提示:本文適用于剛剛入門學習爬蟲的童鞋
爬蟲入門級別教程
- 前言
- 一、爬蟲的合法性及其探究
- 1、爬蟲合法嗎?
- 2、爬蟲要注意什么?
- 二、爬蟲的幾個步驟
- 1、指定url
- 2、發送請求
- 3、接受請求得到的資料
- 4、進行持久化存盤
- 三、幾個案例
- 1、百度一下,你就知道
- 2、豆瓣Top250
- 3、抓取QQ音樂的評論
- 4、豬八戒網
- 5、糗事百科圖片下載
- 總結
前言
提示:隨著資料相關專業的普及,爬蟲已經變得越來越重要,當我們想在網上批量獲取公開資料的時候,手動復制難免費時費力,而這個時候,爬蟲就起到了至關重要的作用
可能會使用到的庫有:requests、lxml、re、bs4 如果沒有這些庫的話可以在命令列使用pip install… 進行安裝!!! 本博客的文章都很簡單,遇到每個實體都建議自己動手去敲,而不是直接賦值黏貼,因為我也沒寫代碼哈哈哈哈,圖片若看不清的話可以點擊放大來看,
提示:以下是本篇文章正文內容
一、爬蟲的合法性及其探究
1、爬蟲合法嗎?
爬蟲是屬于灰色地帶的產物,也就是說,如果你往好的地方用,是沒有關系的,但如果你無視法律的存在,去干壞事,那就是屬于違法了,
2、爬蟲要注意什么?
- 盡量優化自己的程式,不要給別人的服務器造成很大的麻煩,并且不要瘋狂的點擊別人的網站,通常那樣會讓別人承擔不住,
- 不要寫惡意的爬蟲
- 不要爬取網上的隱私資料,商業機密,敏感資料等…
- 不要拼命破解一些別人加密了的資料,通常這些資料別人并不想全給你抓取下來
- robots.txt協議
二、爬蟲的幾個步驟
1、指定url
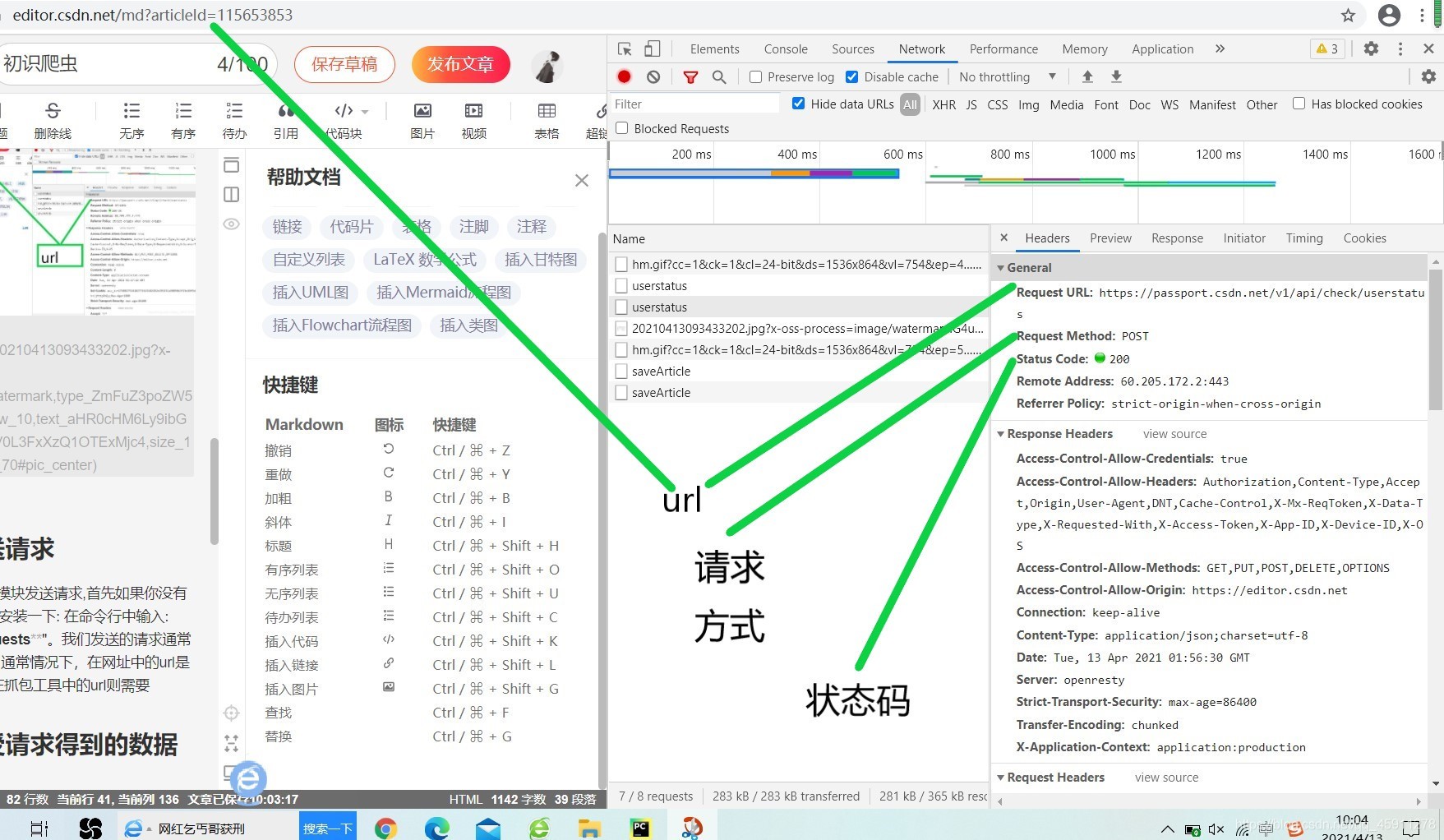
url通常是你要爬取的網站,通常我們會在網址中直接獲取,或者在抓包工具中(按F12或者滑鼠右鍵檢查),找到你想要的資料的網址,下面展示一下獲取url的地方,直接獲取就可以,
2、發送請求
我們使用requests模塊發送請求,首先如果你沒有這個庫的話需要先安裝一下: 在命令列中輸入: “pip install requests”,我們發送的請求通常有post和get,通常情況下,在網址中的url是使用get方式,而在抓包工具中的url則需要看一看Request Method這個引數是什么,
