資料變更,日志檔案比較小,能夠節約網路和磁盤IO,但是準確性不高,對一些系統函式,比如now(),不能準確復制,
- row:基于行的變更,不記錄SQL,記錄每行實際資料的變更,準確性比較高,但是由于記錄了資料變更,所以日志檔案較大,相對于statement有更高的網路和磁盤IO,通常建議使用這個級別,
- mixed:基于statement和row的混合模式,默認使用statement,statement無法復制的操作則使用row,可能發生binlog丟失,導致主從不一致(還沒去驗證過)
??在主從同步的場景中,Master開啟了binlog日志之后,會根據binlog級別將對應的日志內容記錄到二進制檔案中,Slave上會啟動IO執行緒連接到Master,請求讀取指定日志檔案指定位置的日志內容,Master接收到Slave的請求后,會有根據請求的日志檔案和位置讀取日志內容,然后回傳給Slave,同時還會回傳所讀取日志檔案現在到了哪個位置,
??Slave收到日志內容后,會將資料添加到relay log檔案的末尾,并且將Master回傳的binlog檔案和對應的最新位置記錄到master info檔案中,下次讀取對應日志檔案的時候就可以告訴Master從這個位置開始讀取,Slave檢測到realy log檔案有新增后,會決議內容,如果日志基于statement,那么就在Slave上重新執行這些SQL,如果日志基于row,那么Slave直接根據日志內容對對應的行做修改,
??但是要注意的是,對于Master來說,binlog也不是每次直接寫入磁盤的,binlog也有一個binlog cache,在事務提交之前,資料會放入binlog cache,提交之后再從binlog cache刷入磁盤,通過引數binlog_cache_size可以設定binlog cache的大小,通過引數sync_binlog控制刷盤策略:
- 0:不立即刷盤,由系統決定何時將binlog cache刷盤,性能最高,但是可能會丟失多個事務的資料
- N:每N個事務提交之后,將binlog cache刷盤,當N=1時,資料最安全,最多丟失一個事務的資料,但是性能也最低;當N大于1時,會累積多個事務,類似于0的情況,可能會丟失多個事務的資料
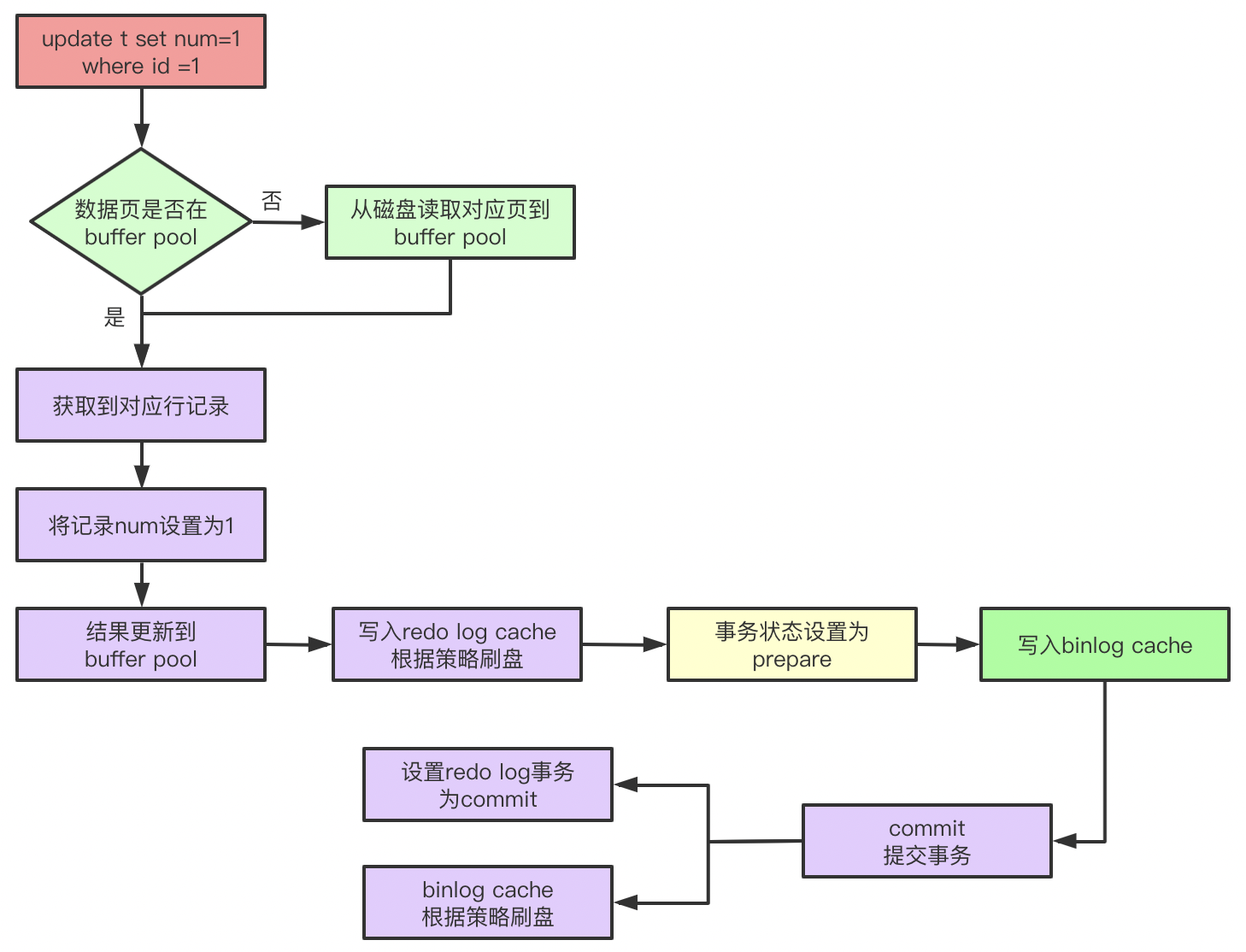
四、兩階段提交
??MySQL最開始是沒有InnoDB引擎的,binlog日志位于Server層,只是用于歸檔和主從復制,本身不具備crash safe的能力,而InnoDB依靠redo log具備了crash safe的能力,redo log和binlog同時記錄,就需要保證兩者的一致性,在前面小節中已經體現了,兩個log的寫入流程是:
寫入relo log->事務狀態設定為prepare->寫入binlog->提交事務->修改redolog事務狀態為commit
