
系列文章目錄
文章目錄
- 系列文章目錄
- 前言
- 一、鏈表的概念及結構
- 1.鏈表的概念
- 2.鏈表的結構
- 二、鏈表的種類
- 三、鏈表的實作
- 1.自定義鏈表結點struct SListNode
- 2.鏈表列印資料SListPrint
- 3.鏈表創建結點BuyListNode
- 4.鏈表尾部插入資料SListPushBack
- 5.鏈表頭部插入資料SListPushFront
- 6.鏈表尾部洗掉資料SListPopBack
- 7.鏈表頭部洗掉資料SListPopFront
- 8.鏈表查找資料SListFindKey
- 9.鏈表在pos位置之后插入資料SListInsertAfter
- 10.鏈表在pos位置之前插入資料SListInsertBefore
- 11.鏈表在pos位置之后洗掉資料SListEarseAfter
- 總結

前言
順序表的問題及思考
問題:
- 中間/頭部的插入洗掉,時間復雜度為O(N)
- 增容需要申請新空間,拷貝資料,釋放舊空間,會有不小的消耗,
- 增容一般是呈2倍的增長,勢必會有一定的空間浪費,例如當前容量為100,滿了以后增容到200,我們再繼續插入了5個資料,后面沒有資料插入了,那么就浪費了95個資料空間,
思考:
如何解決以上問題呢?下面給出了鏈表的結構來看看
一、鏈表的概念及結構
1.鏈表的概念
概念:鏈表是一種物理存盤結構上非連續、非順序的存盤結構,資料元素的邏輯順序是通過鏈表中的指標鏈接次序實作的 ,
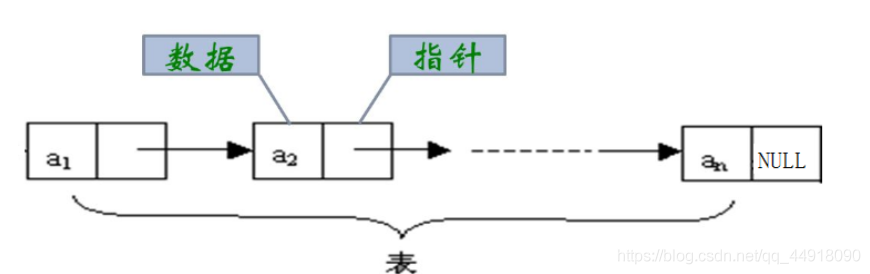
2.鏈表的結構
鏈表包括資料域和指標域:

資料結構中:
二、鏈表的種類
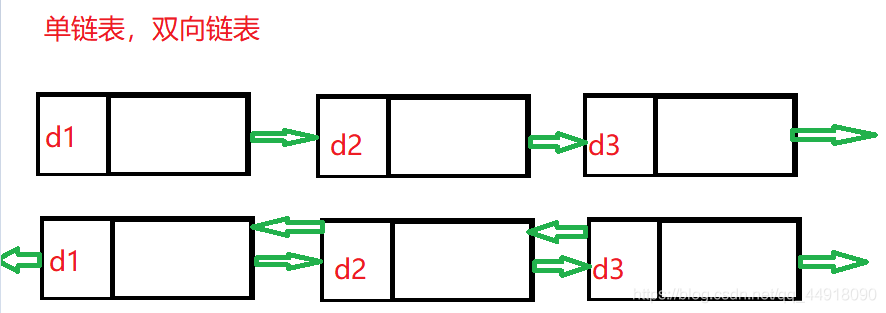
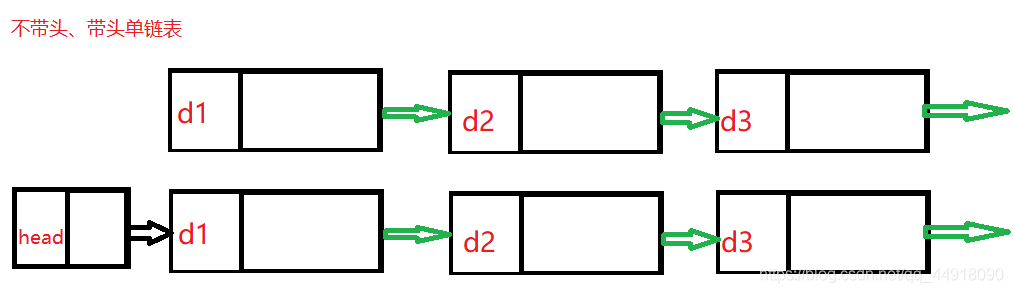
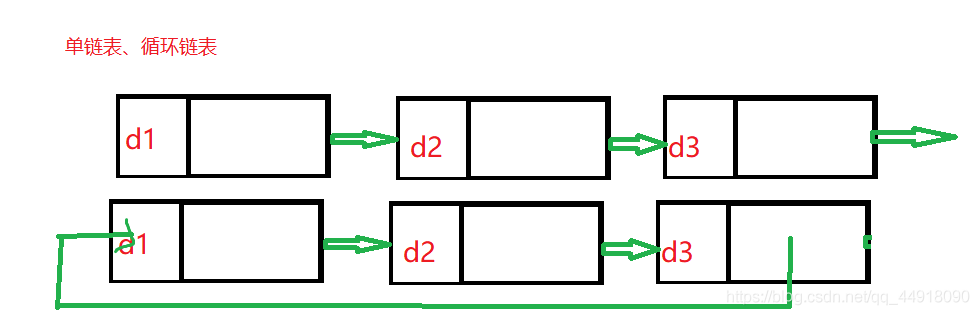
實際中鏈表的結構非常多樣,以下情況組合起來就有8種鏈表結構:
- 單向、雙向
- 帶頭、不帶頭
- 回圈、非回圈
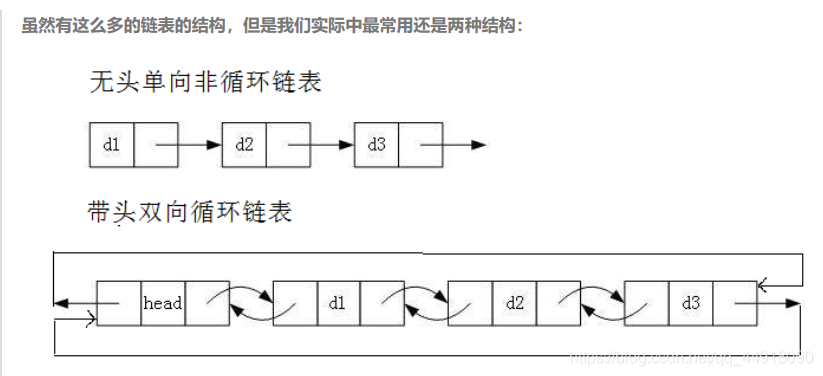
4. 無頭單向非回圈鏈表:結構簡單,一般不會單獨用來存資料,實際中更多是作為其他資料結構的子結
構,如哈希桶、圖的鄰接表等等,另外這種結構在筆試面試中出現很多,
5. 帶頭雙向回圈鏈表:結構最復雜,一般用在單獨存盤資料,實際中使用的鏈表資料結構,都是帶頭雙向回圈鏈表,另外這個結構雖然結構復雜,但是使用代碼實作以后會發現結構會帶來很多優勢,實作反而簡單了,后面我們代碼實作了就知道了