- post請求: requests.post()
- get請求: requests.get()
3、接受請求得到的資料
-
我們要對網頁所回傳的資料進行一些處理,才能得到我們想要的資料,首先我們要接受它,
-
在我們使用post或者get之后,我們需要一些手段來得到我們的資料,通常有:
- text : 獲得網頁源代碼
- json : 獲得json資料(json是一種資料互動方式),通常我們可以直接得到json資料或者使用json.load或json.loads方法將其轉換為Python中的字典
- content : 獲得二進制資料
-
我們需要使用一些匹配規則來匹配我們所需要的資料,通常有:
- re正則運算式
- BeautifulSoup
- Xpath
4、進行持久化存盤
- 持久化存盤這塊讀者可大膽發揮自己的想象力,我們可以存盤在excel表中,以csv或者xlsx的形式、或者存盤在資料庫中,亦或是存盤在txt文本當中,在后面的實體我們再仔細講解,
三、幾個案例
在所有案例開始之前,再次申明,請不要對別人的服務器制造很大的麻煩!!!!!!
1、百度一下,你就知道
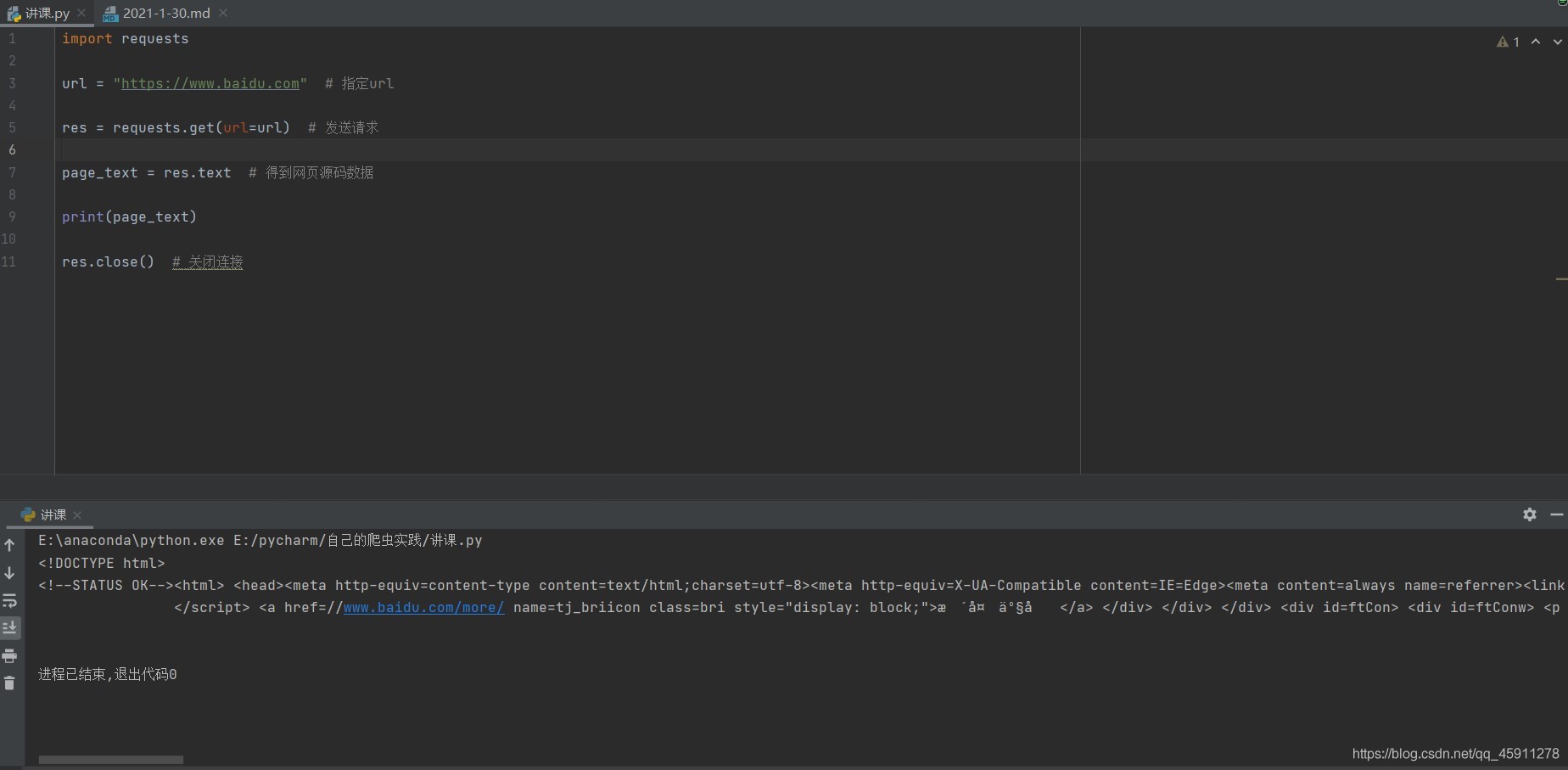
- 我們寫好了我們的程式,然后運行它,發現列印出的原始碼只有如此一點點,我們現在打開百度的首頁,滑鼠右鍵點擊查看網頁源代碼,顯然我們沒有拿到全部的網頁源代碼,而且這里的字符好像也出了點問題,
- 我們先來看一看字符的問題,是不是編碼錯誤? 我們加上res.encoding=“utf-8”,
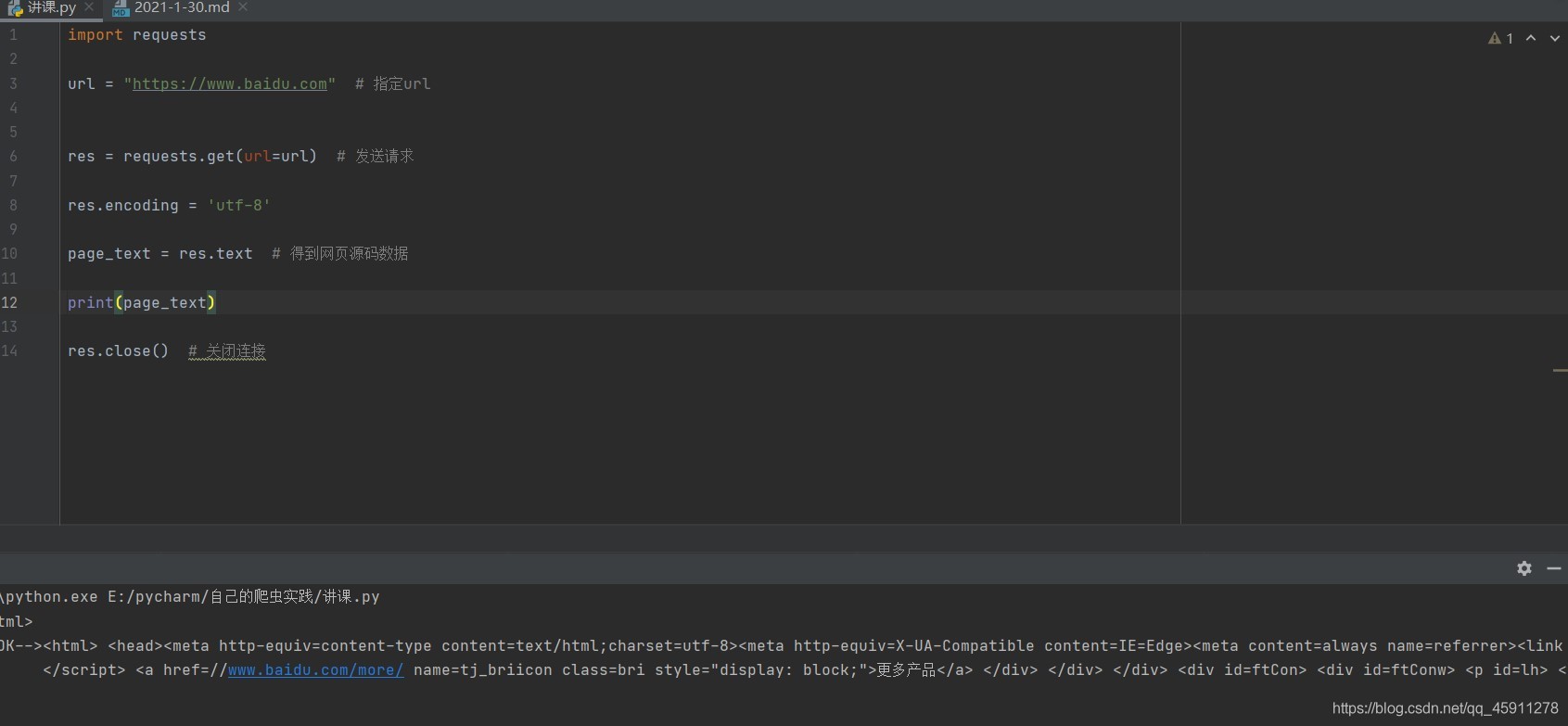
- 這樣就正常了,但是我們怎么解決得不到全部源代碼的問題呢?我們懷疑可能是被發現了,
- 我們需要進行一些偽裝,headers意味發送的請求頭,我們在headers這個字典中加入了User-Agent這個引數,表明我們是一個瀏覽器而不是一個Python程式,User-Agent引數通常在自己的網頁中進行復制,同樣的打開抓包工具,重繪出一些網頁來,在Requests Headers(請求頭)中我們找到User-Agent這個引數(藍筆標注),并直接進行復制,我們首先用雙引號將其隔開,然后在寫成字典形式即可,