??先prepare后commit,這個稱為兩段提交,那么為什么需要兩個段提交呢?redo log和binlog是兩種不同的日志,就類似于分布式中的多節點提交請求,需要保證事務的一致性,redo log和binlog有一個公共欄位XID,代表事務ID,當引數innodb_support_xa打開時,在執行事務的第一條SQL時候會去注冊XA,根據第一條SQL的query id拼湊XID資料,然后存盤在事務物件中,
??如果兩個日志單純的分開提交,則可能會引發一些問題,如果簡單分開提交,那么對于一條更新陳述句執行,有兩種情況:
- 先寫binlog,后寫redo log:如果binlog寫入了,在寫redo log之前資料庫宕機,那么在重啟恢復的時候,通過binlog恢復了資料沒問題,但是由于redo log沒有寫入,這個事務應該無效,也就是原庫中就不應該有這條陳述句對應的更新,但是通過binlog恢復資料后,資料庫中就多了這條更新
- 先寫redo log,后寫binlog:如果redo log寫入了,在寫binlog之前資料庫宕機,那么在重啟恢復的時候,通過binlog恢復從庫,那么相對于主庫來說,從庫就少了這條更新
??采取了兩段提交之后,怎么做crash恢復呢?如果在寫入binlog之前宕機了,那么事務需要回滾;如果事務commit之前宕機了,那么此時binlog cache中的資料可能還沒有刷盤,那么驗證binlog的完整性:到redo log中找到最近事務的XID,根據這個XID到binlog中去找(XID Event),如果找到了,說明在binlog中對應事務已經提交,那么提交redo log中事務即可;否則需要回滾事務,
??至于為什么有binlog和redo log的共存,導致了這么一個復雜的局面,前面也提到了,InnoDB是后面引進MySQL的,redo log屬于InnoDB特有,保證了事務的持久性,而binlog則位于Server層,用于歸檔,
五、undo log
??當一個事務對記錄做出了變更,就會就會產生undo log,默認被記錄到**系統表空間(ibdata)**中,在5.6之后的版本也可以使用獨立的undo 表空間,
??關于表空間,可以理解為磁盤上的物理檔案,比如table1.ibd,就代表的table1表的獨立表空間,其中包含了資料頁、索引等資料,可以通過陳述句:
> show variables like '%innodb_data_file_path%'
> 結果:ibdata1:12M:autoextend
??查看系統表空間,結果顯示格式為name:size:attributes,分別表示名稱,大小和屬性,autoextend表示其會隨著資料增多自動擴容,
??相對于redo log是一種物理日志(記錄了某個資料頁發生了什么更改)來說,undo log則是一種邏輯日志,當一個事務對記錄做了變更操作就會產生undo log,也就是說undo log記錄了記錄變更的邏輯程序,籠統的說,當一個事務要更新一行記錄時,會把當前記錄當做歷史快照保存下來,多個歷史快斬訓用兩個隱藏欄位trx_id和roll_pointer串起來,形成一個歷史版本鏈,當需要事務回滾時,可以依賴這個歷史版本鏈將記錄回滾到事務開始之前的狀態,從而保證了事務的原子性(一個事務對資料庫的所有操作,要么全部成功,要么全部失敗),