三、鏈表的實作
1.自定義鏈表結點struct SListNode
代碼如下:
#pragma once
#include<stdio.h>
#include<assert.h>
#include<stdlib.h>
typedef int SLTDateType;
typedef struct SListNode
{
SLTDateType data; //資料域
struct SListNode* next; //指標域
}SLTNode;
2.鏈表列印資料SListPrint
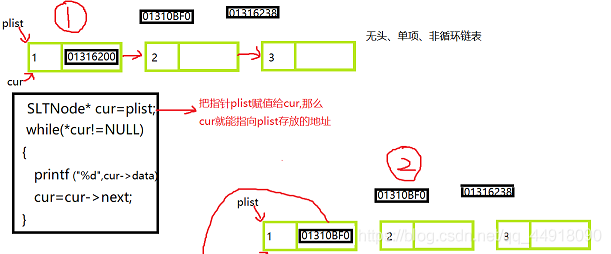
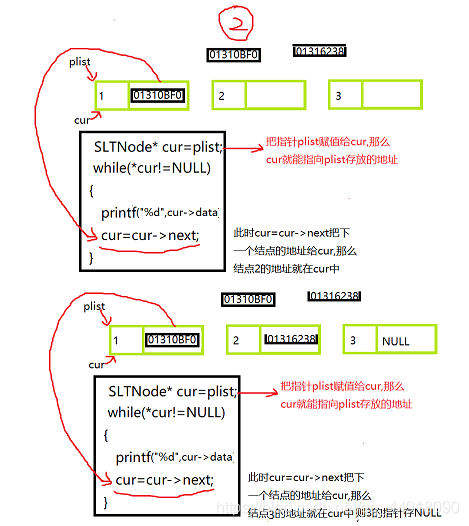
代碼如下:
void SListPrint(SLTNode* plist)
{
assert(plist);
SLTNode* cur = plist;
while (cur !=NULL)
{
printf("%d--> ", cur->data);
cur = cur->next;
}
printf("NULL\n");
}
3.鏈表創建結點BuyListNode
代碼如下:
SLTNode* BuyListNode(SLTDateType num) //創建一個結點
{
SLTNode* node = (SLTNode*)malloc(sizeof(SLTNode));
assert(node);
node->data = num;
node->next = NULL;
return node;
}
4.鏈表尾部插入資料SListPushBack
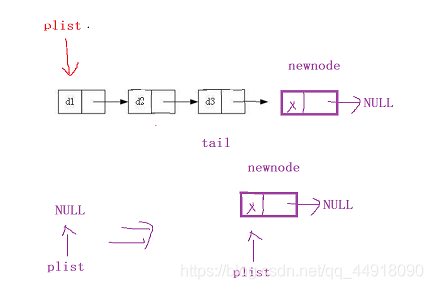
代碼如下:
void SListPushBack(SLTNode** pplist, SLTDateType num) //尾部插入資料,會改變第一個結點,所以傳二級指標
{
assert(pplist);
SLTNode* newnode = BuyListNode(num); //創建一個新結點
if (*pplist == NULL) //考慮當前一個結點都沒有情況
{
*pplist = newnode;
}
else
{
SLTNode* tail = *pplist;
while (tail->next != NULL) //遍歷找到尾結點
{
tail = tail->next;
}
tail->next = newnode; //把新結點的地址給前一個結點的指標