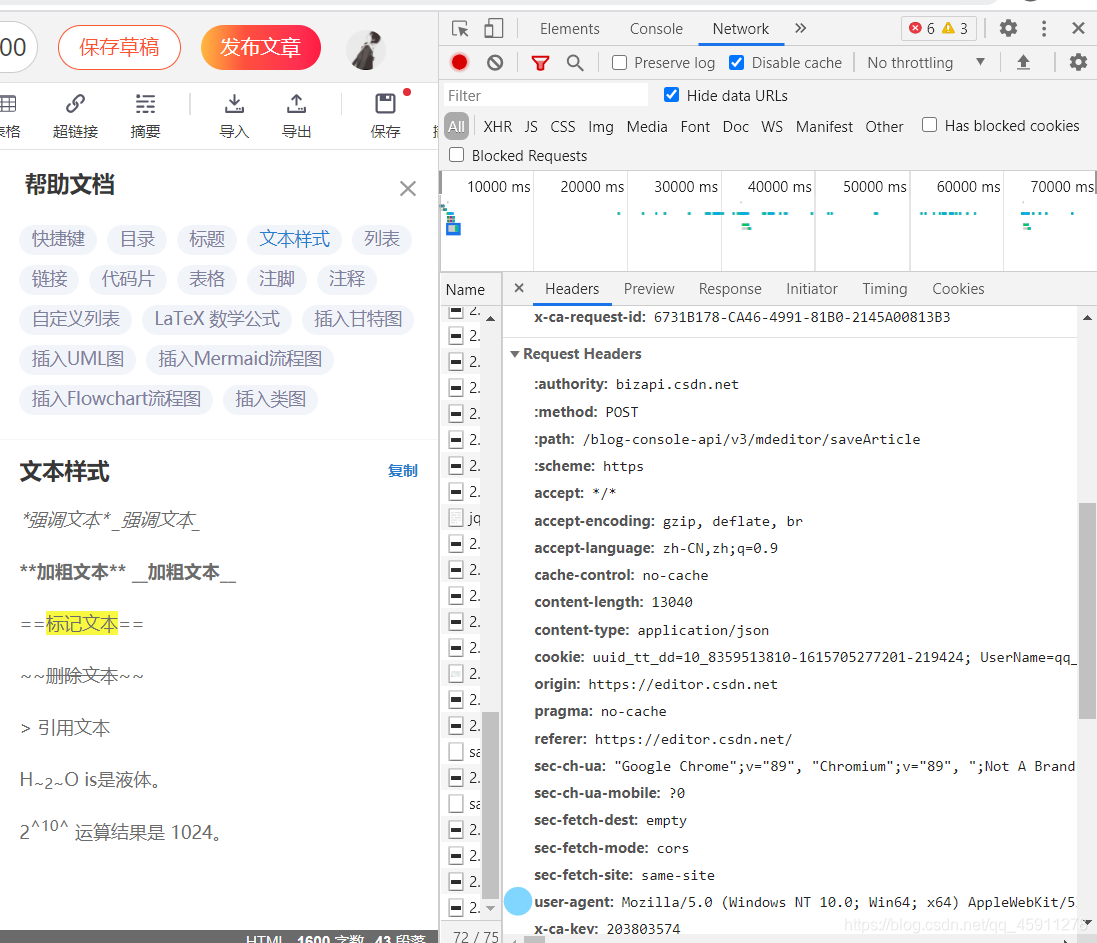
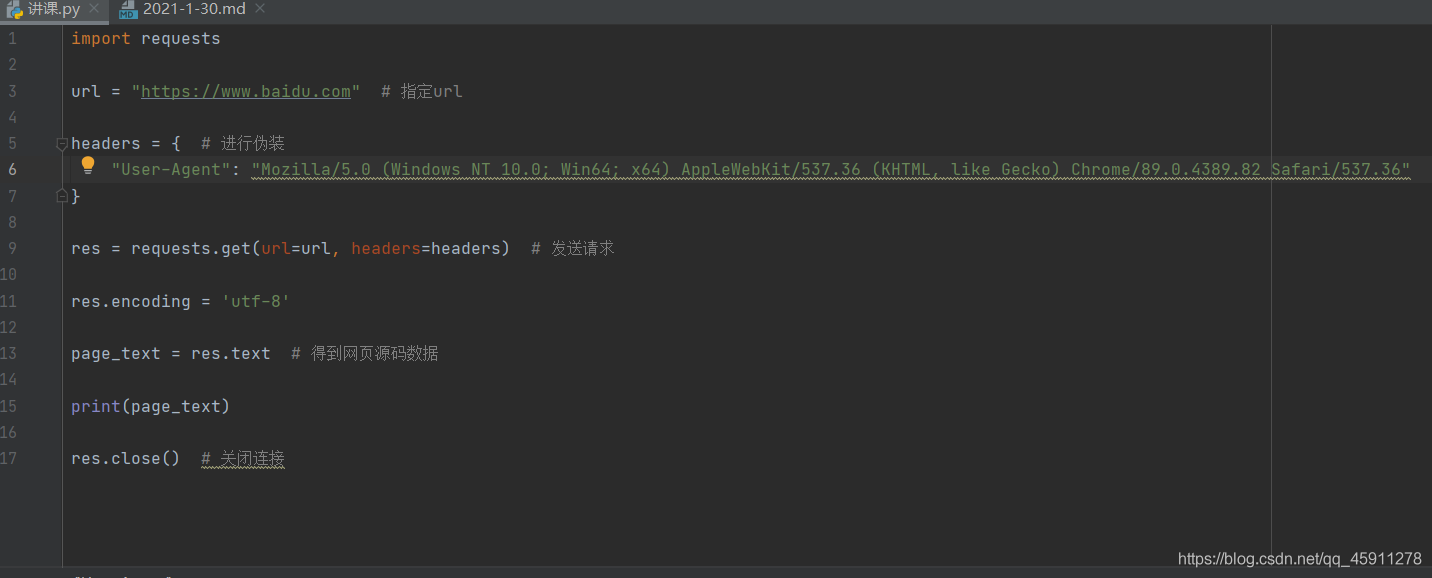
- 這樣看來,我們的資料就變得正常了,
- 現在我們相對剛得到的資料進行持久化存盤,打開一個baidu.html檔案,以寫的方式進行存盤,encoding表示指定編碼方式,
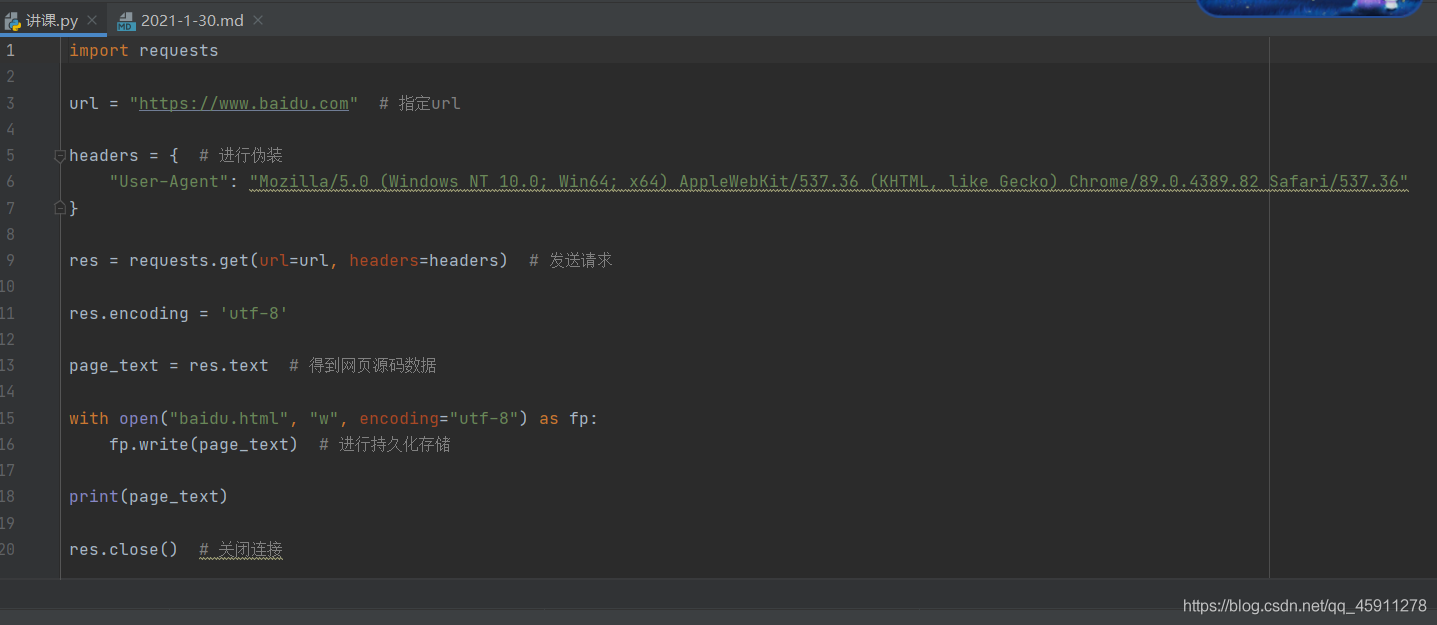
- 這樣在我們得到的原始碼中,我們可以直接點開我們的顯示在瀏覽器上的按鈕(藍筆標注),看看是不是真正獲取了全部的源代碼,
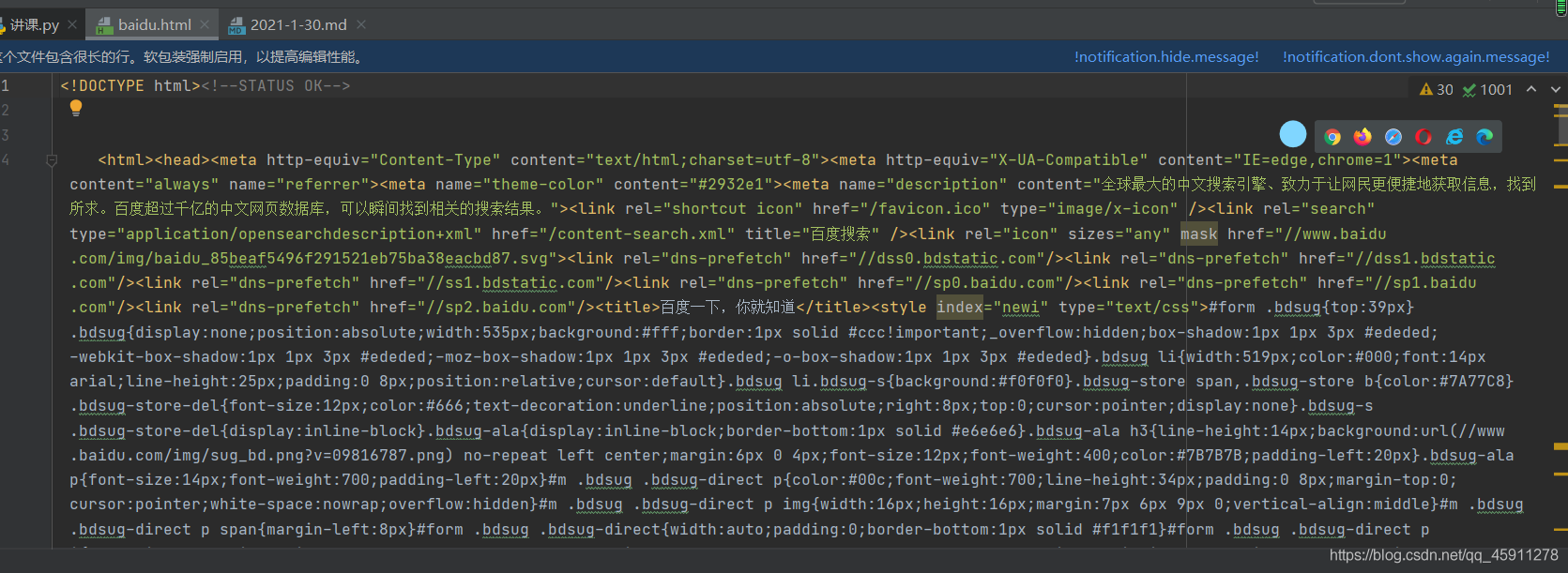
- 補充一個東西,我們百度搜索的東西,假設我要搜索Python
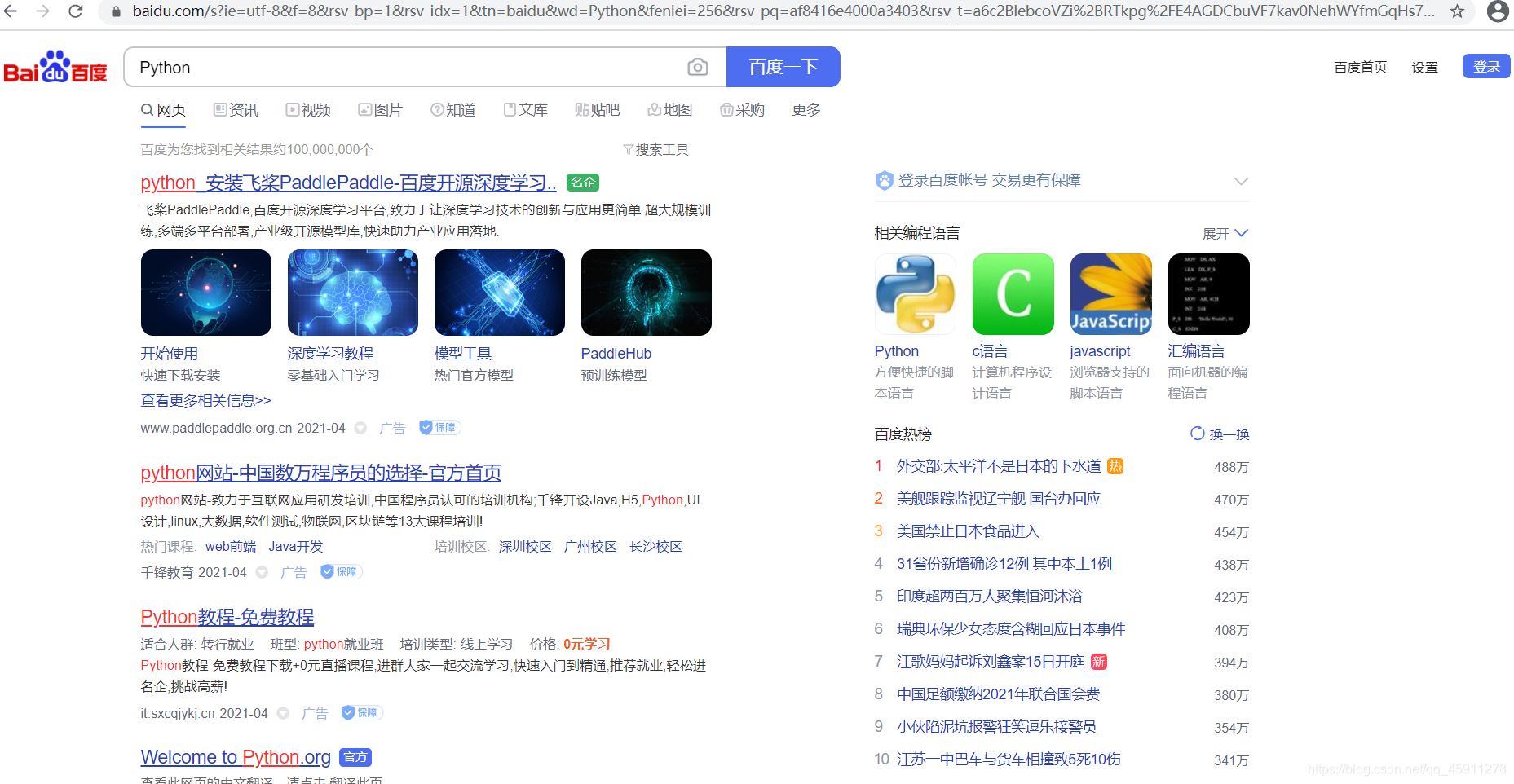
- 好像有一堆引數,但大多數其實是我們不需要的,我們只留下一個wd,
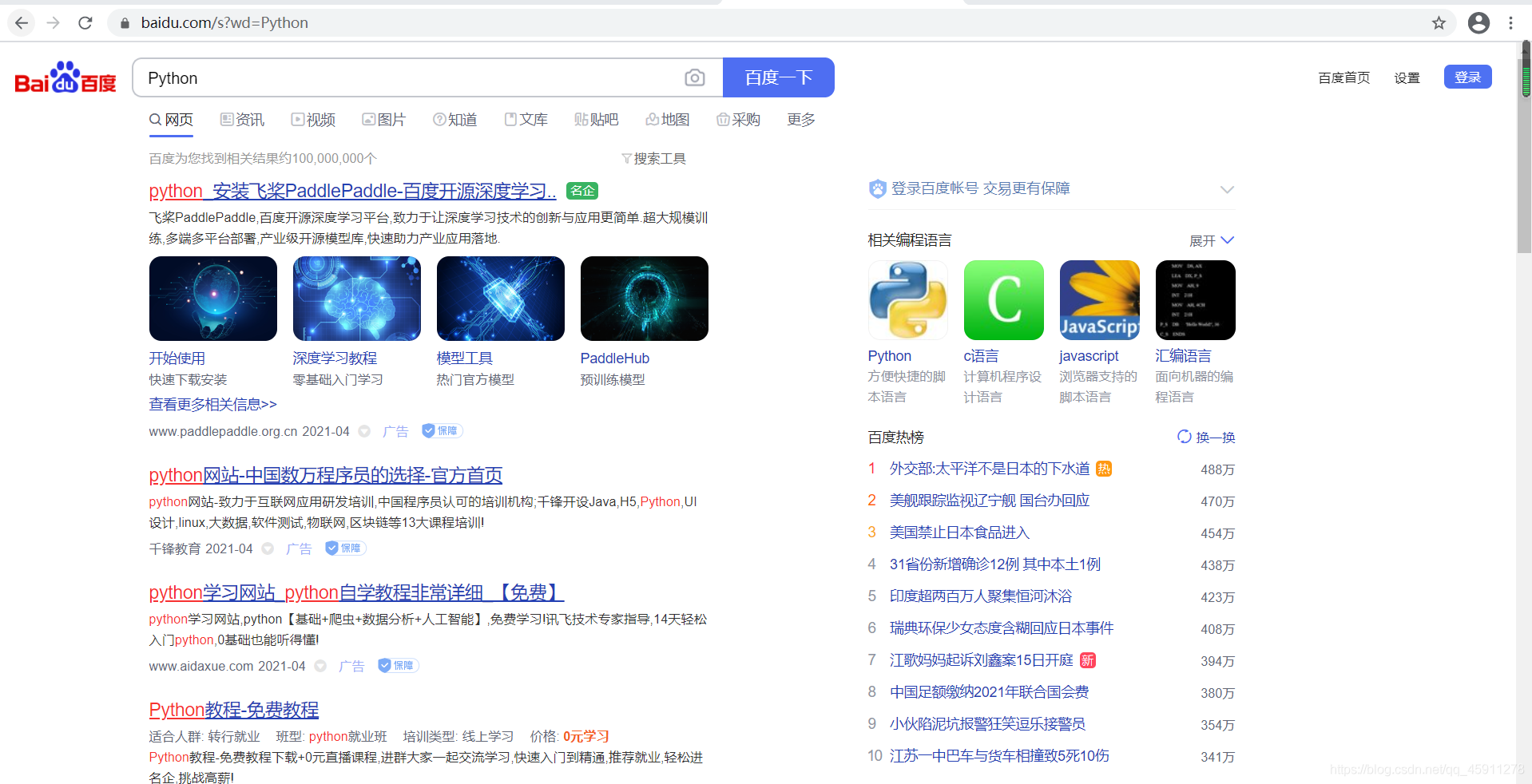
- 搜索出來的東西其實是一樣的,那我們再給這個wd改成Java,
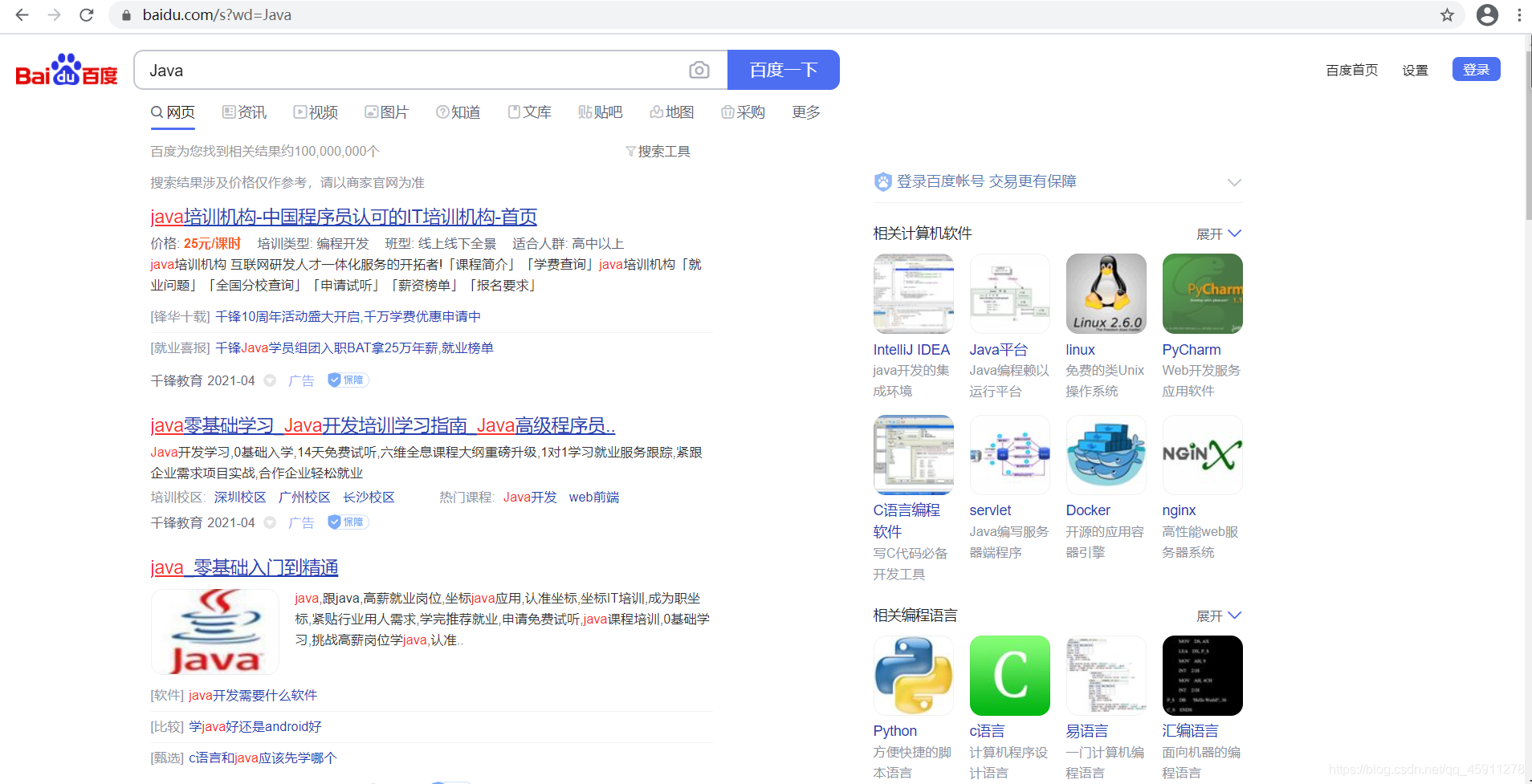
- 可以發現搜索的東西變成了Java,
- 我們打開抓包工具,重繪網頁,發現一個請求,帶著一個引數,這個引數就是我們搜索的關鍵字,
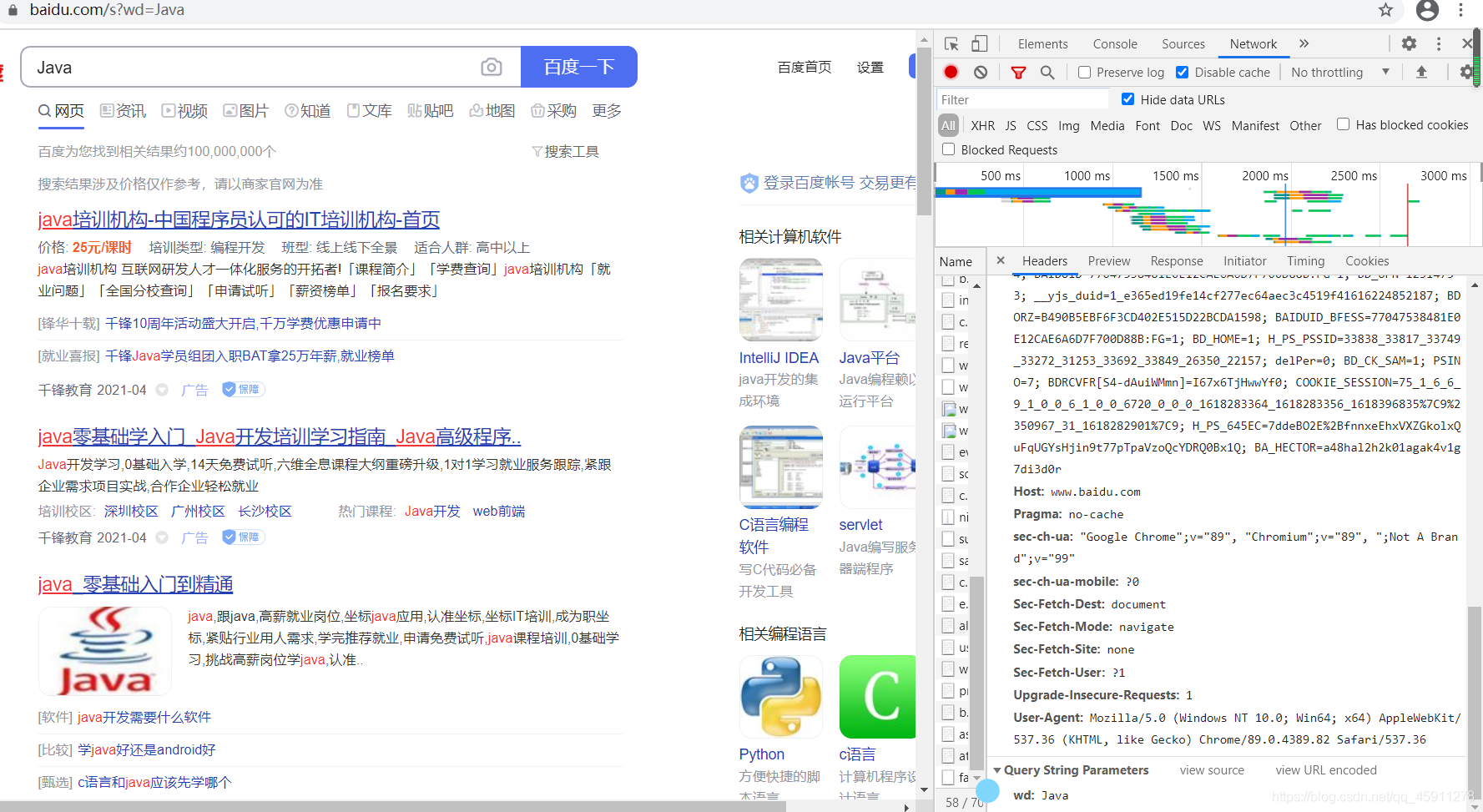
- 你明白了點什么嗎?我們可以發送請求給這個網址,順便帶上引數,
- get請求的引數是params,而post請求是data,
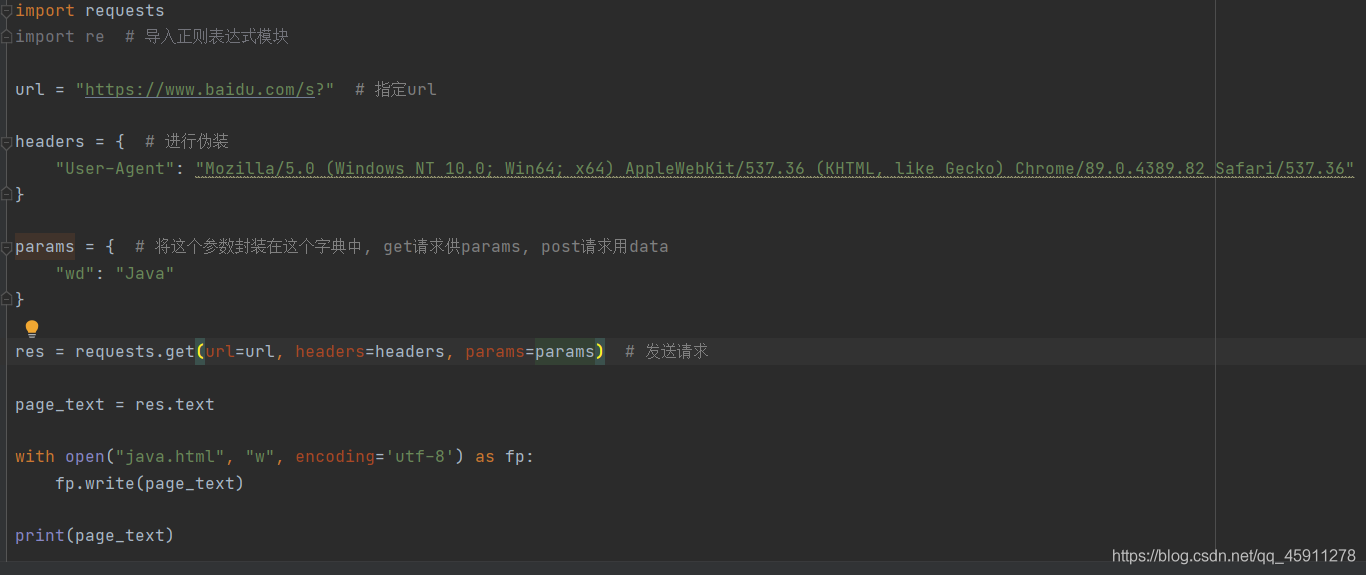
- 當你將得到的這個原始碼打開,你就會發現進入了Java的搜索頁面,
- 這個案例到這就結束了,這僅僅是一個簡單的開始,它讓你明白在原有的基礎上,你可能需要一些偽裝手段,查看/掌握編碼的技巧,
2、豆瓣Top250
- 先進入頁面看看
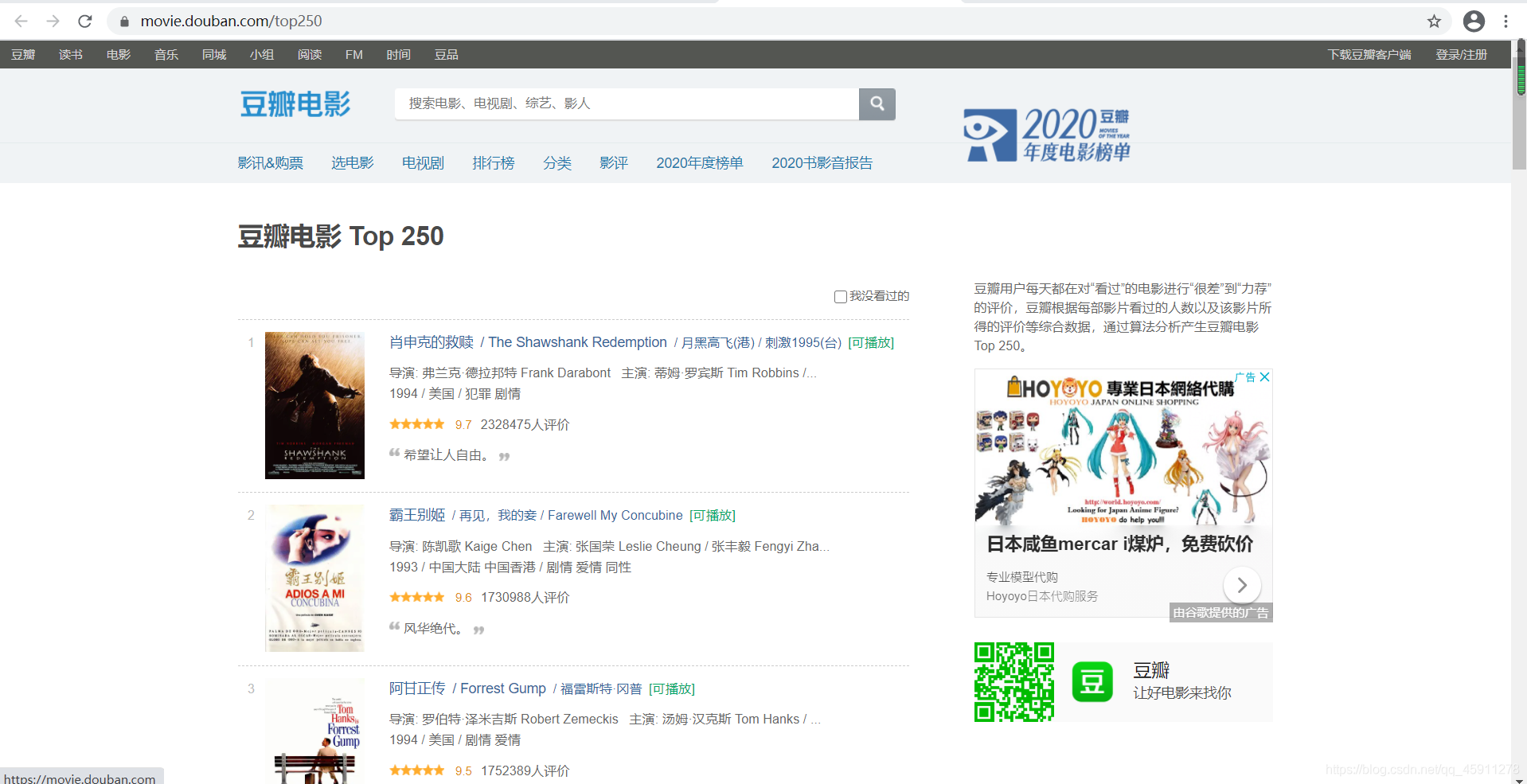