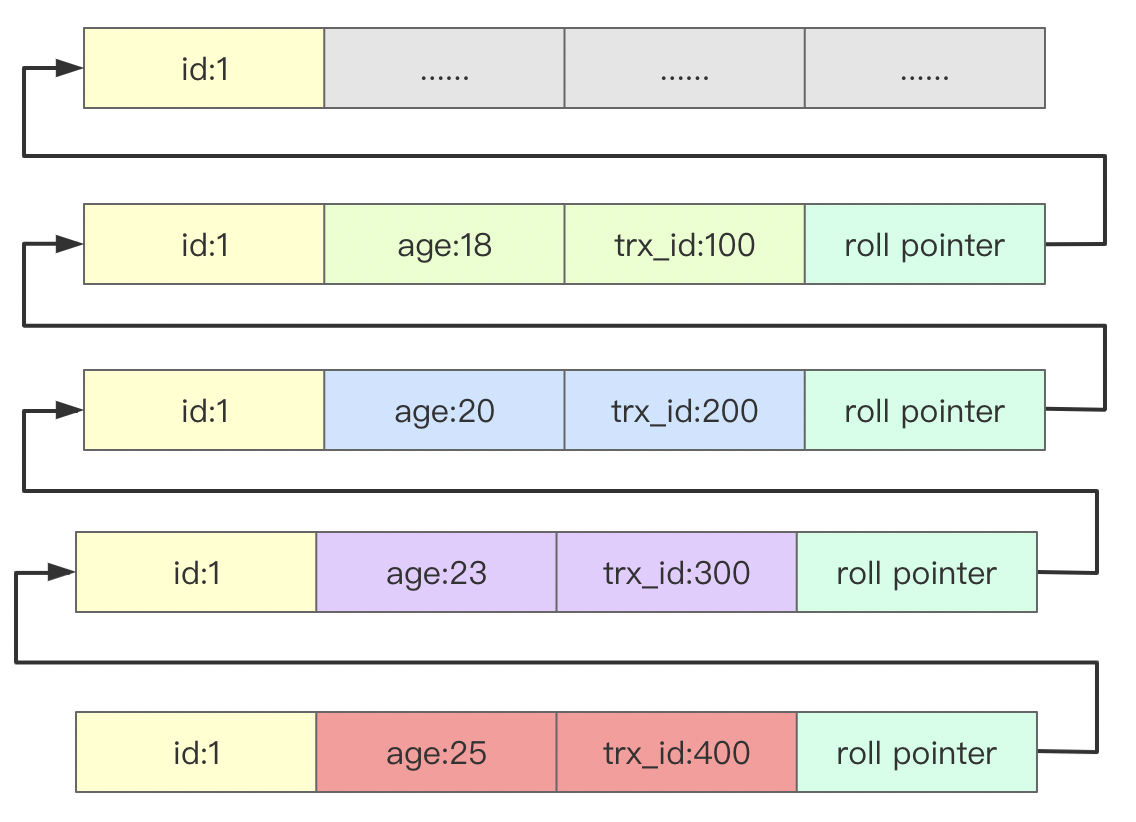
??總結來說,在InnoDB里,undo log分為兩種型別:
- insert undo log:插入產生的undo log,不需要維護歷史版本鏈,因為沒有歷史資料,所以其產生的undo log可以在事務提交之后洗掉,不需要purge操作
- update undo log:更新或洗掉產生的undo log,不會在提交后就立即洗掉,而是會放入undo log歷史版本鏈,用于MVCC,最后由purge執行緒清理
??為了保證多個事務并發操作,在寫各自的undo log時不產生沖突,InnoDB采用一種叫做回滾段(rollback segment,rseg)的結構來存盤undo log,InnoDB中最多可以創建128個回滾段,每個回滾段維護了一個段頭頁,在該頁中又劃分了1024個slot,每個slot又對應到一個undo log物件,雖然回滾段最多可以有128個,但是對于回滾段的布局結構:
- rseg0:預留在系統表空間ibdata中
- rseg 1- rseg 32:這32個回滾段存放于臨時表的系統表空間中
- rseg33 - 128: 普通回滾段,根據配置存放到獨立的undo表空間中,或者如果沒有打開獨立undo表空間,則存放于系統表空間ibdata中
??所以理論上InnoDB最多支持 96 * 1024個普通事務,在每一個讀寫事務開始(或只讀事務轉變為讀寫事務)的時候,都會以輪詢的方式預先為其分配一個普通回滾段(對于只讀事務,如果產生對臨時表的寫入,則需要使用第1~32號臨時表回滾段為其分配回滾段),回滾段分配之后,在這個事務的生命周期內,都會使用這個回滾段,
??當一個事務要存盤undo log的時候,就會從這個事務所使用的回滾段的1024個slot中根據使用undo log型別(insert或update)分配一個slot,如果同一型別的slot之前已經分配過,那么可以直接使用,否則就需要分配一個slot,并創建一個對應的undo頁,然后初始化,但是如果回滾段都用完了則會回傳錯誤,
??在事務提交后,需要purge的回滾段會被放到purge佇列上,留待后臺purge執行緒清理,另外還需要注意一點,對于洗掉操作,InnoDB并不是真正的洗掉原來的記錄,而是將其delete mark設定為1,puge執行緒會把這些標記未洗掉的資料真正從磁盤上洗掉,
參考:
https://mp.weixin.qq.com/s/XTpoYW–6PTqotcC8tpF2A
http://mysql.taobao.org/monthly/2015/04/01/
https://developer.aliyun.com/article/646471
https://zhuanlan.zhihu.com/p/33504555
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/272641.html
標籤:其他