}
}
5.鏈表頭部插入資料SListPushFront
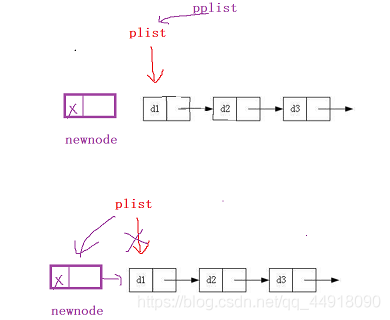
代碼如下:
void SListPushFront(SLTNode** pplist, SLTDateType num)
{
assert(pplist);
SLTNode* newnode = BuyListNode(num);
newnode->next = *pplist;
*pplist = newnode;
}
6.鏈表尾部洗掉資料SListPopBack
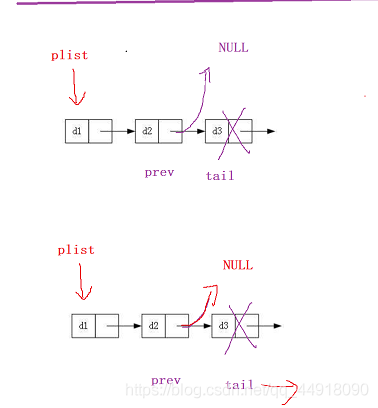
代碼如下:
void SListPopBack(SLTNode** pplist)
{
//1.沒有結點
//2.1個結點
//3.多個結點
if (pplist == NULL)
{
return;
}
else if ((*pplist)->next == NULL)
{
free(pplist);
*pplist = NULL;
}
else
{
SLTNode* prev = NULL;
SLTNode* tail = *pplist;
while (tail->next != NULL)
{
prev = tail;
tail = tail->next;
}
free(tail);
tail = NULL;
prev->next = NULL;
}
}
7.鏈表頭部洗掉資料SListPopFront
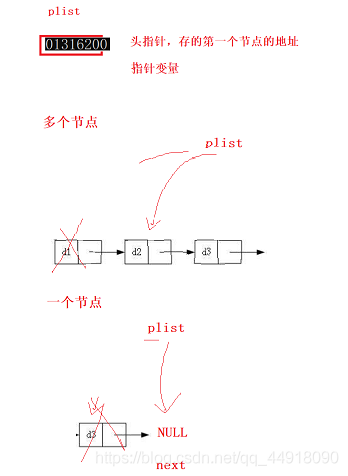
代碼如下:
void SListPopFront(SLTNode** pplist)
{
if (*pplist == NULL)
{
return;
}
else
{
SLTNode* next = (*pplist)->next;
free(*pplist);
*pplist = next;
}
}
8.鏈表查找資料SListFindKey
代碼如下:
SLTNode* SListFindKey(SLTNode* plist, SLTDateType num)
{
SLTNode* cur = plist;
while (cur != NULL)
{
if (cur->data == num)
{
return cur;
}
cur = cur->next;
}
return NULL;
}
9.鏈表在pos位置之后插入資料SListInsertAfter
代碼如下:
void SListInsertAfter(SLTNode* pos, SLTDateType num)
{
assert(pos);
SLTNode* newnode = BuyListNode(num);
newnode->next = pos->next;
pos->next = newnode;
}
10.鏈表在pos位置之前插入資料SListInsertBefore
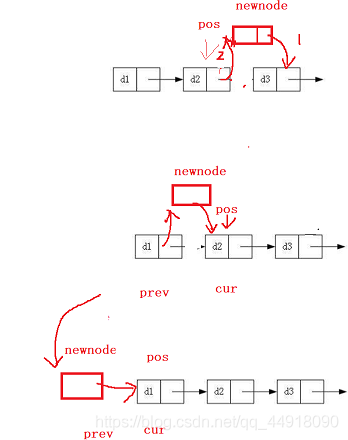
代碼如下:
void SListInsertBefore(SLTNode** pplist, SLTNode* pos, SLTDateType num)
{
assert(pos&&pplist);
SLTNode* newnode = BuyListNode(num);
if (pos == *pplist)
{
newnode->next = pos;
*pplist = newnode;
}
SLTNode* prev = NULL;
SLTNode* cur = pplist;
while (cur != pos)
{
prev = cur;
cur = cur->next;
}
prev->next = newnode;
newnode->next = pos;
}
11.鏈表在pos位置之后洗掉數據SListEarseAfter
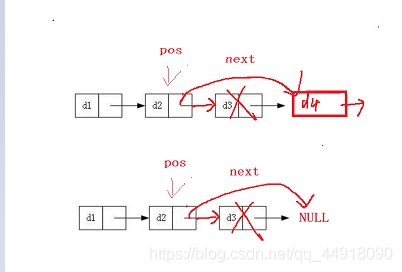
代碼如下:
void SListEarseAfter(SLTNode* pos)
{
assert(pos);
if (pos->next == NULL)
{
return;
}
else
{
SLTNode* cur = pos->next;
pos->next = cur->next;
}
}
總結
以上就是今天要講的內容,本文僅僅簡單介紹了鏈表的各種方法的實作,而鏈表提供了方法能使我們快速便捷地處理資料的函式和方法,我們務必掌握,另外,如果有需要原始碼的私信我即可,還有,,如果上述有任何問題,請懂哥指教,不過沒關系,主要是自己能堅持,更希望有一起學習的同學可以幫我指正,但是如果可以請溫柔一點跟我講,愛與和平是永遠的主題,愛各位了,

轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/275515.html
標籤:其他
上一篇:【熬了五個晚上的長文】致畢業生一封信:那些年我們錯過的BAT,這次全部拿回來!
下一篇:資料結構——紅玫瑰與白玫瑰之爭