- 我們以電影的名字來舉例:我們想獲得一部分電影名字的資料,我們先右鍵選擇查看網頁源代碼,按ctrl+f進行搜索,我們想在原始碼中找一下是否有肖申克的救贖這幾個關鍵字,我們確保在原始碼中是有這些東西的,但是看這么多原始碼,一下子想取出來難免有點費勁,

- 在取出這些資料之前,我們需要先學習一個名叫正則運算式(re)的東西
- 正則運算式是一種匹配規則,你首先需要知道這些,
- . : 匹配除換行符外的任意字串
- \w : 匹配字母或數字或下劃線
- \s : 匹配任意的空白符
- \d : 匹配任意數字
- ? : 匹配0次或1次
- * : 匹配0次或多次
- + : 匹配1次或多次
- ^ : 從頭開始匹配
- $ : 從尾部開始匹配
- {n} : 重復n次
- {n,[m]} : 重復n次或更多次(或到m次)
- [^] : 不匹配字符組里的字符
- .* : 表示貪婪匹配
- .*? : 表示非貪婪匹配
- \W : 表示匹配非字母或數字或下劃線
- \D : 表示匹配非數字
- \S : 表示匹配除空白符外的任意
- \n : 表示匹配一個換行符
- \t : 表示匹配一個制表符
- a|b : 匹配字符a或b
- () : 匹配括號內的運算式,也表示一個值
*別急還有億點點~~~~*
- 然后知道這些函式的話就比較足夠了
- re.findall(匹配規則,字串) : 在字串中找到所有滿足匹配規則的字串,并以串列的形式回傳,
- re.finditer(匹配規則,字串) : 在字串中找到所有滿足匹配規則的字串,并以迭代器的形式回傳,
- re.search(匹配規則,字串) : 在字串中找到一個滿足匹配規則的字串就回傳,
- re.match(匹配規則,字串) : 在字串中從頭匹配,找不到就報錯,
- 預加載匹配規則
- re.compile("",[可加入其它,前面也可,比如re.S,表示讓.可以匹配換行符]) : 在里面填入你的匹配規則
- com = re.compile("")
- com.findall(字串)
- 括號的拓展使用 : (?P<這里可取名字>然后寫正則)
- 例 : (?P< name >.*?) (注意這里面不需要打引號)
- 下面動手試試吧~~~ ,對人家服務器友好一點!!!
-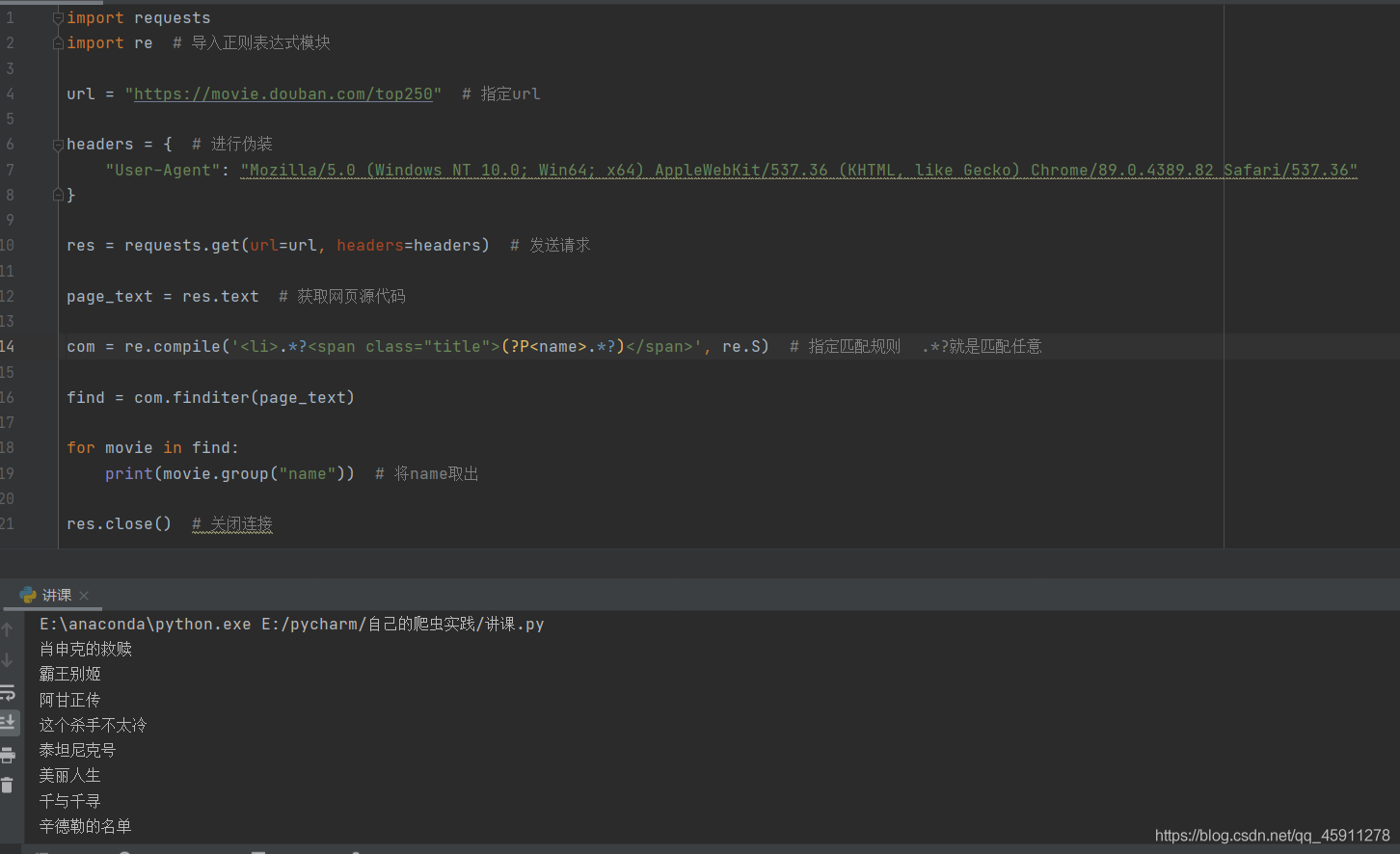
- 我們看到我們已經獲取到了我們需要的資料,
- 其實正則也有偷懶的寫法,即復制網頁源代碼,將某些部位改成.? 或 (.?) ,后者里面是需要匹配的資料,前者是不需要的,但是會幫助你匹配,過濾一些代碼,
- 正則就到這里吧嘻嘻嘻嘻嘻,
- 但我們會發現了個有趣的東西,我們換頁的時候有些引數在改變,我們刪去filter這個引數,留下這個start,當前顯示start是等于25,而我們的頁面中的電影序號是26,這會不會有某些規律,
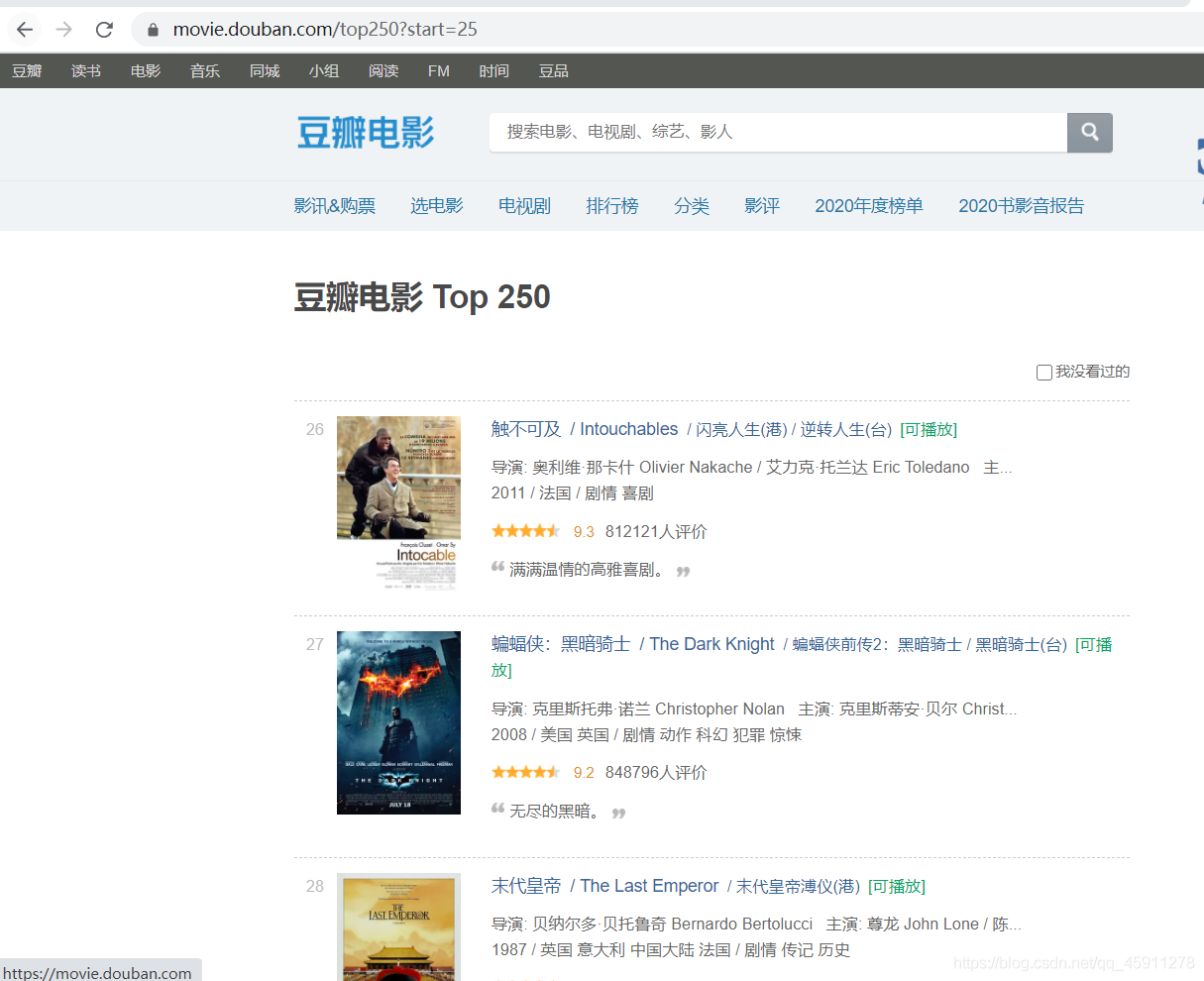
- 我們將start改成30,神奇的一幕發生了!!!
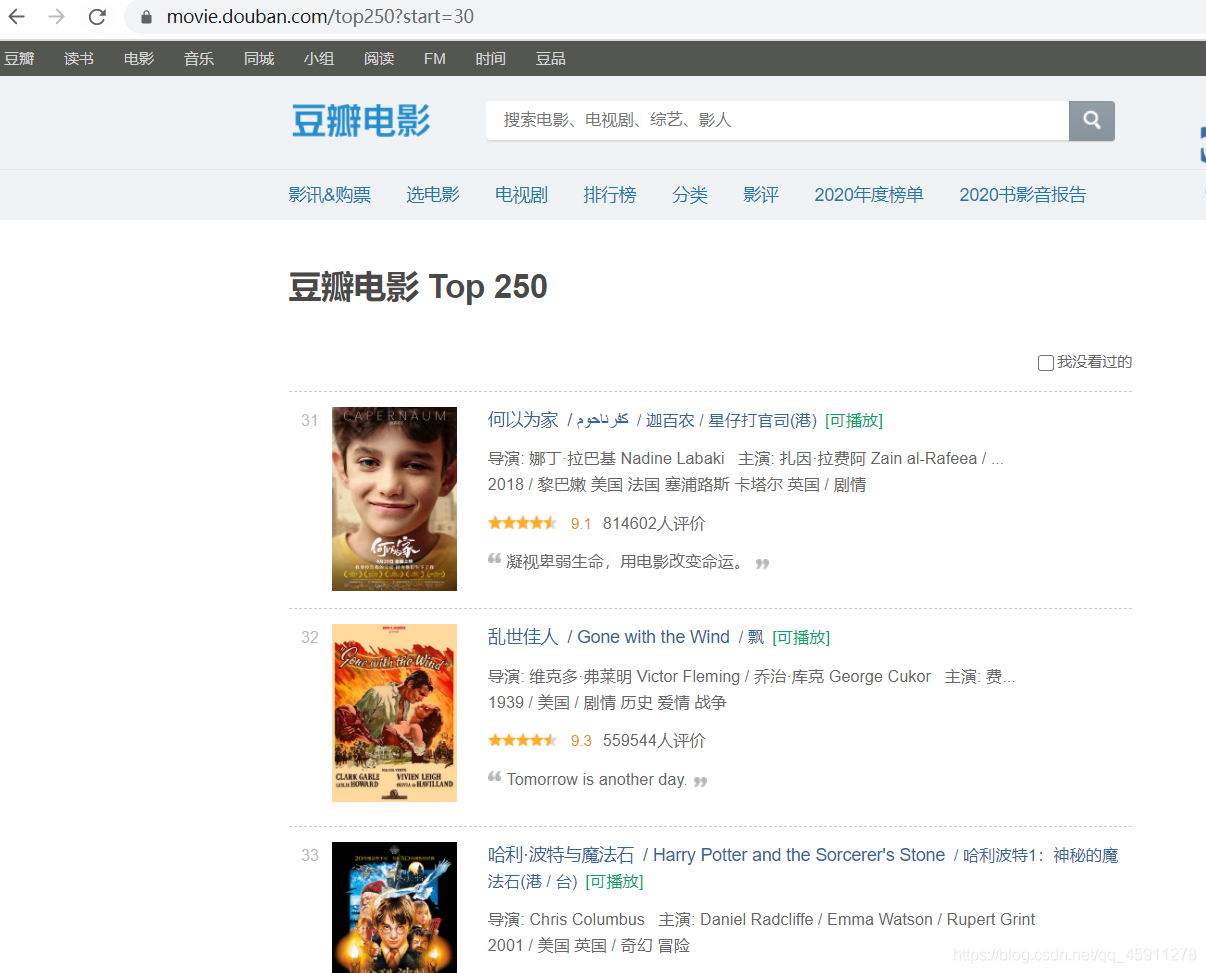
- 現在這個頁面電影的序號是從31開始的了!!!還挺有趣的吧嘻嘻嘻,
- 斜眼笑.jpg,
3、抓取QQ音樂的評論
- 廢話不多說,我們直接找到我們要的一點點評論
- 那個包是在綠色字標注的那個包的上面的那個包,這里標識錯了,
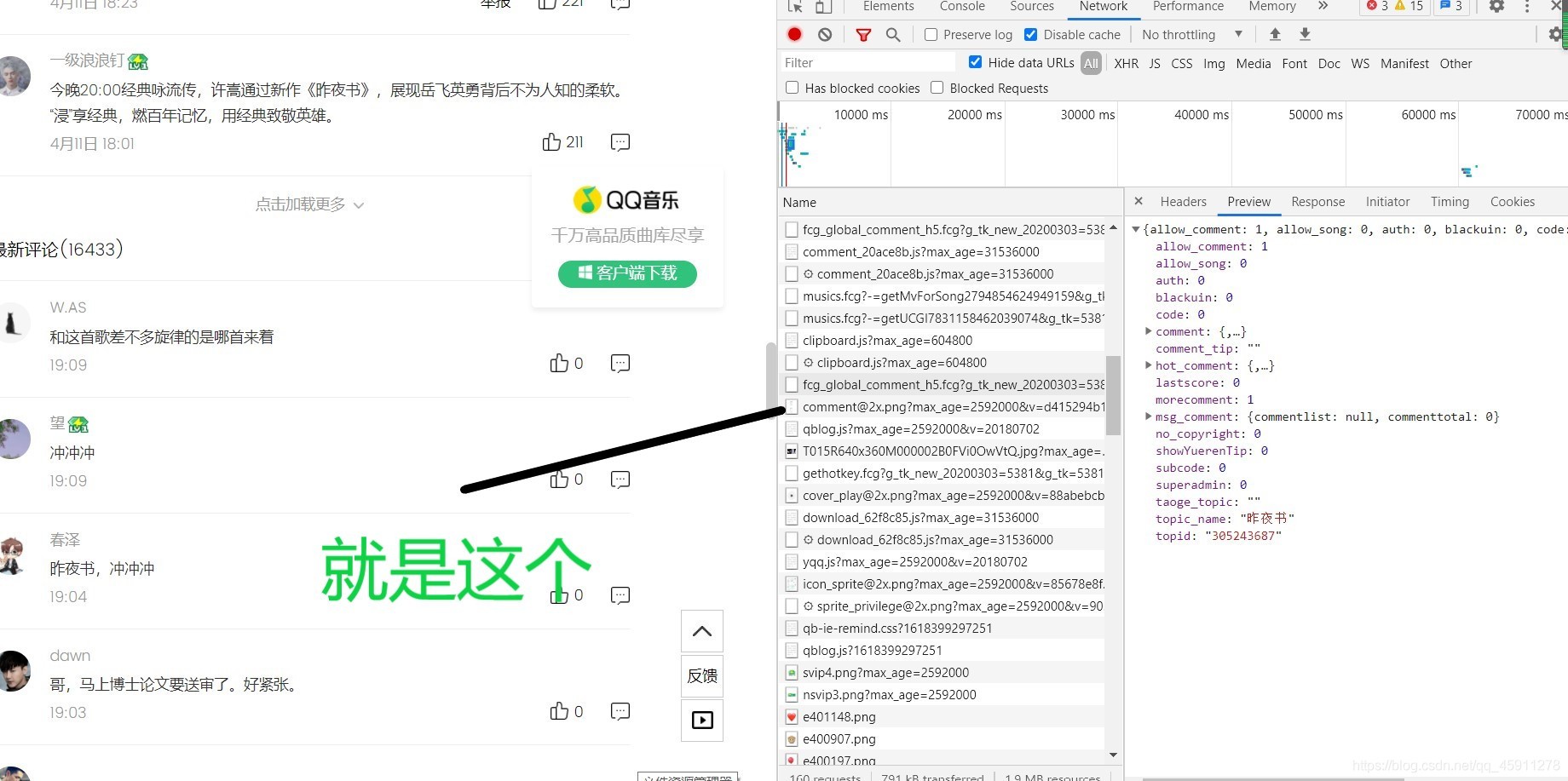
- 現在我們一層層剝開它的心
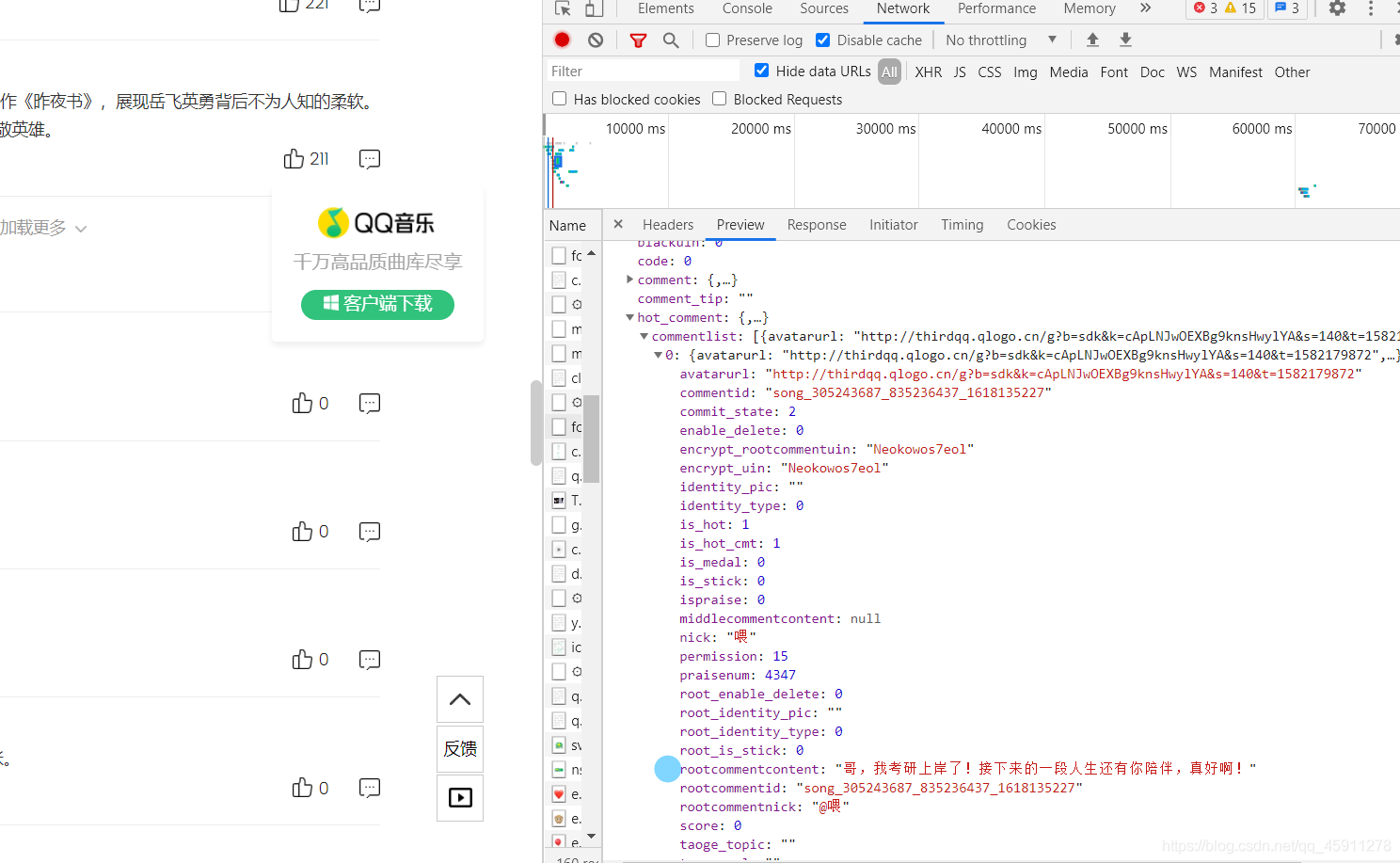
- 這兒!(藍筆標注)應該就是我們想要的東西,好!開始碼代碼,我們事先查看一下請求方式及編碼格式還有回傳的資料,這次的資料居然是json的格式,我們只要在我們請求之后加上 .json() 就好,回傳的格式是Python中的字典,字典的嵌套形式,即要一層層取出你要的東西,
- 例子:
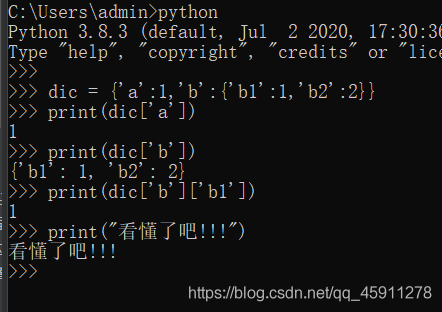
-
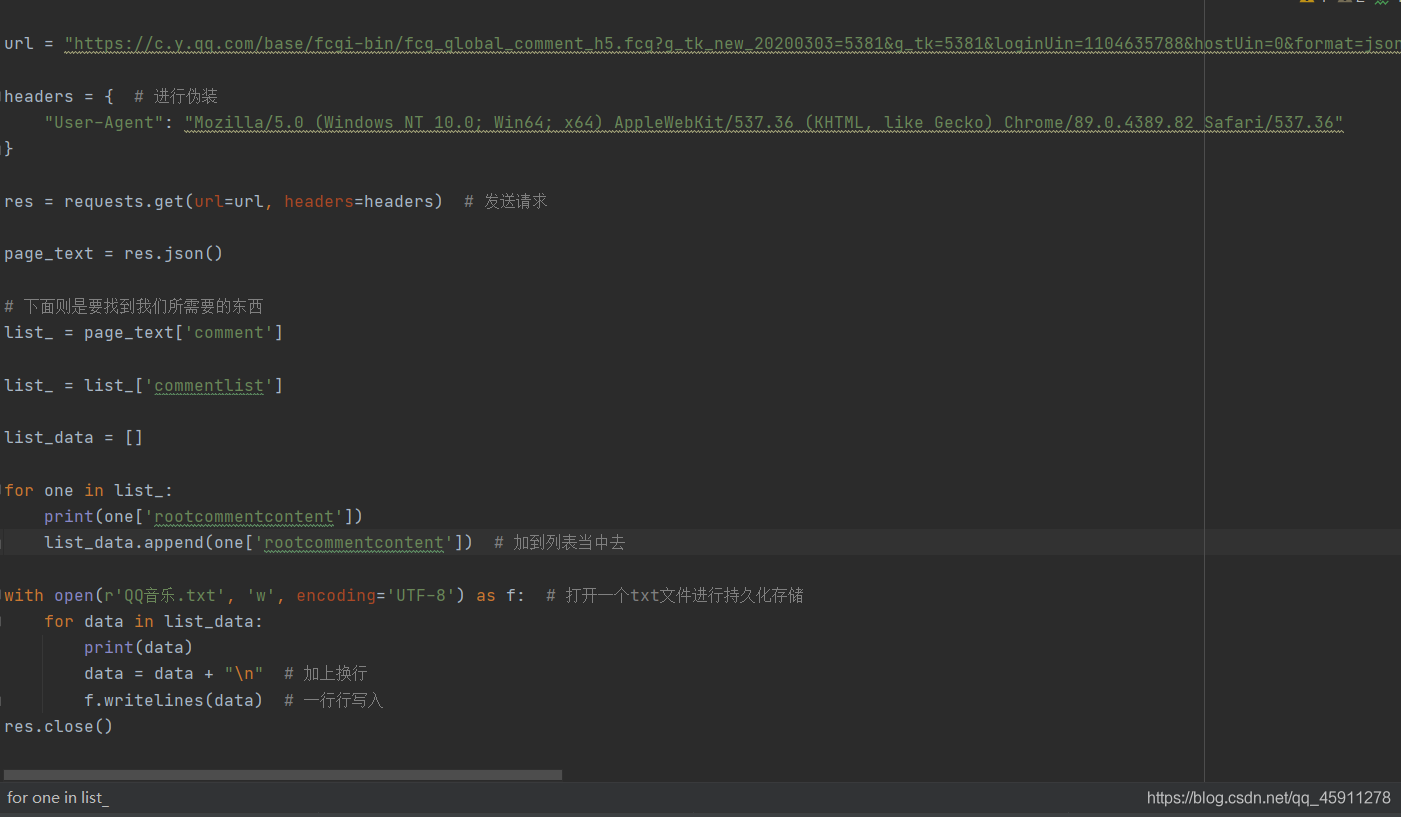
下面是代碼
-
json格式的檔案只要 .json() 就會回傳一個字典啦,至于怎么快速地找到字典中的鍵,那就要將這個字典格式的資料放到json在線決議工具中去,然后就可以清晰地找到了,
-
這就持久化存盤好了

-
完結!!!!
4、豬八戒網
- 先看一看這個網站,還挺有意思的,
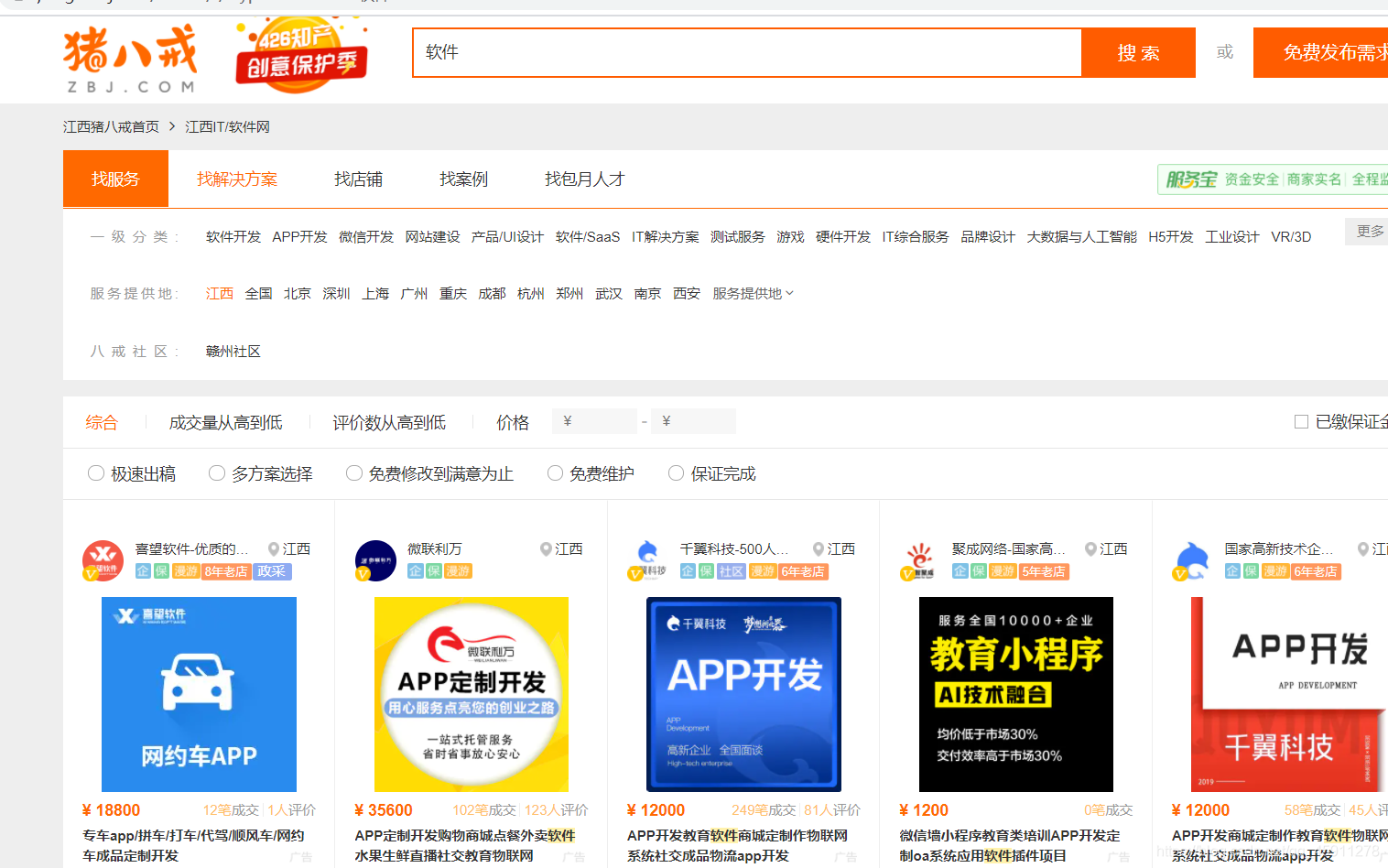
- 我在搜索欄中輸入了軟體二字,現在我們想把這些價格資訊抓取下來
- 我們查看頁面源代碼,發現里面有我們想要的資料,
- 在這之前,我們需要學習一個很方便的匹配規則-Xpath,Xpath嘛用過的人都說好~~~
- Xapth的學習:類似樹的一種查找,從根節點,一層層地查找,回傳串列,
- / : 表示從根節點開始,表示的是一個層級,
- // : 表示從任意節點開始查找, 表是多個層級,
- /div : 查找該節點下的div標簽,
- /div[1] : 查找該節點下的第一個div標簽,Xpath中索引從1開始,
- /div[@class=“abc”] : 查找該節點下的一個div標簽,他有一個class屬性,屬性值為abc,
- /text() : 取該節點下的文本內容
- //text() : 獲取該節點以及它的子節點下的文本內容
- /@attr : 取該節點的attr屬性
- 實體化一個etree物件 from lxml import etree
- 加載本地html的原始碼檔案 : etree.parse(filepath) filepath是檔案路徑
- 加載從互聯網中剛得到的html原始碼 : etree.HTML(‘page_text’)
- 沒啦!是不是很少!!!
- 下面開始擼代碼吧!
- 等等,我們先看看這個箭頭,
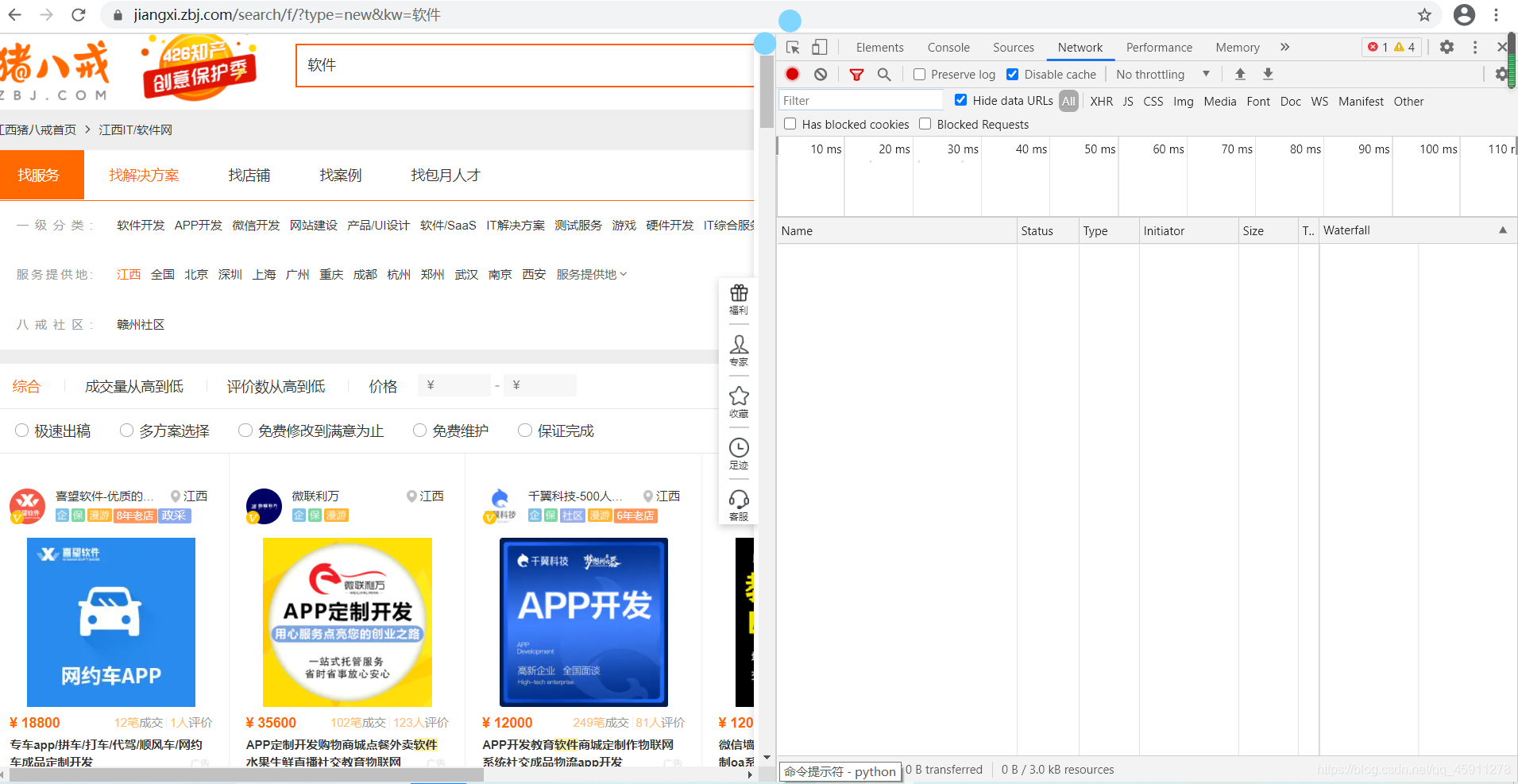
- 點一下他,在點一下你要找的東西,就會跳轉到你想要找的代碼了,
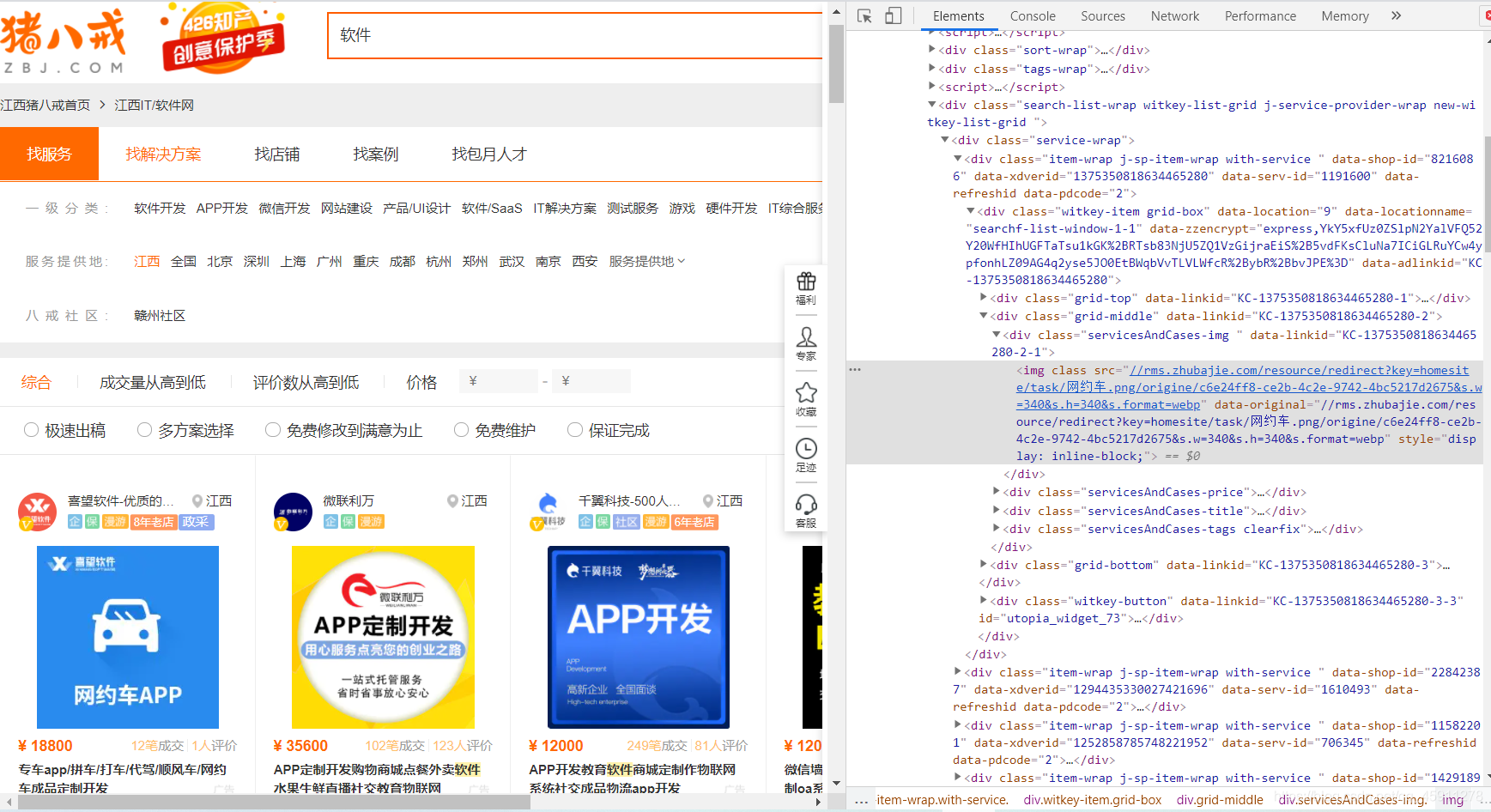
- 然后就是你自由發揮的時候啦,我們順著這個源代碼,一層層地找下來,
- 直接看代碼吧!
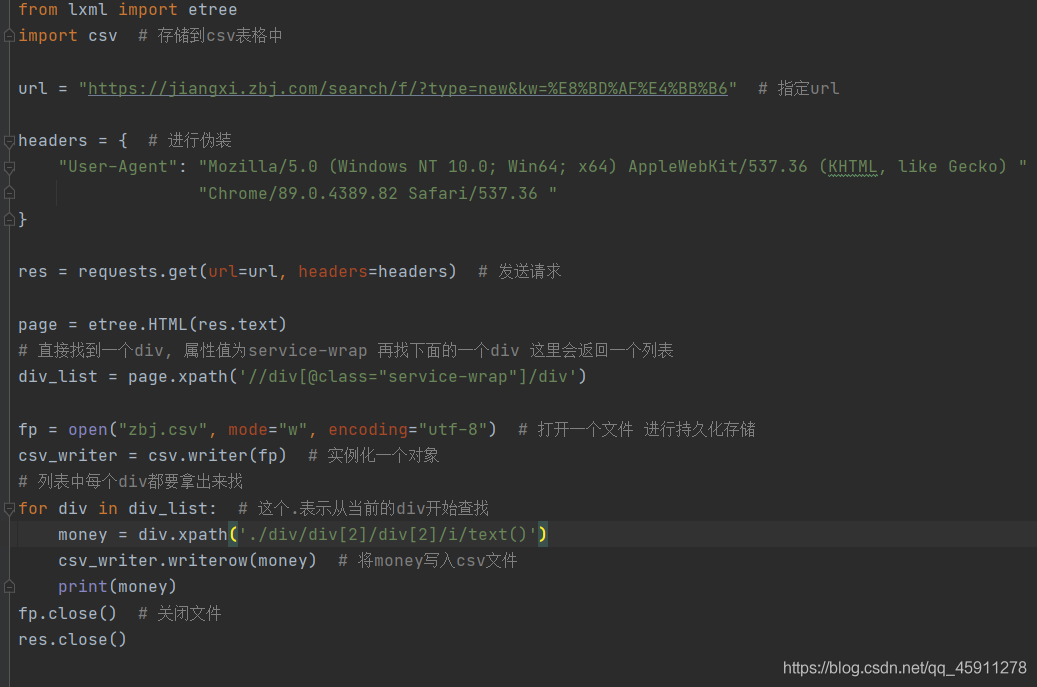
- 再看看我們的檔案
- 資料已經存盤進來了!!!
- 完結!!!
5、糗事百科圖片下載
- 學到這里,你應該知道怎么做了吧?當然是先去找對應的圖片鏈接啊!!!之前講過的怎么分析原始碼在這里依然用得上,而且這里還多了一點東西——那就是你得先找到圖片鏈接,再對鏈接進行訪問,將圖片進行下載,
- 用之前說過的方法,我們可以很輕松地找到圖片鏈接
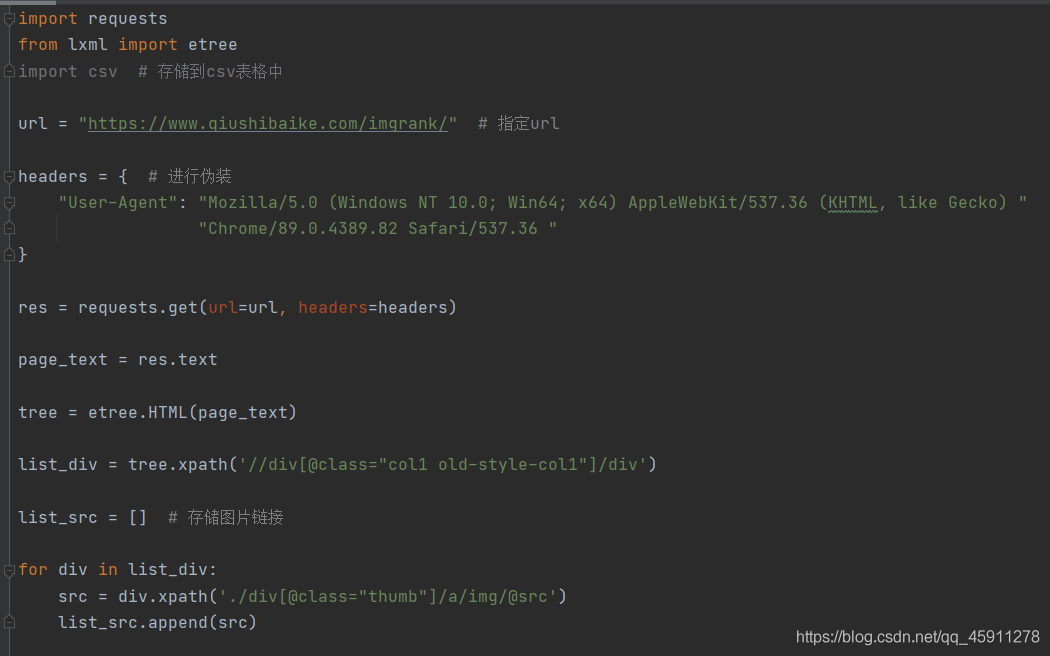
- 然后我們可以根據自己的愛好,選擇自己喜歡的匹配規則,
- 然后呢,找到對應圖片的鏈接,將其存放在一個串列中,
- 之后再對串列中的圖片鏈接進行處理并進行訪問,使用**.content**方法將其下載,
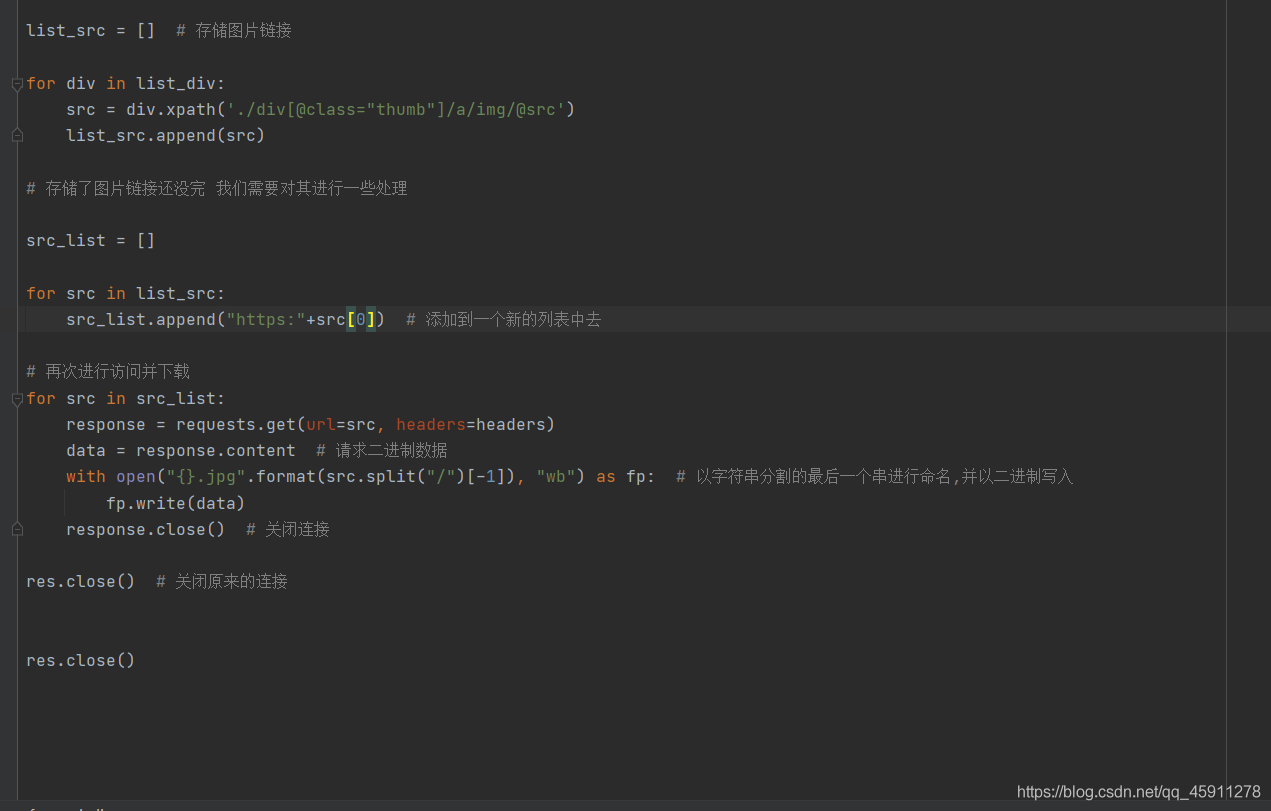
- 現在讓我們來看看我們的檔案有沒有圖片

- 當然是有的啦,只不過沒有展示那么多,
- 有沒有發現一個問題??我的圖片是.jpg.jpg!!!這是因為在給圖片命名的時候我手動添加上了.jpg,好吧是我畫蛇添足了,糗事百科就到這里吧!
總結
提示:本文章中涉及了爬蟲的基本知識,包括發送請求,處理請求,持久化存盤等等,這只是一個小開頭,爬蟲的冰山一角,本文沒有涉及js等更高級的爬蟲,作為初學者不需要了解太多,待對前端有更深入的學習之后再去了解更多就不會感到迷糊了,本文也介紹了爬蟲的一些基本分析方法,當然只是一個思路罷了,如果想學會更多的東西,還是要不斷的聯系以及不斷的摸索,
寫在最后 :
加油!!!!軟體人
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/276664.html
標籤:其他
下一篇:c語言 資料結構線性表